Python 的核心知识点
在量化投资领域,Python 的学习目标非常明确:
高效、准确地实现交易逻辑。
因此,本课程将系统梳理 Python 中与量化交易直接相关的五大核心知识模块。
并详细说明其在实际交易场景中的具体应用。
掌握这些内容,足以支撑你简单地构建从数据处理、信号生成到组合管理的完整量化工作流。
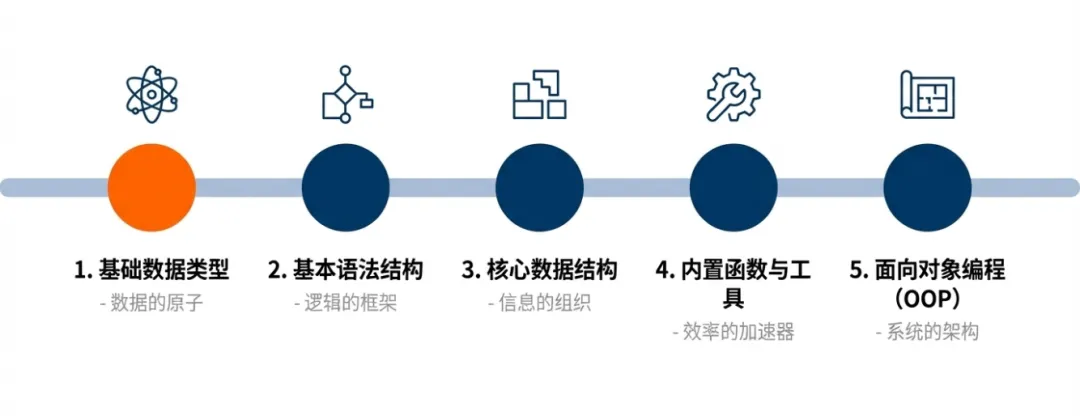
一、基础数据类型
Python 的基础数据类型是所有量化操作的起点。
它们定义了数据在内存中的存储和表示方式。
1. 整数(int)
- 定义:表示任意大小的整数值,包括正整数、负整数和零。
- 定义回测窗口长度(如
lookback_days = 20)。 - 管理订单数量(如
order_size = 100 股)。
2. 浮点数(float)
- 定义:表示带有小数部分的数值,采用 IEEE 754 双精度标准存储。
- 存储股票价格(如
price = 180.50)、指数点位等市场价格数据。 - 计算收益率(如
daily_return = 0.0234 即2.34%)、波动率、夏普比率等金融指标。
- 特性:所有涉及计算的指标,几乎都是 float。浮点运算可能存在微小误差,但在量化容忍范围内。
3. 字符串(str)
- 定义:由 Unicode 字符组成的不可变序列,用于表示文本信息。
- 存储股票代码(如
"600519")、期货合约代码(如 "IF2406")。
- 特性:支持索引、切片、格式化等操作,是连接不同数据源的关键标识符。
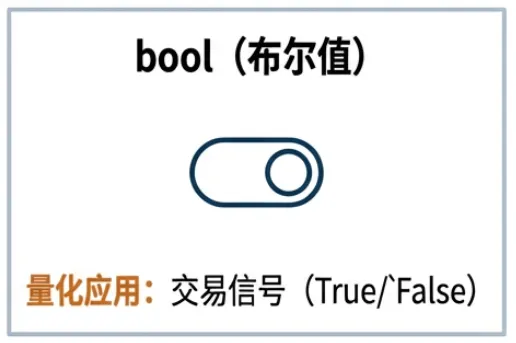
4. 布尔值(bool)
- 定义:仅有
True 和 False 两个取值,用于表示逻辑真/假。 - 作为交易信号的直接输出(如
buy_signal = True)。 - 构建复杂的筛选条件(如
(pe < 20) and (roe > 0.15))。 - 控制程序流程(如
if is_market_open: ...)。
- 特性:可参与逻辑运算(
and, or, not),是策略决策的核心。
5. 空值(None)
- 初始化尚未赋值的变量(如
last_trade_price = None)。
- 特性:
None 不等于 0、空字符串或 False,需用 is None 进行判断。
二、基本语法结构
1. 条件分支(if / elif / else)
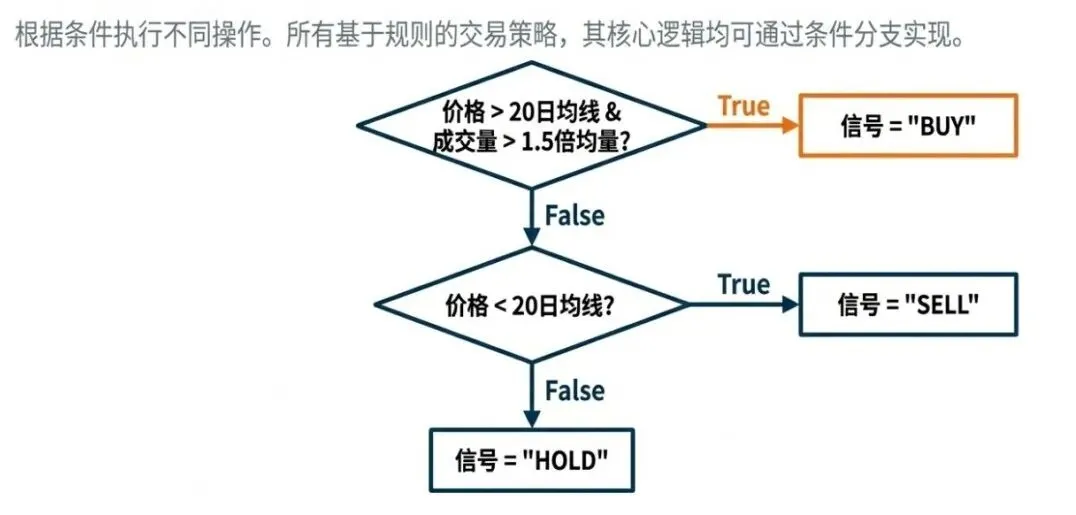
- 量化应用:
if current_price > sma_20 and volume > avg_volume * 1.5: signal = "BUY"elif current_price < sma_20: signal = "SELL"else: signal = "HOLD"
- 关键点:所有基于规则的交易策略,其核心逻辑均可通过条件分支实现。
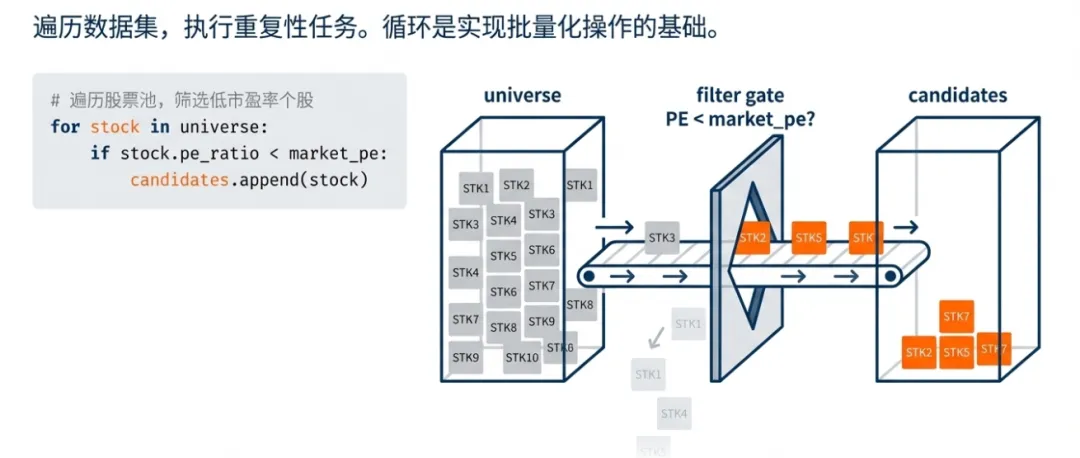
2. 循环(for / while)
for 循环:遍历股票列表、日期索引、因子集合等有序序列。for stock in universe:if stock.pe_ratio < market_pe: candidates.append(stock)
while 循环:在不确定迭代次数的场景下使用,如动态调整仓位直至满足风险预算。
- 关键点:循环是实现批量处理、向量化操作前的基础步骤。
3. 函数(def)
- 功能:将一段具有特定功能的代码封装为可重用的单元。
- 量化应用:
defcalculate_max_drawdown(returns):"""计算最大回撤""" cum_returns = (1 + returns).cumprod() running_max = cum_returns.expanding().max() drawdown = (cum_returns - running_max) / running_maxreturn drawdown.min()
三、核心数据结构(复杂数据的组织方式)
1. 列表(list)
- 保存时间序列数据(如
[100, 102, 98, 105])。
- 常用操作:
append(), pop(), insert(), 切片 [:]。
2. 元组(tuple)
- 存储固定不变的配置参数(如
(250, 0.001) 表示年交易日和手续费)。 - 函数返回多个值(如
return mean, std)。
- 关键点:不可变性保证了数据的安全性,防止意外修改。
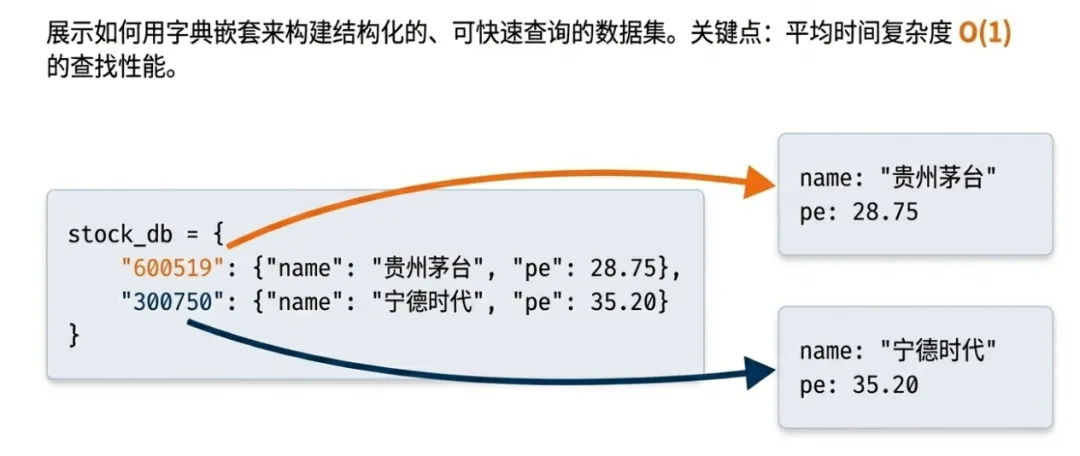
3. 字典(dict)
- 定义:无序的键值对(
key: value)集合,通过键快速访问值。 - 构建股票信息数据库:
stock_db = {"600519": {"name": "贵州茅台", "industry": "白酒", "pe": 28.75},"300750": {"name": "宁德时代", "industry": "电池", "pe": 35.20}}
- 关键点:平均时间复杂度 O(1) 的查找性能,是处理大规模映射关系的首选。
四、内置函数
Python 提供了大量内置函数,可直接用于量化计算:
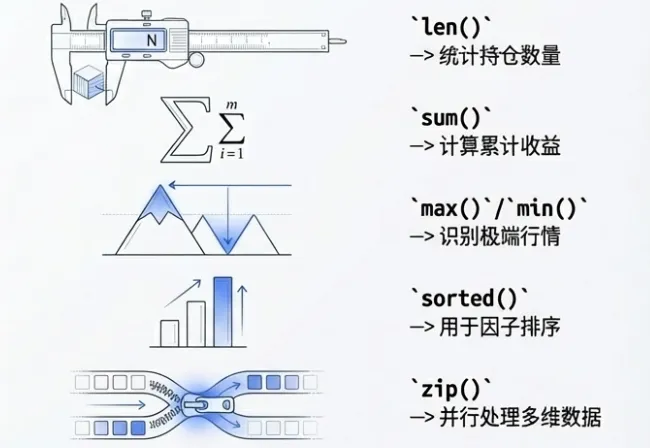
len():返回序列或集合的长度。用于统计持仓数量、数据点个数。sum():计算数值序列的总和。用于计算累计收益、总仓位。max() / min():找出序列中的最大/最小值。用于识别极端行情、计算回撤。sorted():对序列进行排序。用于因子排序、构建多空组合。zip():并行遍历多个序列。用于同时处理价格和成交量等多维数据。enumerate():在遍历时获取索引和值。用于需要位置信息的循环。
这些函数经过高度优化,通常比手动编写的循环更高效、更简洁。
五、面向对象编程(OOP)
当策略复杂度提升,面向对象编程(OOP)成为管理代码的必要手段。
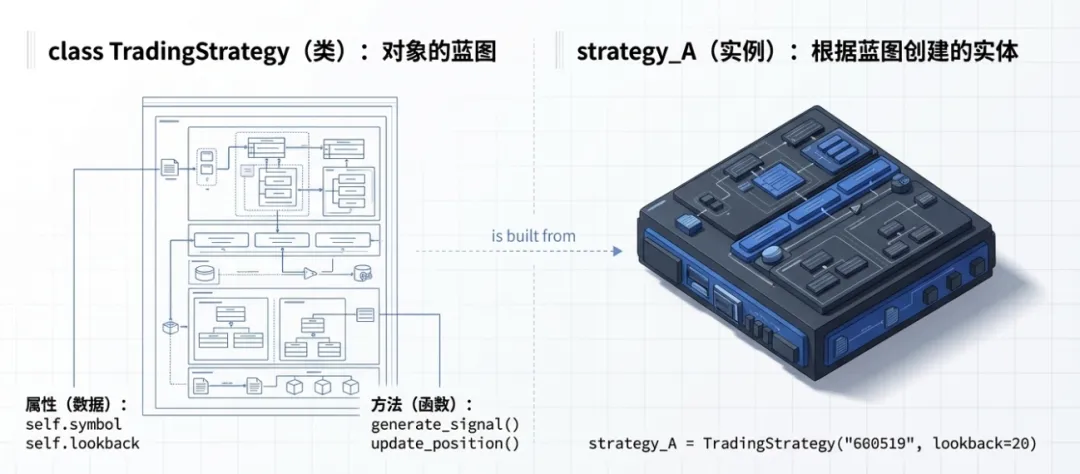
1. 类(class)与实例(instance)
- 类:定义对象的蓝图,包含属性(数据)和方法(函数)。
2. 量化应用示例
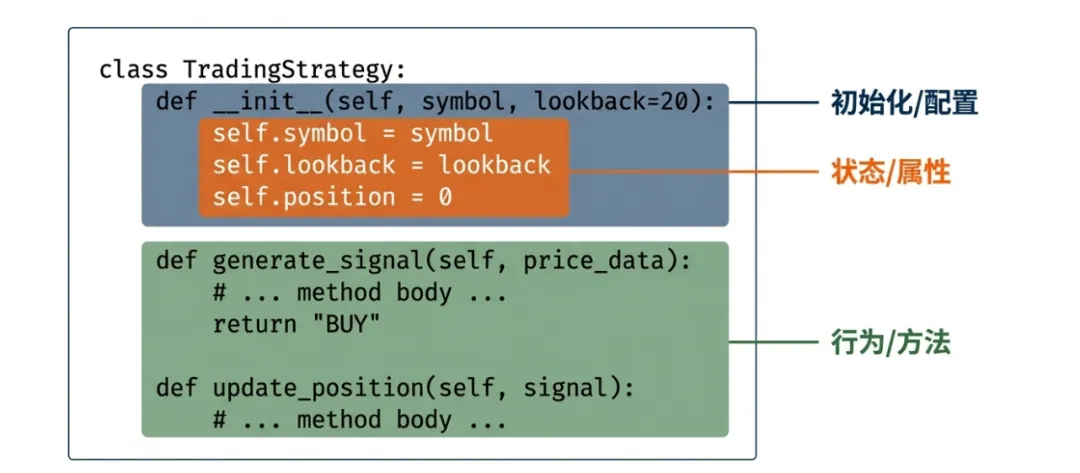
classTradingStrategy:def__init__(self, symbol, lookback=20): self.symbol = symbol self.lookback = lookback self.position = 0defgenerate_signal(self, price_data):"""生成交易信号""" ma = price_data[-self.lookback:].mean()if price_data[-1] > ma and self.position == 0:return"BUY"elif price_data[-1] < ma and self.position == 1:return"SELL"return"HOLD"defupdate_position(self, signal):"""更新持仓状态"""if signal == "BUY": self.position = 1elif signal == "SELL": self.position = 0
3. OOP 的核心优势
- 封装:将数据和操作数据的方法绑定在一起,隐藏内部实现细节。
- 复用:一个策略类可以被实例化多次,用于不同标的或参数。
- 扩展:通过继承机制,可以轻松创建新策略(如
class MeanReversionStrategy(TradingStrategy): ...)。
六、构建你的量化知识体系
本文系统阐述了 Python 在量化交易中的五大核心知识模块:
- 面向对象编程:为构建大型、可维护的量化系统提供了架构支持。
实际上,如果要深入学习,还有非常多的细节可以挖掘,在此,我们仅做一个基础介绍。
掌握这些知识点,你便拥有了将投资想法转化为可执行的量化策略的最基础能力。
下一步,就是将这些知识与金融市场的数据相结合,开启我们的量化实战之旅。