最近准备收拾收拾过几天回老家, 分享之前写的文章。估计大部分人没看过最近刷文章,经常看到一些博主聊基金套利的科普文章, 这里我也简单聊一聊。 后面重点聊一下基金溢价率抓取方法,并附上代码。很多人买基金,只知道在支付宝、天天基金或者银行APP里“申购”和“赎回”,看着每天的净值涨跌心情起伏。但实际上,有一类特殊的基金,叫做LOF基金(Listed Open-end Fund,上市型开放式基金),它们不仅可以在场外买卖,还能像股票一样在证券交易所进行交易。
正是这种“双重身份”,创造了一个经典的套利空间:同一个东西,两个价格。当这两个价格出现偏差时,就是我们的“捡钱”时刻。
今天,我们就结合集思录的实时数据,手把手教你如何用Python量化思维,去挖掘这些散落在市场中的套利机会。
一、 套利的核心逻辑:买低卖高
LOF基金有两个价格:
- 场内交易价格:你在股票软件里看到的价格,由市场供求决定,实时变动。
- 基金净值(NAV)
套利的本质就是利用这两个价格的差价:
- 溢价套利:当场内价格 > 基金净值时,我们可以按照较低的净值“申购”基金,等份额到账后,再在场内按较高的价格“卖出”,赚取差价。 最近炒作的白银LOF就是这种场景。
- 折价套利:当场内价格 < 基金净值时,我们可以买入场内便宜的基金份额,然后按照较高的净值“赎回”,赚取差价。
听起来很简单对吧?但难点在于:市场上有几百只LOF基金,谁有时间每天盯着看?
这时候,Python就派上用场了。
二、 数据挖矿:从集思录发现“黄金”
我们以集思录的数据源为例,看看真实的市场数据藏着什么秘密。
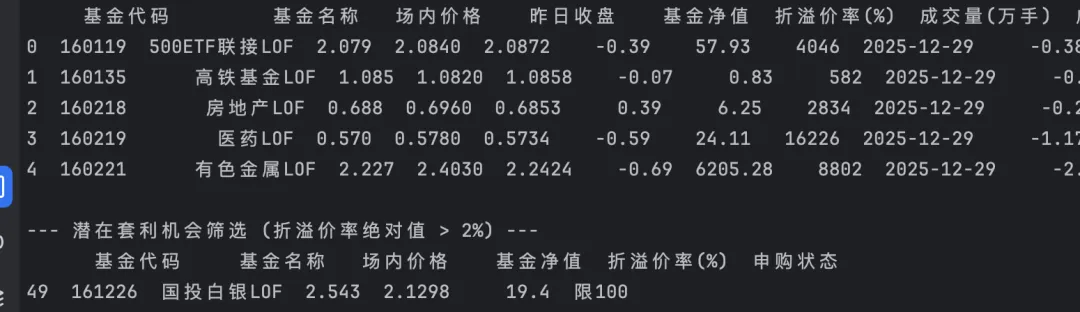
通过抓取集思录的LOF数据接口,我们获得了一份包含基金净值、价格、折溢价率等核心字段的JSON数据。只要稍微分析一下,就能发现有趣的案例:
案例:国投白银LOF (161226)在我们的数据样本中,这只基金出现了惊人的 19.05% 的折价率!
- 场内价格
- 基金净值
- 这意味着,你在场内花2.5元买的基金,实际上只值2元。理论上,如果你买入并立即赎回,瞬间就能获得近20%的收益(当然,这里忽略了赎回费和到账时间)。
数据需要清洗。我们需要通过代码,筛选出折溢价率高 + 申购/赎回费率低 + 成交量大的真正优质标的。
三、 自动化工具:Python抓取实战
为了从海量数据中快速筛选,我们编写一段Python代码。这段代码的核心功能:
- 自动请求:模拟浏览器向集思录发送请求,获取最新的LOF数据。
- 数据清洗:将杂乱的JSON格式数据,转换为清晰的表格,提取出“基金代码”、“折溢价率”、“成交量”、“费率”等核心指标。
- 智能筛选:通过Pandas库,我们可以一行代码就筛选出所有“折溢价率绝对值大于2%”的基金。
- 导出分析:一键生成Excel文件,方便你用肉眼做最后的二次确认。
代码放在最后,需要的自取。
四、 避坑指南:套利不是“无风险”
虽然我们用了Python工具,但必须诚实地告诉你:套利是有成本的,也是有风险的。
在代码分析之外,你还需要手动考量以下几个“致命因素”:
- 费用刺客
找个有免5的证券账户,不然每次交易基金最少5元还是比较高的。LOF申购通常是 T+2 日才能卖出,在这几天里,场内价格可能会回归,导致原本的利润空间被压缩。没有成交量的套利机会就是“镜中花水中月”。一定要选择成交活跃的品种。五、 最后
投资是一场关于信息的博弈。
以前,这些信息差掌握在机构和高阶散户手中;现在,利用Python和公开的数据接口,我们也能构建自己的“量化雷达”。
LOF基金套利,作为一种低风险、中收益的策略,非常适合作为资产配置的辅助手段。它或许不能让你一夜暴富,但这种从数据中挖掘价值、用逻辑战胜市场的过程,正是投资最大的乐趣。
最后附上代码:
import requestsimport pandas as pdimport jsonimport timedef fetch_jisilu_lof_data(): """ 抓取集思录LOF基金数据 """ headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', 'Referer': 'https://www.jisilu.cn/data/lof/', 'Cookie': '' } url = "https://www.jisilu.cn/data/lof/index_lof_list/?___jsl=LST___t=1767011241054&only_owned=&rp=25" try: print(f"正在请求数据: {url} ...") # 3. 发送GET请求 response = requests.get(url, headers=headers, timeout=10) # 4. 判断请求状态 if response.status_code == 200: # 5. 解析JSON数据 json_data = response.json() # 检查是否包含 rows 数据 if 'rows' in json_data: rows = json_data['rows'] print(f"成功获取到 {len(rows)} 条基金数据。") # 6. 数据清洗:提取 'cell' 中的关键字段 clean_list = [] for item in rows: cell = item.get('cell', {}) # 提取套利相关的核心字段 row_data = { '基金代码': cell.get('fund_id'), '基金名称': cell.get('fund_nm'), '场内价格': cell.get('price'), '昨日收盘': cell.get('pre_close'), '基金净值': cell.get('fund_nav'), '折溢价率(%)': cell.get('discount_rt'), # 负数=溢价,正数=折价 '成交量(万手)': cell.get('volume'), '成交额(万)': cell.get('amount'), '净值日期': cell.get('nav_dt'), '指数涨跌幅(%)': cell.get('index_increase_rt'), '申购状态': cell.get('apply_status'), '申购费': cell.get('apply_fee'), '赎回状态': cell.get('redeem_status'), '赎回费': cell.get('redeem_fee'), '基金公司': cell.get('issuer_nm'), '成交量换手率(%)': cell.get('turnover_rt') } clean_list.append(row_data) # 7. 转换为 DataFrame df = pd.DataFrame(clean_list) # 8. 简单的数据类型转换 (便于后续计算) # 将价格、净值、溢折率转为数字类型 numeric_cols = ['场内价格', '基金净值', '折溢价率(%)', '成交量(万手)', '成交额(万)', '指数涨跌幅(%)'] for col in numeric_cols: df[col] = pd.to_numeric(df[col], errors='coerce') return df else: print("返回的数据中未找到 'rows' 字段。") return None else: print(f"请求失败,状态码: {response.status_code}") print(f"响应内容: {response.text[:200]}") return None except Exception as e: print(f"发生错误: {e}") return None# --- 主程序执行 ---if __name__ == "__main__": # 抓取数据 df_lof = fetch_jisilu_lof_data() if df_lof is not None: # 打印前5行预览 print("-" * 50) print("数据预览 (前5行):") print(df_lof.head()) # --- 筛选示例:找出溢价率绝对值大于2%的基金 --- print("\n--- 潜在套利机会筛选 (折溢价率绝对值 > 2%) ---") # 注意:集思录数据中,discount_rt 为负值代表溢价,正值代表折价 target_df = df_lof[df_lof['折溢价率(%)'].abs() > 2.0] print(target_df[['基金代码', '基金名称', '场内价格', '基金净值', '折溢价率(%)', '申购状态']]) # --- 保存到文件 --- filename = 'jisilu_lof_data.xlsx' df_lof.to_excel(filename, index=False, engine='openpyxl') print(f"\n完整数据已保存至: {filename}")
如果我的分享对你投资有所帮助,不吝啬点个关注给个赞👍🏻呗