arxiv:http://arxiv.org/abs/2601.15728
这篇论文《Benchmarking Text-to-Python against Text-to-SQL: The Impact of Explicit Logic and Ambiguity》(Hu 等,2026)通过构建一个名为 BIRD-Python 的新基准,对当前主流的 Text-to-SQL 和新兴的 Text-to-Python 两种范式进行了系统性的对比研究,并提出了一个关键洞见:性能差异的核心并非编程语言本身,而在于用户意图的模糊性与模型是否能获得足够的领域知识。
一、核心问题与动机
背景
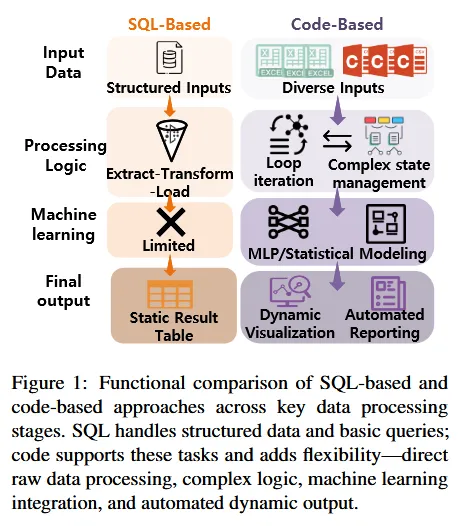
- Text-to-SQL是数据库交互的主流范式,但其局限性在于:
- 数据格式限制:真实世界中的大量数据以CSV、Excel等文件形式存在,而非结构化数据库。
- 表达能力有限:复杂的分析流程(如机器学习、自定义可视化)超出了 SQL 的声明式能力。
- Text-to-Python(特别是使用 Pandas)作为替代方案,因其灵活性和强大的库支持而受到关注,但其在基础数据检索任务上的可靠性尚未得到充分评估。
核心研究问题
Text-to-Python 能否作为一种可靠且灵活的替代方案,取代 Text-to-SQL 进行实际的数据交互?
二、核心贡献
1. 构建 BIRD-Python 基准
- 来源:基于现有的大规模 Text-to-SQL 基准 BIRD。
- 核心工作:
- 数据清洗:发现并修正了BIRD数据集中259个逻辑不一致或过时的标注,建立了一个更可靠的“验证集”。
- 范式转换:将原始的SQL查询精确的重构为Pyhthon/Pandas代码。这不仅仅是语法转换,更重要的是显式地实现SQL引擎隐含的行为(如NULL处理、排序稳定性)。
- 标准化评估:引入了一个LLM-as-a-Judge的语义验证器(Vsem),已解决因输出格式(如列顺序、数据类型)不同而导致的“假阴性”问题,确保评估的是语义等价性而非字面匹配。
2. 提出关键洞见:显式逻辑 vs. 模糊意图
- 根本性差异:
- SQL 是声明式的:用户只需描述“要什么”,DBMS负责“如何做”(如优化执行计划、处理NULL)。这使得SQL对模糊意图有一定的容错性。
- Python 是过程式的:用户必须明确指定“每一步怎么做”。这要求模型对每一个操作细节都有清晰的理解,因此对模糊或未指明的约束极其敏感。
- 核心发现:Text-to-Python的性能劣势主要源于缺失的领域上下文(如“合格率”的具体计算公式),而不是其代码生成能力本身。
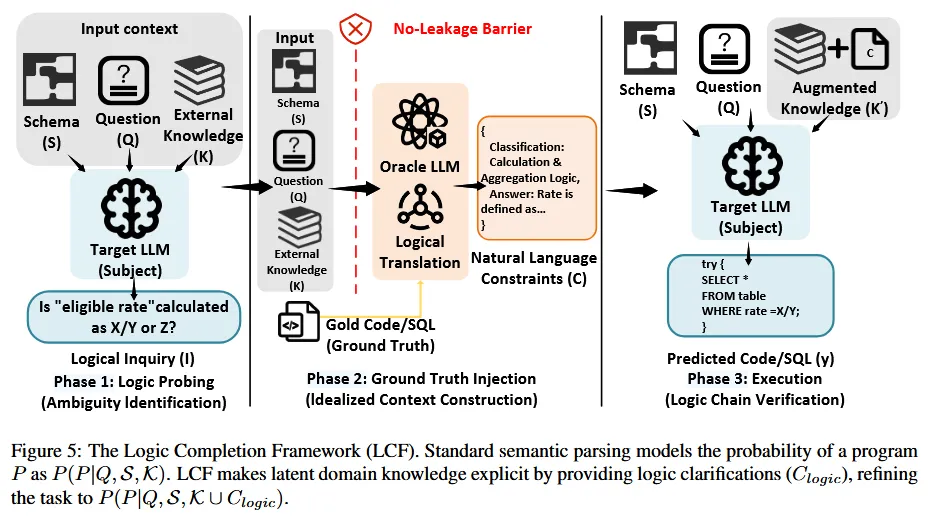
3. 提出逻辑补全框架(Logic Completion Framework, LCF)
为了解决模糊意图问题,作者设计了一个三阶段的交互式框架:
- 逻辑探针(Logic Probing):模型首先分析输入,识别出模糊或不完整的地方,并主动提出澄清问题(例如:“‘合格率’是用 X/Y 还是 Z 计算的?”)。
- 真值注入(Ground Truth Injection):一个“Oracle”(在此实验中是另一个强大的 LLM)根据标准答案,将缺失的逻辑转化为自然语言提示,回答模型的问题。
- 执行(Execution):模型在补充了明确上下文后,再生成最终的代码。
LCF 的作用:它将“因信息不足导致的失败”与“因推理能力不足导致的失败”分离开来,从而更准确地评估模型的真实能力。
三、实验与主要发现
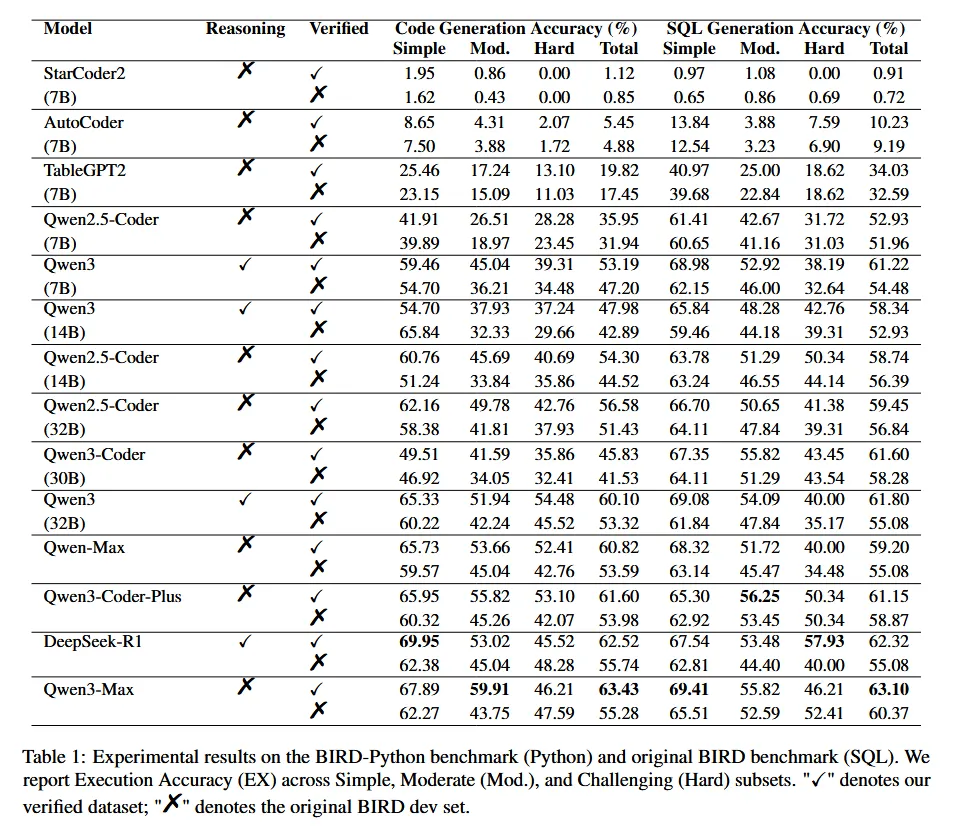
1. 主要结果
- 初始差距:在原始/验证数据集上,Text-to-Python 的性能普遍低于 Text-to-SQL,尤其对于小模型(如 Qwen2.5-Coder 7B: 52.93% → 35.95%)。
- 差距缩小:随着模型规模和推理能力的增强(如 Qwen3-Max, DeepSeek-R1),这一差距显著缩小,甚至在某些情况下反超。
- 数据质量影响:在清洗后的“验证集”上,所有模型的性能都得到了提升,证明了原始数据集中的噪声确实影响了评估的准确性。
2. 错误分析
- 共同挑战:过滤条件错误(Filter Condition Errors)是两大范式最主要的错误来源(~32%),这直接指向了自然语言理解和意图模糊问题。
- 范式特有错误:
- SQL:更多是行/列选择错误(如LIMIT,DISTINST使用不当)。
- Python:显著更高的逻辑错误(Logic Errors: 17.5% vs. SQL 的 0.3%),这印证了过程式编程对显式逻辑的高要求。
3. LCF 实验
- 性能大幅提升:应用 LCF 后,所有模型的性能都急剧提升。例如,Qwen3-7B 在 Python 任务上的准确率从 53.19% 提升至 71.19%。
- 性能差距消失:在 LCF 提供的明确上下文下,Text-to-Python 和 Text-to-SQL 的性能基本持平(如 Qwen3-32B: 72.49% vs. 72.75%)。
- 模型缩放效应显现:在 LCF 条件下,大模型(Qwen3-Max)的优势更加明显,说明它们能更好地利用明确的上下文信息进行推理。
四、总结评价
| |
✅ 首次系统性对比:为 Text-to-Python 在数据检索任务上的能力提供了严谨的评估。 | ❌ 依赖 Oracle:LCF 在实验中依赖于能访问标准答案的 Oracle,在真实场景中可能需要人工介入,增加延迟。 |
✅ 揭示核心瓶颈:清晰地指出性能瓶颈在于上下文缺失,而非范式本身,为未来研究指明了方向。 | ❌ 理想化假设:为公平比较,Text-to-Python 任务被提供了完整的 DDL Schema,这在处理原始、无模式的文件时可能不成立。 |
✅ 提出有效解决方案:LCF 框架不仅是一个评估工具,也为构建更鲁棒的 NLI 系统提供了实用思路。 | ❌ 数据质量:实验主要关注逻辑复杂性,未深入探讨真实世界中常见的脏数据(如类型推断错误)带来的挑战。 |
✅ 高质量数据集:BIRD-Python 的构建过程严谨,为社区提供了一个宝贵的资源。 | |
一句话总结:该论文有力地论证了 Text-to-Python 完全有能力成为 Text-to-SQL 的可靠替代品,但其成功的关键在于解决自然语言固有的模糊性。通过像 LCF 这样的框架来显式地补全缺失的领域知识,可以释放 Python 在数据分析中的全部潜力,为构建更强大、更灵活的分析智能体奠定基础。