RViDeNet论文+代码实践V0.4(问题集:环境血泪史)
- 2026-06-25 11:49:17
RViDeNet论文+代码实践V0.4(问题集:环境血泪史)按照本文操作跑不通代码,可以留言或者私信问我 AIISP课程算是系统的学习,目前课程中介绍AIISP的部分基本看完,剩余传统ISP和基础AI知识点介绍后续穿插着整理。论文+代码实践算是番外篇,基于具体的AIISP任务+理论+代码实践快速的上手AIISP,本人习惯用版本号的方式进行迭代,具体任务的论文+代码实践随着不断的学习,理解也会发生变化,查看最大的版本号即可,中间都是迭代的过程。 EMVD论文+代码实践V0.2 (AIISP V0.8) 无显卡干中学AI 下载RViDeNet pdf论文上传AI工具(强烈推荐使用豆包): 1、让豆包详细总结这篇文档内容;总结下论文; 2、阅读完1的基础上,让豆包翻译全文,中文过完再过一遍英文 一般完成上述两个操作就能明白论文具体解决什么问题?如何解决? 一、解决什么问题: 1、数据集构建:首个动态场景原始视频带噪-干净数据集(55组视频,ISO 1600-25600) 2、网络设计:提出RViDeNet,融合空间、通道、时间相关性处理原始视频 3、功能扩展:支持输出原始域降噪结果,还可通过ISP模块输出sRGB结果(支持自定义ISP) 
二、如何解决的: 1、动态场景数据集构建:我称之为假动态场景,通过拍摄物体运动过程中的静止帧构建,实际还是物体静止、相机静止拍摄,按照我ISP的理解,数据集应该很难模拟真实运动场景噪声表现,尤其是运动区域和静止区域过渡区域,这个可以代码实践,基于效果来看。 
2、介绍了主流的构建视频raw数据的方法包括代码,个人感觉比1的方法更好,只是直觉,以实验效果为准: 
3、RViDeNet (1)整体流程:输入连续 3 帧带噪原始视频→按拜耳模式打包为 RGBG 四子序列→预降噪→对齐→非局部注意力→时间融合→空间融合(生成原始域结果)→ISP 模块(生成 sRGB 结果)。标红部分不是很明白,结合代码进行理解 

(2)损失函数 
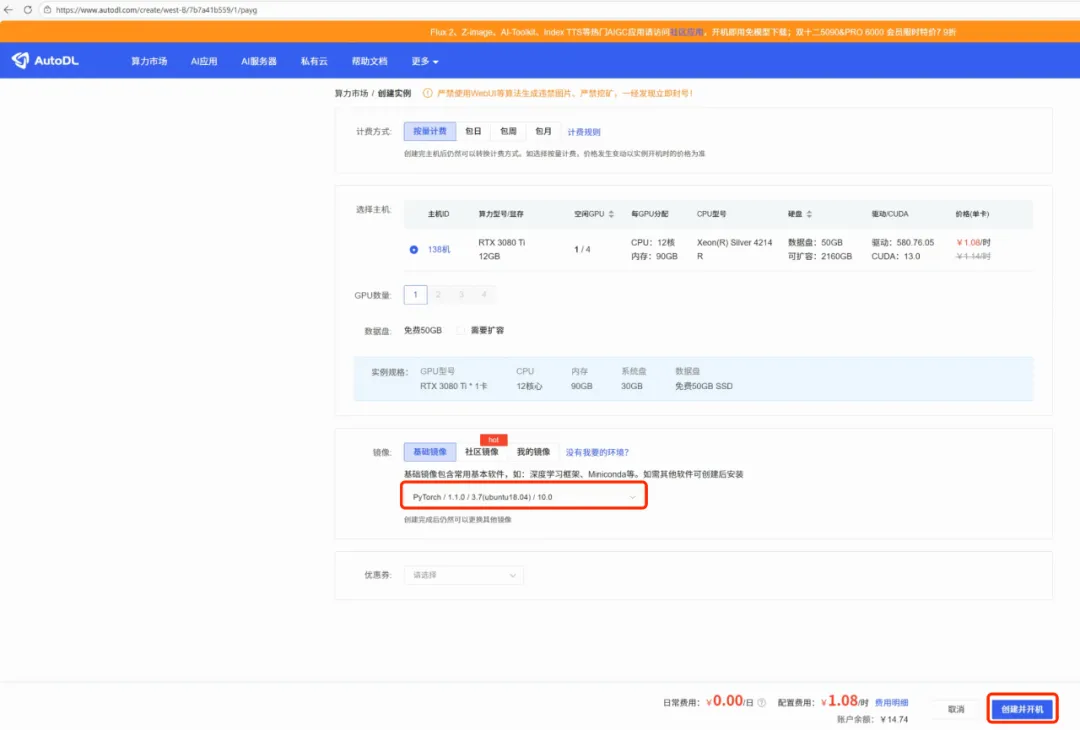
一、环境配置 1、租赁GPU 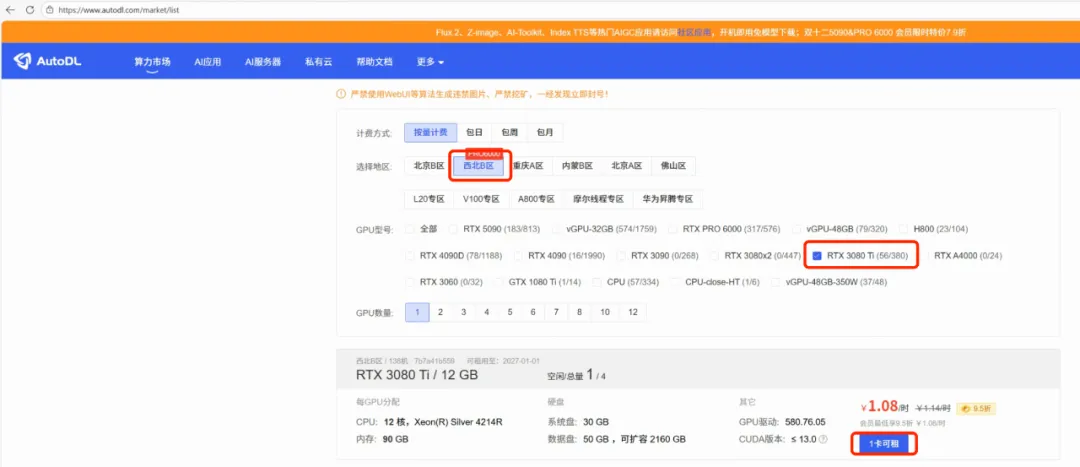
其他操作参考无显卡干中学AI 2、搭建github环境 (1)tensorflow gpu环境问题(cudnn版本没有匹配),先使用cpu版本 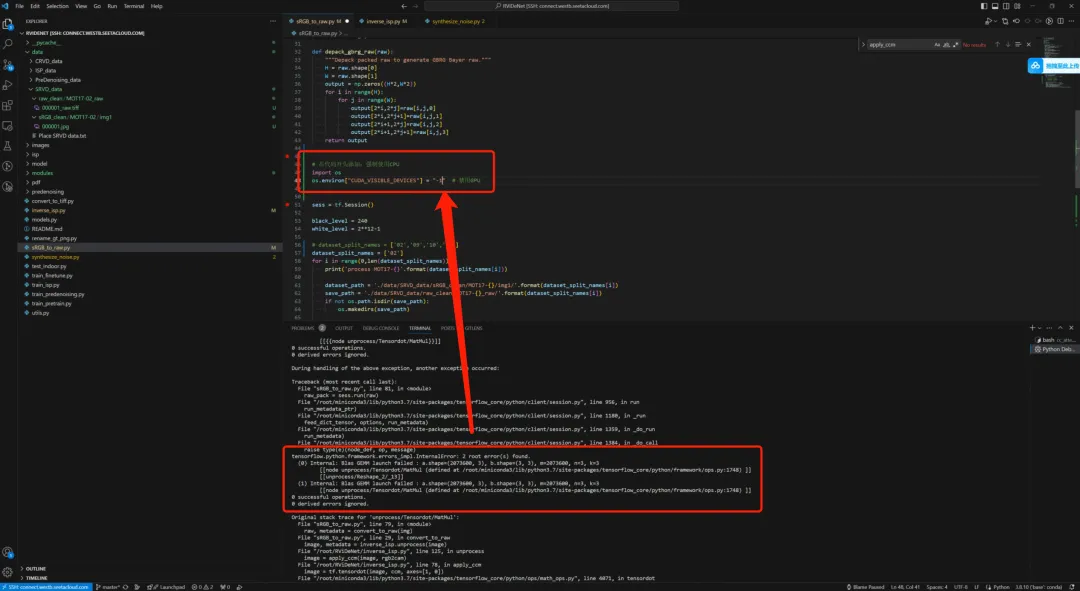
二、数据 数据构建:(1)无噪声rgb转无噪声raw;(2)标定设备噪声模型;(3)在无噪声raw根据设备噪声模型添加噪声 (1)本地下载MOT17Det数据,无噪声rgb转无噪声raw(https://motchallenge.net/data/MOT17Det/),参考无显卡干中学AI,按照代码路径上传AutoDL(开始跑通可以上传几张) 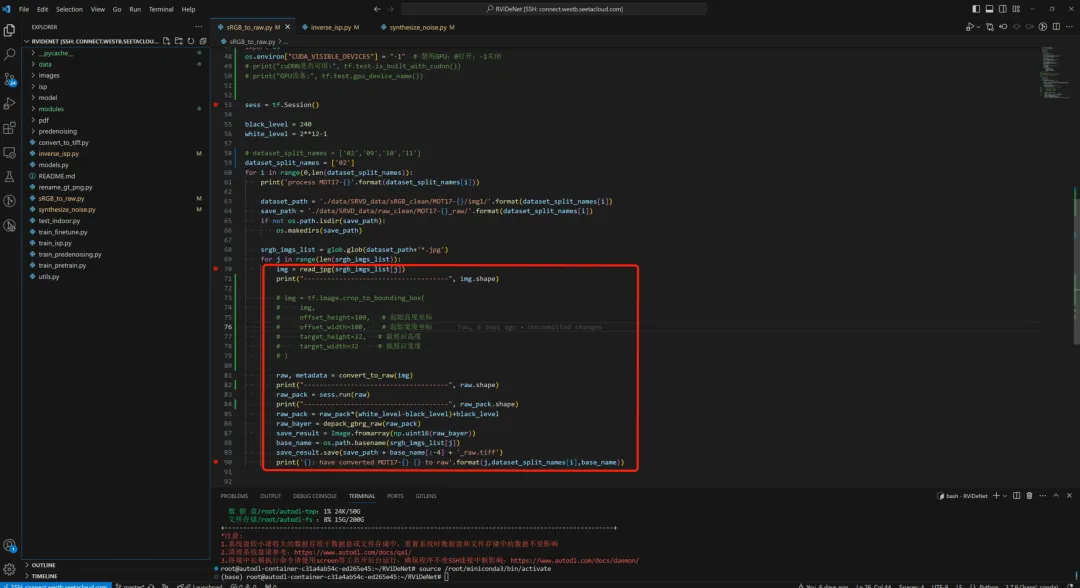
反gtm;反gamma;反ccm;反awb;反demosaic 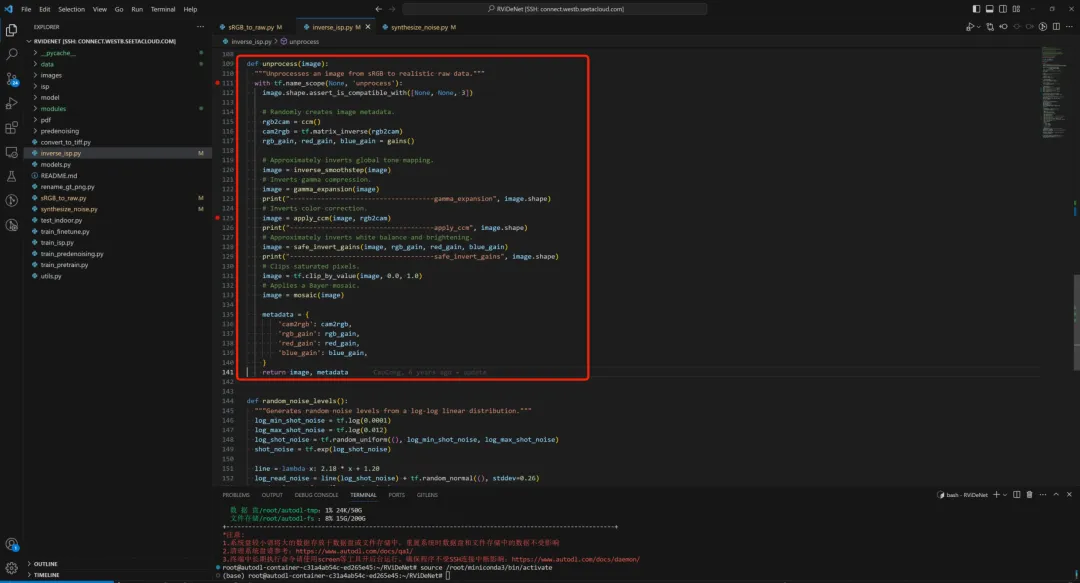
(2)github代码没有标定设备噪声模型的代码,有在无噪声raw根据设备噪声模型添加噪声的代码,我就先反过来,先了解噪声模型怎么用,再结合论文搞清楚如何进行标定设备噪声模型 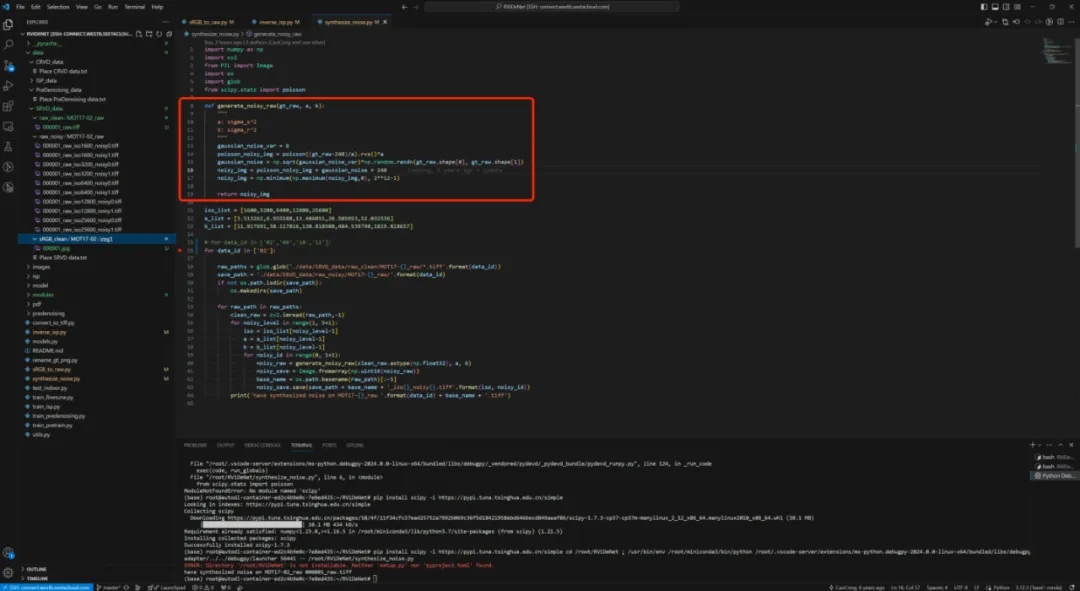
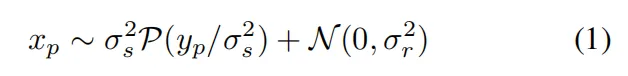
和论文的噪声模型公式对应的上,得出噪声模型不同iso下a,b两个参数a=σs2(散粒噪声方差),b=σr2(读取噪声,黑帧的方差,这个基于黑帧直接算即可),散粒噪声方差论文中的计算过程: 
计算公式比较清晰,有一个地方没搞明白: 1、直线的斜率k即为估计的2σs2?: 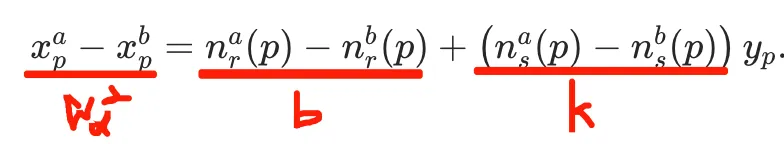
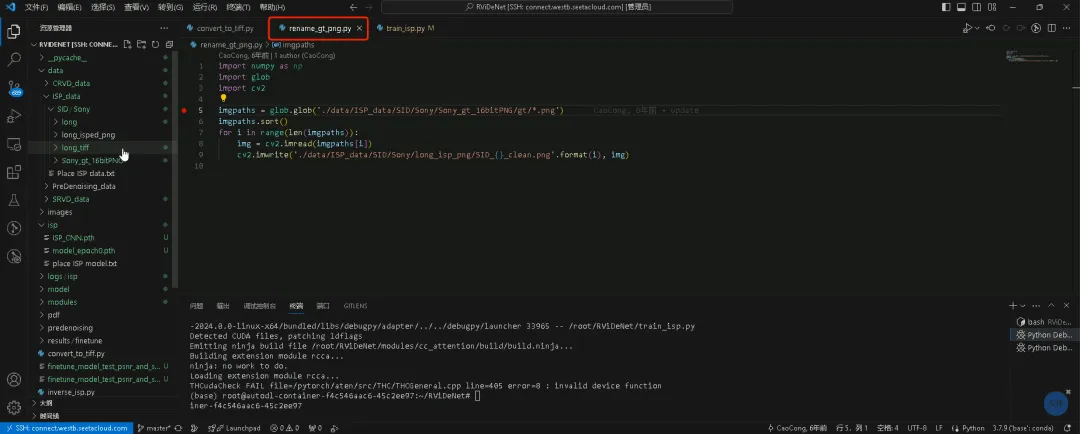
yp和σd2满足线性关系σd2=k*yp+b ,σd2是σs2的两倍;所以k=2σs2 三、训练 RViDeNet整体流程:输入连续 3 帧带噪原始视频→按拜耳模式打包为 RGBG 四子序列→预降噪→对齐→非局部注意力→时间融合→空间融合(生成原始域结果)→ISP 模块(生成 sRGB 结果) 1、ISP模块:基于SID数据集训练 1.1、下载SID数据集,需要外网下载,如有需要私信标准SID数据集 1.2、convert_to_tiff.py和rename_gt_png.py脚本配置下SID数据集路径,生成训练需要的数据格式。脚本几十行代码,比较简单 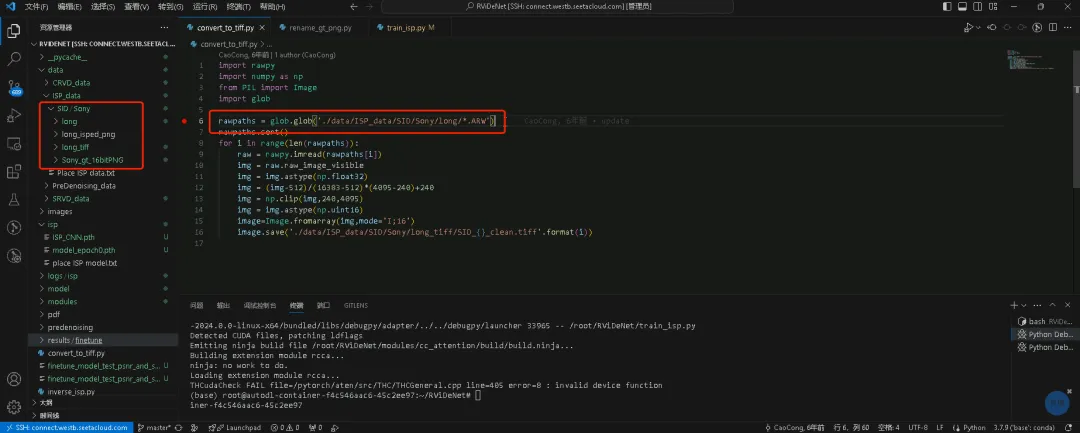
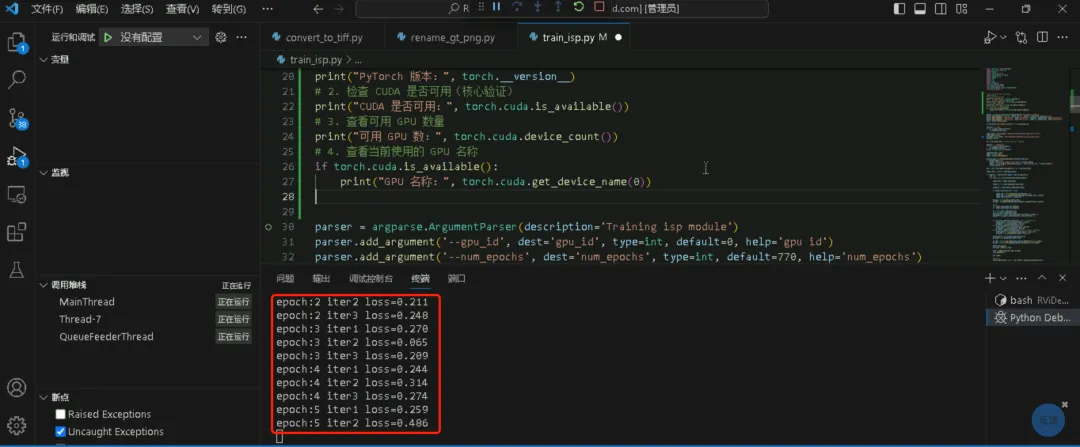
1.3、开始训练:python train_isp.py --gpu_id 0 --num_epochs 770 --patch_size 512 1、截图红框代码报错:RuntimeError: cuDNN error: CUDNN_STATUS_EXECUTION_FAILED 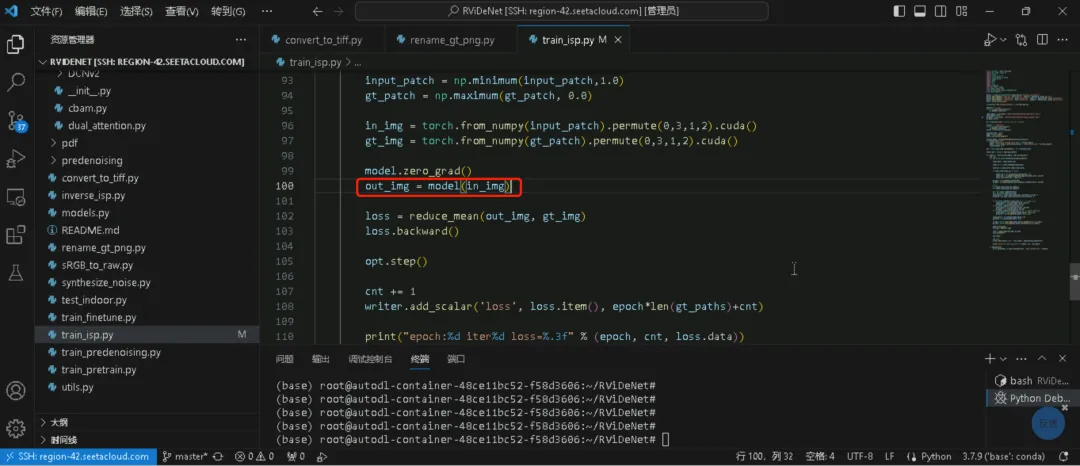
(1)结合豆包分析定位过程梳理了一遍,不得不说当前AI确实牛逼,很清晰,确实提高效率,甚至替代部分工作。不过最终还是没能找到原因 (2)折腾了两个周末,重新创建环境的时候发现3080ti新架构不支持CUDA11以下版本,死马当活马医试了下2080ti,可以了。果然理清楚到极致总能解决问题,只是时间问题。后面跑老的github代码就用2080ti+Pytorch1.1.0+cuda10.0 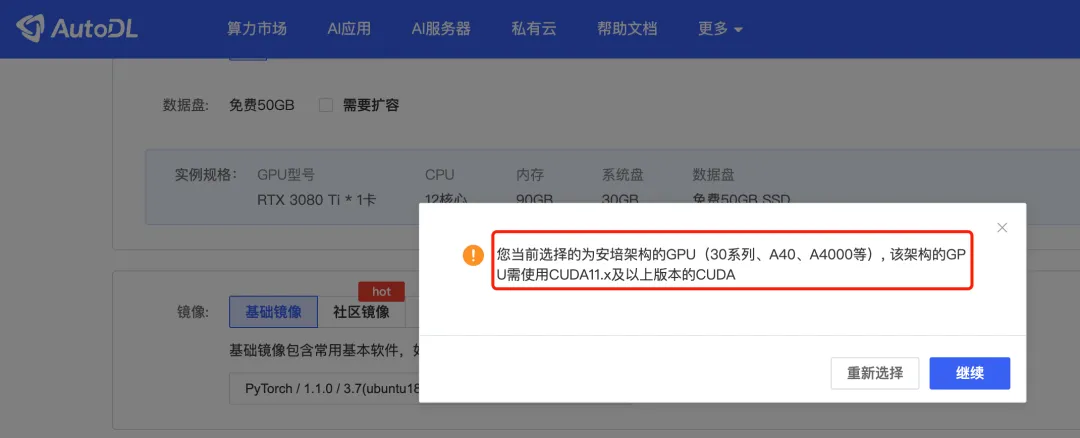
精选文章: AIISP ISP仿真工具 ISP
00
—
前言
往期论文+代码实践:
AIISP_V0.4_20250628_ICELUT论文+代码实践V0.2
01
—
论文
02
—
代码实践
1,跑通代码,可以单步执行
2,单步执行跑一遍整个流程
3,对着论文反复执行2,把不明白的地方加打印或者中间结果图打出来
https://github.com/cao-cong/RViDeNet
https://gitee.com/dripping000/RViDeNet(包含我的修改+一组数据,可直接运行)
# 查看PyTorch版本python3 -c "import torch; print('PyTorch:', torch.__version__)"# 查看PyTorch内置CUDA版本python3 -c "import torch; print('CUDA:', torch.version.cuda)"# 查看系统CUDA版本nvcc -V | grep release# 安装python依赖库pip install tensorflow-gpu==1.13.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepython -c "import tensorflow as tf; print(tf.__version__); print(tf.test.is_gpu_available())"pip install torch==1.0.0 torchvision==0.2.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simplepip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simplepip install scikit-imagepip install rawpypip install ninjapip install tensorboardX
https://storage.googleapis.com/isl-datasets/SID/Sony2025.zip
https://drive.google.com/file/d/1wfkWVkauAsGvXtDJWX0IFDuDl5ozz2PM/view?usp=sharing
03
—
问题集
pytorch、cuda、驱动版本匹配:没问题 能否跑通简单模型例程:不能
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 32岁程序员猝死悲剧揭示职场困境:公开代码倡导“反996”,猝死后工伤认定陷争议
- 【社团风采】当“我的世界”遇上编程 ——我的世界编程社团学期精彩回顾
- 衡水最新乡级行政区划代码公布!
- 优雅代码的32条法则
- Linux Lite 7.8重磅发布,12款核心应用全面重写,正式迈向Python + GTK4新时代!
- 【推荐收藏】2026编程赛事活动全年时间安排
- 备战安徽省赛 | 酷丁编程2026年“省赛冲刺班”限时报名开启!
- 晋江市青少年创意编程大赛有哪些赛项?获奖人数是多少?
- 2025国庆献礼⑦:智码云端《少儿Python趣味编程与人工智能》为未来公民铺设数字思维基石
- Typer vs传统CLI:Python开发者的新选择与最佳实践
