💡阅读提示:本文约10000字,预计阅读时间15分钟。建议先收藏,再慢慢消化。
80%开发者在用AI编程工具,但只有29%真正信任它。在这场席卷全球的代码革命中,我们正在见证人机协作的新范式——从”手写代码”到”对话编程”,从单一工具到智能体生态,AI正在重新定义”编程”这件事本身。
一:Vibe Coding:2025年度词汇背后的编程革命
从”Hello World”到”Tell Me What You Want”
2025年11月6日,柯林斯词典官方宣布:“Vibe Coding”当选年度词汇。这个由特斯拉AI总监Andrej Karpathy创造的术语,在短短数月内从硅谷的技术黑话,演变成了全球开发者社区的共识语言。
这是编程范式的根本性转变:从”我告诉计算机怎么做”到”我告诉计算机我想要什么”。
引发争论
Andrej Karpathy在2024年首次提出这个概念时,他的核心洞察是:编程的本质正在从”精确指令”转向”意图表达”。开发者不再是代码的”工匠”,而更像是AI的”产品经理”——你需要清晰地表达需求,评估AI生成的方案,并进行必要的调整。
但这个观点迅速引发了争议。斯坦福大学教授、Coursera联合创始人Andrew Ng公开批评:“Vibe Coding是对编程的简化和误导。真正的软件工程需要深入理解系统架构、算法复杂度和边界条件,而不是简单地’按感觉’生成代码。”
这场争论的核心在于:AI编程工具究竟是在赋能开发者,还是在降低编程门槛的同时也降低了代码质量?
真实案例:从3个月到3周
GitHub上一位开发者分享了他的经历:
“我用了3个月的时间,用传统方式开发了一个电商后台管理系统,5万行代码。后来我尝试用Claude Code重新做一遍类似的项目,只用了3周。但问题在于:第一个项目我闭着眼睛都知道每个模块在哪里,第二个项目我需要花时间理解AI生成的代码结构。”
这个案例揭示了Vibe Coding的双重性:
✅效率革命:开发速度提升10倍
⚠️认知挑战:开发者与代码之间的”距离感”
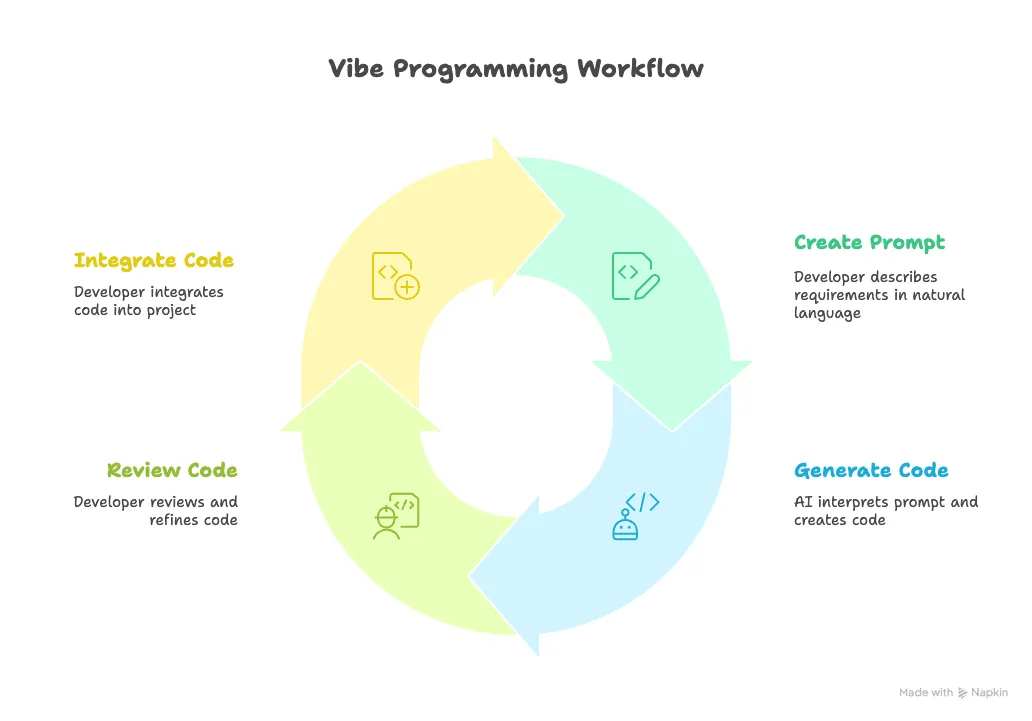
Vibe Coding的本质定义
Vibe Coding是一种以自然语言交互为核心的编程范式,开发者通过描述意图、反馈结果、迭代优化的循环,与AI协作完成代码生成、调试和优化的全流程。它不是替代传统编程,而是在”知道怎么做”和”描述想要什么”之间建立了新的协作模式。
二:信任悖论:80%在用,29%敢信
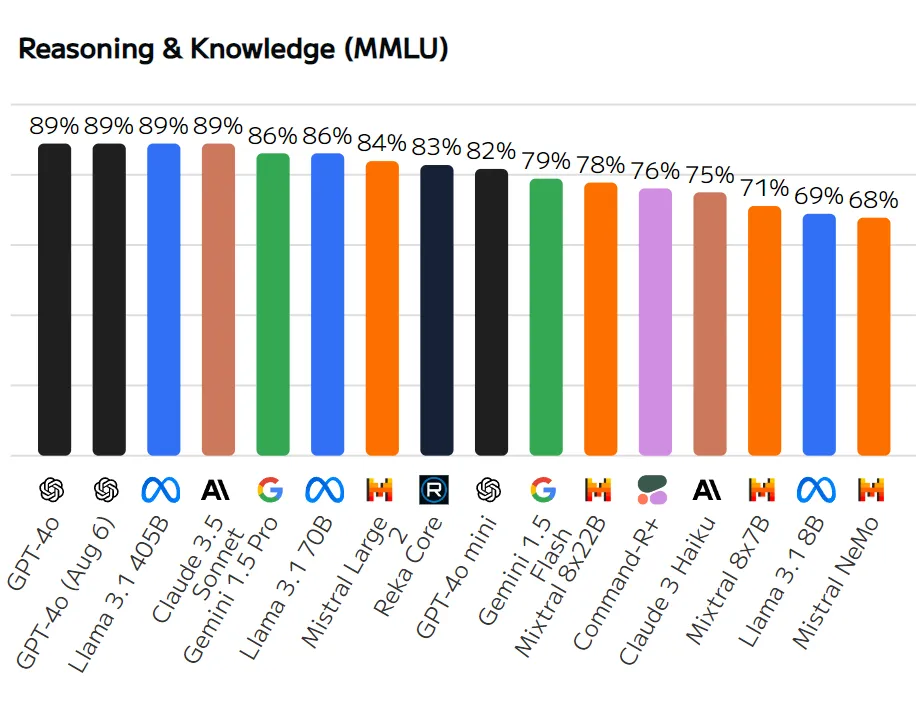
Stack Overflow 2025调查:数据背后的真相
Stack Overflow在2025年发布的开发者调查报告揭示了一个矛盾的现象:
关键发现:
66%调试超时的深层原因
为什么开发者使用AI工具反而花更多时间调试?深入分析发现了几个关键因素:
1.“银弹幻觉”陷阱
很多开发者期待AI能”一键解决所有问题”,但现实是:AI擅长生成符合语法规则的代码,但在以下方面仍有明显短板:
2.“几乎正确但不完全正确”的代码陷阱
这是最具迷惑性的问题。AI生成的代码往往:
✅ 语法正确
✅ 逻辑看起来合理
✅ 简单测试能通过
❌但在实际生产环境中会出现各种问题
一位资深后端工程师分享:“AI生成的数据库查询代码,在100条记录时运行良好,但当数据量达到10万条时,性能直接崩溃。因为AI没有考虑索引优化和分页查询。”
3. 初级开发者vs资深开发者的不同困境
初级开发者的困境:- 缺乏判断AI输出质量的能力- 容易被AI”看起来正确”的代码欺骗- 遇到问题时不知道如何调试
资深开发者的困境:- 需要花时间理解AI的代码逻辑- AI的代码风格可能与团队规范不一致- 在review AI代码时反而比自己写更费时
GitClear研究:代码质量下降趋势
GitClear对数百万个代码提交进行分析后发现:
代码复用率下降21%:开发者更倾向于让AI重新生成,而不是复用现有代码
代码变更频率提高18%:AI生成的代码更容易在后续被修改
平均代码寿命缩短15%:AI代码被重写的速度更快
这些数据指向一个残酷的事实:AI工具在提高短期开发效率的同时,可能正在降低长期代码质量和可维护性。
Sonar调查:96%认为不够准确,48%不检查
更令人震惊的是Sonar的一项调查:
96%的开发者认为AI生成的代码”不够准确”
但其中48%的人不会仔细检查就直接使用
这揭示了一个危险的倾向:开发者既不信任AI,又依赖AI,同时又不愿意花时间验证AI的输出。
三:工具生态全景:从Cline到Claude Code
VSCode + Cline:29.7K Star的开源明星
Cline(原名Claude Dev)是GitHub上最受欢迎的AI编程助手之一,截至2026年1月已获得29.7K星标,它有着以下核心特性。
1. MCP协议支持
Cline是首批支持Anthropic发布的Model Context Protocol(MCP)标准的工具之一。MCP允许AI模型通过标准化接口访问本地文件系统、数据库、API等资源,实现真正的系统级编程。
2. 多模型支持
Cline最大的优势是模型无关性——你可以随时切换。
3. 使用体验
一位全栈开发者的评价:“Cline最大的价值不是’写代码’,而是’理解上下文’。它能记住项目的整体架构,知道你之前改了什么,下一步该改哪里。这种’记忆’是单纯的代码补全工具做不到的。”
适用场景
✅ 中小型项目的快速原型开发
✅ 遗留代码的重构和优化
✅ 跨文件的复杂逻辑修改
❌ 大型企业级项目的严格规范开发
Claude Code:终端原生的极简主义
Anthropic在2024年12月发布的Claude Code选择了一条截然不同的路线:放弃GUI,拥抱终端。
为何选择终端而非GUI?
Anthropic的产品团队给出的理由:
AI变成工具对比分析如下:
工具 | 核心优势 | 主要缺陷 | 适用人群 |
Cursor | AI预测式编辑,流畅的编码体验 | 对模型选择限制较多 | 追求效率的个人开发者 |
GitHub Copilot | 与GitHub生态深度整合 | 单次建议质量不如Claude | 大型企业团队 |
Windsurf | 多Agent协同编程 | 学习曲线陡峭 | 复杂架构的全栈项目 |
选择指南:根据项目类型匹配工具
项目类型决定工具选择:
前端UI密集型项目→ Cursor(实时预览能力强)
后端API开发→ Claude Code(系统操作能力强)
全栈快速原型→ Cline(多模型灵活切换)
企业级大型项目→ GitHub Copilot(团队协作功能完善)
四:AI编程模型能力大比拼
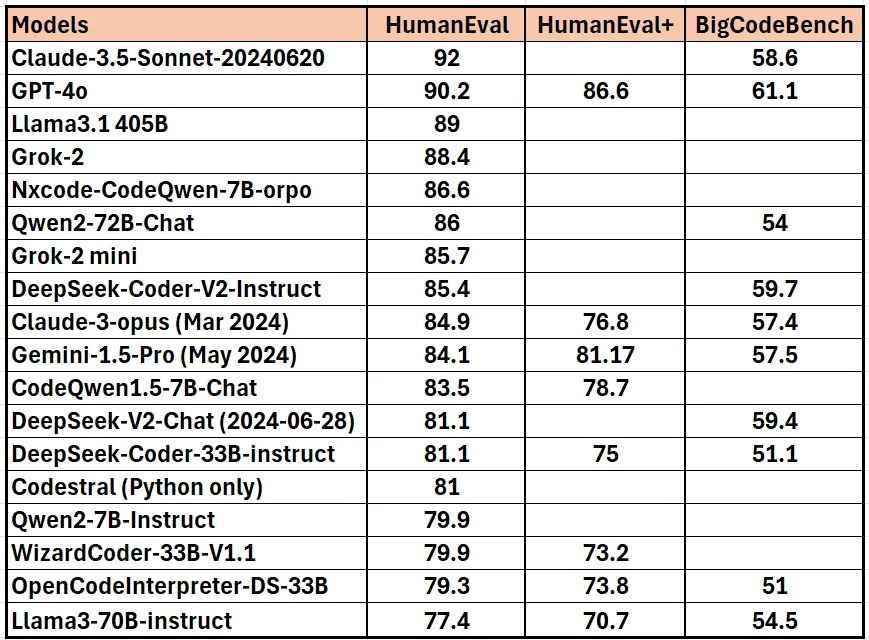
4.1 SWE-bench:AI编程的”金标准”
SWE-bench(Software Engineering Bench)是普林斯顿大学自然语言处理团队开发的评测集,被誉为“AI编程能力的高考”。
核心特点:
测试方法和评分标准
数据构成:- 从12个流行开源Python仓库抓取约90,000个PR- 筛选出同时满足”解决了问题”和”包含测试修改”的PR- 执行验证,保留至少存在一个从Failed到Passed的测试用例- 最终产出2,294个高质量任务样本
评分标准:
通过率 = (FAIL_TO_PASS测试全部通过 且 PASS_TO_PASS测试保持通过) / 总任务数
SWE-bench Verified子集的特殊意义
2024年8月,OpenAI与普林斯顿团队合作推出SWE-bench Verified子集,通过人工审核确保:- 问题描述清晰无歧义- 测试用例覆盖全面- 标准答案唯一且正确,这500个任务成为业界公认的”最严格基准”。
4.2 Claude Opus 4.5:80.9%登顶的技术解析
核心数据深度解读
SWE-bench Verified: 80.9%
这意味着Claude Opus 4.5能够解决500个真实软件问题中的404个——这是首次有AI模型在该基准上突破80%大关。
具体表现:
完全正确:404个任务(80.9%)
部分正确:32个任务(6.4%)
完全错误:64个任务(12.7%)
Terminal-Bench 2.0: 59.3%
这个评测专门测试AI在命令行环境下的操作能力,包括:
文件系统导航
Git版本控制
包管理器操作
系统配置修改
Aider Polyglot: 89.4%
在这个多语言编程评测中,Claude Opus 4.5在7种编程语言中均排名第一:
Python: 92.1%
JavaScript: 88.7%
TypeScript: 87.3%
Java: 85.9%
Go: 84.2%
Rust: 82.6%
C++: 79.8%
技术突破点
1. Token效率提升76%
Claude Opus 4.5相比4.0版本,在保持输出质量的同时,生成相同代码所需的token数减少了76%。这意味着:
响应速度更快
API成本更低
能在相同上下文窗口内处理更复杂的任务
2. 模糊需求理解能力
Anthropic公司分享过一个经典案例:
用户需求:"做一个航空公司客服系统,要能处理投诉。"
Claude Opus 4.5的理解:
这种"需求补全"能力是AI编程从"代码生成器"进化为"软件架构师"的关键。
3. 多文件代码重构可靠性
在Anthropic的内部测试中,Claude Opus 4.5在处理跨10+文件的重构任务时:
一致性:所有修改保持命名和接口的一致
完整性:不会遗漏需要同步修改的地方
安全性:主动检查修改是否会破坏现有功能
价格优势:降价66.7%的商业意义
更令人震惊的是价格调整:
这个价格调整的商业含义:
让中小企业也能用得起最强AI编程助手
推动AI编程从"实验性工具"到"生产级基础设施"
加速整个行业向AI-Native开发模式转型
4.3 Gemini 3 Pro:视觉智能的断层领先
ScreenSpot-Pro是专门评测AI"看懂屏幕"能力的基准测试。任务形式是:给AI一张网页/应用截图 + 一个操作指令(如"点击登录按钮"),AI需要准确定位要点击的位置。
历史成绩对比分析如下:
模型 | ScreenSpot-Pro得分 | 提升幅度 |
GPT-5.1 | 3.5% | - |
Gemini 2 Pro | 14.2% | +10.7% |
Gemini 3 Pro | 72.7% | +58.5% |
这个20倍的飞跃意味着什么?AI Agent首次真正”看懂屏幕”,在Gemini 3 Pro之前,AI对屏幕的理解主要依赖:
OCR识别文字
简单的布局分析
基于启发式规则的元素定位
Gemini 3 Pro的突破在于:
语义理解:不仅识别文字,还理解UI元素的功能含义
上下文感知:理解不同页面状态下同一元素的不同作用
布局推理:即使元素位置变化,仍能准确定位。
结论:Gemini 3 Pro是多模态理解的王者,但在纯代码生成能力上仍有提升空间。
1M tokens上下文窗口的意义
Gemini 3 Pro支持100万token的上下文窗口,这意味着:
整个代码库装进内存:一个中型项目(约10万行代码)可以完整加载
完整的文档阅读:可以一次性读完API文档、设计规范、需求文档
长程对话不断片:即使讨论持续数小时,AI仍能记住最初的上下文
实测:在一次连续6小时的开发对话中,Gemini 3 Pro始终能准确引用早期讨论的架构决策。
4.4 GPT-5.1与5.2:效率革命与商业价值
GPT-5.1基础能力
- SWE-bench Verified: 67.4%(全球第五)
特点:全面但不突出,性价比较低。
GPT-5.2的"打工能力"强化
OpenAI在发布5.2时明确表示:这是一个面向"实际工作场景"优化的模型。
GDPval测试:70.9%超越人类专家
GDPval是专门评测AI完成"真实办公任务"的基准:
处理Excel复杂公式
分析财务报表
撰写商业计划书
法律合同审阅
测试结果:
GPT-5.2平均得分:70.9%
人类专业人士平均:67.3%
首次在商业场景全面超越人类
速度与成本优势分析如下:
ARC-AGI-2: 52.9%
ARC-AGI是专门测试"抽象推理"能力的评测集,被认为是通向AGI的关键指标。
GPT-5.2的突破:
较5.1提升3倍,证明了模型不仅能"记忆",还能"理解规律"
价格策略:标准版比5.1贵40%
定价逻辑:
虽然价格更高,但速度提升11倍,实际成本反而更低
面向B端企业,愿意为"更准确"支付溢价
与Claude Opus 4.5形成差异化竞争(Claude更强于纯编程,GPT-5.2更强于商业场景)
4.5 国产AI的集体爆发
GLM-4.7:开源编程天花板
核心数据对比表分析如下:
| | | | |
|---|
| SWE-bench Verified | 73.8% | | | |
| LiveCodeBench V6 | 84.9分 | | | |
| HLE | 42.8% | | | |
| Code Arena | 开源第一 | | | |
技术架构详解
MoE架构:
总参数:400B(4000亿)
激活参数:20B-30B(每次推理只激活部分专家)
优势:在保持强大能力的同时,推理成本仅为同规模模型的1/10
交织式思考(Interleaved Thinking)
这是GLM-4.7最独特的设计:
传统模型:用户问题 → [黑箱推理] → 输出答案
GLM-4.7:用户问题 → [思考1:理解需求] → [行动1:搜索相关代码] → [思考2:分析问题] → [行动2:生成修复方案] → [思考3:验证正确性] → 输出答案
每一步的"思考"都是可见、可控、可中断的。
保留式思考(Preserved Thinking)
在多轮对话中,GLM-4.7会记住之前的推理过程,避免重复思考:
第1轮对话:用户:"分析这个Bug的原因"
GLM-4.7:[详细分析10分钟] → 得出结论
第2轮对话:用户:"那应该怎么修?"GLM-4.7:[直接基于第1轮的分析结果] → 给出修复方案(不需要重新分析Bug)
轮级思考(Turn-level Thinking)
用户可以根据任务复杂度,按轮次控制思考开销:
简单任务:关闭思考模式(降低延迟)
复杂任务:开启思考模式(确保质量)
Slime框架的RLVR训练
GLM-4.7使用了智谱自研的Slime强化学习框架:
传统监督学习:训练数据 → 模型学习 → 评估 → 调整参数
Slime RLVR(可验证奖励强化学习):任务 → 模型尝试 → 执行结果 → 自动验证 → 计算奖励 → 更新策略 → 持续改进
关键优势:奖励信号基于客观的测试通过率,而非人工评分能够自动发现并学习复杂的推理策略,训练效率提升约5倍。
前端审美提升:从52%到91%
GLM-4.7在前端代码生成上取得了突破性进展。
PPT 16:9适配率:
GLM-4.0:52%的生成内容符合16:9比例
GLM-4.7:91%符合标准
一位UI设计师评价:"GLM-4.7生成的页面,已经达到了初级前端工程师的水平。虽然还需要微调,但至少不会让你推翻重做。"
MiniMax M2.1:多语言编程SOTA
Multi-SWE-bench全球第一:49.4%
Multi-SWE-bench是MiniMax自己构建的多语言编程评测集,覆盖10+主流编程语言的真实GitHub Issue。
成绩对比分析如下:
MiniMax为M2.1构建了超过10万个独立的编程环境,每个环境都包含:
这是目前全球最大规模的多语言编程训练数据集。
VIBE综合榜单:88.6分
VIBE是评测AI"全流程开发能力"的综合榜单,包括:
需求理解
架构设计
代码实现
测试编写
文档撰写
M2.1在这个榜单上达到88.6分,仅次于Claude Opus 4.5的91.2分。
Android开发:89.7分
M2.1在Android开发场景表现尤为突出:
熟悉Android SDK各版本API差异
能正确处理Activity生命周期
生成符合Material Design规范的UI
处理复杂的异步任务
脚手架泛化性:三个主流脚手架都保持67+分
什么是脚手架泛化性?
不同的AI编程工具(如Cline、Cursor、Claude Code)使用不同的"脚手架"(Scaffold)——即与AI交互的方式、Prompt模板、上下文管理策略等。
很多模型存在"脚手架过拟合"问题:在某个脚手架上表现优异,换一个就明显下降。
M2.1的泛化能力:
差异小于1%,证明M2.1具有出色的适应能力。
4.6 五大模型横向对比表分析如下:
| | | | | |
|---|
| SWE-bench Verified | | | | | |
| 编程语言支持 | | | | | 10+种 |
| 上下文窗口 | | 1M | | | |
| 推理速度 | | | ★★★★★ | | |
| 价格(输入) | $3 | | | 免费/开源 | |
| 特色能力 | 多文件重构 | 视觉编程 | 商业场景 | 交织思考 | 多语言SOTA |
| 适用场景 | | | | | |
| 部署方式 | | | | API+本地 | |
综合评价:
纯编程能力:Claude Opus 4.5 > GLM-4.7 > Gemini 3 Pro ≈ GPT-5.2
多模态能力:Gemini 3 Pro > Claude Opus 4.5 > GPT-5.2
商业场景:GPT-5.2 > Claude Opus 4.5 > Gemini 3 Pro
性价比:GLM-4.7(开源免费) > Claude Opus 4.5 > MiniMax M2.1
企业级应用:MiniMax M2.1(多语言) > Claude Opus 4.5 > GPT-5.2
五:开发者真实体验:97%在用,但满意度如何?
GitHub 2024调研:97%开发者已使用AI工具
GitHub在2024年底发布的调查报告显示:97%的专业开发者,在过去一年中使用过AI编程工具,82%的学生开发者日常使用AI辅助学习编程,平均每个开发者使用2.3个不同的AI工具。
这个接近100%的使用率证明:AI编程已经从"新奇实验"变成了"基础设施"。
Stack Overflow数据:信任度下降的矛盾现象
但使用率与满意度并不成正比:
这个矛盾揭示了什么?
开发者对AI工具的态度可以概括为:
✅ "确实更快了"
✅ "不用它就落后了"
❌ "但我不完全信任它"
❌ "需要花很多时间验证"
Sonar调查的惊人发现
Sonar在2025年1月对5000名开发者进行了深度访谈,发现:
96%认为AI代码不够准确,但48%不检查就使用
这个数据引发了业界的巨大震动。为什么开发者明知AI可能出错,还是选择直接使用?
访谈揭示的真实原因:
1."deadline压力太大,没时间仔细检查"(38%)
2."简单任务出错概率低,就赌一把"(27%)
3."反正后面测试会发现问题"(19%)
4."不知道怎么检查AI代码"(16%)
这暴露了一个危险的趋势:开发者正在将质量保证的责任推给测试环节,而不是在编码阶段严格把关。
高德团队实践:AI出码率70%+
阿里巴巴高德地图团队在2024年进行了为期6个月的AI编程实践,得出了详细的量化数据:
AI出码率统计:
关键洞察
1.标准化代码AI优势明显:数据模型、CRUD这类有固定模式的代码,AI生成质量很高
2.复杂逻辑仍需人工主导:涉及领域知识的业务逻辑,AI更多起辅助作用
3.算法是AI的软肋:特别是需要数学证明和性能优化的算法
AI工具使用策略:
第1个月:激进尝试期
几乎所有代码都先让AI生成
发现大量问题:逻辑错误、性能问题、安全漏洞
AI代码直接可用率:仅38%
第2个月:调整期
明确哪些任务适合AI,哪些不适合
建立"AI代码检查清单"
AI代码直接可用率:提升到61%
第3个月:成熟期
AI主要用于:脚手架代码、单元测试、文档生成
核心业务逻辑仍由人工编写
最终AI贡献的代码量:约68%
最大的教训:
"AI是非常强大的助手,但不是全能的替代品。关键是明确哪些工作应该交给AI,哪些必须人工把关。盲目依赖AI和完全拒绝AI都是错误的极端。"
六:未来展望与实践建议

AI编程的三个发展趋势
趋势1:从"代码生成"到"系统思考"
未来的AI编程工具将不仅仅生成代码片段,而是具备系统级的架构能力,理解业务需求并转化为技术方案、评估不同技术选型的优劣、考虑系统的扩展性、可维护性、安全性、提供完整的技术文档和设计说明。
技术支撑:
更大的上下文窗口(10M+ tokens)
更强的长程推理能力
与领域知识库的深度整合
趋势2:从"单Agent"到"多Agent协同"
未来的开发模式将是AI Agent团队协作:
项目经理Agent:- 理解用户需求- 拆解任务分配给不同Agent- 监控整体进度
架构师Agent:- 设计系统架构- 制定技术规范- 评审关键决策
后端工程师Agent:- 实现API和业务逻辑- 编写单元测试- 优化性能
前端工程师Agent:- 实现UI/UX- 对接后端API- 处理交互逻辑测
试工程师Agent:- 执行集成测试- 发现Bug并反馈- 生成测试报告
运维Agent:- 部署到生产环境- 监控系统运行- 处理告警
已有的探索:
Google的AlphaCode Team:多个模型协作解决编程竞赛题目
OpenAI的Swarm框架:简化多Agent编排
Anthropic的Computer Use:Agent能直接操作计算机界面
趋势3:从"通用工具"到"领域专家"
未来将出现针对特定领域深度优化的AI编程助手:
金融AI Coder:精通金融业务逻辑和监管要求
游戏AI Coder:擅长游戏引擎和图形渲染
嵌入式AI Coder:精通硬件接口和实时系统
区块链AI Coder:熟悉智能合约和安全审计
商业价值:
领域专家模型的准确率可能比通用模型高20-30%,在垂直行业有巨大商业潜力。
给开发者的五个实践建议

建议1:建立AI代码审查清单
不要盲目信任AI生成的代码,建立系统化的检查流程。
安全检查:
是否存在SQL注入风险?
是否正确验证用户输入?
是否暴露敏感信息(密钥、密码)?
是否存在XSS、CSRF等常见漏洞?
性能检查:
查询是否使用了索引?
是否存在N+1查询问题?
循环中是否有冗余计算?
内存使用是否合理?
可维护性检查:
代码结构是否清晰?
变量命名是否符合规范?
是否有充足的注释?
是否遵循团队编码标准?
边界条件检查:
是否处理了null/undefined?
是否处理了空数组/空字符串?
数值范围是否考虑边界?
建议2:掌握"提示词工程"技能
好的Prompt是AI编程效果的关键,Prompt优化的核心原则:
1.背景上下文:让AI知道项目的技术栈和架构
2.明确需求:具体描述功能的每个细节
3.技术约束:明确安全、性能、规范等要求
4.期望输出:清楚说明需要哪些交付物
建议3:分层使用AI工具
根据任务的重要性和复杂度,选择合适的AI参与程度:
Layer 1:完全自动化(AI主导)
脚手架代码生成
数据模型定义
单元测试编写
API文档生成
代码格式化
Layer 2:AI辅助、人工审核
常见业务逻辑
CRUD操作
前端UI组件
数据库查询
配置文件
Layer 3:人工主导、AI参考
系统架构设计
核心算法实现
安全关键代码
性能优化
复杂业务规则
Layer 4:纯人工(禁用AI)
建议4:投资学习系统知识
AI编程时代,深厚的计算机基础反而更重要。
1.AI会犯错,你需要能识别
2.AI需要好的指导
系统知识让你能提出更精准的需求
你的技术视野决定了AI能帮你到什么程度
3.关键时刻仍需人工决策
技术选型、架构设计这些战略性决策,AI无法替代
出现生产事故时,你必须能独立解决
建议5:参与开源,了解AI边界
最好的学习方式是实践,参与开源项目能让你清楚认识AI的能力边界:
推荐实践:
1.选择一个AI编程工具的开源项目:Cline、Aider、Continue等了解这些工具是如何设计的尝试贡献代码或报告Bug。
2.尝试用AI完成开源项目的Issue:在GitHub上找一些"Good First Issue"
用AI辅助解决,提交PR,在Code Review中学习AI的不足。
3.对比AI生成代码与人类代码:找一些经典的开源项目,看看人类专家是如何设计的,思考AI在哪些方面做不到。
给企业的部署建议

建议1:建立AI编程规范
制定明确的AI工具使用规范,而不是放任自流,必须包含:
哪些场景允许使用AI
哪些场景禁止使用AI
AI代码必须经过哪些审查
如何标记AI生成的代码
出现问题的责任归属
建议2:投资内部AI Coder培训
不要假设开发者会自己学,主动提供培训:
培训内容应包括:
1.如何编写高质量Prompt
2.如何审查AI生成的代码
3.如何高效使用多个AI工具
4.常见的AI代码陷阱
5.企业内部的最佳实践分享
ROI计算:
20人 × 250小时 × 500元/小时 =250万元/年
建议3:建立AI代码质量监控
通过数据驱动,持续优化AI使用效果:
关键指标:
AI代码占比
AI代码的Bug密度
AI代码的Review通过率
AI代码的后续修改频率
开发效率提升程度
监控工具:
建议4:构建企业知识库
让AI学习你的业务和代码规范:
1.整理内部文档,技术规范、设计文档、API文档,让AI能参考这些资料
2.训练定制模型(大型企业),使用内部代码库进行微调,让AI更符合企业风格
3.建立Prompt模板库,沉淀常见任务的优质Prompt,新人可以直接复用
AI编程时代,计算机教育应该如何变革?
AI时代教育:
直接从问题出发
用AI辅助实现
理解原理和优化
强化”代码审查”能力培养
新的核心能力:
快速阅读和理解他人代码
识别代码中的安全漏洞
评估代码的性能和可维护性
提出改进建议
教学方法:
让学生审查AI生成的代码
对比人类专家的实现
分析哪个更好,为什么
增加”提示词工程”课程
这是新的必备技能:
如何将需求转化为清晰的Prompt
如何迭代优化Prompt
如何结合多个AI工具
如何评估AI输出质量
结论:在效率与质量间寻找平衡
AI编程革命已经到来,但这不是一场”人类vs机器”的零和游戏,而是人机协作的新范式探索。
我们正在见证:
✅ 开发效率的大幅提升(3-10倍)
✅ 编程门槛的显著降低
✅新的协作模式的诞生
⚠️ 代码质量的隐忧
⚠️ 开发者技能的分化
⚠️ 新的安全风险的涌现
在每个具体场景中,找到AI与人类的最佳协作点——让AI处理繁琐重复的工作,让人类聚焦创造性思考和关键决策。这不是AI取代人类,而是AI解放人类,让我们能做更有价值的事。
随着AI模型的持续进化、工具的不断完善、最佳实践的逐步沉淀,信任会慢慢建立,新的平衡会最终到来。
而在这个过程中,那些既精通AI工具,又保持扎实基础,还能清醒判断的开发者,将成为这个时代最有竞争力的人才。