相信大家大概率遇到过这种“玄学bug”:单线程跑完全正常,一上多核就数据错乱;本地调试没问题,上线后偶尔崩一次,排查起来抓心挠肝。其实很多时候,罪魁祸首就是「指令乱序」,而内存屏障,就是解决这个问题的“终极武器”。今天咱们从“是什么-为什么-怎么用”三层,把内存屏障彻底讲透!
先给大家抛一个真实开发中高频出现的场景,快速代入感受下内存屏障的必要性:
假设我们做一个简单的生产者-消费者模型,线程A负责写入数据,线程B负责读取,代码逻辑看似毫无问题:
#include<pthread.h>#include<stdio.h>// 共享数据结构typedef struct { int data; int ready; // 标记数据是否就绪} shared_obj;shared_obj obj = {0, 0};// 线程A:生产者,写入数据void *producer(void *arg){ obj.data = 100; // 第一步:写入业务数据 obj.ready = 1; // 第二步:标记数据已就绪 return NULL;}// 线程B:消费者,读取数据void *consumer(void *arg){ // 循环等待数据就绪 while (!obj.ready); // 读取数据并打印 printf("读取到的数据:%d\n", obj.data); return NULL;}intmain(){ pthread_t tid1, tid2; pthread_create(&tid1, NULL, producer, NULL); pthread_create(&tid2, NULL, consumer, NULL); pthread_join(tid1, NULL); pthread_join(tid2, NULL); return 0;}
大家可以先思考下,这段代码会稳定输出100吗?
答案是:单线程跑(比如注释掉一个线程)永远正常,但在多核CPU上运行,偶尔会输出0或者乱码——明明obj.ready已经被设为1了,obj.data却还是初始值0。
这不是代码逻辑错了,而是CPU和编译器的“优化操作”搞的鬼:它们会在不影响单线程逻辑的前提下,打乱无依赖指令的执行顺序,这就是「指令乱序」。而内存屏障,就是用来约束这种乱序、守护指令执行秩序的核心工具。
一、内存屏障是什么?
先给大家一个通俗到能直接记牢的定义:内存屏障就像“交通信号灯”,不禁止所有车辆通行,只约束特定车辆的通行顺序,确保路口两侧的车辆不会乱闯。
专业定义:内存屏障是约束CPU指令执行顺序、阻止编译器指令重排的同步原语,核心作用是保证「屏障两侧的内存操作满足部分有序」——简单说,屏障前的所有操作必须全部完成,才能执行屏障后的操作。
这里要避坑:它不是“禁止所有乱序”,而是“在关键位置强制排序”,平衡性能优化与逻辑正确性——毕竟,完全禁止乱序会让CPU性能暴跌,内存屏障的精髓就是“精准约束”。
1.1 不同场景内存屏障
内存屏障的应用场景,本质和“乱序风险”强绑定,不同场景下的乱序风险不同,屏障的用法也不同,给大家整理了3类高频场景:
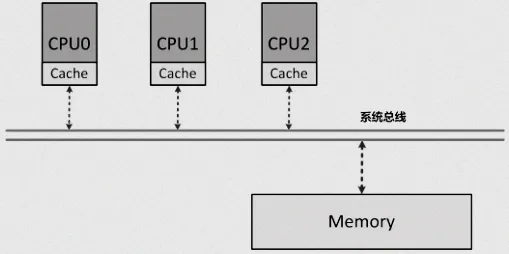
1. 单核vs多核:单核只有编译器乱序,只需用编译器屏障即可;多核还要额外处理CPU乱序和缓存同步问题,必须用硬件内存屏障;
2. 用户态vs内核态:用户态多是简单并发(如普通多线程读写),屏障用法较简单;内核态(如驱动、进程调度)对顺序要求更严格,屏障使用更频繁;
3. 业务场景:无锁编程、设备驱动寄存器操作、共享内存读写,都是内存屏障的高频应用场景,也是面试常考场景。
1.2 内存屏障的核心定位
总结下来,内存屏障解决两大核心问题,也是我们必须学它的原因:一是单处理器的编译器/CPU指令乱序,二是多处理器的内存同步延迟。
对于内核开发者来说,不懂内存屏障,就没法搞定多核并发和设备驱动的隐形bug;哪怕是用户态开发者,写高并发无锁代码时,也迟早要和它打交道——这就是为什么它是必修课。
二、为什么会出现内存屏障?
2.1 内存乱序是怎么出现的?
内存屏障的出现,本质是“性能优化”与“逻辑正确”的矛盾产物,现代CPU和编译器,为了压榨硬件性能,会做各种优化:编译器会重排指令、CPU会乱序执行、缓存会异步同步数据……这些优化在单线程下完全无害,还能大幅提升效率,但到了多核并发场景,就会破坏指令的“逻辑顺序”,引发数据错乱——内存屏障,就是为解决这个矛盾而生的。
举个通俗例子:你让外卖员先送奶茶、再送汉堡,外卖员为了省时间,可能先去取汉堡(顺路),但必须保证奶茶先送到你手上——这就是“优化与顺序的平衡”,内存屏障就是那个“保证顺序”的约定。
2.2 理解内存屏障
很多朋友对内存屏障有个误区:觉得它是“阻止CPU乱序”的工具。其实不是,它的核心逻辑是「建立顺序约束」。
例如:你让朋友先买菜、再做饭,朋友可能为了省时间,先把锅烧上(无依赖操作),但必须等菜买完才能开始炒——内存屏障就相当于“必须等买菜完成,才能做饭”的约束,不限制无关操作,只保证关键顺序。
所以,理解内存屏障的关键,是“识别需要约束的顺序”,而不是盲目加屏障——加少了会出bug,加多了会拖慢性能。
2.3 内存屏障的分类(初步梳理)
按作用范围,内存屏障最核心的分类只有两类,后续所有细分都基于这两种,先记牢这个框架,后面再细化:
1. 编译器屏障:只约束编译器,不让它重排指令,不影响CPU的乱序执行;内核中用barrier()宏实现,实操中常和READ_ONCE/WRITE_ONCE搭配;
2. 硬件内存屏障:既约束编译器,也约束CPU,强制CPU按顺序执行指令,还能处理缓存同步问题;内核中按功能分为读、写、通用三类,后续详细拆解。
后面我们会详细拆解这两类屏障的实现和用法,还会补内核源码和实操代码,这里先记住这个核心分类即可。
三、为什么要有内存屏障?——乱序执行的四大核心根源
搞懂乱序的根源,才能精准判断什么时候需要加内存屏障,避免盲目加屏。其实乱序主要来自四个方面,全是编译器和CPU的“优化操作”,每类都补实操案例和代码:
3.1 编译器优化
编译器(如GCC、Clang)在编译时,会对无显式数据依赖的指令进行重排,目的是提升代码执行效率,这是最基础的乱序根源,给大家上代码实操:
比如下面两句代码,没有数据依赖(x和y互不影响):
在O2及以上优化等级下(开发中常用O2优化),编译器可能会重排成:
单线程下,这两种顺序完全等价;但在多线程中,一旦x和y是共享变量,重排就可能导致其他线程读取到错误的数据——比如线程C读取x和y,可能读到y=1但x未赋值的情况。
编译器屏障的作用,就是阻止编译器做这种“自作主张”的重排,给大家补一段加了编译器屏障的代码,对比效果:
int x, y, r;x = r;barrier(); // 编译器屏障,阻止编译器重排上下两句代码y = 1;
加了barrier()后,编译器不会把x=r和y=1的顺序重排,这就是编译器屏障的核心作用。
3.2 处理器执行时的多发射和乱序优化
现代CPU为了提升吞吐量,采用了「多发射」和「流水线」技术:把一条指令拆分成取指、译码、执行、写回等多个阶段,同时处理多条指令(比如前一条指令在执行时,下一条已经在译码)。
对于无数据依赖的指令,CPU会主动乱序执行——比如先执行耗时短的指令,再执行耗时久的,避免流水线空闲,这也是多核场景下乱序的核心根源之一,用设备驱动的实操案例拆解:
设备驱动中,需要先写寄存器地址,再写数据,代码如下:
#define ADDR_REG 0x1000 // 地址寄存器#define DATA_REG 0x1004 // 数据寄存器// 写数据到指定寄存器地址voidwrite_reg(int data){ *(volatile int *)ADDR_REG = 0x200; // 设置地址 *(volatile int *)DATA_REG = data; // 写入数据}
从代码逻辑看,必须先设置地址,再写入数据,硬件才能正确识别数据要写入的目标位置。但CPU的多发射和乱序优化,可能会打乱这两句指令的执行顺序——比如先执行数据写入,再执行地址设置。
这种乱序会导致严重问题:数据被写入到错误的地址,可能导致设备卡死、数据错乱,甚至烧毁硬件。这也是为什么设备驱动中,硬件内存屏障是“刚需”——必须强制CPU按代码逻辑顺序执行指令。
补充一个关键知识点:这里用volatile修饰指针,是为了避免编译器优化掉寄存器读写操作(确保每次都真实读写硬件寄存器),但它不能阻止CPU乱序——很多新手会混淆volatile和内存屏障,记住:volatile仅约束编译器,不约束CPU,多核场景下仍需加硬件屏障。
那怎么解决CPU乱序的问题?核心就是加硬件写屏障,咱们修改代码如下,添加wmb()硬件屏障,强制地址写入完成后再执行数据写入:
#define ADDR_REG 0x1000 // 地址寄存器#define DATA_REG 0x1004 // 数据寄存器// 写数据到指定寄存器地址(加硬件屏障版)voidwrite_reg(int data){ *(volatile int *)ADDR_REG = 0x200; // 设置地址 wmb(); // 硬件写屏障,约束CPU顺序,强制地址写入先完成 *(volatile int *)DATA_REG = data; // 写入数据}
加了wmb()后,CPU会严格保证:ADDR_REG的写操作完全完成(包括同步到缓存),才会执行DATA_REG的写操作,彻底避免寄存器操作乱序,这就是硬件屏障的核心价值。
3.3 读取和存储指令的优化
除了编译器重排、CPU多发射乱序,CPU对读写指令的专项优化,也会导致内存操作乱序,这部分容易被忽略,咱们拆成“写缓冲”和“读合并”两个高频优化场景,结合代码实操讲解:
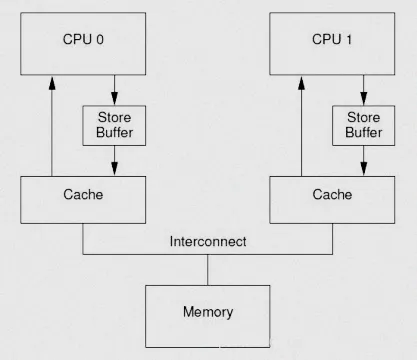
3.3.1 写缓冲优化:写操作的“延迟生效”陷阱
现代CPU都有「写缓冲」(Write Buffer),本质是一块高速临时存储区域。当CPU执行写操作时,不会直接把数据写入主存(主存读写速度慢,会拖慢CPU),而是先写入写缓冲,等写缓冲满了、或者CPU空闲时,再批量同步到主存。
这种优化会导致“写操作延迟生效”,进而引发乱序问题,给大家上一个多核场景的实操案例:
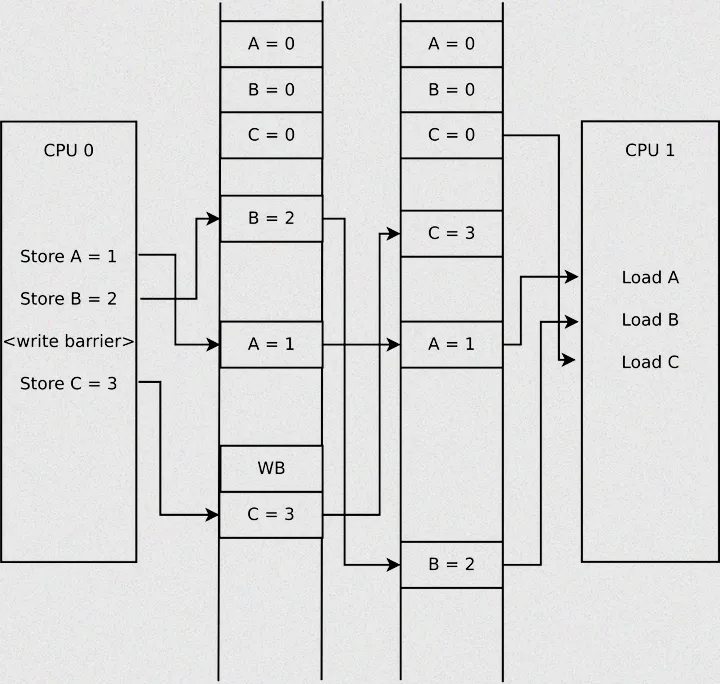
核心A执行两个写操作,核心B执行两个读操作,代码如下:
// 核心A(写操作)int a = 0, b = 0;a = 1; // 写操作1b = 2; // 写操作2// 核心B(读操作)int x = b; // 读操作1int y = a; // 读操作2
按代码逻辑,核心B最多读到x=0、y=0(未同步)或x=2、y=1(正常同步),但实际可能读到x=2、y=0——核心A的b=2先写入写缓冲并同步,a=1还在写缓冲中未同步,导致核心B读到b的新值、a的旧值,出现逻辑乱序。
解决办法:在核心A的两个写操作后加写屏障wmb(),强制写缓冲同步,确保a和b的写操作同时生效;核心B的两个读操作前加读屏障rmb(),确保读取顺序。
3.3.2 读合并优化:读操作的“顺序打乱”问题
CPU对读操作的优化主要是「读合并」(Read Coalescing):当CPU读取多个连续的内存地址时,会把多个读操作合并成一次读取,减少内存访问次数,提升效率,但会打乱读操作的原本顺序。
比如读取连续的4个int变量,代码顺序是读a、读b、读c、读d,CPU可能合并成一次读取,实际读取顺序可能变成a、c、b、d——单线程下无影响,多核场景下,若其他核心同时修改这些变量,就可能读到错乱的组合值。
如果读操作的顺序对业务逻辑至关重要(比如先读配置、再读数据),必须加读屏障rmb(),阻止CPU打乱读顺序。
3.4 缓存同步顺序
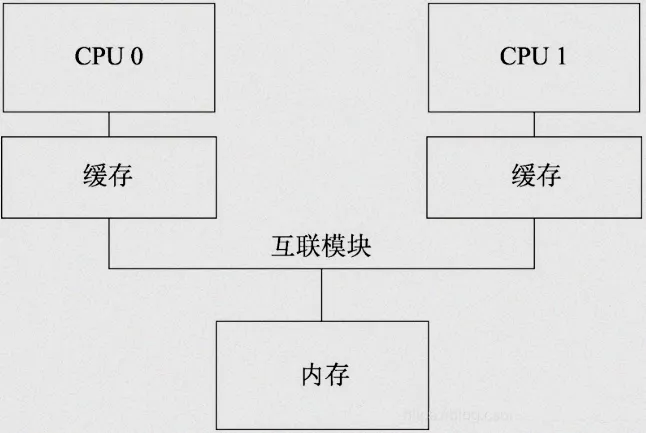
多核CPU中,每个核心都有自己的私有缓存(L1、L2),缓存的存在让内存读写速度提升10倍以上,但也带来了「缓存一致性」问题,这是多核场景下乱序的核心根源之一。
先明确一个核心逻辑:多核架构下,共享变量的修改流程是“核心修改私有缓存→异步同步到主存→其他核心从主存同步到自身缓存”,同步过程是异步的,这就会导致缓存同步顺序错乱。
实操案例:核心A修改两个共享变量,核心B读取这两个变量:
// 共享变量int flag = 0;int count = 0;// 核心Acount = 10; // 步骤1:修改countflag = 1; // 步骤2:修改flag,标记count已更新// 核心Bwhile (!flag); // 等待flag更新printf("count值:%d\n", count); // 读取count
可能出现的问题:核心A修改count后,先同步flag到主存,count还在自身缓存中未同步;核心B读取到flag=1(新值),但读取count时,还是从自身缓存中获取旧值0,导致输出错误。
核心原因:缓存同步是异步的,CPU不会保证多个变量的同步顺序,而内存屏障的核心作用之一,就是「强制缓存同步顺序」——让屏障前的写操作,必须同步到主存(或其他核心的缓存),再执行屏障后的操作。
修改后的代码(加通用屏障):
// 核心Acount = 10;mb(); // 通用屏障,强制count同步完成后,再执行flag的修改flag = 1;// 核心Bwhile (!flag);mb(); // 通用屏障,强制flag读取完成后,再读取countprintf("count值:%d\n", count);
加了mb()后,核心A会保证count的缓存同步完成,再修改flag;核心B会保证flag读取完成(同步新值),再读取count,彻底解决缓存同步顺序问题。
3.5 补充:乱序执行的“底线”
这里给大家划一个关键底线,避免大家过度恐慌、盲目加屏障:CPU和编译器不会无限制乱序,它们会严格遵守「显式数据依赖」——有显式数据依赖的指令,绝对不会被乱序。
实操案例(有显式依赖,不会乱序):
int p = 0x1000;int Q = p; // 步骤1:Q依赖p的值int D = *(int *)Q; // 步骤2:D依赖Q的值
这两句代码有明确的显式依赖:必须先执行Q=p,才能执行D=*(int *)Q,否则Q是未初始化的值,会导致内存访问错误。因此,编译器和CPU都不会打乱这两句的顺序,无需加屏障。
但「隐式依赖」(逻辑上有依赖,代码上无显式依赖),编译器和CPU无法识别,这就是内存屏障要解决的核心场景——比如前面的ready和data,逻辑上data写入后才会置ready,但代码上无显式依赖,就需要加屏障建立顺序。
判断是否需要加屏障,先看是否存在“隐式依赖+多核/编译器优化”,有则考虑,无则无需加。
四、内存一致性模型
理解内存屏障,必须先懂内存一致性模型——它是CPU对内存操作顺序的“约定规则”,直接决定了内存屏障的使用场景和实现方式,新手常忽略这部分,导致屏障用错场景、浪费性能。
内存一致性模型主要分为两类:强内存模型和弱内存模型,咱们结合主流架构(x86、ARM)拆解,附实操注意点:
4.1 强内存模型:“省心型”架构
强内存模型的核心特点:CPU会天然保证大部分内存操作的顺序,除了少数特殊情况(如写缓冲导致的写-读乱序),几乎不需要额外加内存屏障,开发起来更省心。
主流架构:x86、x86_64(我们常用的PC、服务器,大多是x86架构)。
x86强内存模型的约定:
1. 读-读、读-写、写-写操作,天然保证顺序,不会乱序;
2. 仅允许“写-读”乱序(由写缓冲导致,比如前面核心A写a、写b,核心B读b、读a,可能读到b新值、a旧值);
3. 无需显式加rmb()、wmb(),仅在需要解决“写-读”乱序时,加mb()或smp_mb()即可。
x86架构下,很多并发场景可以不用显式加屏障——比如内核的原子操作、自旋锁,已经内置了适配x86的屏障,无需额外处理。
4.2 弱内存模型:“严格型”架构
弱内存模型的核心特点:CPU几乎不保证任何内存操作的顺序,编译器和CPU的乱序更自由,大部分并发场景都需要显式加内存屏障,否则必然出现bug,开发起来更严谨。
主流架构:ARM、PowerPC(嵌入式设备、手机,大多是ARM架构)。
ARM弱内存模型的约定:
1. 不保证任何读写操作的顺序,哪怕是读-读、写-写,也可能乱序;
2. 缓存同步完全异步,必须通过屏障强制同步;
3. 几乎所有并发场景(共享变量读写、寄存器操作、无锁编程),都需要显式加屏障。
做嵌入式内核开发(ARM架构),一定要养成“加屏障”的习惯,哪怕是简单的共享变量读写,也要确认是否需要加屏障——这是嵌入式开发中避免玄学bug的关键。
4.3 核心总结:架构决定屏障用法
一句话记住:架构的内存模型越弱,对内存屏障的依赖越强;反之,强内存模型可以大幅减少屏障的使用,降低性能开销。
五、Linux内核内存屏障的详细类型与实现
Linux内核封装了一套统一的内存屏障接口,屏蔽了不同架构(x86、ARM)的差异,开发者不用关心底层CPU指令,直接调用内核接口即可——这也是内核的核心优势之一,“一次编码,多架构适配”。
下面我们按“作用范围”和“功能”,拆解内核中的内存屏障,每类都补内核源码、实操代码和适用场景,新手可以直接套用。
5.1 按作用范围分:编译器屏障 vs 硬件内存屏障
5.1.1 编译器屏障:只约束编译器,不干预CPU
编译器屏障的核心作用:阻止编译器跨越屏障重排指令,对CPU的乱序执行、缓存同步没有任何约束,仅解决编译器优化导致的乱序问题。
Linux内核中,编译器屏障通过barrier()宏实现,先给大家看内核源码(简化版,来自linux-5.10/include/linux/compiler.h):
#define barrier() __asm__ __volatile__("" ::: "memory")
逐字拆解这个宏,帮大家彻底搞懂,避免死记硬背:
1. asm:嵌入式汇编的关键字,告诉编译器,这段代码包含汇编指令;
2. volatile:告诉编译器,不要优化这段汇编代码,避免编译器把它“优化掉”(如果没有这个关键字,编译器可能认为空汇编没用,直接删除);
3. "":空汇编指令,没有实际执行的CPU操作,仅用于触发编译器的约束;
4. "memory":核心约束,告诉编译器,这段代码会读写内存,编译器不能把屏障前后的内存操作,重排到屏障的另一侧。
5.1.2 编译器屏障的配套工具:READ_ONCE/WRITE_ONCE
除了barrier(),内核还提供了READ_ONCE()和WRITE_ONCE()宏,用于避免编译器对“单个变量”的优化(如变量重排、冗余读取、合并读写),本质是通过volatile特性实现,相当于“单变量的编译器屏障”。
内核源码(简化版):
#define READ_ONCE(x) (*(const volatile typeof(x) *)&(x))#define WRITE_ONCE(x, val) (*(volatile typeof(x) *)&(x)) = (val)
实操场景:单线程修改共享变量,多核读取,仅需要阻止编译器重排时,用READ_ONCE/WRITE_ONCE替代barrier(),更轻量:
// 单线程修改(生产者)WRITE_ONCE(obj.data, 100);WRITE_ONCE(obj.ready, 1);// 多核读取(消费者)while (!READ_ONCE(obj.ready));printf("读取到的数据:%d\n", READ_ONCE(obj.data));
避坑提示:READ_ONCE/WRITE_ONCE仅约束编译器,不约束CPU,多核场景下若有CPU乱序,仍需搭配硬件屏障使用。
5.1.3 硬件内存屏障:约束CPU+隐含编译器屏障功能
硬件内存屏障是功能更强的屏障,核心作用有两个:一是约束CPU的乱序执行,二是强制缓存同步;同时它会隐含编译器屏障的功能——无需额外加barrier(),就能阻止编译器重排。
Linux内核中的硬件内存屏障,按功能分为三类:读屏障、写屏障、通用屏障,分别对应不同的内存操作场景,内核会根据目标架构,自动适配底层CPU指令(如x86的mfence、ARM的DMB)。
5.2 按功能分:读/写/通用屏障的核心差异
5.2.1 读屏障(rmb()):只读操作的“顺序锁”
核心作用:保证屏障前的所有读操作,全部完成(包括缓存同步)后,再执行屏障后的读操作,对写操作无任何约束——仅约束读操作的顺序。
内核接口:rmb(),底层适配逻辑(简化版):
#ifdef CONFIG_X86#define rmb() asm volatile("lfence" ::: "memory") // x86用lfence指令#elif defined CONFIG_ARM#define rmb() dmb(ish) // ARM用DMB指令,ish表示作用于所有核心#endif
适用场景:多线程读取共享数据,需要保证读操作的顺序,比如先读取配置参数,再读取业务数据,避免读到“新配置、旧数据”:
// 读取配置参数int config = READ_ONCE(global_config);rmb(); // 强制配置读取完成,再读业务数据// 读取业务数据int data = READ_ONCE(global_data);
5.2.2 写屏障(wmb()):写操作的“同步阀”
核心作用:强制屏障前的所有写操作,全部完成(并同步到缓存/主存)后,再执行屏障后的写操作,对读操作无任何约束——仅约束写操作的顺序。
内核接口:wmb(),底层适配逻辑(简化版):
#ifdef CONFIG_X86#define wmb() asm volatile("sfence" ::: "memory") // x86用sfence指令#elif defined CONFIG_ARM#define wmb() dmb(ishst) // ARM用DMB指令,ishst表示同步写操作#endif
高频场景:设备驱动寄存器操作(前面讲过的案例)、多线程写入共享变量,需要保证写操作顺序:
#define ADDR_REG 0x1000#define DATA_REG 0x1004voidwrite_reg(int data) { *(volatile int *)ADDR_REG = 0x200; wmb(); // 强制地址写操作完成,再写数据 *(volatile int *)DATA_REG = data;}
5.2.3 通用屏障(mb()):读写全约束的“万能锁”
核心作用:约束所有读写操作的顺序——屏障前的所有读、写操作全部完成后,再执行屏障后的所有读、写操作,是功能最强的硬件内存屏障。
内核接口:mb(),底层适配逻辑(简化版):
#ifdef CONFIG_X86#define mb() asm volatile("mfence" ::: "memory") // x86用mfence指令#elif defined CONFIG_ARM#define mb() dsb(ish) // ARM用DSB指令,比DMB更严格#endif
适用场景:读写混合的并发场景,比如生产者写入数据、消费者读取数据,且双方都有读写操作:
// 生产者(写操作)obj.data = 100;mb(); // 强制数据写入完成,再置readyobj.ready = 1;// 消费者(读操作)while (!obj.ready);mb(); // 强制ready读取完成,再读数据printf("%d", obj.data);
关键提醒:通用屏障的性能开销最大,因为它会完全暂停CPU流水线、强制缓存同步,所以能不用就不用,能用地域性屏障就不用通用屏障——比如仅写操作有序,就用wmb(),别用mb()浪费性能。
5.3 架构差异:x86与ARM的内存屏障实现
前面我们提到,内核会自动适配不同架构的屏障指令,但作为内核开发者,了解底层实现,能更精准地选择屏障类型、优化性能,咱们重点对比x86和ARM的核心差异:
5.3.1 x86架构:强内存模型下的轻量实现
x86采用强内存模型,天然保证读-读、读-写、写-写的顺序,仅允许写-读乱序,因此屏障的实现更轻量,开销更小:
1. rmb():底层用lfence指令,仅约束读操作顺序,开销极小;
2. wmb():底层用sfence指令,仅约束写操作顺序,开销小于mb();
3. mb():底层用mfence指令,约束所有读写操作,是x86中开销最大的屏障;
4. 特殊优化:x86中,很多原子操作(如atomic_inc)、自旋锁(spinlock)会隐含mb()的功能,无需额外加屏障。
实操建议:x86架构下,优先用rmb()/wmb(),仅在解决写-读乱序时用mb(),避免滥用通用屏障。
5.3.2 ARM架构:弱内存模型下的严格约束
ARM采用弱内存模型,几乎不保证任何内存操作顺序,因此屏障的实现更严格,且支持作用域配置(通过屏障指令的参数),灵活适配不同的多核场景。
ARM的核心屏障指令有三类,咱们结合内核用法拆解:
1. DMB(数据内存屏障):
核心作用:保证屏障两侧的数据操作顺序,不等待操作完成,只保证顺序;
内核适配:rmb()、wmb()底层多用电DMB,搭配作用域参数(如ish:所有核心、osh:同一路由域);
适用场景:大多数需要保证顺序,但不需要等待操作完成的场景(如寄存器写操作顺序)。
2. DSB(数据同步屏障):
核心作用:比DMB更严格,不仅保证顺序,还会等待屏障前的所有数据操作全部完成(包括缓存同步、写缓冲刷新),再执行后续操作;
内核适配:mb()底层常用DSB,确保读写操作完全同步;
适用场景:需要确保操作完全完成的场景(如多核信号同步)。
3. ISB(指令同步屏障):
核心作用:刷新CPU指令缓存,保证屏障后的指令重新从内存中读取,适用于指令修改后需要立即生效的场景(如动态修改内核代码、模块加载);
内核适配:内核中用得较少,仅在指令修改场景使用(如kprobes动态探针)。
举个通俗例子:DMB就像“让两辆车按顺序通过路口”,不管它们有没有到达目的地;DSB就像“让第一辆车到达目的地后,第二辆车再出发”——严格保证操作完成。
六、内存屏障的使用规则
内存屏障的使用,核心是“精准”——用对了能解决玄学bug,用错了会导致性能暴跌,甚至还是有bug。结合前面的理论和实操,给大家总结4条核心使用规则:
6.1 规则1:按需选择屏障类型,不滥用通用屏障
核心原则:“最小粒度约束”——能用地域性屏障(rmb()、wmb()),就不用通用屏障(mb());能不用屏障,就不用。
实操对比(避坑案例):
错误用法:所有场景都用mb(),哪怕只是写操作顺序约束,导致性能开销翻倍;
正确用法:读操作场景用rmb(),写操作场景用wmb(),读写混合场景才考虑mb()。
6.2 规则2:贴合架构特性,适配强/弱内存模型
不同架构的内存模型不同,屏障的用法也不同,这是新手最容易踩的坑,给大家整理了实操对照表(直接套用):
1. x86(强内存模型):
无需显式加rmb()、wmb(),仅解决写-读乱序时用mb()/smp_mb();
优先复用内核同步原语(原子操作、自旋锁),避免手动加屏障。
2. ARM(弱内存模型):
所有并发场景(共享变量读写、寄存器操作),都需显式加屏障;
按场景选择DMB/DSB,避免滥用DSB(开销大)。
6.3 规则3:区分单核与多核,减少冗余屏障
1. 单核系统:仅存在编译器乱序,无需用硬件屏障(rmb()/wmb()/mb()),只用编译器屏障(barrier()、READ_ONCE/WRITE_ONCE)即可;
2. 多核系统:需同时考虑编译器乱序和CPU乱序,优先用硬件屏障,且推荐用smp系列屏障(smp_rmb()、smp_wmb()、smp_mb())——这类屏障在单核系统中为空宏,多核系统中等价于对应的硬件屏障,兼顾兼容性与性能。
实操代码(多核专用屏障):
// 多核场景:生产者-消费者obj.data = 100;smp_wmb(); // 多核生效,单核为空,不浪费性能obj.ready = 1;while (!obj.ready);smp_rmb();printf("%d", obj.data);
6.4 规则4:优先复用内核高级同步原语
内核提供的原子操作(atomic_t)、RCU、自旋锁、互斥锁等同步原语,已经内置了对应的内存屏障,无需额外手动加屏障——这是最安全、最高效的用法,新手优先选择。
实操案例(内置屏障,无需额外加):
// 原子操作:内置屏障,无需加mb()atomic_t count = ATOMIC_INIT(0);atomic_inc(&count); // 内置屏障,保证操作顺序// 自旋锁:加锁/解锁时内置屏障spinlock_t lock;spin_lock_init(&lock);spin_lock(&lock); // 加锁,内置屏障// 临界区操作spin_unlock(&lock); // 解锁,内置屏障
不要在已用同步原语的临界区,额外加屏障——比如自旋锁临界区内,无需再加mb(),否则会增加冗余开销。
七、实战:内存屏障在内核开发中的典型应用
理论讲完,结合三个高频实战场景,帮大家落地内存屏障的用法——这三个场景,是内核开发中最容易遇到的,也是面试常考的。
7.1 设备驱动开发:硬件寄存器操作的“保命符”
设备驱动中,寄存器操作(地址、数据、控制寄存器)有严格的先后顺序,一旦乱序,就会导致硬件操作失败、设备卡死,甚至烧毁硬件——内存屏障是这里的“刚需”。
以I2C驱动(嵌入式高频场景)为例,拆解屏障的用法:I2C通信中,需要先配置控制寄存器(开启I2C),再写入数据寄存器(发送数据),最后读取状态寄存器(判断是否发送成功),代码如下:
#define I2C_CTRL_REG 0x1000 // 控制寄存器#define I2C_DATA_REG 0x1004 // 数据寄存器#define I2C_STATUS_REG 0x1008 // 状态寄存器#define I2C_EN 0x01 // 开启I2C的位// I2C发送数据函数inti2c_send_data(int data){ // 1. 配置控制寄存器,开启I2C *(volatile int *)I2C_CTRL_REG = I2C_EN; wmb(); // 强制控制寄存器配置完成,再执行后续操作 // 2. 写入发送数据 *(volatile int *)I2C_DATA_REG = data; wmb(); // 强制数据写入完成,再读取状态 // 3. 读取状态寄存器,判断是否发送成功 int status = *(volatile int *)I2C_STATUS_REG; if (status & 0x02) { // 0x02表示发送成功 return 0; } return -1;}
这里的两个wmb(),分别约束“控制寄存器配置→数据写入”“数据写入→状态读取”的顺序,避免CPU乱序导致的通信失败;同时用volatile修饰寄存器指针,避免编译器优化掉读写操作。
7.2 无锁数据结构:高性能并发的“核心支撑”
无锁编程(Lock-Free)的核心优势是高性能——避免锁的上下文切换开销,适合高并发场景(如内核网络、消息队列),而内存屏障是无锁编程的“基石”——没有屏障,无锁数据结构必然出现数据错乱。
无锁环形缓冲区是多核并发中最常用的无锁组件,我们以它为例,完整实现一个带内存屏障的无锁环形缓冲区,新手可以直接套用。
7.2.1 利用内存屏障实现无锁环形缓冲区
无锁环形缓冲区采用生产者-消费者模型,核心逻辑:生产者写入数据后更新写指针,消费者读取写指针后读取数据,靠内存屏障保证顺序,无需加锁。
完整实操代码(适配x86/ARM多核,内核态可用):
#include<linux/types.h>#include<linux/compiler.h>#include<linux/smp.h>#define BUF_SIZE 1024 // 缓冲区大小// 无锁环形缓冲区结构typedef struct { int buf[BUF_SIZE]; int prod_idx; // 生产者指针(下一个写入位置) int cons_idx; // 消费者指针(下一个读取位置)} lock_free_ringbuf;// 初始化缓冲区voidringbuf_init(lock_free_ringbuf *rb){ rb->prod_idx = 0; rb->cons_idx = 0;}// 生产者写入数据(返回0成功,-1缓冲区满)intringbuf_produce(lock_free_ringbuf *rb, int data){ int next_prod = (rb->prod_idx + 1) % BUF_SIZE; // 判断缓冲区是否满(避免覆盖未读取的数据) if (next_prod == READ_ONCE(rb->cons_idx)) { return -1; } // 写入数据 rb->buf[rb->prod_idx] = data; smp_wmb(); // 多核写屏障:强制数据写入完成,再更新写指针 // 更新写指针 WRITE_ONCE(rb->prod_idx, next_prod); return 0;}// 消费者读取数据(返回0成功,-1缓冲区空)intringbuf_consume(lock_free_ringbuf *rb, int *data){ // 判断缓冲区是否空 if (READ_ONCE(rb->prod_idx) == rb->cons_idx) { return -1; } // 读取数据 *data = rb->buf[rb->cons_idx]; smp_wmb(); // 多核写屏障:强制数据读取完成,再更新读指针 // 更新读指针 WRITE_ONCE(rb->cons_idx, (rb->cons_idx + 1) % BUF_SIZE); return 0;}
核心屏障解读:
1. 生产者侧:smp_wmb()保证“数据写入→写指针更新”的顺序,避免消费者读到“写指针已更新,但数据未写入”的错误;
2. 消费者侧:smp_wmb()保证“数据读取→读指针更新”的顺序,避免生产者覆盖未读取的数据;
3. READ_ONCE/WRITE_ONCE:避免编译器优化指针读取/更新,搭配smp系列屏障,适配单核/多核场景。
7.3 多核同步场景:替代锁机制的“轻量方案”
在多核系统中,对于简单的同步场景(如共享变量的读写同步、核心间信号通知),可以用内存屏障替代自旋锁、互斥锁等重量级同步机制,降低上下文切换开销,提升系统吞吐量。
以“多核核心间信号同步”为例,核心A发送信号,核心B等待信号,用内存屏障实现轻量同步,代码如下:
#include<linux/smp.h>#include<linux/cpu.h>volatile int signal = 0; // 同步信号量// 核心A:发送信号(假设绑定在CPU0)voidcore_a_send_signal(void){ signal = 1; // 设置信号量 smp_mb(); // 多核通用屏障:强制信号量同步到所有核心}// 核心B:等待信号(假设绑定在CPU1)voidcore_b_wait_signal(void){ // 循环等待信号,cpu_relax()让出CPU,减少空转开销 while (!READ_ONCE(signal)) { cpu_relax(); } smp_mb(); // 强制信号量读取完成,再执行后续操作 // 信号处理逻辑 pr_info("核心B收到信号,开始执行操作\n");}
关键解读:
1. smp_mb():仅在多核系统中生效,等价于mb(),强制信号量同步;单核系统中为空宏,不浪费性能;
2. READ_ONCE:避免编译器优化signal的读取,确保每次都从内存中读取最新值;
3. cpu_relax():内核提供的轻量接口,让CPU让出执行权,减少空转带来的性能开销,适合循环等待场景。
适用场景:简单的多核同步,无需复杂的临界区保护,用内存屏障替代锁,性能提升明显。
7.4 什么时候需要注意考虑内存屏障?
5个高频场景,只要遇到其中一个,就需要考虑加内存屏障:
1. 多核系统中,共享变量的读写同步(无锁场景);
2. 设备驱动中,寄存器的先后操作(地址、数据、控制寄存器);
3. 无锁数据结构的实现(环形缓冲区、无锁栈/队列);
4. 编译器优化等级为O2及以上(开发中常用,容易出现指令重排);
5. 弱内存模型架构(ARM、PowerPC)的开发(几乎所有并发场景都需要)。
八、内存屏障的优化方法
内存屏障会带来性能开销——暂停CPU流水线、触发缓存同步、刷新写缓冲,尤其是频繁使用时,会导致系统吞吐量下降。因此,优化内存屏障的核心,是“减少屏障数量、选择合适的屏障类型”,兼顾正确性与性能。
8.1 硬件上的优化
硬件层面的优化,主要依赖CPU架构的原生特性,可针对性适配,无需修改代码逻辑,重点关注3点:
1. 利用强内存模型架构:优先在x86架构下开发,减少屏障的使用,降低开销——x86天然保证大部分操作顺序,无需显式加屏障;
2. 选择高效的屏障指令:比如ARM下,优先用DMB(轻量),而非DSB(重量级),仅在需要确保操作完成时用DSB;x86下,优先用lfence/sfence,而非mfence;
3. 缓存优化:减少共享变量的频繁读写,降低缓存同步压力——缓存同步是屏障开销的核心来源,减少共享变量修改,可间接减少屏障的开销。
8.2 软件上的优化
软件层面的优化,核心有4点:
1. 精准选择屏障类型:读场景用rmb(),写场景用wmb(),拒绝滥用mb()——比如仅写操作顺序约束,用wmb()比mb()节省50%以上的开销;
2. 复用内核高级同步原语:原子操作、RCU、自旋锁等已内置屏障,无需额外加屏障——比如用atomic_t替代普通共享变量,既保证同步,又避免手动加屏障;
3. 减少屏障数量:合并相邻的内存操作,共用一个屏障——比如多个连续的写操作,可在最后加一个wmb(),而非每个写操作后都加,减少屏障调用次数;
4. 适配编译优化:O2及以上优化才需要考虑编译器屏障,O0优化(无优化)可省略barrier()、READ_ONCE/WRITE_ONCE——开发调试时用O0,上线时用O2,兼顾调试效率与性能。
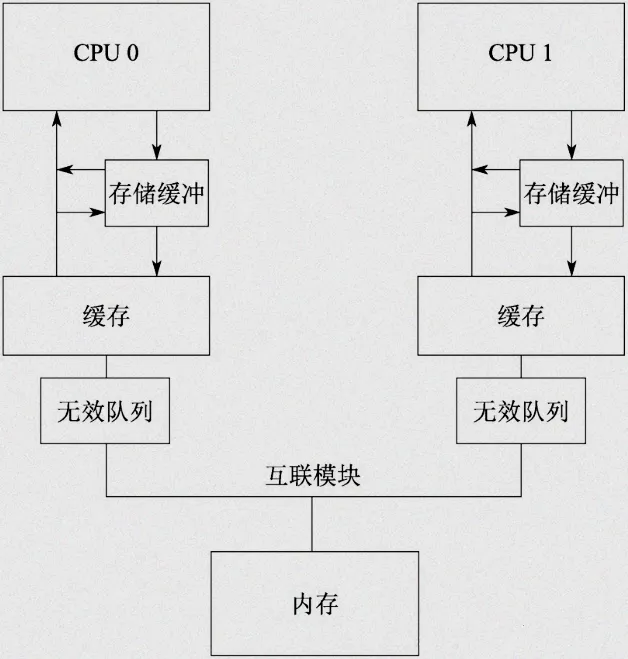
8.3 Invalidate Queues(无效队列)优化
Invalidate Queues(无效队列)是CPU处理缓存同步的一种优化机制,核心作用是“批量处理缓存无效操作”,减少内存屏障触发的缓存同步开销,无需手动操作,只需了解其原理并适配。
当一个核心修改了共享变量,需要通知其他核心“缓存失效”(重新从主存读取数据),这些失效通知会被存入无效队列,CPU会批量处理队列中的通知,而非逐个处理——这就减少了频繁触发缓存同步的开销,间接降低内存屏障的执行成本。
减少共享变量的频繁修改,避免无效队列被频繁触发——比如将多个共享变量合并成一个结构体,批量修改,减少缓存失效通知的次数,优化无效队列的处理效率。
给大家一个口诀,轻松记住内存屏障的核心,面试时被问到,直接套用:“屏障前后分先后,读写分类选对路,多核架构看场景,性能权衡是关键”。
内存屏障看似复杂,但只要抓住“乱序根源”和“场景适配”两个核心,就能灵活运用。