在Linux系统中,进程是资源分配和调度的基本单位,所有程序的运行本质上都是进程从创建、运行到消亡的生命周期过程。而Linux进程的完整生命周期,核心围绕fork(创建)、exec(程序替换)、wait(父进程等待)、exit(进程终止) 四个关键系统调用展开——fork实现进程的“复制”,exec完成程序的“替换”,wait保障父进程对子进程的“回收”,exit实现进程的“优雅终止”。
本文将从进程生命周期的核心原理出发,拆解每个关键阶段的底层逻辑,结合可运行的C语言代码示例,搭配实际生产场景的实践方案,让你彻底搞懂Linux进程从诞生到消亡的完整过程。
一、Linux进程的核心基础:先搞懂这3个关键概念
在深入生命周期之前,需先理清3个基础概念,这是理解后续操作的前提:
1. 进程ID(PID)与父/子进程
Linux中每个进程都有唯一的进程ID(PID,Positive Integer),由内核动态分配(默认从300开始,PID=0为空闲进程、PID=1为init/systemd进程,是所有进程的“祖先进程”)。
通过fork创建的新进程为子进程,原进程为父进程,子进程会继承父进程的PID(作为自身PPID,父进程ID),形成Linux的进程树结构(可通过pstree命令查看)。
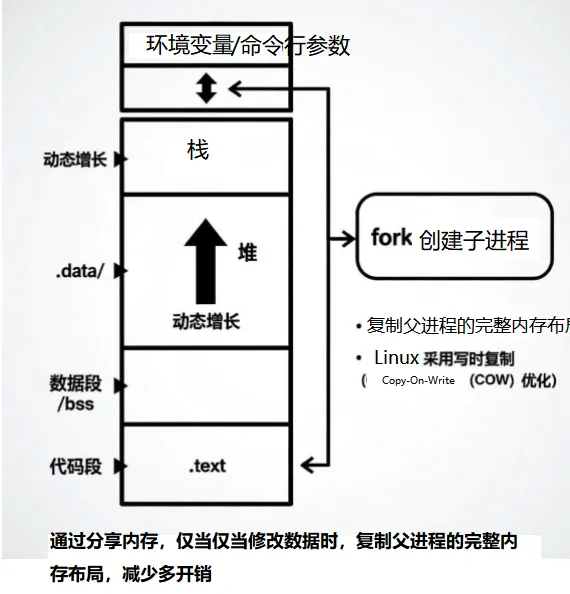
2. 进程的内存布局
每个进程拥有独立的内存空间(内核通过页表实现隔离),经典布局从低地址到高地址依次为:代码段(.text)、数据段(.data/.bss)、堆(heap)、栈(stack)、环境变量/命令行参数。
fork创建子进程时,会复制父进程的内存布局(Linux实际采用写时复制(Copy-On-Write,COW) 优化:默认共享内存,仅当父/子进程修改数据时,才会真正复制对应内存页,减少内存开销)。
3. 系统调用与用户态/内核态
fork、exec、exit、wait均为Linux系统调用——进程从用户态切换到内核态,请求内核完成进程管理的底层操作(如分配PID、修改进程表、释放资源等),操作完成后再切回用户态。
Linux系统调用可通过man 2 函数名查看详细文档(如man 2 fork),这是开发和排查问题的重要工具。
二、Linux进程完整生命周期:四大阶段+核心系统调用
Linux进程的生命周期可概括为4个核心阶段,串联起fork、exec、wait、exit四大关键系统调用,完整流程为:父进程创建(fork)→ 子进程程序替换(exec)→ 子进程运行并终止(exit)→ 父进程回收子进程(wait)。
若父进程未及时回收终止的子进程,子进程会变成僵尸进程(占用PID资源,无法被重新分配);若父进程先于子进程终止,子进程会被init/systemd(PID=1) 收养,成为“孤儿进程”,最终由祖先进程回收。
阶段1:进程创建——fork(),实现“复制式创建”
1. fork的核心原理
fork()是Linux创建新进程的唯一方式(除了init进程),其核心特性是**“一次调用,两次返回”**:
- 调用
fork()时,内核会为子进程分配新的PID,复制父进程的进程表、文件描述符、内存页表(写时复制)等资源; - 父进程中,
fork()返回子进程的PID(大于0的整数); - 若创建失败(如系统PID耗尽、内存不足),
fork()返回**-1**,并设置errno。
2. fork的关键特性:写时复制(COW)
早期Linux中,fork会直接复制父进程的所有内存,效率极低。现代Linux采用写时复制优化:
- fork后,父、子进程共享同一块物理内存,页表标记为“只读”;
- 当任意一方(父/子)尝试修改内存数据时,内核会为修改的内存页创建副本,各自持有独立的可写副本;
- 只读数据(如代码段)始终共享,直到进程执行exec替换程序。
3. 代码示例:基础fork创建子进程
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<errno.h>
intmain() {
// 定义变量存储fork返回值
pid_t pid;
// 全局变量,验证写时复制
int global_var = 10;
// 调用fork创建子进程
pid = fork();
// fork失败处理
if (pid == -1) {
perror("fork failed"); // 打印错误信息(结合errno)
return-1;
}
// 子进程:fork返回0
if (pid == 0) {
printf("【子进程】PID: %d, PPID: %d\n", getpid(), getppid());
global_var += 5; // 子进程修改全局变量
printf("【子进程】global_var: %d(修改后)\n", global_var);
// 子进程暂时不退出,等待父进程执行
sleep(2);
}
// 父进程:fork返回子进程PID(>0)
if (pid > 0) {
printf("【父进程】PID: %d, 子进程PID: %d\n", getpid(), pid);
printf("【父进程】global_var: %d(原始值)\n", global_var);
// 父进程等待子进程执行完成,避免子进程成为僵尸进程
sleep(3);
}
// 父、子进程都会执行这行代码(验证独立运行)
printf("PID: %d, 执行结束\n", getpid());
return0;
}
4. 编译运行与结果分析
# 编译(保存为fork_demo.c)
gcc fork_demo.c -o fork_demo
# 运行
./fork_demo
运行结果:
【父进程】PID: 1234, 子进程PID: 1235
【父进程】global_var: 10(原始值)
【子进程】PID: 1235, PPID: 1234
【子进程】global_var: 15(修改后)
PID: 1234, 执行结束
PID: 1235, 执行结束
关键结论:
- 子进程修改全局变量后,父进程的变量值不变——验证写时复制,修改触发内存副本创建,实现进程内存隔离;
- 父进程通过
sleep(3)等待子进程,避免子进程先终止成为僵尸进程。
阶段2:程序替换——exec()系列,实现“进程的程序重载”
1. exec的核心问题:为什么需要exec?
fork创建的子进程,复制的是父进程的代码段和数据段——子进程默认执行和父进程相同的程序,而实际开发中,我们需要子进程执行新的程序(如父进程是Shell,子进程执行ls、ps等命令),这就需要exec系列函数完成程序替换。
exec的核心作用:替换当前进程的代码段、数据段、堆、栈,保留进程的PID(进程本身未消亡,只是运行的程序被替换),实现“一个进程,运行不同程序”。
2. exec系列函数:6个函数,一个核心
Linux提供6个exec系列函数(统称execve的封装,execve是系统调用,其余为库函数),头文件均为<unistd.h>,核心区别是参数格式和是否搜索PATH环境变量,常用的是execlp和execvp。
| | |
|---|
| int execlp(const char *file, const char *arg, ..., NULL); | |
| int execvp(const char *file, char *const argv[]); | |
| int execl(const char *path, const char *arg, ..., NULL); | |
| int execv(const char *path, char *const argv[]); | |
| int execle(const char *path, const char *arg, ..., NULL, char *const envp[]); | |
| int execve(const char *path, char *const argv[], char *const envp[]); | |
关键特性:
- 若执行成功,不会返回(因为当前进程的代码段已被替换,原程序后续代码不再执行);
- 若执行失败,返回**-1**(需在exec后添加错误处理,否则错误会被忽略);
- 仅替换程序资源,进程的PID、PPID、文件描述符(未设置FD_CLOEXEC)等保持不变。
3. 代码示例:fork+exec组合,实现“父进程创建子进程执行新程序”
这是Linux最经典的进程使用模式(如Shell、Nginx、Docker等底层均基于此),示例实现:父进程创建子进程,子进程通过execlp执行ls -l /tmp命令,父进程等待子进程完成。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<errno.h>
intmain() {
pid_t pid;
printf("【父进程】开始执行,PID: %d\n", getpid());
// 阶段1:fork创建子进程
pid = fork();
if (pid == -1) {
perror("fork failed");
return-1;
}
// 子进程:执行exec替换程序
if (pid == 0) {
printf("【子进程】创建成功,PID: %d,即将执行ls命令\n", getpid());
// 阶段2:exec替换程序,执行ls -l /tmp,参数以NULL结尾
execlp("ls", "ls", "-l", "/tmp", NULL);
// 注意:若exec执行成功,以下代码不会执行;只有失败时才会走到这里
perror("execlp failed"); // 打印exec失败原因(如命令不存在)
_exit(1); // 子进程执行失败,异常退出,退出码1
}
// 父进程:等待子进程终止并回收资源
if (pid > 0) {
int status;
// 阶段3:waitpid等待子进程,pid为子进程PID,status存储退出状态
pid_t ret = waitpid(pid, &status, 0);
if (ret == -1) {
perror("waitpid failed");
return-1;
}
// 解析子进程退出状态:正常退出/异常终止
if (WIFEXITED(status)) {
printf("【父进程】子进程(%d)正常终止,退出码: %d\n", pid, WEXITSTATUS(status));
} elseif (WIFSIGNALED(status)) {
printf("【父进程】子进程(%d)被信号终止,信号号: %d\n", pid, WTERMSIG(status));
}
}
printf("【父进程】执行结束,PID: %d\n", getpid());
return0;
}
4. 编译运行与结果分析
# 编译(保存为fork_exec_demo.c)
gcc fork_exec_demo.c -o fork_exec_demo
# 运行
./fork_exec_demo
运行结果:
【父进程】开始执行,PID: 1236
【子进程】创建成功,PID: 1237,即将执行ls命令
总用量 0
-rw-r--r-- 1 root root 0 12月 5 10:00 test.txt
drwxr-xr-x 2 root root 40 12月 5 09:50 test_dir
【父进程】子进程(1237)正常终止,退出码: 0
【父进程】执行结束,PID: 1236
关键结论:
- 子进程执行
execlp后,成功替换为ls程序,输出/tmp目录内容,原子进程的C代码不再执行; exec执行成功无返回,因此perror("execlp failed")仅在命令不存在(如写为lss)时才会执行;- 父进程通过
waitpid精准等待指定子进程,避免僵尸进程,同时解析退出状态判断子进程是否正常终止。
阶段3:进程终止——exit()/_exit(),实现“优雅消亡”
进程终止分为正常终止和异常终止,exit()和_exit()是正常终止的核心函数,也是进程生命周期的“收尾操作”。
1. 进程终止的两种方式
| | |
|---|
| 程序执行完毕、调用exit()/_exit()、main函数return | exit(0) |
| 被信号杀死(如kill -9)、访问非法内存、除零错误 | kill -9 1237 |
2. exit()与_exit()的核心区别
两者均为进程终止函数,头文件分别为<stdlib.h>(exit)和<unistd.h>(_exit),核心区别是是否刷新标准输出缓冲区:
- _exit(int status):系统调用,直接终止进程,释放内核资源(PID、内存、文件描述符),不刷新用户态缓冲区(如printf未换行的内容会丢失);
- exit(int status):库函数,封装了_exit,执行流程为:刷新缓冲区 → 执行atexit()注册的清理函数 → 调用_exit()终止进程。
status参数:进程退出码(0表示正常,非0表示异常),父进程可通过wait/waitpid的status参数解析该值(通过WEXITSTATUS(status))。
3. 代码示例:exit()与_exit()的缓冲区差异
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
intmain() {
// 测试1:使用exit(),会刷新缓冲区,输出内容
printf("测试exit():缓冲区内容"); // 无换行,缓冲区未自动刷新
exit(0); // 刷新缓冲区后终止,内容会输出
}
// 注释上面的代码,测试下面的代码
/*
int main() {
// 测试2:使用_exit(),不刷新缓冲区,内容丢失
printf("测试_exit():缓冲区内容"); // 无换行,缓冲区未自动刷新
_exit(0); // 直接终止,缓冲区内容不输出
}
*/
编译运行结果:
- 测试1(exit):输出
测试exit():缓冲区内容; - 测试2(_exit):无任何输出(缓冲区内容丢失)。
4. 核心建议
- 应用层开发优先使用exit():确保printf、fwrite等的缓冲区内容被刷新,避免数据丢失;
- 子进程exec执行失败时,优先使用**_exit()**:避免刷新父进程的缓冲区(fork后父、子进程共享缓冲区,exit()会导致重复刷新);
- main函数的
return n等价于exit(n):编译器会在main函数末尾自动插入exit(return值)。
阶段4:资源回收——wait()/waitpid(),避免僵尸进程
1. 僵尸进程的产生原因
当子进程终止后,内核会保留该进程的部分资源(PID、退出状态、运行时间),等待父进程通过wait/waitpid读取,若父进程未及时调用wait/waitpid,子进程会变成僵尸进程(Zombie),状态为Z(可通过ps -ef | grep Z查看)。
僵尸进程的危害:Linux系统的PID数量有限(默认最大65535),大量僵尸进程会耗尽PID资源,导致系统无法创建新进程。
2. wait()与waitpid()的核心区别
两者均为父进程回收子进程的函数,头文件为<sys/wait.h>,核心区别是是否阻塞和是否能精准回收指定子进程:
| | |
|---|
| pid_t wait(int *status); | 阻塞等待任意一个子进程终止,返回终止的子进程PID |
| pid_t waitpid(pid_t pid, int *status, int options); | |
关键参数说明:
pid:指定等待的子进程PID,常用值:>0(等待指定PID的子进程)、-1(等待任意子进程,等价于wait)、0(等待同组的子进程);options:等待模式,常用值:0(阻塞模式,等价于wait)、WNOHANG(非阻塞模式,若无子进程终止,立即返回0);status:存储子进程的退出状态,可为NULL(不关心退出状态),通过以下宏解析:WIFEXITED(status)WEXITSTATUS(status)WIFSIGNALED(status)WTERMSIG(status)
3. 代码示例:非阻塞waitpid,实现父进程同时管理多个子进程
实际开发中,父进程往往需要创建多个子进程,此时使用非阻塞waitpid(WNOHANG) 轮询回收子进程,避免阻塞导致父进程无法处理其他任务。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<errno.h>
#define CHILD_NUM 3 // 创建3个子进程
intmain() {
pid_t pid[CHILD_NUM];
int i, status;
// 步骤1:创建3个子进程
for (i = 0; i < CHILD_NUM; i++) {
pid[i] = fork();
if (pid[i] == -1) {
perror("fork failed");
return-1;
}
if (pid[i] == 0) {
// 子进程:执行不同的睡眠,模拟不同的运行时间
printf("【子进程%d】创建成功,PID: %d,即将睡眠%d秒\n", i+1, getpid(), i+1);
sleep(i+1); // 子进程1睡眠1秒,子进程2睡眠2秒,子进程3睡眠3秒
printf("【子进程%d】执行结束,PID: %d\n", i+1, getpid());
exit(i); // 子进程正常退出,退出码为i(0/1/2)
}
}
// 步骤2:父进程非阻塞轮询,回收所有子进程
int recv_num = 0; // 已回收的子进程数量
while (recv_num < CHILD_NUM) {
pid_t ret = waitpid(-1, &status, WNOHANG); // 非阻塞等待任意子进程
if (ret > 0) {
// 成功回收子进程
recv_num++;
if (WIFEXITED(status)) {
printf("【父进程】回收子进程PID: %d,退出码: %d\n", ret, WEXITSTATUS(status));
}
} elseif (ret == 0) {
// 暂无子进程终止,父进程执行其他任务(模拟)
printf("【父进程】暂无子进程终止,执行其他任务...\n");
sleep(1);
} else {
// waitpid失败(无更多子进程)
perror("waitpid failed");
break;
}
}
printf("【父进程】所有子进程已回收,执行结束\n");
return0;
}
编译运行结果:
【父进程】暂无子进程终止,执行其他任务...
【子进程1】创建成功,PID: 1238,即将睡眠1秒
【子进程2】创建成功,PID: 1239,即将睡眠2秒
【子进程3】创建成功,PID: 1240,即将睡眠3秒
【子进程1】执行结束,PID: 1238
【父进程】回收子进程PID: 1238,退出码: 0
【父进程】暂无子进程终止,执行其他任务...
【子进程2】执行结束,PID: 1239
【父进程】回收子进程PID: 1239,退出码: 1
【父进程】暂无子进程终止,执行其他任务...
【子进程3】执行结束,PID: 1240
【父进程】回收子进程PID: 1240,退出码: 2
【父进程】所有子进程已回收,执行结束
关键结论:
- 非阻塞
waitpid让父进程在等待子进程的同时,可执行其他任务,提升程序并发能力; - 轮询回收确保所有子进程都被及时回收,彻底避免僵尸进程;
- 可通过
pid[i]数组精准管理每个子进程,适合多子进程场景。
三、Linux进程生命周期的完整流程图
结合以上四个阶段,整理出Linux进程(fork+exec模式)的完整生命周期流程图,直观呈现每个阶段的核心操作和状态转换:
父进程(运行中)
|
v
调用fork() → 内核创建子进程(写时复制)→ 父进程返回子进程PID,子进程返回0
| |
|(父进程) |(子进程)
| v
| 调用exec系列函数 → 替换程序代码段/数据段
| |(执行新程序)
| v
| 程序执行完毕 → 调用exit()/_exit() → 子进程终止(状态Z,僵尸进程)
| |
v |
调用wait/waitpid() ←←←←←←←←←←←←
|(回收子进程资源,清除僵尸状态)
v
父进程继续运行/终止
特殊场景分支:
- 子进程未执行exec,直接exit → 父进程回收子进程(无程序替换,仅复制父进程代码执行);
- 父进程未调用wait/waitpid → 子进程终止后成为僵尸进程;
- 父进程先于子进程终止 → 子进程被init/systemd(PID=1)收养,成为孤儿进程,最终由祖先进程回收。
四、实际生产场景实践:基于fork+exec的经典应用
fork+exec是Linux系统编程的基础,几乎所有后台服务和命令行工具都基于此模式开发,以下是3个典型的生产场景实践,让你理解理论如何落地。
场景1:Shell终端的底层实现(最经典的fork+exec应用)
我们日常使用的Bash/Zsh终端,其核心工作原理就是fork+exec+wait:
- Shell作为父进程,持续读取用户输入的命令(如
ls -l、ps -ef); - 子进程调用
exec系列函数(如execvp)替换为对应的命令程序; - Shell调用
waitpid阻塞等待子进程执行完毕,回收资源后,再次等待用户输入。
验证方式:在Shell中执行ps -ef | grep bash查看Shell的PID,执行ls -l时,通过pstree -p ShellPID可看到子进程的创建和销毁过程。
场景2:Nginx多进程模型(master-worker模式)
Nginx作为高性能Web服务器,采用master-worker多进程模型,底层基于fork实现,无需exec(因为worker进程需要执行和master相同的核心代码):
- Master进程(主进程):负责读取配置、监听端口、管理worker进程;
- Master进程通过
fork创建多个Worker进程(数量通常等于CPU核心数,充分利用多核); - Worker进程:共享master的监听端口,处理客户端请求,相互独立(一个worker异常不会影响其他worker);
- 当配置更新时,master进程通过信号通知worker进程优雅退出,再fork新的worker进程,实现无缝重启。
核心优势:基于fork的写时复制,master创建worker的开销极低;多进程隔离,提升服务稳定性。
场景3:批量任务处理(如数据清洗、日志分析)
在大数据处理场景中,常需要父进程创建多个子进程并行处理批量任务(如按文件分块清洗日志),核心流程:
- 父进程:读取任务列表(如100个日志文件),按CPU核心数拆分任务(如8核心拆分为8个任务块);
- 父进程fork创建8个子进程,每个子进程分配一个任务块;
- 子进程调用exec执行数据清洗程序(如Python脚本、C程序),处理对应任务块;
- 父进程通过非阻塞waitpid轮询回收子进程,统计任务执行结果(成功/失败);
核心优势:并行处理提升任务效率,子进程独立执行,单个任务失败不影响整体流程。
五、常见问题与避坑指南
在基于fork+exec开发Linux程序时,容易遇到以下问题,提前规避可大幅提升开发效率:
1. 僵尸进程的彻底解决方法
除了父进程调用wait/waitpid,还有两种经典方案解决僵尸进程:
- 方案1:父进程注册SIGCHLD信号处理函数,当子进程终止时,内核会向父进程发送SIGCHLD信号,在信号处理函数中调用waitpid回收子进程;
- 方案2:父进程fork两次,创建“孙子进程”执行任务,父进程立即回收子进程,孙子进程成为孤儿进程,由init/systemd回收(适合无需父进程管理的后台任务)。
2. exec执行失败的常见原因
exec返回-1的常见场景,按排查优先级排序:
- 程序名/路径错误(如
execlp("lss", ...),命令不存在); - 程序无执行权限(如
chmod -x test.sh,需执行chmod +x test.sh); - 参数格式错误(如未以NULL结尾,
execlp("ls", "ls", "-l", /tmp),缺少NULL);
3. fork创建子进程的注意事项
- fork后,父、子进程的文件描述符是复制关系(指向同一个文件表项),若需独立操作文件,需在fork后关闭不需要的文件描述符,或设置FD_CLOEXEC(exec时关闭文件描述符);
- fork后,父、子进程的信号掩码、环境变量等会继承,需根据需求修改;
- 避免在多线程程序中随意fork(fork后仅复制当前线程,其他线程会终止,容易导致锁资源泄漏)。
六、总结
Linux进程的完整生命周期,本质是内核对进程资源的分配、管理和释放过程,而fork、exec、wait、exit四大系统调用,串联起了进程从创建到消亡的全部核心操作:
- fork:实现进程的“复制式创建”,基于写时复制优化,最小化内存开销,是所有新进程的诞生方式;
- exec:实现进程的“程序替换”,保留PID,替换运行的程序,是Linux实现程序调度的核心;
- wait/waitpid:实现父进程对子女进程的“资源回收”,避免僵尸进程,是进程生命周期的“收尾保障”;
- exit/_exit:实现进程的“优雅终止”,释放资源,传递退出状态,是进程生命周期的“最后一步”。
fork+exec的组合,是Linux系统“一切皆进程”的底层支撑,从简单的Shell命令执行,到高性能的Nginx多进程模型,再到批量的大数据处理,都基于这一核心模式。理解了进程的完整生命周期,不仅能让你轻松编写Linux系统程序,更能为后续学习进程通信、进程调度、多线程开发打下坚实的基础。
最后一个小建议:本文的所有代码示例均可直接编译运行,建议你在Linux虚拟机/服务器中亲手实践,通过修改参数(如fork的子进程数量、exec的命令)、模拟异常(如kill子进程、让exec执行失败),直观感受进程的状态变化,这是理解Linux进程最有效的方式。