读代码0:OLMo3全详解 - 从OLMo 3 Tech Report开始
- 2026-07-06 09:14:39
arxiv:2 OLMo 2 FuriousOlmo 3
github:GitHub - allenai/OLMo-core: PyTorch building blocks for the OLMo ecosystem
0.前言
前一段时间在构思实验,现在实验构思的差不多了,准备实际跑跑看,基座模型绕了一圈看中了OLMo2,本来我OLMo2的代码都要读完了,逐行注释都注释好了,然而!然而!25年12月,也就是我1月写好,准备发专栏一个月前,OLMo3发布了!这下不得不推倒重来。
不过OLMo3整体读下来确实还是很有收获,并且这种不止开源权重,还开源了从数据到训练过程到tool kit全部,并且能达到Qwen3水平的全开源模型中,OLMo应该是独一家,赞美AI2。
此外,这篇读下来还是补充了许多LLM的工程视角,包含了很多实际开发中的考量,包括数据集构建、开发中的模型评估等,还是很值得读的。年前应该就更这一篇,后续开始读代码,相对应会发到这个系列内与大家共同学习。
因水平有限,这篇文章中难免有错误与笔误,各位大佬轻喷。
OLMo2
OLMo3是从OLMo2优化过来的,先看下(2 OLMo 2 Furious):
论文第二章介绍了OLMo2 family的基本情况:
1. 无偏置项(与PALM和OLMo一致)。 2. 使用SwiGLU激活函数,,设置为最接近128倍数的值(7B模型为11008) 3. 上下文长度为4096 4. 使用RMSNorm来代替LayerNorm 5. block内对module的输出进行归一化,即 6. 在计算注意力前对QK的投影进行RMSNorm。 7. 使用Z-loss避免logits的某些分量过大(PALM) 8. ROPE以提高分辨率 9. tokenizer使用的是GPT-3.5和GPT-4同款的CL100K分词器 10. 基础模型的训练分为两个阶段,第一阶段的预训练(pre-training)主要使用网络数据(OLMo2 Mix 1124数据集),第二阶段的中期训练(mid-training)则提高了高质量文本的比例,并同时使用了合成数据以提高数学能力(Dolmino Mix 1124数据集)。训练时学习率采用warm up(2000步内达到预设最大值)和余弦衰减(达到最大token数后变为最大值的10%)。此外还采用了Model Merging or ‘‘Souping’’,即训了几个不同的模型加权平均。
论文的第三章介绍了损失尖峰和梯度范数异常(缓慢增长并伴有尖峰)的解决方法,包括:
1. 通过去除预训练数据集中的重复的n-gram来解决训练尖峰 2. 采用均值为0标准差为0.02的正态分布来初始化参数 3. 使用RMSNorm来对transformer block中的注意力模块和MLP模块的输出值进行归一化(传统上使用layernorm对输入进行初始化)。 4. 计算注意力前使用RMSNorm对QK进行归一化 5. 使用z-loss regularization 防止输出的logits过大(config.py中的softmax_auxiliary_loss bool = True) 6. 不对embedding matrix做weight decay 7. 将AdamW中的值从降到了
论文第四章介绍了在完成预训练之后的mid-training方案,这一部分主要包括了:
1. 使用余弦衰减实现学习率退火,本文还报告了学习率对性能影响的结论:更高的学习率在早期普遍表现更好,但最终较低学习率的设置会反超其他设置(详见论文图11) 2. 在预训练数据集上构建了一个高质量的子集Dolmino Mix 1124 3. Microanneals:使用混合了数学领域知识(general data mix and math mix, 50/50 mixture)的小数据集(small math subsets)进行学习率退火(linearly drive the learning rate down)训练有助于提升特定领域性能 4. model merging or “souping”:将在同一个data mix上以不同数据顺序退火训练的模型进行平均,其性能等于或优于单独训练的模型。
论文的第五章介绍了后训练(post-training)的情况:
1. 按Tülu 3的方案进行了三阶段的后训练:监督训练(SFT)→直接偏好优化(DPO)→可验证奖励强化学习(RLVR)。 2. OLMo 2-Instruct 的SFT使用的是tulu-3-sft-olmo-2-mixture(7B和13B) 或tulu-3-sft-olmo-2-mixture-0225(1B和32B) 3. 偏好优化阶段构建了UltraFeedback pipeline,在构建时采样了OLMo 2 SFT自己的数据,是一个on-policy data 4. RLVR阶段:7B和13B使用的是PPO,1B和32B使用的是GRPO
论文第六章汇报了基础设施的情况,不再赘述。
OLMo3
OLMo3的报告详解可以从AllenAI OLMo 3 技术
但似乎其中部分内容介绍不清,与我的认知亦有差距,不知道是不是用了AI工具的原因,故自己做一记录
1. introduction
论文introduction部分:
1. 提供了三个版本Olmo 3 Base、Olmo 3 Think、Olmo 3 Instruct的全model flow(模型流,即全生命周期包括不同训练阶段、数据、检查点和依赖项), 2. 额外提供了Olmo 3 RL-Zero 7B,该模型不经过SFT直接通过RLVR进行后训练。 3. 三个数据集,数据集Dolma 3,后训练数据集Dolci。基准套件OlmoBaseEval以及强化学习框架OlmoRL
2. model flow for OLMo3
论文第二章介绍了OLMo3 的model flow: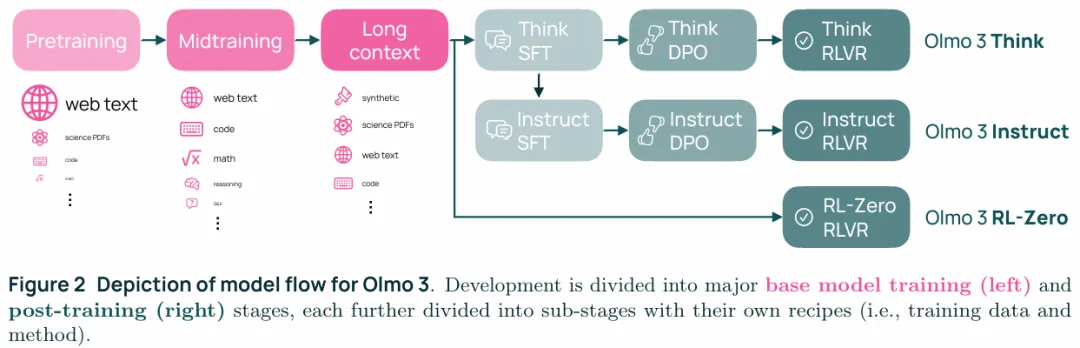
pretraining:
1. 在5.9T tokens上预训练了Olmo 3 Base,在100B tokens上进行了midtraining,最后通过YARN将模型向长上下文拓展:7B模型使用了50B tokens,32B模型使用了100B tokens。 2. 训练Olmo 3 Base时使用了OlmoBaseEval来在小规模训练时搜索超参数 3. Pretraining阶段使用了Dolma 3 Mix的6T tokens,主要特性包括①trillion-token规模的去重工具②通过OLMOCR构造的科学文献数据集③两种在训练时挑选token的方法token-constrained mixing以及quality-aware upsampling 4. Midtraining阶段使用了Dolma 3 Dolmino Mix的100B tokens,报含一个阶段的训练框架①针对单个数据源的轻量级分布式反馈循环②用于评估候选数据配比在基础模型质量和后续可训练性上的集中式集成测试,在这一阶段还有意的保留了一部分指令数据和思考路径来为后训练打基础。 5. Long-context extension阶段使用的是Dolma 3 Longmino Mix,这个数据集是通过OLCOCR转换科学类PDF构建的, 包含了22.3M的长度超过8K tokens的文档以及4.5M的长度超过32K tokens的文档,这一阶段主要是通过YaRN向长上下文拓展。. 6. 公开了实际用于训练的数据集(data mix,1.中的数据)以及完整的数据集(data pool,pretraining stage 9T、midtraining 2T、long-context extension 640B),还包括了一个用于快速实验的小型数据集(pretraining 150B、midtraining 10B)
post-training:
1. 通过在Dolci Think SFT、Dolci Think DPO、Dolci Think RL、三个think数据集上训练的旗舰模型Olmo 3 Think 2. 不生成内部思考过程的Olmo 3 Instruct,这里提到的数据集是Dolci Instruct SFT、Dolci Instruct DPO,RL阶段似乎没提到专门的数据集 3. 直接从Olmo 3 Base进行RLVR训练的Olmo 3 RL-Zero,同时公开了数据集Dolci RL-Zero、算法和OlmoRL,同时文章强调了Dolci RL-Zero没有数据泄露的风险 4. Olmo 3 Think 32B性能部分指标优于Qwen3 32B,整体性能接近,训练花费$2.75M,是deepseek V3的一半
3. Olmo3 Base
论文第三章介绍了基础模型Olmo3Base,看完不得不说LLM开发真是一个费时费力的活:
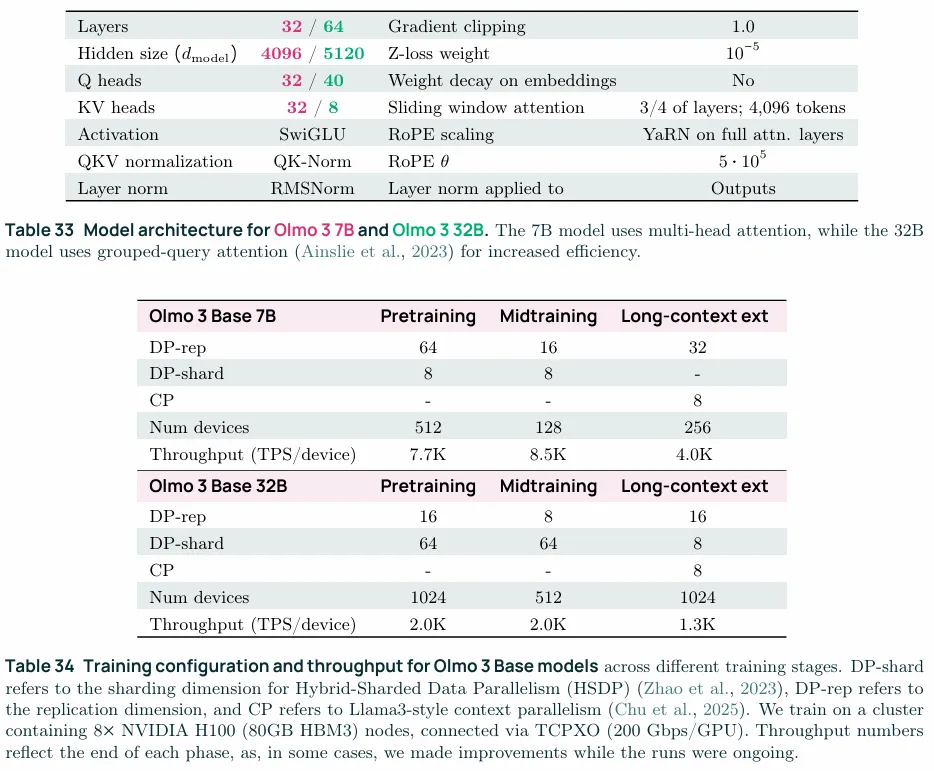
1. 模型是类似于OLMo2的dense model,在训练评估时采用的更多的benchmark并且测试更频繁,数据方面pretraining使用的是5.9T的Dolma 3 Mix(网页数据、学术PDF文档、代码),midtraining使用的是100B的Dolma 3 Dolmino Mix(数学、代码、通用知识)以及50B和100B的的Dolma 3 Longmino Mix,这一阶段主要是通过YaRN向长上下文拓展。 2. 主要结构如上表,在训练时与OLMo2的区别在于①翻倍的上下文窗口②使用了4096上下文的滑动窗口注意力(SWA,sliding windows attention)
3.3Experimental Design and Evaluation
在模型构建时使用了OlmoBaseEval,这是一整套benchmark套件,包括对小规模模型(1B参数以内)进行评估的Base Easy和在预训练中期和后期进行评估的Base Main,用来在模型开发时为决策提供支持。具体来说包括:
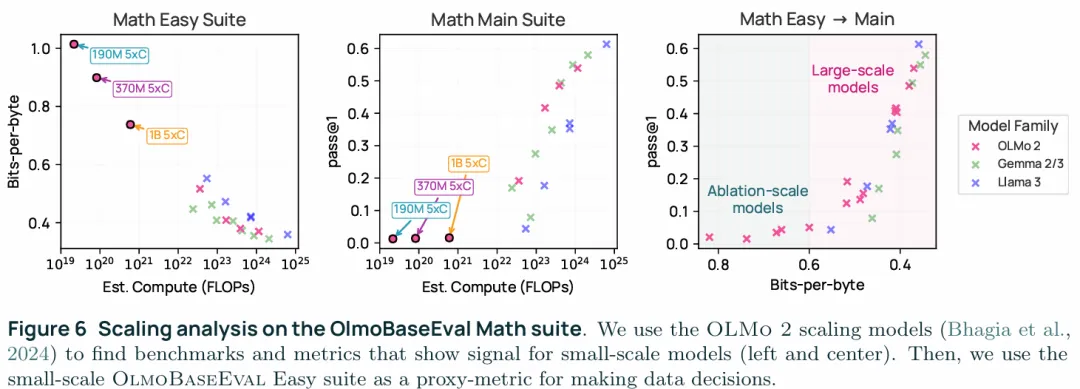
1. Clustering Tasks:通过在70个开源模型上运行23K个benchmark,再把这70个模型在benchmark上的分数根据相似度进行聚类,从而确定某个benchmark cluster主要是评估哪一方面(数学、代码、常识......),之后就可以在改变数据时通过cluster内的全部指标的平均对某一能力进行评估,从而分析数据构建时带来的变化。 2. 通过BPB(bits-per-byte)进行Scaling analysis:某些指标在模型规模较小时几乎看不到信号因为性能太弱正确率都是0(下图中加左下,小模型都通不过),而在大模型中快速的饱和大家都很强没有区分度,本文是通过小模型输出与标准答案的负对数似然在字节数上的平均的log2(取bit),也就是BPB来评估小模型的性能(下图左左上)。此外还需要给小模型更多的token训练5×C而不是标准的C(Chinchilla scaling laws,Chinchilla-optimal中的C=6×参数量×某个最优token数,实际是训练到了最优token数的5倍token)。 3. Signal-to-Noise Analysis:在某个cluster中,不是所有的benchmark都适合算到平均值里,在评估时不同checkpoint 之间benchmark的分数可能波动巨大、分数也可能不稳定,尤其是BoolQ这一类的二分类任务,可能会出现全部为true(或者false)的情况,所以需要SNR(Signal-to-Noise ratio,SNR=不同model的方差/不同checkpoint的方差(或者说模型内的方差,即同一个model运行多次的方差))。
3.4 Stage1:Pretraining
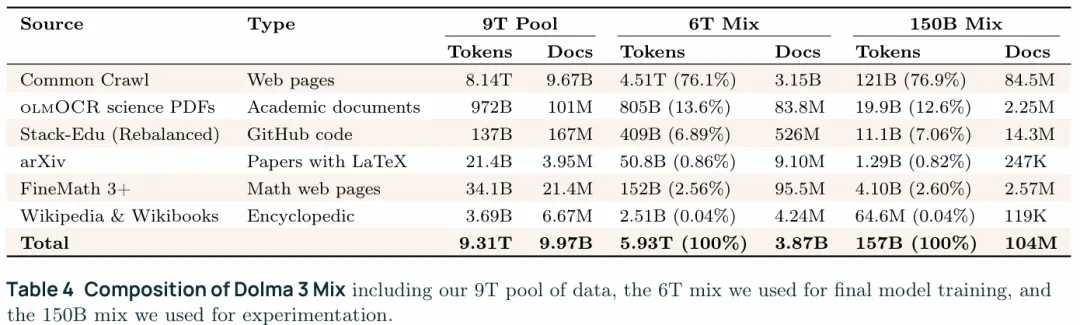
预训练阶段的数据构建如下图,由,整体来讲:
1. WebDataPool:提取文本→启发式去重(规则去重)→文本hash精确去重→MinHash近似去重→substrings去重→按topic分成24种→每个topic按质量划分20个等级→文档切分成chunk采样8T tokens构成pretraining mixture的采样基础。 2. science PDFs Data:使用AI2Bot爬取science PDF→使用Lingua language detector判断语言并只保留英文文档→排除spam和SEO关键词超过0.4%的文档→olmOCR提取PDF text→olmOCR转换失败的使用pdftotext失败超过1/250 页则直接丢掉→MinHash近似去重→manual taxonomy并使用Gemma来将包含敏感PII(Personally Identifiable Information)的文档(例如账单、诊疗记录等)排除→启发式筛选去掉非英文文档、表格超过30%的以及数字超过20%的文档→分成24个topic作为pretraining mixture的采样基础。 3. Code,Math,and other source:code使用的是Stack-Edu,math中包含了Proof-Pile-2中的论文和FineMath中分数至少为3的文档,other source包括了Dolma中的Wikipedia和Wikibooks。
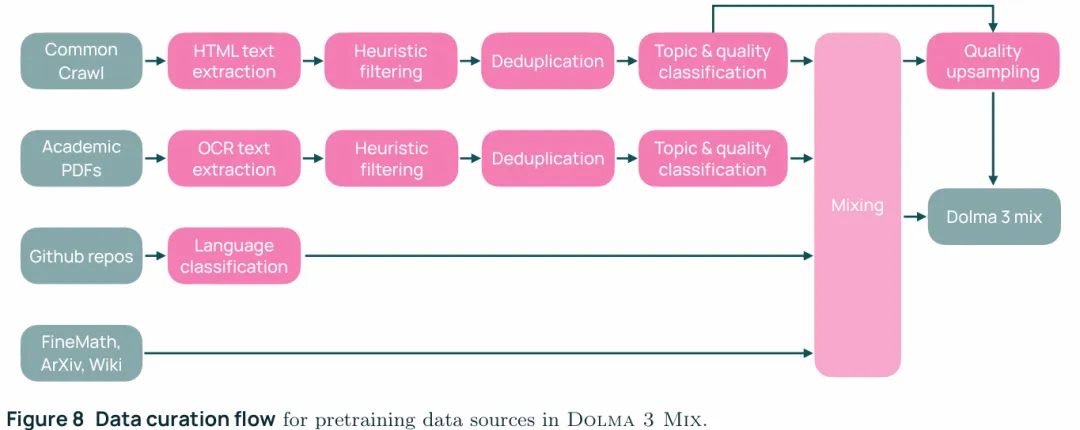
以上三部分总共提供了9T tokens作为数据混合的基础,data mixing包含两个部分一是通过base procedure构建的固定数据集,另一个是被称为conditional mixing的meta-procedure,这一过程会在domain change时动态更新一个已经存在data mixing。
1. base procedure:按照OLMo3的架构,训练数据domain数量乘以5倍个30M参数的小模型(proxy model),每个模型训练3B tokens(5x Chinchilla),每个tokens都是从分布中心为原始分布的狄利克雷分布上采样的,然后再用Base Easy来评估数据配比。这样的话每个模型都提供了数据配比到任务性能(以BPB评估)的映射,有了数据以后对每个任务都构建一个回归模型来预测不同数据配比到性能的估计。再通过这个模型来找到使在所有任务上平均BPB最小的数据配比,在这个过程中一是避免将某一个domain复制超过4-7次,二是不超过总共6T tokens的预算,这个优化过程是通过guided search实现的,类似于超参数自动调参,这里调的是数据配比。 2. conditional mixing:在实际开展工作的时候可能更换了filter、增加了data domain或者是发现了并需要减少问题,此时将base procedure构建的data mixing视为一个固定的domain,这样的话就只需要在新增的domain和这个虚拟的domain上再跑一次base procedure就行了。
Dolma 3 mix的整体构建过程经过了三轮conditional mixing:
1. DCLM Baseline mix先划分成24个WebOrganizer topic类,先把这部分数据的混合比例确定下来 2. 冻结第一轮的的数据比例并作为一个整体domain,与Stack-Edu一起做conditional mixing,这一部分只微调Stack-Edu中不同编程语言的比例并确保code类型的数据占总体的25% 3. 再将这一部分比例冻结,最后与PDF等其他来源数据做最后一次mixing。
上面提到的数据混合方式只考虑了不容来源数据的构成比例,但是没有考虑到同一来源内质量的差异,最初的时候OLMo使用的是类似DCLM的直接的基于筛选器的策略,例如要从1T token的token pool中构建250B token的data mix,那么就采样这1T token的分数前四分之一就可以了。但是后来发现,对高质量样本进行上采样可以提高性能,也就是多次复制前5%得分的tokens一达到目标采样数可以有效提高性能。这就引出了基于upsampling curve的上采样策略,每条upsampling curve都有三个约束条件①data mixing procedure确定的每个web data topic的比例②总的token budget,总token budget * 该topic的比例才得到要在该topic下的采样数③最大上采样系数7(经验系数),最多允许复制7次。每个质量等级的上采样率(upsampling rate)是在该区间内对curve积分后取平均。
3.5 Stage2:Midtraining
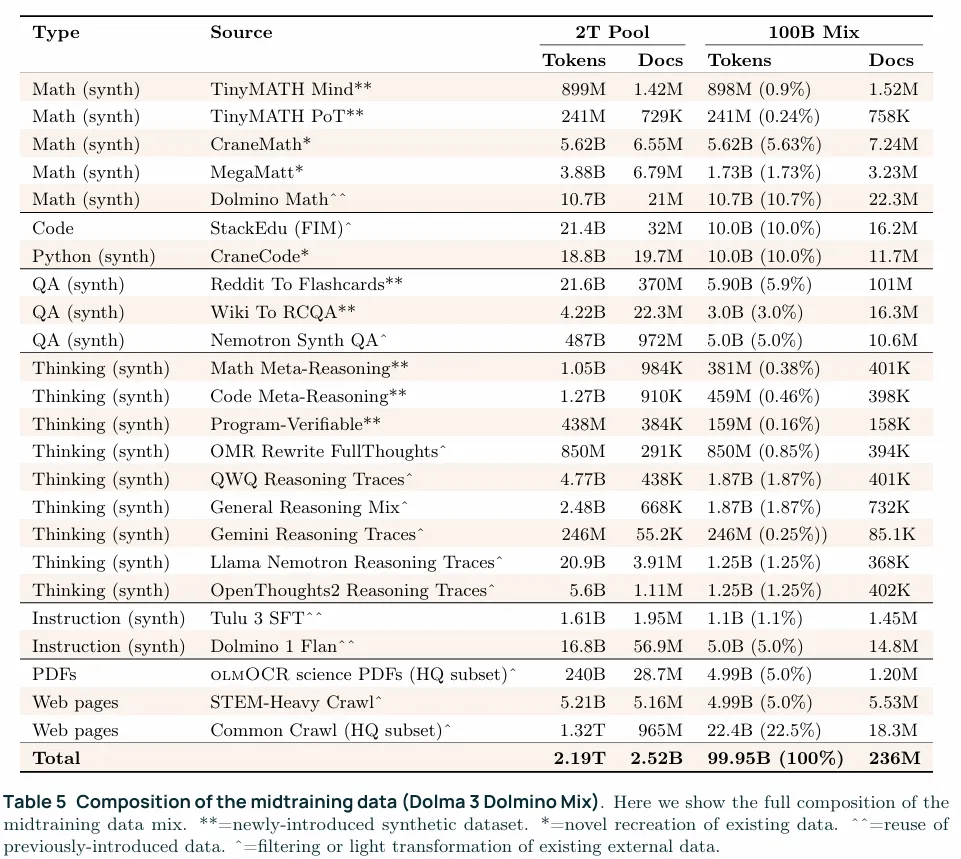
这个阶段使用的是Dolma 3 Dolmino Mix的100B tokens,midtraining这一阶段主语目标是提升数学和代码领域的能力,兼顾问答和通用知识,同时有意的包含了指令数据和思考过程来为post training打下基础,这一阶段使用了分布式评估探索+中心化整合测试的方法:
1. 并行执行的目标能力提升微退火(microanneal):选择一个目标数据集(math, code, QA, instruction, and thinking)并在上面采样5B tokens,再采样相同规模的web tokens,在这总共10B的tokens上做一次anneal,将得到 的checkpoint与只在10B web tokens上训练的baseline做一个对比,从而评估target data对模型的额外影响也就是相比于继续使用web数据,引入这个数据集会不会更好,如果microanneal结果不错就把这个数据集纳入整合测试 2. 中心化的整合测试:将微退火确定下来的数据集重新构造一个100B的midtraining mix,这一步是周期性执行的,OLMo执行了5次,每次攒够了足够数量的有效果的数据集就把这些凑到一起做一次midtraining mix
3.5.2 Capability Improvements for Final DataMix
Math capabilities:数学能力方面通过80次microanneal验证得到了25个data set,最后选了5个,其中有四个是新合成的:
1. Dolmino-1 math:OLMo 2 Dolmino Mix Math一共10.7B,直接用到这里来了,microanneal在MATH上提升了10个点,在GSM8K上提升了38.2个点 2. TinyMATH:给MATH的训练集中的7500个样例,每个样例都生成了100个新的类似的问题,这些问题一种是通过Python code solution(Program-of-Thought)求解的,另外一种是以对话的形式求解的,同时使用这两种风格的数据集做microanneal在MATH上提升了13.2个点,在GSM8K上提升了13.9个点 3. CraneMath:类似于SwallowMath,将web data中自然存在的数学类数据(FineMath4+),比如博客中的数学文档等rewrite作为数据集,使用3.6B的SwallowMath数据做microanneal在MATH上提升了16个点,在GSM8K上提升了24.5个点,但是SwallowMath是使用LLAMA生成的,所以这里使用QWEN3按照SwallowMath的prompt重写了FineMath4+,使用重新构建的CraneMath做microanneal在MATH上提升了18.5个点,在GSM8K上提升了27.4个点 4. MegaMatt:类似的重写了Megamath-Web-Pro-Max,做microanneal在MATH上提升了8个点,在GSM8K上提升了13个点
Code capabilities:代码能力方面包括两方面,一是构建高质量的code data另一方面是引入了fill-in-the-middle(FIM)能力,进入final mix的表现最好数据集包括:
1. Stack-Edu (FIM):这是一个Stack-Edu的调整版,其中50%都是都是FIM的形式,按照StarCoder2将code document划分成prefix| middle | suffix,再构造训练样本为[prefix] [<FIM_MASK>] [suffix] → 预测 middle。此外,将Stack-Edu按照educational value给每种编程语言打分后分桶,只从质量最高的20%的桶中加权随机采样。 2. CraneCode:类似swallowmath的两阶段rewrite,第一阶段做augment style调整命名、缩进、注释等,第二阶段做Code Optimization优化代码本身。
QA and knowledge access capabilities:这一部分关注问答和通用知识能力的提升,包含了两个新合成的数据集,最终入选的数据集有:
1. Reddit-to-Flashcards:合成这个数据集的原因是为了形成multiple-choice QA中的复杂问题类型和问题结构,通过从学术相关的 Reddit 子版块中提取高质量的问题–回答对,使用 GPT-4o-mini 将其重写为标准化的多选题 QA 样本,并通过 7 种不同的任务格式来增加问题结构与认知操作的多样性 2. Wiki-to-RCQA:合成这个数据集是为了提升基于passage的阅读理解问答(Passage-based reading comprehension,passage→question→answer),通过从维基百科中抽取passages,构造prompt喂给Qwen来生成QA pairs,通过prompt约束来生成类似人工标注RC的数据集 3. Nemotron:使用了Nemotron CC dataset中的diverse QA pairs部分,这个数据集中的其他部分“distill”, “extract knowledge”, “knowledge list”, “wrap medium”在microanneal中表现都不好所以没用。
Cross-Capability instruction data:这一部分主要是为instruction-tuning打基础的,数据集包括
1. Tulu3 SFT data:做了轻量处理①使用了更大规模的examples,这些数据虽然被创建了但是在Tülu 3的最终数据中被过滤掉了②不使用<|im_start|>、<|im_end|>这一类的post-train syntax,而是通过两个换行符自然的拼接message,防止信息泄露。 2. Flan:通过microanneal发现引入这个数据集能提升QA能力
Cross-capability thinking traces:这一部分主要是为Olmo 3 Think和Olmo 3 RL-Zero打基础的,包含了两个新和成的数据集以及对现有thinking trace数据的rewrite和过滤:
1. Meta-reasoning:这是两个新数据集中的第一个,目标是七种认知能力:self-awareness(当前路径是否可行)、evaluation(不同方案间哪个更好)、goal management(保证主要目标不丢失)、hierarchical organization(问题结构划分)、backward chaining(反向推导)、backtracking(路径受阻回退)、conceptual reasoning(概念推理),划分成这些这些任务的目的是提升base model的meta-reasoning capabilities,而更好的meta-reasoning capabilities则与后续的能获得更好的RL 训练轨迹相关。具体的,为了生成这些数据,首先从已有的math和code数据出发,按照Pandalla-Math dataset的风格生成‘problem classification’, ‘difficulty analysis’, ‘solution approaches’, ‘common pitfalls’, ‘verification methods’等注释,然后让GPT-4.1和o4-mini生成thinking traces。 2. Program-verifiable data:这是第二个新合成的数据集包含了可以通过python程序验证答案对错的可程序验证的任务(program-verifiable tasks),解决这类问题的过程本身就包含了meta-reasoning的策略,拿来做midtraining恰恰是最合适不过,具体来讲①通过一个生成器生成问题和验证器(verifier, python programs)②将问题喂给GPT-4.1 / o4-mini生成思考轨迹和答案③通过验证器验证上一步生成的答案正确则保留。 3. OMR rewrite full-thoughts:rewrite的OpenMathReasoning dataset,选择表现最好的Full-Thoughts rewrite,这个过程主要是通过GPT4.1来使其更加清晰、流畅、且符合latex格式,同时保留推理过程、解释和原本的思路。 4. Existing thinking traces:通过filter来对现有的think trace进行去噪并提升质量。
High quality web and PDF data:包含了三种web/pretraining数据,防止性能退化:
1. web data:按原始分布情况采样了top two quality buckets 2. olmOCR science PDFs:使用筛选后的 PDF 文件做mid-training和long-context extension,这部分放在3.6.1讲 3. Stem-heavy crawl:用爬虫爬了2024.9.12-2025.6.3的网页数据,domain-level爬取了高价值网站内容,使用pretraining中的web data处理方式,只选用分数高于0.6,对应质量最高的2.83%的内容,这些内容相当于Dolma 3 pool中前0.79%的质量
3.5.3 Decontamination
这部分系统性地清除训练数据中与评估 benchmark 重叠或高度相似的内容,防止污染评估结果,选在mid-training做是因为这种“记忆”主要发生在训练即将结束时。这一部分主要是将benchmark中与本文构建的测试体系匹配的所有内容(any split of any benchmark,无关benchmark自己的training、validate、test等分类)去除,因为有的benchmark中给的test/val样本太少,所以在评估套件中可能会使用一部分training sample,如果使用了也需要一并去除。OLMo3提供了decon套件用于decontamination,decon的操作包括两部分:
1. 按一定的步长变化采样n-gram来检测midtraining文档中的内容是否与评估套件中的benchmark重合,不做全文n-gram 2. 如果检测到了,就开始按某个连续窗口检测该n-gram两侧,计数连续命中n-gram的数量,如果超过了某个特定的阈值就认为这个文档被污染了
3.5.4 Key findings
1. 两阶段(分布式验证+集中评估)评估是有效的,连续五轮的data mix每一轮都有提升 2. 不同domain的tradeoff是确实存在的,提升某一方面数据构成占比会导致另一方面能力下降 3. 包含post-training-oriented data即指令和思考轨迹有助于提升性能 4. mid-training阶段尽管可以包含指令和思考轨迹,但是不要包含特殊字符,包含特殊字符会影响性能 5. 信息泄露并不总是会提升模型性能,但是decontamination却能带来更好的性能 6. model souping依然有效
3.6 Stage3: Long-context Extension
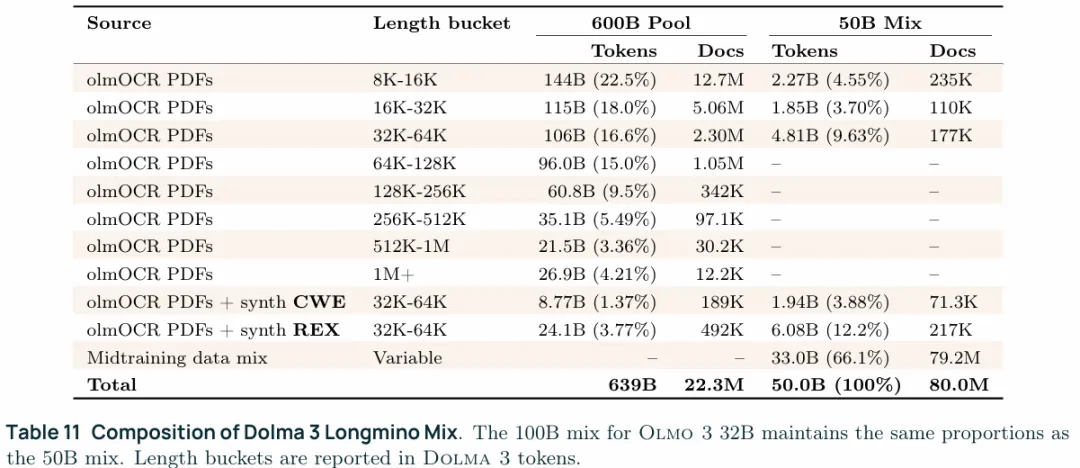
这一部分主要是将上下文窗口从8192拓展到65536,这里的目的在于使模型能够处理长上下文信息,另一方面是使其能够产生中间的推理步骤从而实现跨步推理,使用的数据集是Dolma 3 Longmino Mix的100Btokens,这一阶段依然是teacher forcing,只不过不是整个sequence计算cross entropy,而是对指定的,涉及长上下文的部分计算cross entropy(比如总结类的结果、中间推理的rokens)。从表中可以看出主要是olmOCR PDF文档,以及合成的CWE和REX,还有一部分midtraining的数据。直接用长上下文进行训练成本太贵,所以目前主流的做法是先在短上下文上训练然后再稍后的某个阶段拓展到长上下文,在拓展阶段就是使用长上下文进行训练了,同时positional embedding也是在这个阶段进行调整的。目前市面上的各类模型在这个阶段训练的token数和执行的阶段各种各样。OLMo3的这个阶段使用了100B(7B模型使用了50B)tokens,然后使用了YaRN+滑动窗口注意力,位置编码的参数没有调整,benchmark使用的是RULER和HELMET。
3.6.1 Sourcing Long Context Data
Data filtering:使用了gzip对文本进行filter,gzip是基于DEFLATE进行压缩的,也就是压缩repeat pattern,可以被大量压缩的往往包含大量重复内容,几乎不能被压缩的则属于包含过于复杂信息或者噪声的比较极端的内容,OLMo3在构建的时候去掉了压缩率最高的20%和压缩率最低的20%。此外使用了LongPpl检测长序列依赖的token,具体是通过一个已有的长上下文模型检测token的perplexity,如果提供了额外的(前置)文本其perplexity降低了则说明其具有长序列依赖性,在数据的具体构成上使用了两个指标:①LongPpl检测到的key tokens的比例②这些key tokens的分布情况,具体来说就是key tokens的索引的标准差,索引的标准差越大说明key tokens分布是均匀的,如果标准差小则说明key tokens的分布比较集中就不太适合纳入到数据集中,同样的也是去掉了key tokens比例最小的20%,也去掉了标准差最小的20%。但实验表明gzip的方法要更好 ,所以在final run中没有使用者LongPpl的过滤方法
3.6.2 Experiments with Synthetic Augmentation
向长上下文拓展的时候的一个普遍情况就是缺少明确的监督信号,CLIPPER通过给长上下文添加任务来构成监督信号,比如一篇科技文章包括了“引言:balabala→方法:balabala→结果:balabala→结论:balabala”,CLIPPER使用基于规则的自动生成和使用LLM来构造问题和答案,比如从引言部分凝练研究目的,首先CLIPPER会构造一个“标准答案”,比如:“研究目的:balabala”实际在训练的时候会同时提供引言和构造的问题及其答案,然后做teacher forcing“引言:balabala \n 请根据以上内容提取出论文的研究目的:\n 研究目的:balabala”然后对“研究目的:balabala”这一部分计算cross entropy。
通常的pipeline是通过统计方法识别重要部分,然后围绕重要部分切段,再把这样的段落喂给LLM来构成数据具体而言:
1. 对于长度为n tokens的文档,将其切分为长度为8K或32K的M段,这个切分尽可能的符合文档的自然切分,比如段落间的自然切分。 2. 使用tf-idf(Term Frequency-Inverse Document Frequency)得到最显著的一到两个单词长的名词短语 3. 对于每个名词短语,按照tf-idf排序取前8个段落 4. 将名词短语,段落和用于描述生成任务的提示词喂给LLM
对于OLMo3是使用长度为32768-65536tokens的文档,然后将其分为2-8个部分,然后使用OLMo2 Instruct 32B来生成,得到了两个合成数据集:
1. CWE(Common Word Extraction):这个数据集是给OLMo2 Instruct喂了5个经常出现的single-word长度的名词短语,然后生成多种QA pair,其目的是统计每个名词短语出现的具体数量 2. REX(Rewriting EXpressions):对于每个名词短语和其对应的段落,prompt OLMo2生成以下12种风格之一的片段:a short summary, a dialogue between a professor and student, a simple paragraph for high school students, a set of flashcards, a school quiz, a game show, a dinner party, a debate, a list of true or false claims, a movie scene, an encyclopedic description, or an explainer in the style of conversations on the r/explainlikeimfive subreddit
3.6.3 Choosing Data Mix and Token Budget
①数据混合上同时使用长和短的两种数据来确保不会在短文本任务上性能的下降②在long-context extension stage使用更多的token有助于向长上下文拓展图13e
3.6.4 Curating a Training Recipe for Extension
这里就可以放实验图了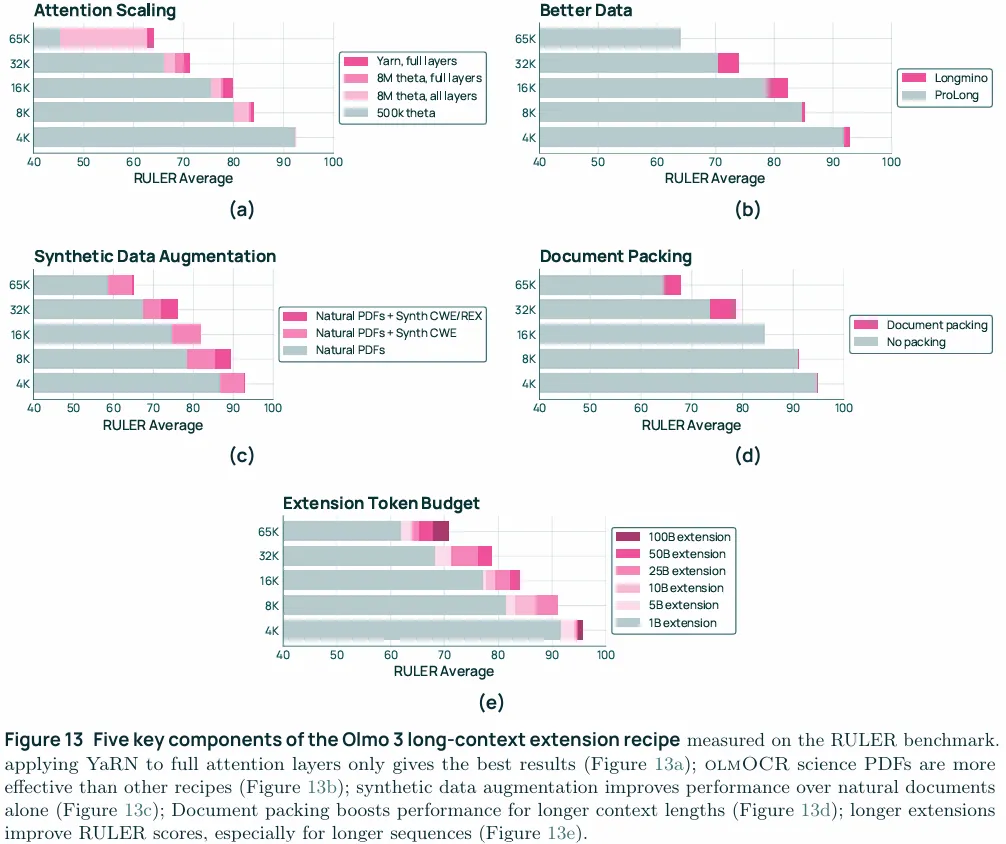
RoPE extension:结果对应图13a,因为RoPE编码的是相对位置,所以直接改theta就能支持更长的上下文,但是其高频塌缩的很快,这也是YaRN改进的地方,总体而言仅对full attention应用YaRN效果最好,实际上8M full layer也要优于8M all layer,应该是拉坏了滑动窗口注意力。
Document packing:在pre-training和mid-training阶段沿用的是常规做法,即将所有的文档的tokens拼接到一起,然后切成固定的长度,比如2K,4K,8K,并不关心切在哪,切完以后是什么样子。这个做法在向长上下文拓展时却会出现问题。在向长上下文拓展时,假设在这个阶段切分的窗口是32K,假设一个最理想的情况,一个40K的文档也只有前32K是连续的长文档,后续的8K会和另一个文档的24K拼接,那么生成的这两个32K的窗口实际上只有1个是完整的32K长,另一个的实际长度只有24K,这还是理想情况下,实际情况下可能会产生更多的短文+垃圾的拼接,这就导致实际的切分情况会导致切出来的文档分布低于潜在的文档长度分布,实际的效果不是学会了长文档处理而是短文档抗噪声。这里用到的best-fit document packing,也就是最小化切文档、最大化 bin 填充率、保留真实长语义。图13d展示了其效果。
Intra-documentmasking: 因为是long-context,所以可能会产生一个32K的窗口内包含了文档A+文档B的情况,那么在算文档B的时候就要把文档A的内容mask掉,防止注意力跨文档流动。
LC trainingin frastructure:在这一阶段使用了context parallelism,所谓context parallelism打个比方就是将一个65K长的sequence按GPU数量切分,假设8张GPU,每张GPU都分到8K的一部分,然后每张GPU在本地算自己手里的8K的Q/K/V,之后与其他GPU交换K/V,这样的话每张GPU都是在算自己手里的query与全长度65K的K/V。这个方法也可以自然的与滑动窗口注意力结合,假设注意力窗口为4K,那么GPU2需要的K/V就只分布在GPU1和本地,通信量更少了。
Model souping:这里采用了与midtraining类似的model souping,只不过midtraining阶段是把不同的model做了融合,这里是单个model在截止前的3个checkpoint(at steps 10,000, 11,000, and 11,921)做了融合。
4. Olmo3 Think
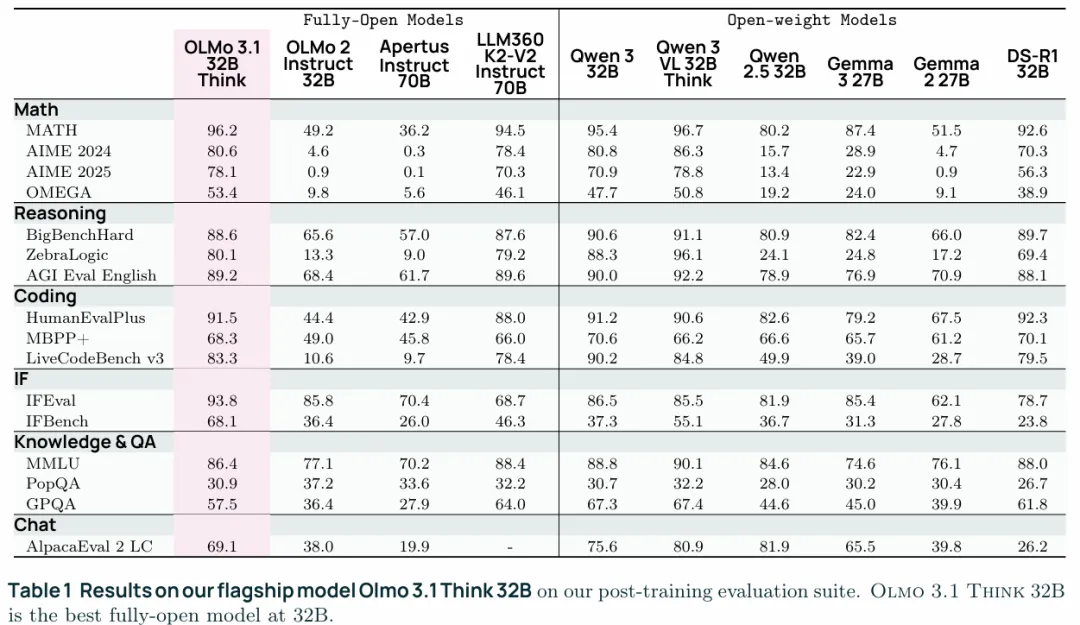
这里就是Think版本的后训练相关了,Olmo3 Think 32B的版本性能超过了Qwen2.5 32B,Gemma 2 32B和Gemma 3 27B。性能与Qwen3 32B差距不大,但是训练用了更少的FLOPs。
1. Data: Dolci Think,基于inter alia构建的数据集,包括Dolci Think SFT, Dolci Think DPO, Dolci Think RL 2. Three-Stage training recipe:遵循了SFT→DPO→RLVR的三阶段训练,同时指出了三阶段训练性能要显著优于SFT→RLVR的两阶段方法 3. OLMoRL:基于GRPO构建的RL训练方法,在近期一些工作的基础上优化了GRPO,并且也不再局限于数学和代码领域使用。
4.1 Main Results for Olmo3 Think
4.1.1 Evaluation Details
构建了一套benchmark来评估OLMo3,具体的benchmark如下图。
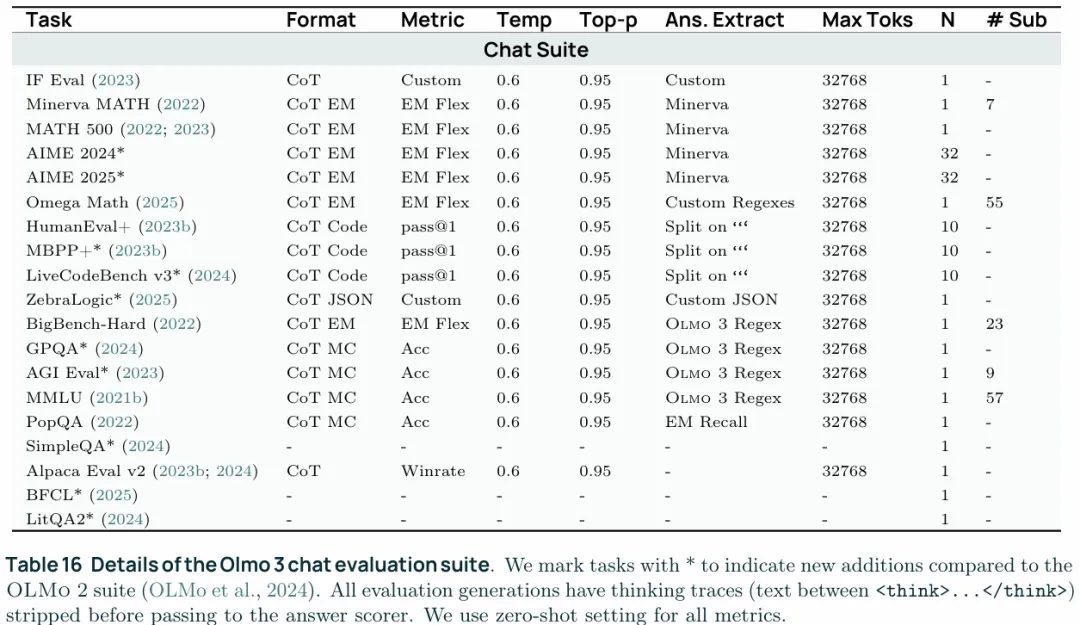
图中Format给出了输出的形式,CoT就是显式输出think trace,CoT EM(Exact Match)要求显式输出think trace但是最后要求给出精确的数学答案,CoT Code要求输出代码,CoT JSON要求输出JSON格式,CoT MC(multi choice)是要求给出多选。Metric是评价标准,EM Flex允许语义相同但字符不一致的情况,比如1/2和2/4,paa@1是生成中至少有一次通过,ACC就是准确率了,winrate指的是在偏好比较中生成的内容被更加偏好的概率。temp和Top-p是生成采样参数。Ans.Extract指定了生成内容的提取方式,要把答案提取出来,否则CoT会影响评估。Max Toks是最大输出长度。N是采样数,对于同一个问题采样几个答案。#Sub是该任务下的子任务的数量。
对推理模型进行评估消耗的算力很多,大概占到了算力预算的10%-20%,为了能更好的评估模型,去除额外的影响,OLMo3使用14个模型在每个benchmark上跑了3轮,统计了每种benchmark的方差,将这些benchmark分成了:
1. 高方差:GPQA: 1.4798, AlpacaEval 3: 1.2406, IFEval: 0.8835. 2. 稳定:ZebraLogic: 0.5638, Omega: 0.5579, AIME 24 (Avg@32): 0.5437, HumanEvalPlus: 0.4615, AgiEval: 0.4339, BigBenchHard: 0.3866. 3. 非常稳定:LiveCodeBench (Avg@10): 0.2852, MBPPPlus: 0.2749, MATH: 0.2522, MMLU: 0.2219, PopQA: 0.1554.
4.1.2 Main Results
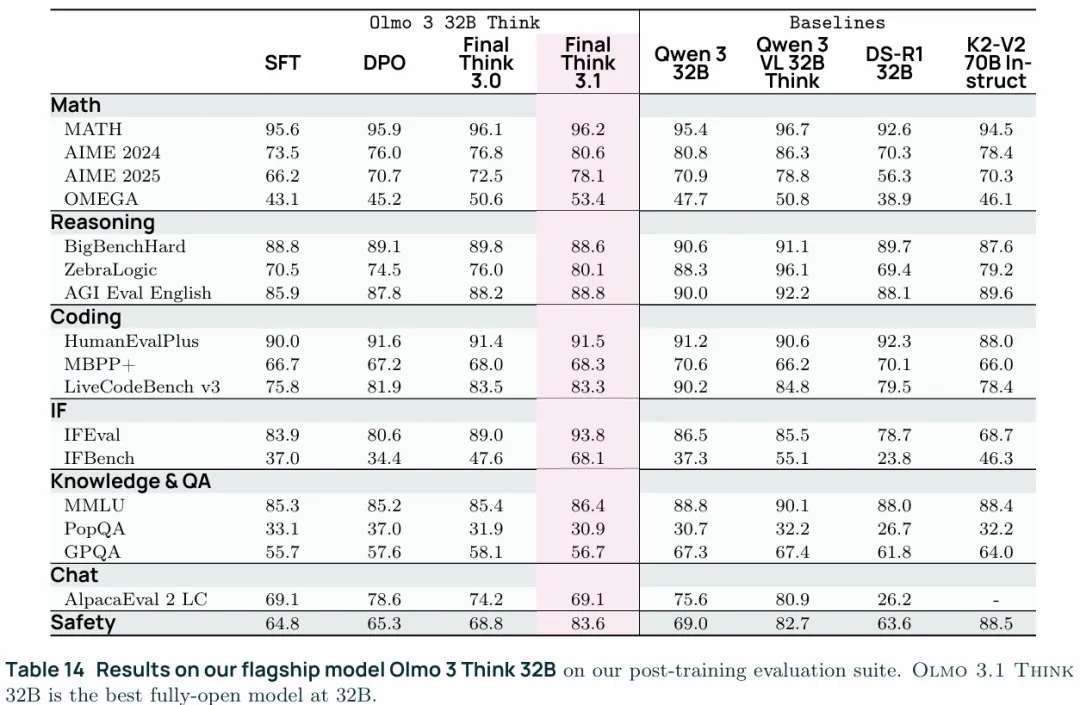
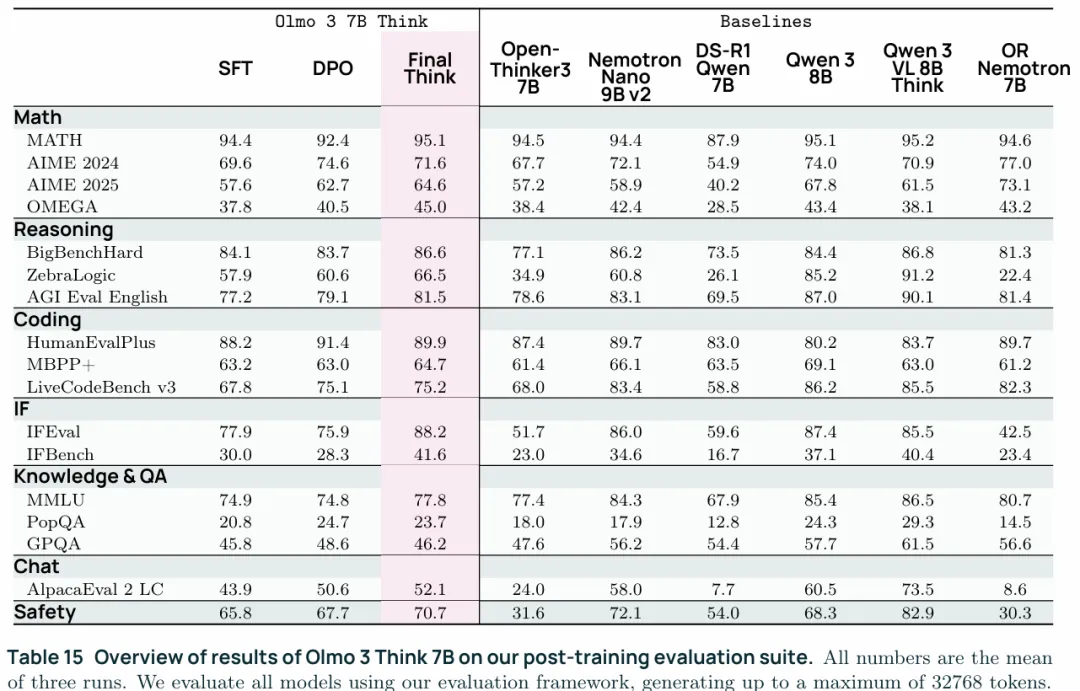
与其他主要模型的对比如下图,这里值得一提的就是Think3.1用的是OLMoRL,3.1与3的区别是,3是在开发的早期推出的版本,后续可能有配方的调整,比如数据混合比例等,3.1使用的是结项是的最佳配方。
4.2 Supervised Fine tuning with Dolci Think SFT
4.2.1 Dolci Think SFT: Data Curation
首先来看数据集构建,首先是收集了大量的prompts,在对这些prompts进行过滤和(再)生成,prompts的来源如下: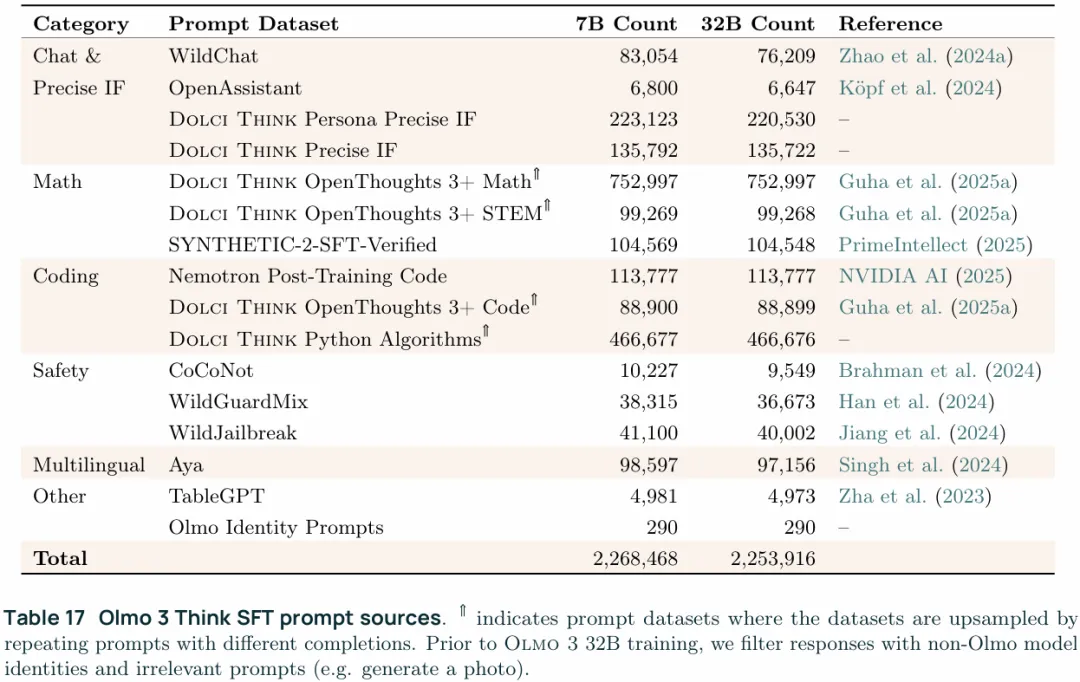
数据集的构建分为三个阶段:
Step1:sourcing prompts and generating reasoning traces:
1. Math:math的prompts来自OpenThoughts3和SYNTHETIC 2,这两个数据集都是不止有prompts,也包含了部分reasoning trace和答案,对于OpenThoughts3中reasoning trace完整的就直接三来用,对于不完整的就用QwQ-32B补全,OpenThoughts3中reasoning trace也是用这个模型生成的,如果补全后仍然不完整就弃之不用。对于SYNTHETIC-2则是将所有的验证集拿来用了。 2. Code:Dolci Think Python Algorithms的prompts来源是AceCoder、The Algorithms中的python子集、Llama Nemotron Post-training和OpenCodeReasoning,对于每个prompt都用QwQ-32B来生成16个response,随后使用GPT-4.1生成测试用例,也就是按prompt生成test input和期望的行为和结果,来验证生成的response是否正确,只保留验证通过的部分。OpenThoughts3中的code则是只保留16条response,更多的部分不再采用。 3. Chat & safety:chat部分的prompts来源有Tülu3中的Wildchat子集(也包括未被Tülu3使用的部分)、Tülu3中的OpenAssistant子集。safety部分使用的是Tülu 3的safety prompts。这些prompts统一喂给DeepSeek R1来生成reasoning trace。 4. Precise instruction following:精确指令遵循使用的是Tülu 3 mix,并且附加了可验证约束(verifiable constraints),这个可验证约束指的就是可被程序化验证的约束,比如格式约束(要求输出的是JSON/YAML/code block等)、结构约束(恰好3条、每条不超过20词、以特定前缀开头等)、语言 / 风格约束(只使用英语、只使用第一人称等)这一类的,可以被正则表达式、解析器等程序化验证的约束条件。此外还使用了Tülu 3中的Persona IF prompts,persona指的就是角色扮演,也就是经常用到的“假设你是一名医生/学者/教师”这一类的prompt,只不过persona使用的是Nemotron-Personas-USA中的persona 5. Science & other:science prompts来自OpenThoughts3 science子集。others来自Tülu 3中的TableGPT子集和Aya。OpenThoughts3中不完整的同样是经过了补全,其他数据集prompts是喂给DEEPSEEK R1生成的reasoning chain
Step2:filtering:
1. Heuristic filtering:这里过滤掉的主要有1.非商业使用的及许可证不明的,这里主要是因为non-commercial(NC)许可证可能会导致许可证污染使训练出的模型无法商业使用,使用数据训练大模型属于衍生使用(derivative use),对个人而言,在明确非商业、私下研究且不分发模型或其服务的前提下,使用 non-commercial 数据训练模型通常被视为许可允许范围内的低风险行为;但一旦涉及模型发布、公共服务或潜在商业用途,即使主体仍是个人,也可能构成对 non-commercial 许可的违反。2.reasoning chain不完整的3.领域错误的,比如验证指令遵循中的约束是否被遵循、代码运行是否正常4.提及其他模型开发者和截止日期的,这里把截止日期排除在外是防止模型受到日期约束,从而避免产生类似于超过某个日期后就认为自己不应该回答的情况。5.大量重复的6.包含了大量中文字符以及包含了Chinese political values的,排除中文字符主要是因为训练数据主要是英文,如果在reasoning chain中包含了大量中文字符可能会导致reasoningchain不稳定,如果要做多语言主流的做法是显式多语言post-training(explicit multilingual post-training)也就是为每种语言单独做后训练(语言隔离)再辅以受控制的语言混合。 2. Topic filtering:使用OpenAI query taxonomy将数据集按照话题分类,然后去除或将与模型无关的prompts下采样,比如请求图片生成的prompts就是去除,因为超出了模型能力、问候寒暄类的就是downsamplin,防止学到过多的无意义内容,造成token浪费。
Step3:data mixing:
这一阶段使用了类似于midtraining的方法,也就是分布式实验+中心化整合。具体来讲,OLMo3将100K的OpenThought 3数据作为baseline,然后去分布式实验其他类型的100K实验数据,发现其他类型的数据都能够带来benchmark的提升,所以在最终数据构建的时候这些数据每类都包含了一部分。
Step4:decontamination:
这一部分是去除掉与验证集重合的部分来防止数据污染,使用的是Tülu 3的流程和工具,具体来讲就是对训练样本生成8-grams,对评估样本生成8-grams,重合率大于50%就将训练样本移除防止污染,此外使用了额外的启发式:1.与任务无关的公共样本不做n-gram2.数学领域符号密集的 n-gram不去除
4.2.2 Training
SFT阶段的训练还是teacher forcing,OLMo2使用的是open-instruction,OLMo3用的是自己的OLMo-core,最终候选模型的确定是通过“vibe-test” questions,也就是评估使用的整体感觉来确定,最后是做了model souping,将最后确定的两个模型的权重做加权平均,加权平均有助于平滑模型行为,所以有助于提升vibe。
4.3 Preference Tuning with Delta Learning
通常偏好优化更多的被用于与人类偏好对齐,近期的一些工作比如QwQ就没有使用preference tuning(SmolLM3 例外),但是经过重新审视,preference tuning作为对比学习的一种能够提供单独使用SFT以外的能力收益,所以OLMo3依然使用了preference tuning,并构建了Dolci Think DPO这个数据集。此外OLMo3还报告了,如果继续使用从Qwen3 32B生成的thinging trace做SFT反而会伤害到OLMo3的能力,这恰恰说明了从模仿中带来的收益已经饱和,单独对高质量样本做SFT已经无法诱导出足够的学习信号,所以通过对比学习从正例和反例之间的delta中诱导出学习信号才能进一步提升能力。所以在构建样本时需要尽可能的降低反例的质量(从而最大化delta)。这里使用的是长度归一化的DPO:
圆括号中间的部分就是delta learning hypothesis中的delta,只要delta够大就会有学习信号,但是这也有一个基本的要求,就是模型具有足够的基本能力来区分正例和反例,从而在正例和反例的差异中习得什么是好什么是坏。因为DPO是基于teacher forcing的,也就是逐token计算交叉熵,这样的话就会有这样一个困境,即如果需要明确的学习信号就要加大正例和反例之间的差异,通常正例的输出会更长,会包含一些“step by step”等模板化的句式化身做题家,因为这些句式(包括无token-level对齐)会实实在在的影响交叉熵计算,且在高质量正例中共有,但是为了真正提升能力将正例和反例,去把格式、长度等统一,仅在关键的一到两处做区分,则会减小delta,进而减小梯度,使得学习信号太弱无法顺利学习。这也关系到之后的一个阶段RLVR,或者说另一个更开放的问题,即下一步学习信号应从何而来的问题,就不展开了。
4.3.1 Dolci Think-DPO: Preference Data Creation
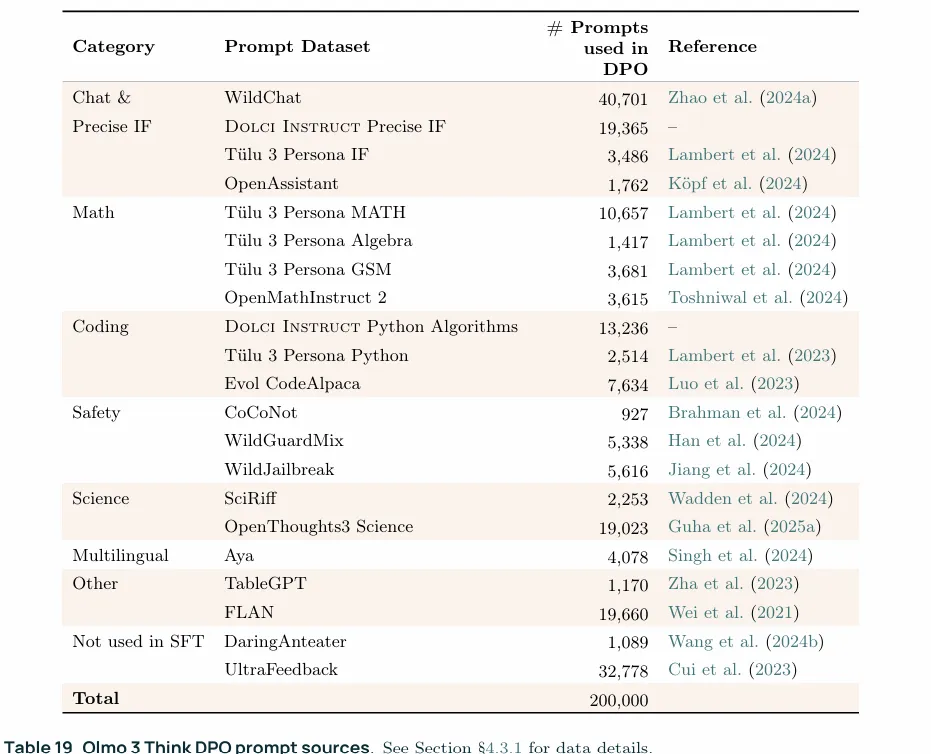
与SFT数据的构建类似,首先是收集prompts,来源如上图,然后合成“chosen”和“rejected”两种类型的相应,以此构成delta信号,按照delta-learningheuristic的方法,对于每个prompt,“chosen”是由一个强力模型生成的(Qwen3 32B Think),而“reject”是由一个全面弱化的模型生成的(Qwen3 0.6B think)生成的。具体步骤为:
1. Step1:sourcing prompts andc ontrastive completions:prompts的来源是Dolci Instruct SFT,此外还添加了Daring Anteater以及OLMo 2 7B preference dataset中的UltraFeedback子集 2. Step2:filtering:对于chosen的响应,应用SFT阶段的topic filter和heuristic model-identity filtering,这里的model-identity filtering应该指的是会暴露模型身份的内容,像是"作为一个语言模型..."或是“我无法处理这个请求”,因为上面提到了wildchat涉及到图片生成类内容,这一阶段过过滤掉chosen的高质量回复以形成没有这一类请求更好的delta信号,另一方面可能也涉及保持SFT阶段风格延续的考量。rejected则不处理作为反例。 3. Step3:mixing:因为在推理模型上做实验相比于在非推理模型更高,所以在数据混合实验沿用了非推理模型的情况,细节留在第五章。这里使用了Olmo 3 Instruct实验中表现最好的三个prompts分布,然后使用Qwen生成chosen和rejected,数据混合是通过经验确定的。
4.3.2 Training
这个阶段只训练一个epoch,扫描learning rate和dataset size,dataset size也是一个重要的超参数,early stop对于偏好微调的性能影响很大。除了在测试套件上进行测试,还进行了vibe-test
4.4 Reinforcement Learning with OlmoRL: The Cherry on Top
这一部分包括了100K的Dolci-Think-RL数据集,包含了数学、代码、指令遵循、对话等内容。此外还有OLMoRL算法细节和infrastructure。
4.4.1 OlmoRL Algorithmic Details
OLMoRL是在GRPO的基础上构建的,具体来说吸纳了DAPO、Dr GRPO、以及其他的一些改进。核心依然是RLVR的核心,也就是给定一个prompt通过一个验证器(verifier)来验证生成的响应(response)是否接近prompt的ground truth。在GRPO基础上的改进具体有:
1. Zero gradient signal filtering:类似DAPO的方法,对生成的response进行过滤,也就是当GRPO对于一个prompt生成K个response时,如果这一组生成的response都具有相同的reward,那么就把这组response丢弃不用。 2. Active sampling:在zero gradient filtering的基础上进行动态采样,也是从DAPO上继承和改进的,当丢弃掉某些group时再采样对应数量的group,保证batchsize一致,详见4.4.3 3. Token-level loss:因为GRPO是以trace为单位计算log prob的这样就会导致生成更长回答的求出来的log prob更大使得模型在生成时盲目追求长生成,所以需要按token level来进行归一化 4. No KL loss:按照目前主流方法移除了KL约束项,这使得策略能够更自由的更新,并且也没有导致过拟合和训练过程的不稳定 5. Clip higher: 截断的上界会比截断的下界更大从而允许更加宽松的更新 6. Truncated importance sampling:实际的采样策略是依托vLLM,是加载到vLLM实现极致加速推理的,因为vLLM极致的工程实现(fused kernel、fp16/bf16 rounding),可能会导致与之间的gap,这就需要进行修正。 7. No standard deviation normalization:在计算优势的时候不使用标准差归一化优势,防止标准差对reward进行压缩或放大,比如reward都很小/大,且标准差很小(说明生成的response都差不多),此时实际上就不应该有明确的学习信号,但是除以小标准差反而会放大学习信号,类似的情况在高标准差的情况也存在,反而导致好的回答和坏的回答之间的差异变小,从而造成学习信号异常。
最终的学习目标如下:
这一部分用于Truncated importance sampling,实际就是与之间的比值,和是截断超参数,,这里的优势是不计算方差的:
这里的另外一个重要部分就是验证器的构成Verifiers:
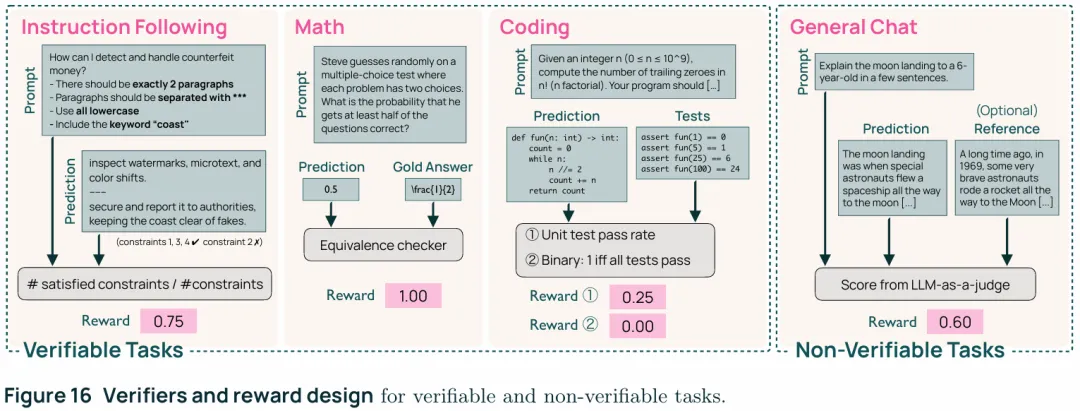
1. Math:使用SymPy转化答案,以使其与标准答案进行比较 2. code:基于测试用例的验证器,也就是生成一组测试用例,有两种使用方式一是按照测试用例的通过率进行奖励,比如四个测试用例中通过了1个那奖励就是0.25;另一种是测试用例全部通过才给予奖励否则就是0. 3. Instruction-following:prompt带可验证约束条件,当所有的约束条件都满足时奖励为1,否则为0 4. Chat—reference:当回答具有明确答案的问题时,将回答和答案喂给一个大模型来给出一个0到1的分数 5. Chat—open-ended:没有明确答案的时候,将回答喂给一个大模型来给出一个0到1的分数
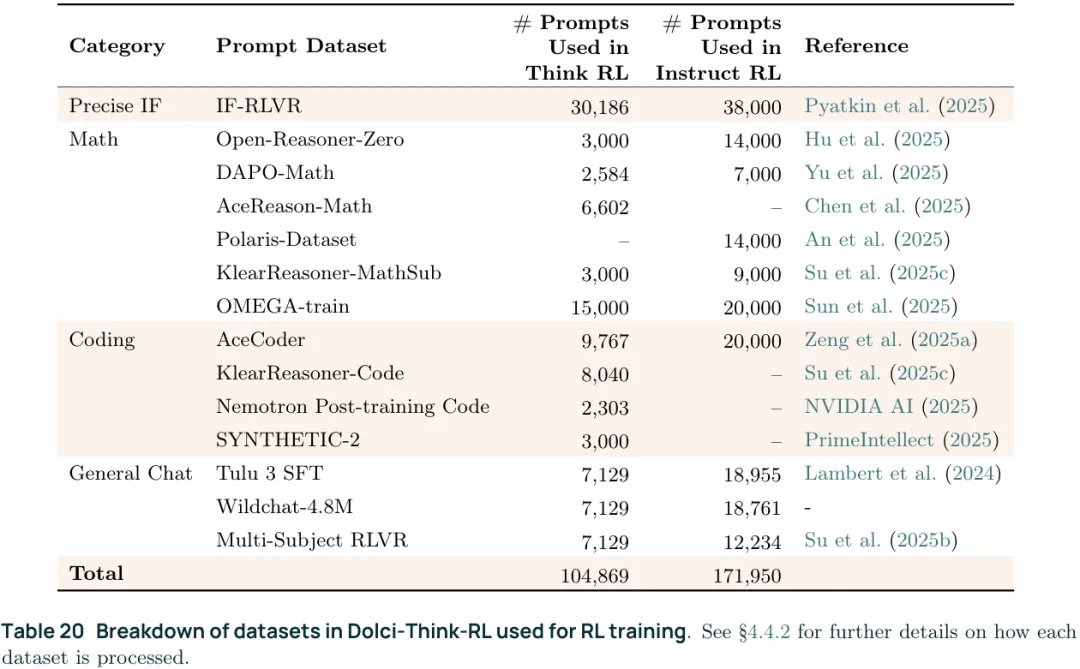
4.4.2 Dolci-Think-RL:Curatinga State-of-the-art RLVR Dataset
数据集构建上,构建了一个100K的包含了数学、代码、指令遵循和常规聊天四个领域,每个样本都需要能够验证正确性或是给出质量评价,详见上面的verifiers。数据集中的内容在许可和来源上都十分小心。
Step1:sourcing prompts:
1. Math:包括Open-Reasoner-Zero、DAPO-Math、AceReason-Math、DeepScaler、KlearReasoner-MathSub、OMEGA,领域覆盖代数、组合学、数论、集合。 2. Coding:包括AceCoder、Klear-Reasoner Code、Nemotron Post-training Code、SYNTHETIC-2 code、Open-Code Reasoner,其中Klear-Reasoner和SYNTHETIC-2包含可以使用的test case,其他prompts(problem)需要的test case需要合成,合成过程包括三步1) problem rewriting, (2) solution generation,(3) test case generation。拿到test case后,用test case执行对应的solution,只保留超过80%测试用例通过的solution和测试正确的test case。落地上可能是nsjail/firejail这一类的sandbox,也可能是一个专门的judge server,具体没写。 3. Instruction-following:prompts来自IF-RLVR,并最多包含5条约束,约束是从IFEval和IFBench-Train中采样的 4. General chat:prompts来自(a) Tülu 3 SFT(b) 新版本的 WildChat-4.8M,这个数据集中包含了用户与chatbot之间的多轮对话(c) the Multi-subject RLVR dataset (Su et al., 2025b),这个数据集是人类专家编写的用于验证的数据集,同时包含了问题和答案。WildChat中只采样英语且不需要推理的样本。Tülu 3中的样本是用GPT4.1重写了prompts,并且使用了SFT阶段的设置,从数据集中自带的response中提取了参考答案。对于上面提到的三个prompts来源,对于每个选用的prompts使用经OpenThoughts 2微调的Qwen 2.5 7B来生成8个response,然后计算这8个response与reference answer之间的F1 score(精确率和召回率的调和平均,,),过滤掉平均F1小于0.1(response和answer几乎无重合,可能是noisy sample)和大于0.8(问题太简单,7B模型也能随便答对)的样本。另一个是WildChat中包含了相当数量的角色扮演内容(比如“如果你是哈利波特/夏洛克福尔摩斯”),如果某个角色在其中涉及到的次数太多,则至多保留十条,进行角色去重。在最后还进行了人工数据过滤以移除代码和数学类的prompt
Step 2: offline difficulty filtering:如step1中的,首先是从训练的起点对每条prompt采样8个response,然后移除那些对模型来说过于简单的prompts,也就是通过率65%以上的部分,这个过程的temperature和top-p都设成1,与训练阶段的采样超参数保持一致。随后7B 的OLMo3是offline filtering,也就是训练开始前就做了这个筛选,而OLMo3 32B版本则是active sampling,在训练过程中,32B 会不断从候选 prompt 池中尝试采样;对每个 prompt 生成 K 个 rollouts 并计算 GRPO 组内 advantage,只有当该组 reward 不完全相同、能产生非零 GRPO 组梯度时,该 prompt 才会被“接受”,用于填充 RL training batch。因为做offline filtering很费算力,所以使用7B版本过滤的数据作为采样的起点,在训练过程中使用active sampling填满RL training batch。
Step3:data mixing:这里的data mixing因为直接跑RL实验很费算力,所以做了一个三阶段的pipeline,①从一个SFT的训练中间检查点出发,在特定的数据集上训练500-1000个RL step来观察性能的变化趋势②当算法发生调整的时候,首先在进行数学领域进行训练,数学域是一个对算法变化最敏感、反馈最快、噪声最小的 probe domain③周期性的在全部领域的data mix上进行训练,检查这个配比在全任务上会不会崩、会不会被某一域拖垮、会不会产生明显负迁移来确保data mixing的稳定性。在为最终训练做准备时选取了最有希望的数据集,并且仔细地调整了高质量数据的比例,同时保证不同领域的数据大致相当,数学和指令遵循类的数据要略多一点(在①中表现较好)。此外在OMEGA数据集的部分子任务上做了下采样,从7B模型的过滤中发现这部分任务太难了。通过这个pipeline构建了7B OLMo3的数据集,并且该数据集也是32B OLMo3的训练起点。7B 模型最初的训练使用的是旧版 RL 基础设施(Infrastructure),尚未引入 pipelineRL 与 truncated importance sampling,因此完整训练耗时约 15 天;随后作者在保持相同训练设置的前提下,使用新版基础设施复现了该训练,仅用约 6 天即达到了相近性能。
4.4.3 OlmoRL Infrastructure in Open Instruct
LLM的RL阶段中,一个关键点在于inference过程的管理,也就是RL 中的rollout,对于OLMo3推理模型来讲最大输出长度为32K,平均输出长度也达到了10K,推理过程占了算力的大头,32B的OLMo3使用8张H100来训练,却使用了20张H100来推理,等待推理结果的时间占了总训练时间的75%,从GPU利用率的角度看,推理消耗大概是训练消耗的5倍。对于7B模型而言,这个比例更夸张,使用了7张H100做推理,2张H100做训练,从GPU利用率的角度看,推理消耗大概是训练消耗的14倍,所以这个阶段的工程实现与SFT阶段不同,不追求细颗粒的分片以最大化吞吐量。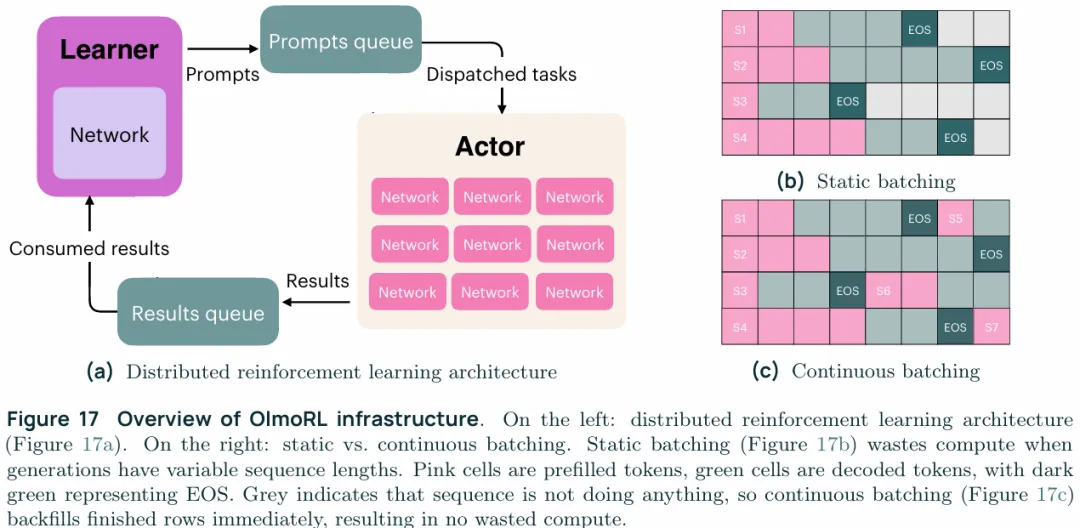
Fully asynchronous training:如上图,使用的是一个全异步的训练方式,他这里的参考文献指向的是ICLR 2025《ASYNCHRONOUS RLHF: FASTER AND MORE EFFICIENT OFF-POLICY RL FOR LANGUAGE MODELS》,包含了一个中心化的learner负责从result队列中提取数据更新权重,并从 RL 数据池里取 prompts放到队列里,而分布式的actor则是维持了一个pool,这个pool中有若干actor,每个actor都运行一个vLLM实例只负责从prompt队列里加载prompt做自回归生成/推理并做验证,中心化的learner定义的将参数推送/拉取给actor,actor拿到参数后就加载,actor每完成一次推理就会马上读取prompt队列里的下一条数据继续生成。不做同步式架构的原因在于,不同actor的推理长度可能不同,有的可能几秒就出结果,有的可能要几分钟,采用全同步就不得不全都空转等待生成序列最长的那个结果。这一阶段的组织应该是Ray+DeepSpeed+vLLM的工程实现。
Continuous batching:实际上就是actor每完成一次推理就会马上读取prompt队列里的下一条数据继续生成。
Active sampling:既然是全异步的,那么该架构下就允许从actor处持续的拉取梯度非0的结果直到满足一个batch的需求。DAPO是一次性生成所需数量三倍的prompts以满足batch需求,但是这就存在浪费,但是在全异步情况下就可以逐条拉取符合要求的结果直到满足batch需求。
Inflight updates:在LLM的RL阶段,一个常见的目标是最小化actor policy和learned policy之间的差距,这一点的根源来自于PPO/GRPO的near on-policy,通常的做法是同步方式,也就是actor等待最慢的actor执行完以后,卸载掉KV cache,然后统一更新参数,这就导致了GPU效率的的浪费。同样的依赖于全异步的架构,actor可以在一次生成结束后再更新自己的权重,这就保证了thread-safe,而不必暂停生成或是卸载KV cache,因为每次生成的KV cache都是参数一致的。
Better threading and engineering:实际上这一小节全部的变化都来自于全异步的框架,这个框架将actor之间解耦,允许他们独立的运行。此外还围绕GPU利用率做了许多工程上的工作,比如直接使用continuous batching一开始效果是不如static batching的,但是添加预取(prefetch)并将预处理(cpu取出prompt,可能包含反序列化,随后是分词,构建输入结构)后的prompt塞进队列后才看到了吞吐量上的的提升。
4.5 Key Findings
1. DPO yields gains where SFT on the same data cannot:这个就是上面分析的,单纯的SFT已经无法产生足够的学习信号,但是通过DPO构造delta信号就可以 2. DPO and SFT both benefit from RL, but DPO remains a better starting point:在SFT阶段后直接进行RLVR的效果不如SFT之后做了DPO再进行RLVR的效果好,主要体现在像AlpacaEval这一类RLVR阶段不会明确强化的指标上,SFT之后直接做RLVR会导致这个指标的下降,即便是RLVR明确强化的指标,比如Omega和AIME2025,做完DPO再RLVR效果也要更好一点。按我的理解,进入RL阶段前模型的基础能力是越强越好的,因为DPO实际上也是teacher forcing的,但RLVR阶段就是真正意义上具有探索阶段的RL了。 3. Rewards steadily increase across all domains during RL:经过RL训练各项指标都会稳定增长,生成长度首先缩短然后逐步增长,这可能与在SFT和DPO阶段习惯于生成长序列有关 4. Mixing RL data from varied domains can prevent over-optimization:在单一领域数据集上训练会导致过拟合,例如在IFEval only的数据集上训练会导致AlpacaEval的指标对应下降,呈现出明显的trade off,但是使用混合数据就不会产生这种情况 5. Mixing data yields lower train reward, but not lower down stream performance:尽管使用混合数据集进行训练时,reward model给出的reward会比单一领域数据训练得到的reward低,但是在指标评估时却没有观察到这种性能下降的情况。这说明了混合数据有助于防止过拟合以及reward-hacking ,这有助于下游任务性能的提升。 6. Continuous batching and inflight updates are crucial to training speed:分布式框架下的Continuous batching和inflight updates能够在一半的节点上实现两倍的训练加速。 7. OlmoRL shows significant improvement in precise instruction following:RL在精确指令遵循上也有显著的提升。
5. Olmo3 Instruct
OLMo3 instruct是一个快速响应模型,不同于Think 版本的inference-time scaling,Instruct主打非推理、日常使用,所以在DPO阶段使用了多轮对话数据并且提升了对响应准确度的要求
5.1 Main Results for Olmo3 Instruct
具体的指标我就不贴了,OLMo3 Instruct在许多指标上超过了Qwen3
5.2 Supervised Fine tuning with Dolci Instruct SFT
在OLMo 2 Instruct的基础上构建了Dolci Instruct SFT,大幅改进了通用对话、推理和函数调用能力。
5.2.1 Function-calling Training Data
这里收集数据的目的是给模型提供一个基本的function calling能力,并且让模型接触到实际操作真实环境(比如,MCP,Model Context Protocol),并以此解决问题的trajectories,为此收集了两类使用LLM合成的数据:
Trajectories with real interactions:这一类数据的轨迹中展示了智能体使用MCP来回答问题,所有的轨迹都包含了一个用户操作以及多个agent与环境的交互,主要关注以下两个领域:
1. Science QA dataset:这个数据集的构建是通过GPT-4.1-mini和AI2自家的ASTA Scientific Corpus(ASC) MCP server,问题的答案需要从学术内容的细节中获得,主要包括:1)基于论文内容的问题,主要关注摘要和全文2)基于引文图谱(citation-graph based)的问题,涉及作者、会议、引用等元数据。 2. Web search QA dataset:是基于DR Tulu修改的,分为多个阶段:首先是从开源benchmark,HotpotQA、TaskCraft、WebWalkerQA中采样问题(queries)此外还包括SearchArena和OpenScholar公开的真实的用户prompt。随后讲这些queries会通过GPT-5过滤,仅保留需要检索的,且具有长格式、可验证回答的queries。之后这些queries通过配备了SerperAPI(google search API)的GPT-5来生成trajectories。
Trajectories with simulated interactions:尽管能从真实环境的反馈中获得trajectories非常nice,但问题是难以大规模的获取这一类的数据。为了填补这个空缺,OLMo3通过LLM模拟环境来实现合成trajectories,构成了数据集SimFC。首先从现存的API数据集xLAM、ToolACE,以及公开的MCP servers中等获得API和工具的信息、签名、出/入参说明和格式等信息,为LLM合成轨迹提供模板,然后喂给大模型来获得完整的轨迹,来模拟用户的问题、环境的响应以及chatbot的回复。通过仔细构建prompt就可以实现多轮次、多步调用以及因参数错误等拒绝响应的情况。不得不说这确实是一个获取trajectories的好办法,从下图也可以看出来,真实的trajectories反而不包括multi-turn也就是用户多次交互的情况。
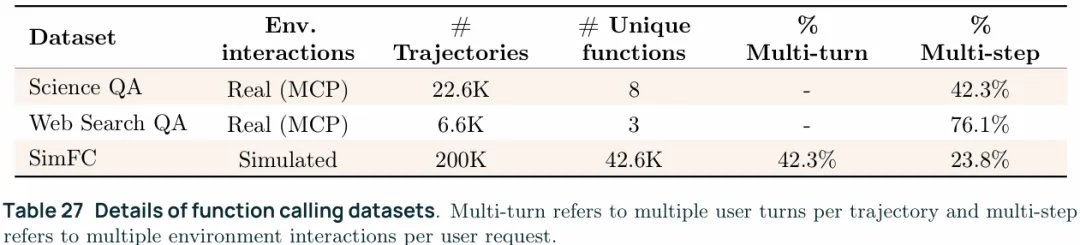
Balancing function diversity with interaction complexity:从上图可以看出,真实的和合成的数据有明显的不同,SimFC显然有更多种类的数据,数据量也更大,但是其multi-turn数据相比于multi-step要更简单。multi-step trajectories也对应于更复杂的任务,此外真实的交互尽管数据规模更小,但也主要对应复杂的multi-step trajectories。
Unified data format:对全部的的tool-use data按照OpenAPI的格式统一了工具定义和用python风格code block统一了工具调用的格式,而这对稳定的且高质量训练十分重要。这里的tool specifications是被写到system prompt中的,而tool call则是使用XML tag标记,tool call的结果被写到environment这个角色中。OLMo3 instruct相比于Olmo3 Think在vocabulary中多了关于tool use的tag,使用这些tag要比直接将,, , 作为文本直接encoding要好。
Evaluating function calling:区分intrinsic function calling和extrinsic task completion评估模型的function calling能力。intrinsic function calling使用的benchmark是Berkeley Function Calling Leaderboard (BFCLv3),目的是匹配模型输出的function call与标准答案。task completion accuracy使用的是MCP+Asta Scientific Corpus (ASC) tool/Serper API,为了对使用工具的效果进行评估,使用的是LitQA2中的75个问题,这些问题中的论文同样可以在ASC中索引到,此外为了评估模型使用搜索和浏览工具的能力使用了SimpleQA的一个子集。在对extrinsic task completion进行评估的时候,使用OpenAI’s Agent SDK作为中间的胶水层,模型向其提供function calling而OpenAI’s Agent SDK则解析模型提供的内容并向外调用MCP server。
5.2.2 Curating Dolci Instruct SFT
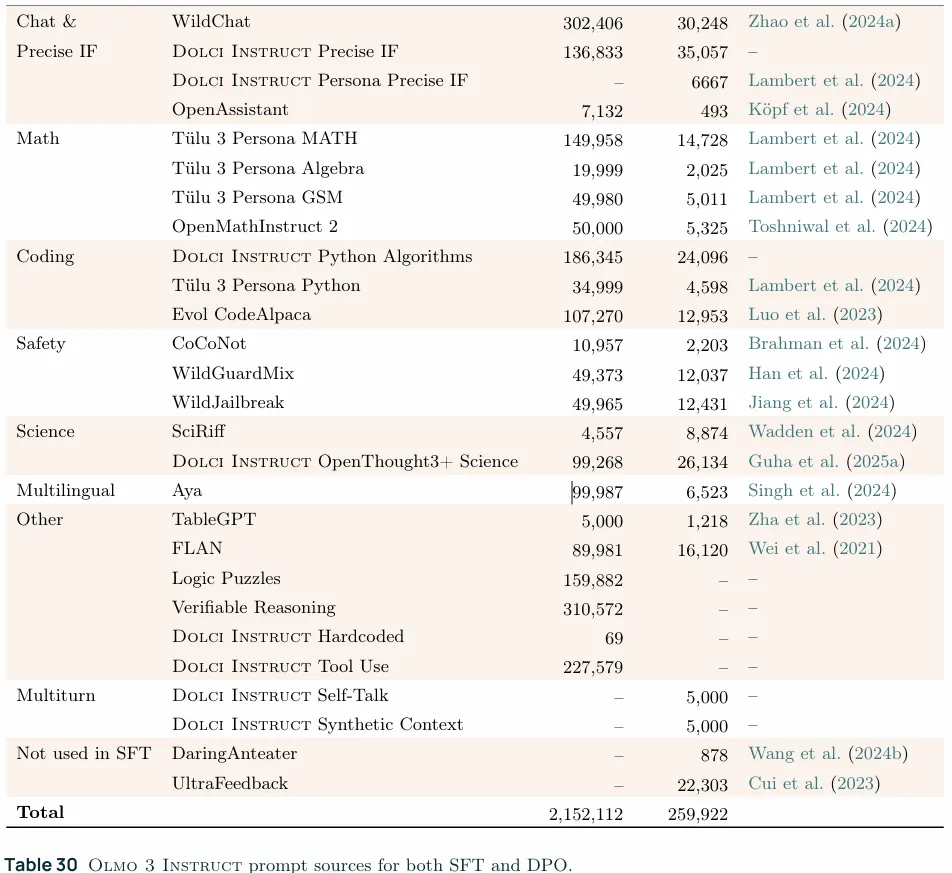
1. Step 1. Sourcing Prompts and Completions:prompt的来源包括上面5.2.1提到的function calling datasets(上表中的Dolci Instruct Tool Use)、4.2.1中提到的指令遵循和科学类prompts、以及从WildChat中采样的更多的聊天类prompts。如果原本就包含reasoning traces则将其去掉(比如4.2.1中提到的OpenThoughts3 science subset)。此外需要注意的是,上表中的Dolci Instruct Tool Use只在SFT阶段使用了,而没有在DPO阶段使用,应该是tool use的delta信号不好构建吧。 2. Step2:Filtering & Mixing:使用了4.2.1节中描述的过滤和data mixing策略,数据混合的起点(basic mix)是从OLMo 2 SFT的一个经升级后的100K中间版本开始的。 3. 训练的起点是Olmo3 Think SFT之后。
5.3 Preference Tuning with Dolci Instruct DPO
5.3.1 Preference Signals
Delta-learning heuristic pairs:这里的delta pair构建类似于Dolci Think DPO,使用一个能力强的模型生成正例(Qwen3 32B生成chosen response)然后再通过一个能力弱的模型生成反例(Qwen3 0.6B生成reject response),生成时关掉深度思考。
Delta-aware GPT-judged pairs:在Delta-learning heuristic pairs中reject response直接由弱模型生成就好了,这里又通过GPT-4.1选择reject response中最差的一个,以此最大化delta信号。这里的经验是OLMo2在使用UltraFeedback pipeline的时候有两个问题,就是在构造generator model的时候generator性能都太强,使得无法 产生足够的delta信号,在OLMo3这里一是使用足够弱的模型(0.6B),另一个就是生成一组reject response,然后让GPT4.1来选最差的。
Multi-turn preferences:为了让模型更好的实现多轮对话,进一步地从Tülu3-DPO这个数据集出发合成了多轮对话数据,生成的多轮对话数据只在最后一轮对话有区别,从而避免难以进行质量划分,这里的delta信号构建还是挺粗糙的,因为质量区别只显著存在于最后一轮对话,也有可能是为了避免多轮对话中credit assignment问题。生成方式有两种:1)self-talk,从一个prompt出发,让模型自己生成后续的用户追问,然后再自己解答。2)synthetic context,也就是从一个prompt出发生成一系列相关但是独立的问题,把一个prompt拆成多轮对话的形式,比如"A和B的区别是什么"就可以拆成“什么是A”“A是XXX”“什么是B”“B是XXXX”B与A有什么区别”“A和B之间的区别是XXXX”。
Controlling length bias:通常偏好数据存在length bias,即偏好更长的回复,不止是能力更强的模型会生成更长的回复,包括LLM judge也更偏爱长回复,尽管更长的回复有助于推理,但是也会习得length bias,所以在实际训练时对数据进行了过滤,从而将chosen和reject的样本之间的token数量差距控制在100以内。
5.3.2 Prompt Mixing
DPO的prompt pool是基于SFT阶段构建的,额外多了DaringAnteater和UltraFeedback的一部分,此外因为DPO阶段的性能表现不会随数据量的增加而一直增长下去,所以将数据集总大小作为一个超参数,数据集内的各部分的比例也有数量上限。为了确定这个比例,首先是从所有的prompt来源中进行近似平均采样,采集了100K作为baseline,然后按来源做消融实验从而确定domain的影响。此外还通过50Kdomain + 50K baseline的实验来更好的理解对某一domain进行上采样的影响。但是很多时候改变prompt来源比例并不能反映出对应的影响,例如对code类prompt进行上采样反而会降低code benchmark。所以在确定最终的比例时实际是通过专家来确定9个候选比例,然后再将这9个比例与baseline进行对比,从而确定下来的经验比例。这里做的实验和分析相比Think版本更多,可能是先开发了Think版本,然后再instruct这里迭代出了更好的data mixing方法。
5.3.3 Training
实验设置于Think版本一致,学习率和datasize作为超参数一点点试过去,此外上面提到的长度筛选也做了实验,来控制不同的长度差距。最终checkpoint的确定是从不同长度约束的检查点开始,通过vibe test以及performance-vs-length分析做出的。
5.4 Reinforcement Learning with Dolci Instruct-RL
调整了Dolci Think RL的prompt pool,1.减少了有难度的数学和code domain。2.不再使用offline difficulty filtering,因为Instruct更通用,所以没必要过滤掉太简单的样本。
5.4.1 Training
整体与Think版本类似,使用OLMORL训练,7B版本的生成长度最大为8K tokens,32B版本是16K。因为Olmo 3 Instruct要避免生成过长的输出,并且保持整体的可使用性,所以训练的起点有两个,一个是整体表现最好的、另一个是尽管指标略低,但是使用起来体感最好的,也就是vibe test最佳的。训练结果的最终确认是通过平均表现、生成长度以及vibe test确定的,具体的,先给训练完的checkpoint通过平均得分进行排序,如果有checkpoint得分相同则优先考虑test-time scale更少的,随后通过vibe test来测试。
5.5 Key Findings
Starting from the Olmo3 Think SFT is helpful:从Olmo3 Think SFT开始比直接做instruct SFT有三个点的平均提升,并且从Olmo3 Think SFT开始也不会明显的影响生成长度,或者说不会生成冗长的think trace。
High contrast in preference pairs drives DPO improvements:保持chosen和rejected的高对比度是有必要的。
Combining different preference signals improves over all performance:这点已经在上面说过了,通过GPT选择来最大化delta信号。
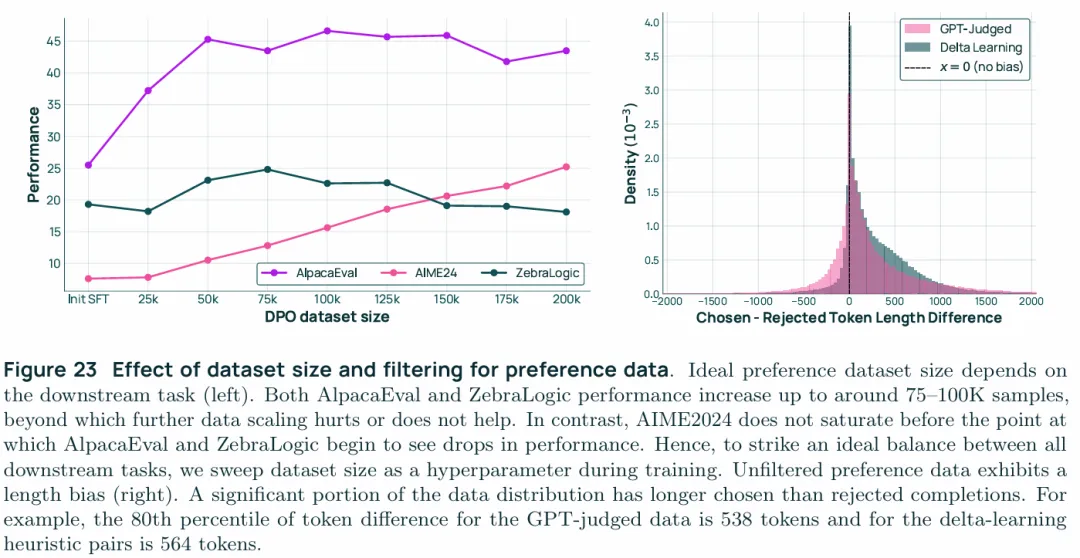
The ideal amount of preference data depends on the downstream task:DPO阶段训练的最优数据量对不同的下游任务是不同的,如上图AlpacaEval这种泛对话类的最优点比较早75-100K,ZebraLogic也大致在这个区间,但是AIME 2024这一类的hard reasoning却始终没有饱和迹象,这也体现了不同下游任务对过拟合的敏感程度,这同样说明了这一阶段early stopping的重要性,如果想要一个某方面特化的模型也需要考虑下游任务需要来确定data size这一参数。
Concise, usable model out puts from preference tuning can boost RL performance:在DPO阶段使用length filter能有效减小在生成长度上的偏好,从而增强模型的整体易用性,尽管生成长度被控制会导致某些benchmark上的指标不太好,比如数学类的AIME和MATH。但是除了易用性以外,经过长度控制的模型在RLVR阶段的表现也更好,这可能来源于固定上下文窗口的情况下,短上下文模型可能“每token更聪明”,从而在优化期间把有限的预算用得更高效,所以,尽管一开始的目的是在易用性和性能上做取舍,但是最终在这两方面都得到了提升。此外,从经过上下文控制的DPO checkpoint开始进行RLVR训练起来也更稳定。
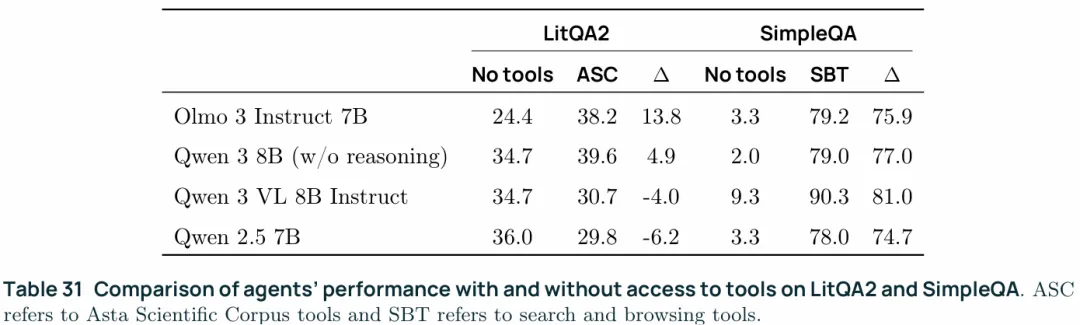
Need for tools:上表给出了tool use所能带来的增益,所有模型在被赋予搜索工具后SimpleQA的性能都有了大幅提升,但是在LitQA2上,Qwen仍更多的依赖基础知识而不是尝试去检索,这可能与训练方式有关,毕竟OLMo3被明确的训练使用ASC。
6. Olmo3 RL-Zero
开源了直接从OLMo3 base出发,直接进行RLVR训练的一切,包括Dolci RL-Zero数据集、基于OLMo3的整套RL方案以及OlmoRL代码库,此外Dolci RL-Zero是经过decontaminate的,这使得社区能够得到无数据泄露影像的的结论。
6.1 Reinforcement Learning From Base with Dolci RL-Zero
Data:数学方面,大幅过滤了DAPO Math、Klear-Reasoner Math、Open-Reasoner-Zero、Omega,DAPO math经过去重,并去掉了非英文的样本,对于Klear-Reasoner, Orz, 和Omega这一类的更大规模的数据集,则是通过语义将问题进行聚类,每一类中都选取一个有代表性的问题,这个过程也同样包含了DAPO Math。随后对数据集进行了decontaminate,确保没有预训练阶段的数据泄露或者评估数据的泄露,此外还进行了offline filtering,如果OLMo3 base对一个问题采样8次都通过就将这个问题排除掉。最终得到了13.3K的数学类prompts,code、指令尊姓、常规对话类是从Dolci Think RL下采样得到的。

Prompt and eval template:因为RL-zero是从OLMo3 base直接训练的,所以使用如上图的simple template效果要更好,因为在pre-training或者说mid-training之后直接做RLVR,有些模板中的复杂符号比如模型并没有见过,所以更容易被当做噪声。但是如果是经过了SFT、DPO,模型已经大量见过这一类模板了,内马尔这一类的模板就可以更加稳定的作为推理模式的触发信号。为了与RL-zero匹配,评估数据也要做对应的清洗,去掉这类模板。
RL algorithm:整体遵循了4.4.1中的方法,除了(i)训练时输出长度最大为16K(OLMo3 Think在训练时就支持32K长度输出)(ii)评估模型时的最大输出长度为32K,并且temp设为1来测试pass@k。在训练阶段缩短长度可能是因为RL-zero的原因,为了能更好的做credit assignment。
6.2 Key Findings
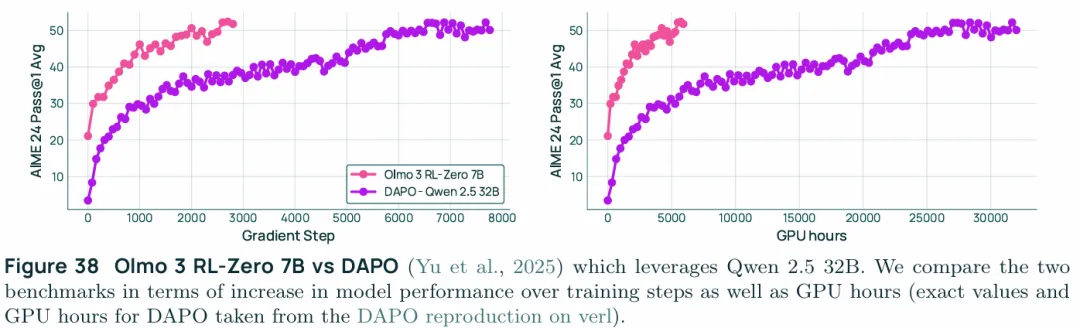
Olmo 3 RL-Zero can strongly improve on reasoning:这段主要表述RLVR可以稳定提升各类性能,这里值得一提的是OLMo3 的7B RL-Zero模型超过了DAPO在QWen32B模型上的表现。
Olmo3 RL-Zero mix can benchmark challenges in multi-objective RL:以往的研究大多基于RLHF或是单一domain的RLVR,而OLMo3 RL-Zero构成了一个包含数学、代码、指令遵循和常规对话的多目标的研究基准,此外这种多目标的优化相比于单一目标优化性能上依然有所欠缺。
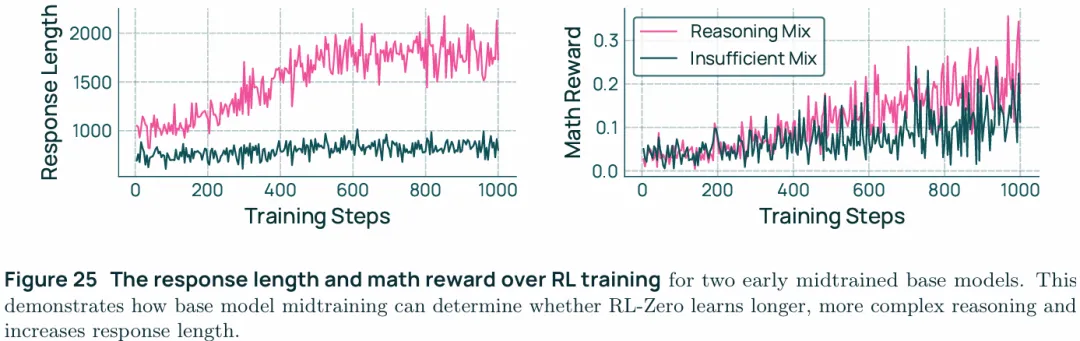
Olmo3 RL-Zero can benchmark reasoning data mixes in midtraining:RL-Zero允许单独研究mid training阶段对下游任务的影响。如上图,midtraining阶段添加了reasoning数据后能够改善RLVR阶段的学习情况,midtraining阶段如果不混入reasoning数据则会导致模型无法掌握backtracking,answerverification,等技能。
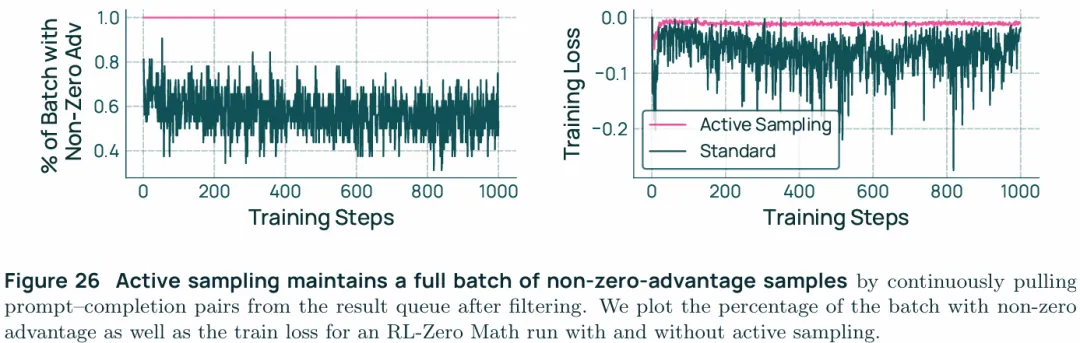
Active sampling stabilizes training:Olmo 3 RL-Zero提供了对RL 算法与基础设施进行实验的基础,比如active sampling的评估,也就是过滤GRPO中0梯度组的方法如上图,上图左展示了非0梯度group的占比,而上图右展示了对应的影响。
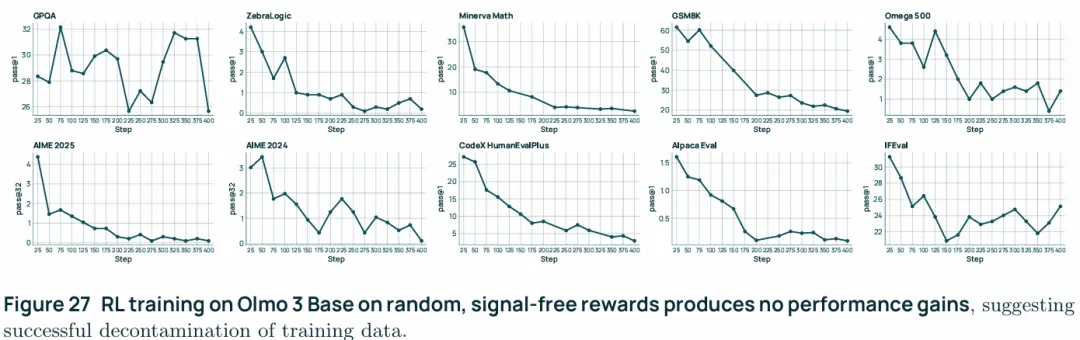
Eval decontamination is verified via spurious rewards:近期的一些工作揭示了用与模型效用无关的“虚假奖励”训练也能带来显著提升,这暗示任务可能被污染,也就是模型在预训练或中期训练阶段已见过评测数据。虚假奖励可把记住的答案引导出来,从而与真正的推理能力学习相混淆。为了验证OLMo3 RL-Zero的纯净性,做了一组随机分配奖励的实验,具体做法是在 Dolci RL-Zero 上训练,但给模型提供与答案无关的
0/1奖励,如果被污染,那么虚假奖励也能提升性能。结果如上图,使用随机奖励进行训练并未在任何基准评测上带来性能提升,成绩要么在随机波动中保持持平,要么出现下降,这说明模型在随机奖励下,只是在拟合一些和任务本身无关的随机相关性,而不是学到了任何有意义的任务结构或推理能力。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 【社团风采】当“我的世界”遇上编程 ——我的世界编程社团学期精彩回顾
- 衡水最新乡级行政区划代码公布!
- 优雅代码的32条法则
- Linux Lite 7.8重磅发布,12款核心应用全面重写,正式迈向Python + GTK4新时代!
- 【推荐收藏】2026编程赛事活动全年时间安排
- 备战安徽省赛 | 酷丁编程2026年“省赛冲刺班”限时报名开启!
- 晋江市青少年创意编程大赛有哪些赛项?获奖人数是多少?
- 2025国庆献礼⑦:智码云端《少儿Python趣味编程与人工智能》为未来公民铺设数字思维基石
- Typer vs传统CLI:Python开发者的新选择与最佳实践
- Python基础——字典与while循环
