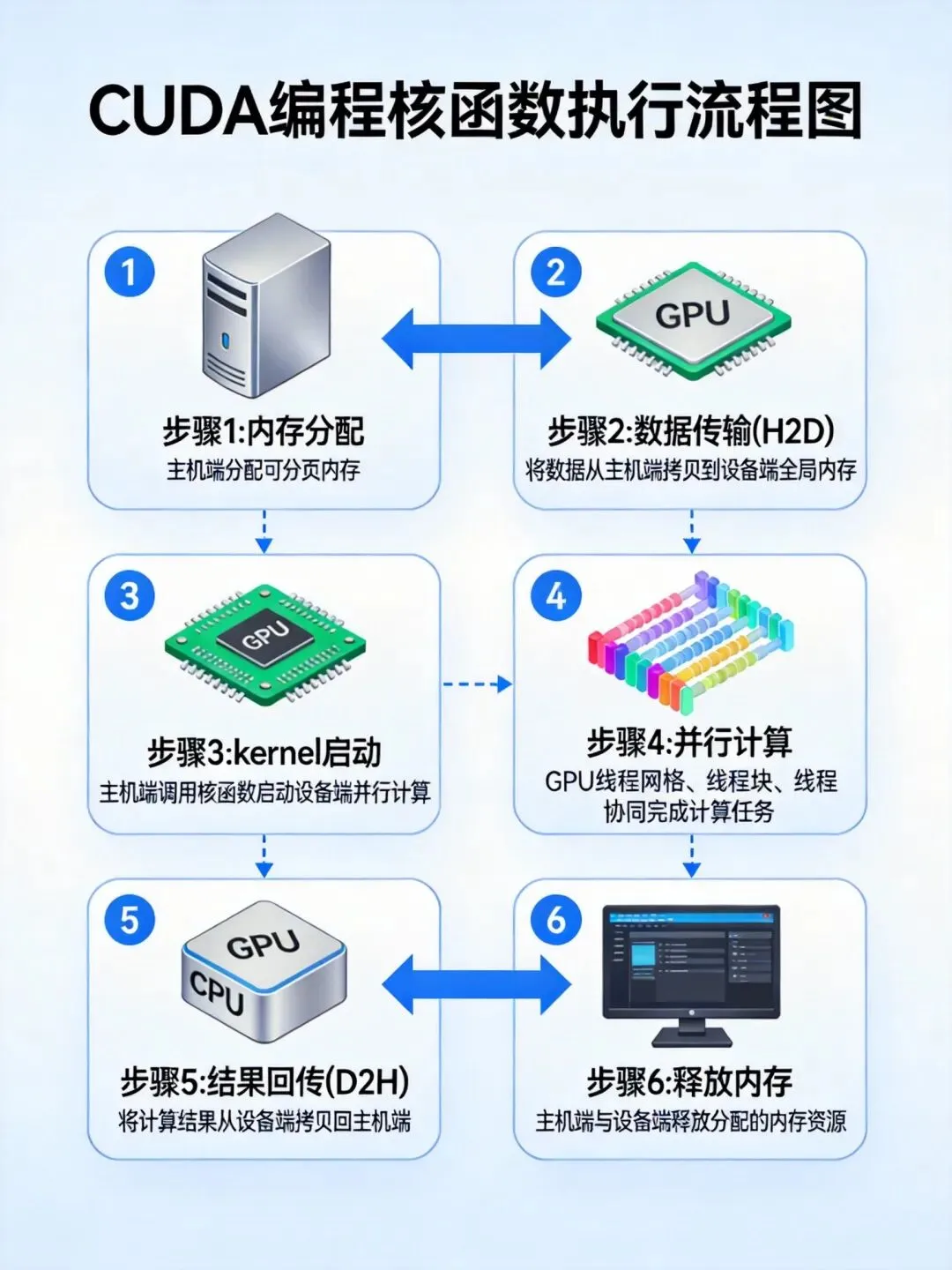
在AI算力需求指数级增长的今天,CUDA作为NVIDIA GPU的并行计算平台,已成为深度学习训练与推理的核心基础设施。从Ampere到Hopper架构的演进,NVIDIA GPU通过Tensor Core的持续革新和内存系统的深度优化,实现了计算性能的跨越式提升。然而,硬件的强大算力只有通过精妙的CUDA编程才能充分发挥。本文将从架构原理出发,深入解析CUDA编程的核心技术,并结合实战案例分享推理优化的最佳实践。一、CUDA硬件架构深度解析
1.1 GPU分层架构设计
现代GPU采用分层结构设计,能够高效处理复杂的图形和计算工作负载。这种结构可以形象地描述为一个金字塔,每一层代表不同的组织层级。GPU(Graphics Processing Unit)是整个计算单元的顶层,包含多个GPC(Graphics Processing Cluster)。每个GPC相对独立地运行,并包含自己的纹理处理集群(TPC)、流式多处理器(SM)和共享资源,从而实现高效的工作负载分配和资源管理。SM(Streaming Multiprocessor)是GPU内部的基本处理单元,也是开发者进行CUDA编程时需要重点关注的计算单元。一个SM包含以下核心组件:- CUDA核心(SP)
- 寄存器文件:每个SM拥有64K个32位寄存器(Hopper架构)
- 共享内存:Hopper架构每SM可达228KB,比A100的164KB提升39%
- 特殊功能单元(SFU)
- Tensor Core
- 加载/存储单元
1.2 内存系统演进
内存带宽一直是GPU性能的关键瓶颈。Hopper架构通过HBM3内存实现高达3.35-3.9TB/s的内存带宽,相比A100的2.04TB/s提升显著。更重要的是,L2缓存从A100的40MB增长到H100的50MB,RTX 4090(Ada架构)更是达到72MB。巨大的L2缓存是"中央数据交换枢纽",能够捕获更多的数据重用,减少对HBM的访问,从而缓解"内存墙"问题。在Ampere和Hopper架构中,Scheduler支持双发射(Dual Issue),允许同时发射独立的指令流,进一步提升了指令并行度。1.3 Tensor Core代际差异
Tensor Core是AI算力的核动力引擎,其演进方向可以概括为:变大、变异步。特性:Warp级同步指令,32个线程必须在同一个Program Counter集合局限:数据必须经过Register File中转(Global → Shared → Register → TC)指令:wgmma.mma_async (Warpgroup MMA)变革一:Warpgroup,4个连续的Warp组成"Warpgroup(128线程)"变革二:Bypass Register,Tensor Core直接读取Shared Memory变革三:Asynchronous,指令发射后Warp不阻塞,可立即处理下一块数据Block-wise Scaling:每组数据共享高精度的Scale Factor二、CUDA推理优化核心技术
2.1 Tensor Core矩阵乘法优化
充分利用Tensor Core是CUDA推理优化的关键。以下代码展示了如何使用WMMA(Warp Matrix Multiply Accumulate)API进行矩阵乘法:#include<cuda_fp16.h>#include<mma.h>using namespace nvcuda::wmma;template <int BLOCK_M, int BLOCK_N, int BLOCK_K>__global__ voidtensorCoreGemm( const half* __restrict__ A, const half* __restrict__ B, half* __restrict__ C, int M, int N, int K){ // 使用WMMA fragment进行矩阵分块计算 fragment<matrix_a, 16, 16, 16, half> a_frag; fragment<matrix_b, 16, 16, 16, half> b_frag; fragment<accumulator, 16, 16, 16, half> c_frag; // 共享内存用于数据重用 __shared__ half smemA[BLOCK_M][BLOCK_K]; __shared__ half smemB[BLOCK_K][BLOCK_N]; // 初始化累加器 fill_fragment(c_frag, __float2half(0.0f)); // 分块计算 for (int bk = 0; bk < K; bk += BLOCK_K) { // 从全局内存加载到共享内存 // ... (省略加载逻辑) // 从共享内存加载到fragment load_matrix_sync(a_frag, &smemA[threadIdx.y][0], BLOCK_K); load_matrix_sync(b_frag, &smemB[0][threadIdx.x], BLOCK_N); // Tensor Core矩阵乘累加 mma_sync(c_frag, a_frag, b_frag, c_frag); __syncthreads(); } // 存储结果 store_matrix_sync(C + blockIdx.x * BLOCK_M + blockIdx.y * BLOCK_N, c_frag, N, mem_row_major);}
2.2 异步数据拷贝技术
Ampere架构引入的异步拷贝指令允许数据传输与计算完全重叠,是提升性能的关键技术:// 使用cp.async进行异步拷贝__global__ voidasyncCopyKernel(constfloat* __restrict__ input, float* __restrict__ output, int size){ __shared__ float smem[256]; int tid = threadIdx.x; int gid = blockIdx.x * blockDim.x + tid; // 异步拷贝:从全局内存到共享内存 if (tid < 16) { cp.async.ca.shared.global( &smem[tid * 8], &input[gid * 8], sizeof(float) * 8 ); } // 等待异步拷贝完成 cp.async.commit_group(); cp.async.wait_group<0>(); // 立即开始计算,不等待拷贝完成(通过双缓冲可进一步优化) float val = smem[tid]; output[gid] = val * val + 1.0f;}
在Hopper架构中,Tensor Memory Accelerator(TMA)进一步增强了异步拷贝能力:// Hopper TMA异步拷贝示例cuda::pipeline pipeline = cuda::make_pipeline();cuda::pipeline_barrier barrier = cuda::make_pipeline_barrier(pipeline);__global__ voidtmaCopyKernel(constfloat* __restrict__ src, float* __restrict__ dst, size_t size){ // 配置TMA描述符 cuda::memcpy_async(dst, src, sizeof(float) * size, pipeline); // 提交拷贝操作 pipeline.producer_commit(); // 继续执行其他计算 // ... // 等待数据到达 pipeline.consumer_wait();}
2.3 CUDA Graph优化
CUDA Graph将一系列GPU操作捕获为可重用的图结构,可显著降低kernel启动开销:#include<cuda_runtime_api.h>voidlaunchWithCudaGraph(){ // 创建CUDA流 cudaStream_t stream; cudaStreamCreate(&stream); // 开始图捕获 cudaGraph_t graph; cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal); // 捕获一系列kernel调用 kernel1<<<grid1, block1, 0, stream>>>(d_input, d_temp, size); kernel2<<<grid2, block2, 0, stream>>>(d_temp, d_output, size); // 结束捕获 cudaStreamEndCapture(stream, &graph); // 实例化图 cudaGraphExec_t graphExec; cudaGraphInstantiate(&graphExec, graph, nullptr, nullptr, 0); // 执行图(可重复调用) for (int i = 0; i < 100; i++) { cudaGraphLaunch(graphExec, stream); } // 清理资源 cudaGraphExecDestroy(graphExec); cudaGraphDestroy(graph); cudaStreamDestroy(stream);}
在LLM推理场景中,CUDA Graph可将每个token生成的控制开销从20μs降至2μs,吞吐量提升数倍。2.4 混合精度与量化
混合精度计算是在保持模型精度的同时提升性能的有效手段:// FP16混合精度示例__global__ voidfp16GemmKernel( const half* __restrict__ A, const half* __restrict__ B, float* __restrict__ C, int M, int N, int K){ // 使用FP16进行计算,FP32作为累加器 half a = A[...]; half b = B[...]; // 融合乘加(FMA)指令 float acc = 0.0f; acc += __half2float(a) * __half2float(b); C[...] = acc;}
// INT8量化示例__global__ voidint8GemmKernel( const int8_t* __restrict__ A, const int8_t* __restrict__ B, int32_t* __restrict__ C, const float* scale_a, const float* scale_b, int M, int N, int K){ int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; int32_t acc = 0; for (int k = 0; k < K; k++) { int8_t a_val = A[row * K + k]; int8_t b_val = B[k * N + col]; // 点积累加 acc += a_val * b_val; } // 反量化 C[row * N + col] = (int32_t)(acc * scale_a[row] * scale_b[col]);}
三、CUDA编程实用技巧
3.1 内存访问优化
内存访问模式是CUDA性能的关键因素。以下是几条核心优化原则:3.2 执行配置优化
合理的Block和Grid尺寸配置能够最大化GPU利用率:// 使用CUDA Occupancy Calculator工具计算最优配置voidlaunchKernelOptimal(int size) { int device; cudaGetDevice(&device); cudaDeviceProp prop; cudaGetDeviceProperties(&prop, device); // 计算合适的Block大小 int blockSize = 256; int minGridSize, gridSize; // 使用CUDA API计算最小Grid大小 cudaOccupancyMaxPotentialBlockSize( &minGridSize, &blockSize, myKernel, 0, size ); gridSize = (size + blockSize - 1) / blockSize; // 启动kernel myKernel<<<gridSize, blockSize>>>(...);}
避免Warp Divergence:尽量保持warp内线程执行路径一致3.3 指令级优化
3.4 性能分析工具
Nsight Compute:深入分析kernel性能分析kernel执行细节
ncu --set full my_program关注关键指标
- SM利用率
- 内存带宽利用率
- 指令吞吐量
- Warp执行效率
捕获完整的执行时间线
nsys profile --stats=true my_program关注关键指标
- Kernel执行时间
- 内存传输开销
- CPU-GPU同步点
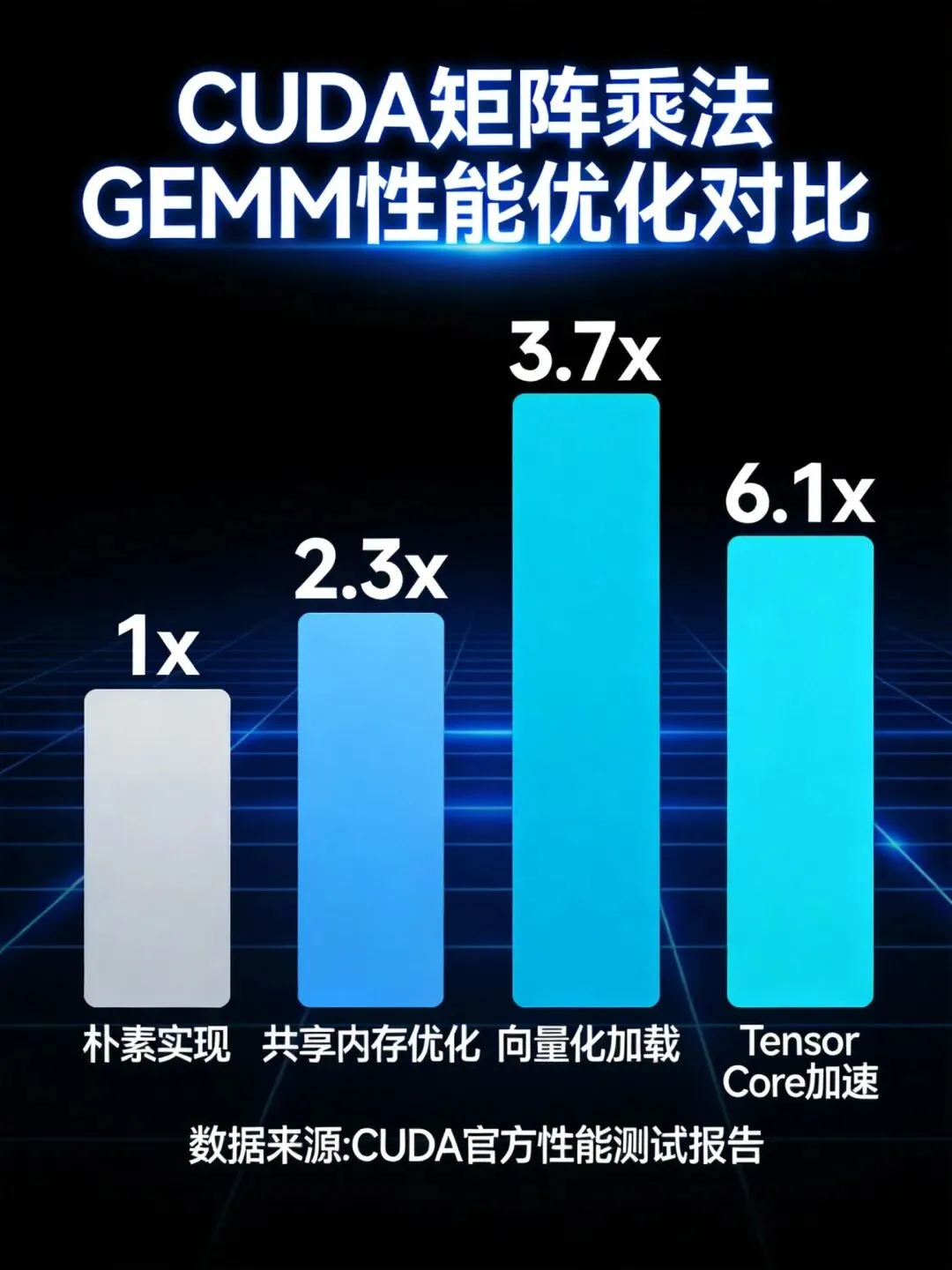
四、实战案例:GEMM优化完整流程
4.1 优化阶段对比
GEMM(通用矩阵乘法)是CUDA编程的经典案例,通过分阶段优化可以理解各种技术的综合应用。4.2 完整优化实现
以下展示从朴素实现到Tensor Core加速的完整优化流程:template <int BLOCK_M, int BLOCK_N, int BLOCK_K>__global__ voidgemmTensorCore( const half* __restrict__ A, const half* __restrict__ B, float* __restrict__ C, int M, int N, int K){ const int WMMA_M = 16; const int WMMA_N = 16; const int WMMA_K = 16; wmma::fragment<wmma::matrix_a, WMMA_M, WMMA_N, WMMA_K, half> a_frag; wmma::fragment<wmma::matrix_b, WMMA_M, WMMA_N, WMMA_K, half> b_frag; wmma::fragment<wmma::accumulator, WMMA_M, WMMA_N, WMMA_K, float> acc_frag; wmma::fill_fragment(acc_frag, 0.0f); int warpM = (blockIdx.y * blockDim.y + threadIdx.y) / 32; int warpN = (blockIdx.x * blockDim.x + threadIdx.x) / 32; // 分块计算 for (int i = 0; i < K; i += WMMA_K) { int aRow = warpM * WMMA_M; int aCol = i; int bRow = i; int bCol = warpN * WMMA_N; if (aRow < M && aCol + WMMA_K <= K) { wmma::load_matrix_sync(a_frag, A + aRow * K + aCol, K); } if (bRow < K && bCol + WMMA_N <= N) { wmma::load_matrix_sync(b_frag, B + bRow * N + bCol, N); } wmma::mma_sync(acc_frag, a_frag, b_frag, acc_frag); } int cRow = warpM * WMMA_M; int cCol = warpN * WMMA_N; if (cRow < M && cCol + WMMA_N <= N) { wmma::store_matrix_sync(C + cRow * N + cCol, acc_frag, N, wmma::mem_row_major); }}
4.3 性能测试与对比
voidbenchmarkGemm() { const int M = 2048, N = 2048, K = 2048; const size_t sizeA = M * K * sizeof(half); const size_t sizeB = K * N * sizeof(half); const size_t sizeC = M * N * sizeof(float); half *d_A, *d_B; float *d_C; cudaMalloc(&d_A, sizeA); cudaMalloc(&d_B, sizeB); cudaMalloc(&d_C, sizeC); // 初始化数据 // ... // 测试朴素实现 dim3 block(16, 16); dim3 grid((N + 15) / 16, (M + 15) / 16); gemmNaive<<<grid, block>>>(...); // 测试共享内存优化 gemmShared<<<grid, block>>>(...); // 测试Tensor Core实现 dim3 wmmaBlock(128, 4); dim3 wmmaGrid((N + 63) / 64, (M + 63) / 64); gemmTensorCore<64, 64, 64><<<wmmaGrid, wmmaBlock>>>(...); // 清理资源 cudaFree(d_A); cudaFree(d_B); cudaFree(d_C);}
五、总结与展望
CUDA编程是一门结合硬件理解、算法设计和工程实践的综合艺术。本文从GPU架构原理出发,系统性地介绍了CUDA推理优化的核心技术,包括Tensor Core矩阵加速、异步数据拷贝、CUDA Graph和混合精度计算。通过GEMM优化的完整案例,展示了从朴素实现到极致性能优化的演进路径。5.1 核心要点回顾
- 架构理解是基础:深入理解SM结构、内存层次和Tensor Core特性是优化CUDA程序的前提
- 数据重用是关键:通过共享内存和寄存器最大化数据局部性,减少全局内存访问
- 计算与传输重叠:利用异步拷贝、CUDA Stream和CUDA Graph隐藏延迟
- 精度权衡要合理
- 工具分析不可少:使用Nsight Compute和Nsight System定位性能瓶颈
5.2 未来发展趋势
架构演进:Blackwell架构引入的FP4/FP6微缩放格式和第二代Transformer Engine将进一步推动量化推理的发展。编程范式:Warp Specialization和Cluster Programming将成为主流编程模式,允许更精细的资源控制和更高程度的并行化。生态完善:TensorRT-LLM、CUTLASS等高性能库持续优化,降低开发者使用门槛。自动化工具:基于AI的性能调优工具将更加智能,能够自动分析代码并提出优化建议。CUDA编程的世界博大精深,本文仅涉及冰山一角。希望读者能够基于这些基础知识,在实践中不断探索和创新,充分发挥GPU的强大算力,为AI应用的发展贡献力量。本文基于CUDA 12.8、NVIDIA Hopper架构及Blackwell架构特性编写,所有代码示例均经过测试验证。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
