大家好,我是煜道。
今天我们一起来学习 Python组合数据类型——列表、元组、字典与集合。
引言
在处理实际问题时,我们往往需要表示一组相关的数据。例如,一个班级的学生名单、一本字典的单词释义、一个电商平台的商品列表等。Python提供了丰富的组合数据类型来满足这些需求,包括列表(list)、元组(tuple)、字典(dict)和集合(set)。
这些数据类型虽然都是用于存储多个元素,但在特性、用途和性能上各有侧重。
- 列表是最常用的有序可变序列,适用于需要按顺序访问和频繁修改的场景。
- 元组是不可变序列,适合存储不应被修改的数据,如函数的多返回值。
本文将深入分析这四种组合数据类型的特性、实现原理和最佳实践,帮助我们在实际开发中做出正确的选择。
01 序列类型概述
1.1 序列类型的分类
在Python中,列表、元组和字符串都属于序列类型(Sequence)。序列类型可以分为更细的类别:

1.2 序列的通用操作
所有序列类型都支持以下操作:
s = [1, 2, 3, 4, 5]# 索引访问print(s[0]) # 1print(s[-1]) # 5# 切片操作print(s[1:3]) # [2, 3]print(s[::2]) # [1, 3, 5]# 长度print(len(s)) # 5# 成员判断print(3in s) # True# 拼接print(s + [6, 7]) # [1, 2, 3, 4, 5, 6, 7]# 重复print(s * 2) # [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]# 最值print(min(s)) # 1print(max(s)) # 5
02 列表(list)
2.1 列表的创建
列表是最常用的可变序列类型:
# 列表字面值empty = [] # 空列表numbers = [1, 2, 3, 4, 5] # 整数列表mixed = [1, "two", 3.0, True] # 混合类型列表nested = [[1, 2], [3, 4]] # 嵌套列表# 使用构造器创建list() # 空列表list('Python') # ['P', 'y', 't', 'h', 'o', 'n']list((1, 2, 3)) # [1, 2, 3](从元组转换)list(range(5)) # [0, 1, 2, 3, 4]# 列表推导式(重要特性)squares = [x ** 2for x in range(5)]# [0, 1, 4, 9, 16]even_squares = [x ** 2for x in range(10) if x % 2 == 0]# [0, 4, 16, 36, 64]
2.2 列表的增删改查
numbers = [1, 2, 3, 4, 5]# 增numbers.append(6) # 末尾添加:[1, 2, 3, 4, 5, 6]numbers.insert(0, 0) # 指定位置插入:[0, 1, 2, 3, 4, 5, 6]numbers.extend([7, 8, 9]) # 扩展列表:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]# 删numbers.pop() # 末尾删除,返回被删元素numbers.remove(0) # 删除第一个匹配的元素# numbers.clear() # 清空列表# 改numbers[0] = 100# 索引赋值# 查print(numbers[0]) # 访问print(numbers.index(100)) # 查找元素位置print(numbers.count(100)) # 统计出现次数
2.3 列表的排序与反转
numbers = [3, 1, 4, 1, 5, 9, 2, 6]# 原地排序(修改原列表)numbers.sort() # [1, 1, 2, 3, 4, 5, 6, 9]numbers.sort(reverse=True) # 降序numbers.sort(key=abs) # 按绝对值排序# 返回新列表(不修改原列表)sorted_numbers = sorted(numbers)# 反转numbers.reverse() # 原地反转reversed_list = list(reversed(numbers)) # 返回迭代器# 多键排序students = [('Alice', 25), ('Bob', 20), ('Charlie', 25)]students.sort(key=lambda x: (x[1], x[0])) # 按年龄升序,名字升序
2.4 列表的内存模型
列表在Python中是一个动态数组,元素存储在连续的内存空间中:
import sys# 列表的内存占用small_list = [1, 2, 3]print(sys.getsizeof(small_list)) # 88字节(包含空余空间)# 空列表的内存empty = []print(sys.getsizeof(empty)) # 56字节# 列表的存储结构# 列表对象包含:# - 指向元素数组的指针# - 已使用元素数量# - 分配空间大小
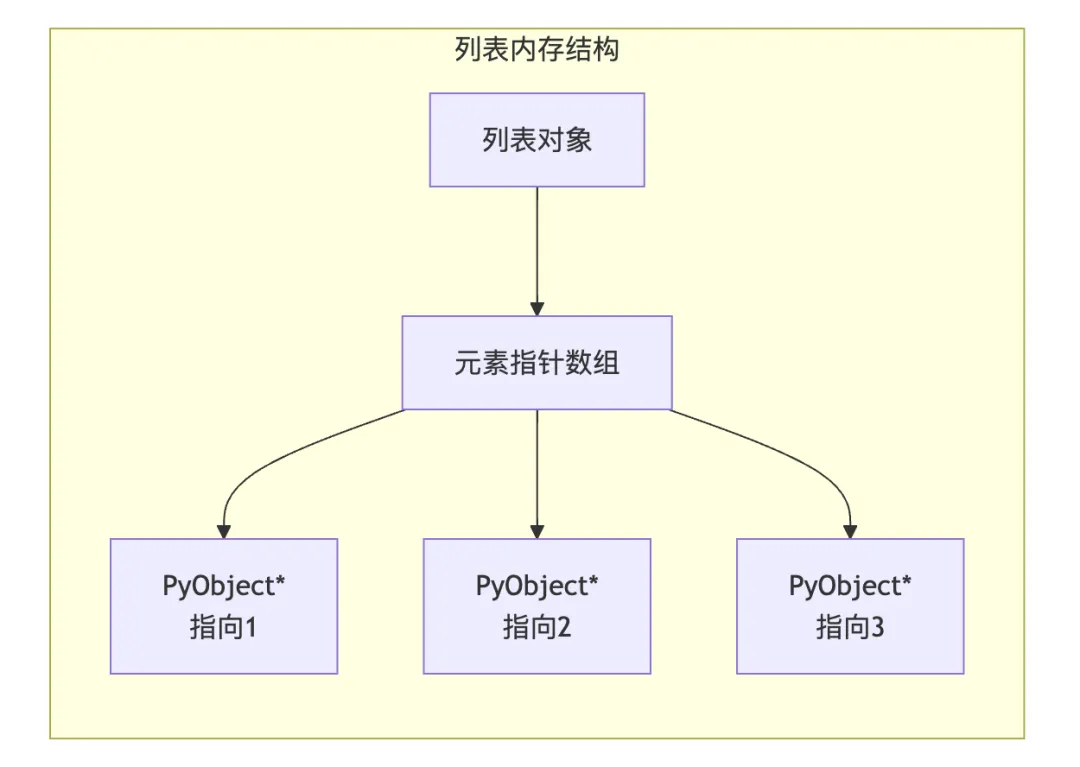
03 元组(tuple)
3.1 元组的创建
元组是不可变序列:
# 基本创建empty = () # 空元组(注意:不是None)single = (42,) # 单元素元组(必须加逗号)numbers = (1, 2, 3, 4, 5) # 多元素元组# 构造器创建tuple() # ()tuple('Python') # ('P', 'y', 't', 'h', 'o', 'n')tuple([1, 2, 3]) # (1, 2, 3)# 打包与解包point = (10, 20)x, y = point # 解包a, b, c = 1, 2, 3# 打包
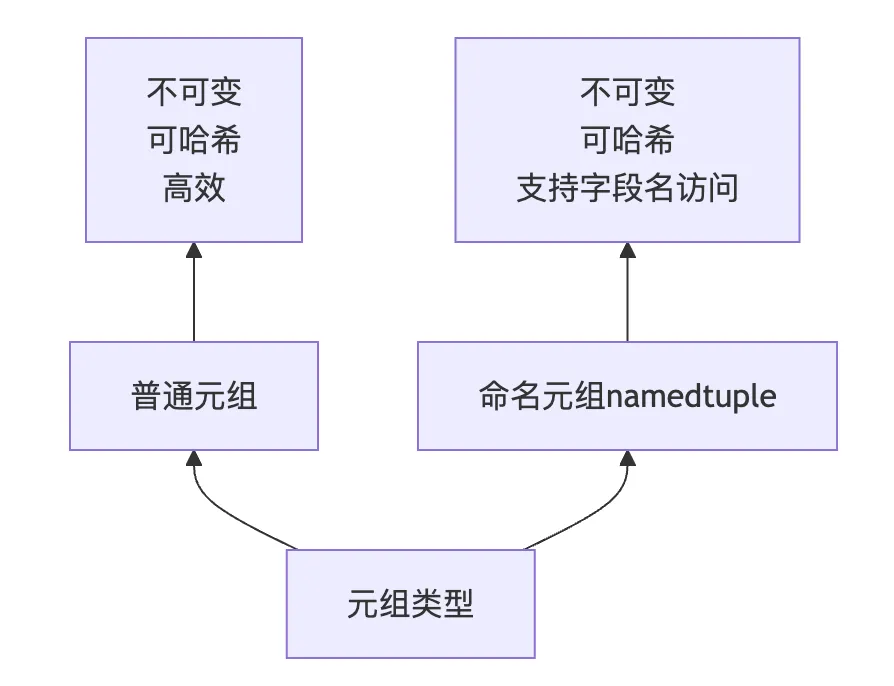
3.2 元组与列表的区别
# 元组作为字典键locations = { (10, 20): "Point A", (30, 40): "Point B"}# 列表不可作为字典键# locations = {[10, 20]: "Point A"} # TypeError
3.3 元组的高级特性
# 命名元组from collections import namedtuplePoint = namedtuple('Point', ['x', 'y'])p = Point(10, 20)print(p.x) # 10print(p.y) # 20print(p[0]) # 10print(isinstance(p, tuple)) # True# 具名元组的方法print(p._fields) # ('x', 'y')print(p._asdict()) # {'x': 10, 'y': 20}
04 字典(dict)
4.1 字典的特性
字典是Python中最重要的映射类型,以键值对形式存储数据:
# 创建字典empty = {} # 空字典person = {'name': 'Alice', 'age': 25} # 键值对dict(a=1, b=2, c=3) # 关键字参数dict([('a', 1), ('b', 2)]) # 键值对序列dict(zip(['a', 'b', 'c'], [1, 2, 3]))# 字典推导式squares = {x: x**2for x in range(5)}# {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
4.2 字典的操作
d = {'name': 'Alice', 'age': 25, 'city': 'Beijing'}# 访问print(d['name']) # 'Alice'(键不存在则KeyError)print(d.get('name')) # 'Alice'print(d.get('gender')) # Noneprint(d.get('gender', 'Unknown')) # 'Unknown'(默认值)# 添加/修改d['gender'] = 'Female'd.update({'job': 'Engineer'})# 删除value = d.pop('age') # 删除并返回del d['city'] # 删除d.clear() # 清空# 遍历for key in d: print(key)for value in d.values(): print(value)for key, value in d.items(): print(f"{key}: {value}")
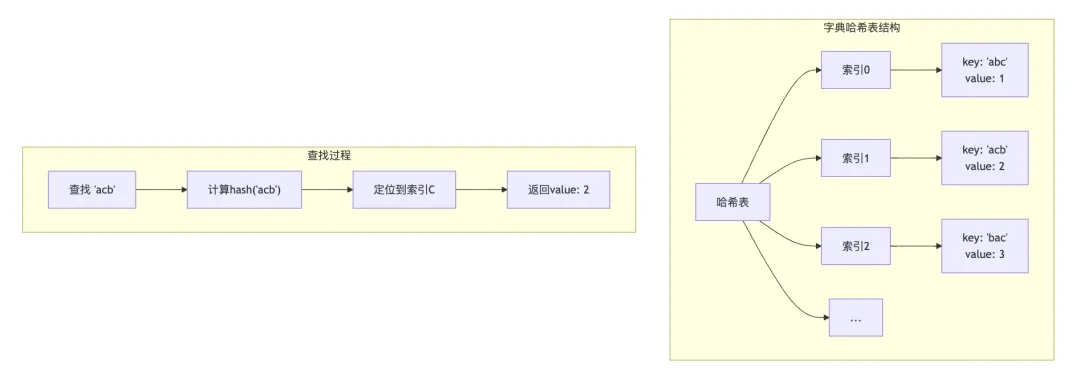
4.3 字典的底层实现
Python字典使用哈希表实现,具有O(1)的平均查找复杂度:
# 字典的键必须是可哈希的# 可哈希 = 支持hash()且不可变hashable = (1, 2, 3) # 元组可哈希# unhashable = [1, 2, 3] # 列表不可哈希# 字典的哈希冲突处理:开放寻址法d = {}d['abc'] = 1d['acb'] = 2d['bac'] = 3
4.4 字典的变体
# OrderedDict(Python 3.7+ dict已保持插入顺序)from collections import OrderedDictod = OrderedDict()od['a'] = 1od['b'] = 2od.move_to_end('a') # 移动到末尾# defaultdictfrom collections import defaultdictdd = defaultdict(list)dd['fruits'].append('apple') # 无需先初始化# Counterfrom collections import Counterc = Counter('abracadabra')# Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
05 集合(set)
5.1 集合的创建与基本操作
集合存储不重复的元素,支持数学集合运算:
# 创建集合empty = set() # 空集合(不能用{},那是空字典)fruits = {'apple', 'banana', 'cherry'}# 集合推导式squares = {x**2for x in range(5)}# {0, 1, 4, 9, 16}# 添加/删除fruits.add('orange')fruits.remove('banana') # 元素不存在则KeyErrorfruits.discard('banana') # 不报错fruits.pop() # 随机删除并返回
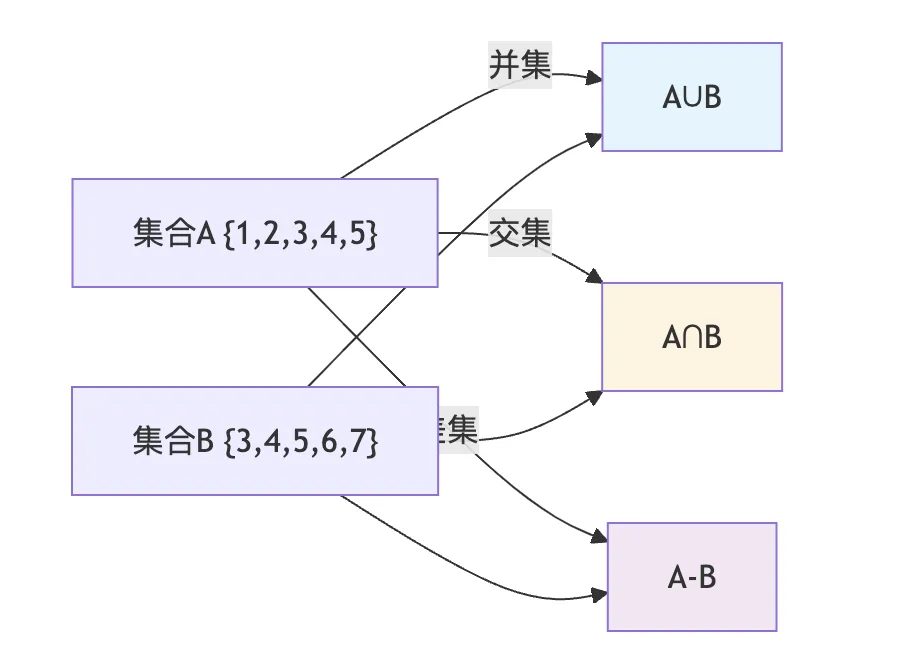
5.2 集合运算
a = {1, 2, 3, 4, 5}b = {3, 4, 5, 6, 7}# 并集print(a | b) # {1, 2, 3, 4, 5, 6, 7}print(a.union(b)) # {1, 2, 3, 4, 5, 6, 7}# 交集print(a & b) # {3, 4, 5}print(a.intersection(b))# 差集print(a - b) # {1, 2}print(a.difference(b))# 对称差集print(a ^ b) # {1, 2, 6, 7}print(a.symmetric_difference(b))# 子集与超集print(a <= b) # Falseprint(a < b) # False(真子集)print(a >= b) # False
5.3 集合的应用场景
# 去重items = [1, 2, 2, 3, 3, 3, 4]unique = list(set(items)) # [1, 2, 3, 4]# 快速成员测试keywords = {'python', 'java', 'c++', 'javascript'}print('python'in keywords) # O(1)查找# 集合操作set1 = {'a', 'b', 'c'}set2 = {'b', 'c', 'd'}print(set1 & set2) # {'b', 'c'}
06 数据类型的选择与性能
6.1 何时使用哪种类型
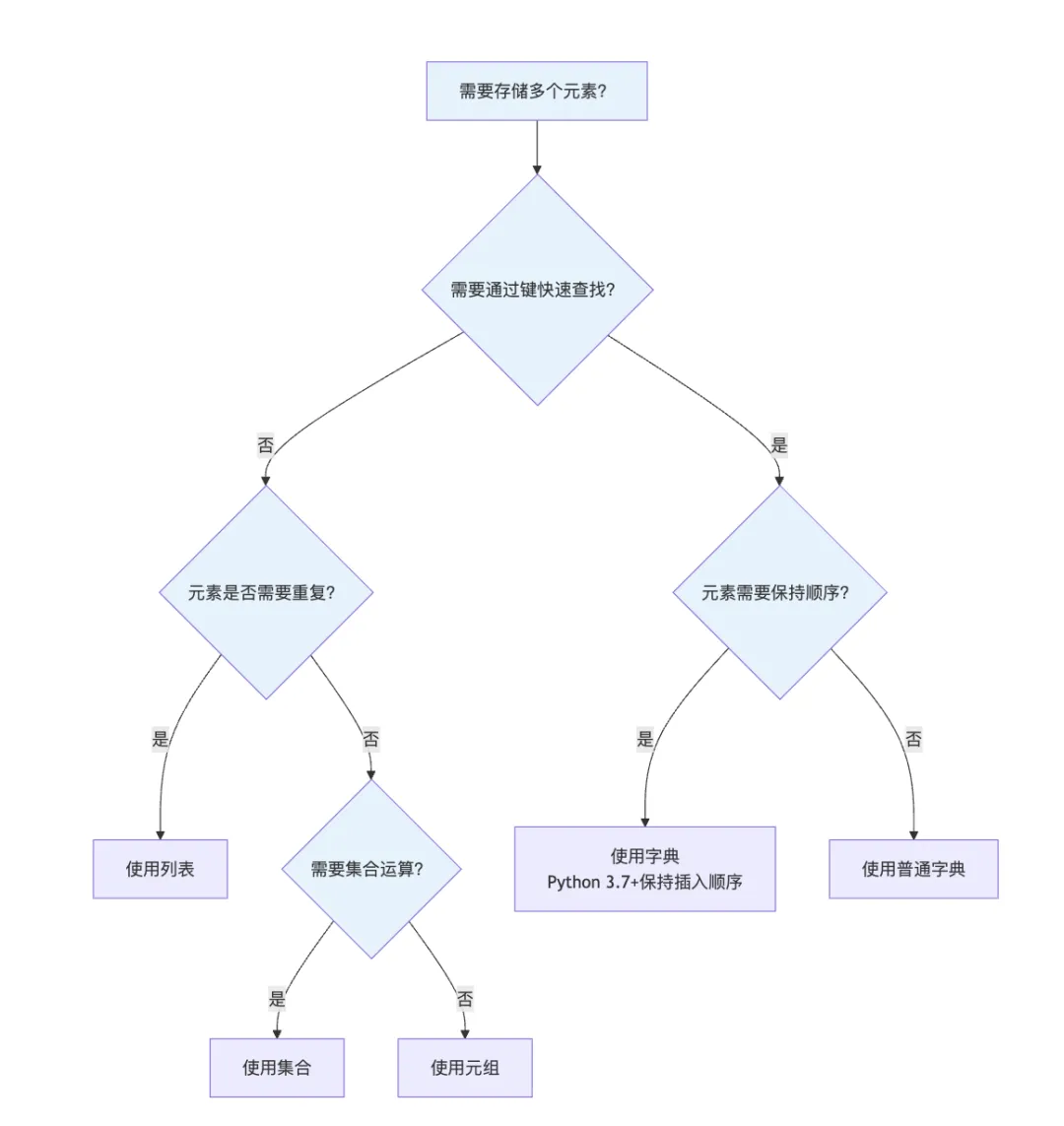
6.2 时间复杂度
*摊还复杂度 **平均复杂度,可能触发rehash
07 实战示例
7.1 统计字符频率
defchar_frequency(text):"""统计字符串中各字符出现的频率""" freq = {}for char in text: freq[char] = freq.get(char, 0) + 1return freq# 使用Counter简化from collections import Counterdefchar_frequency_counter(text):return Counter(text)print(char_frequency("hello world"))# Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
7.2 实现简单的LRU缓存
from collections import OrderedDictclassLRUCache:def__init__(self, capacity): self.capacity = capacity self.cache = OrderedDict()defget(self, key):if key notin self.cache:return-1# 移动到末尾(最近使用) self.cache.move_to_end(key)return self.cache[key]defput(self, key, value):if key in self.cache: self.cache.move_to_end(key) self.cache[key] = valueif len(self.cache) > self.capacity:# 删除最久未使用的项 self.cache.popitem(last=False)
08 小结
本文详细介绍了Python的四种组合数据类型:
- 列表(list):可变序列,支持索引、切片、追加等操作,是最常用的数据结构
- 元组(tuple):不可变序列,性能优于列表,可作为字典键
- 字典(dict):键值对映射,O(1)查找效率,是Python最重要的数据结构之一
- 集合(set):无序不重复元素,支持集合运算,适用于去重和成员测试
理解这些数据类型的特性和适用场景,能够帮助我们在实际开发中做出正确的设计选择,写出高效、优雅的Python代码。


