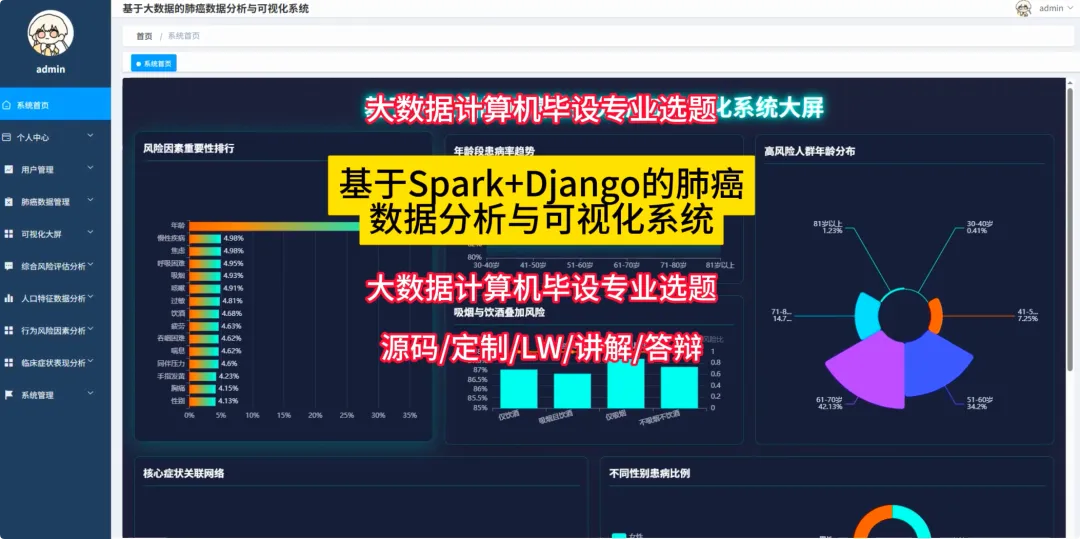
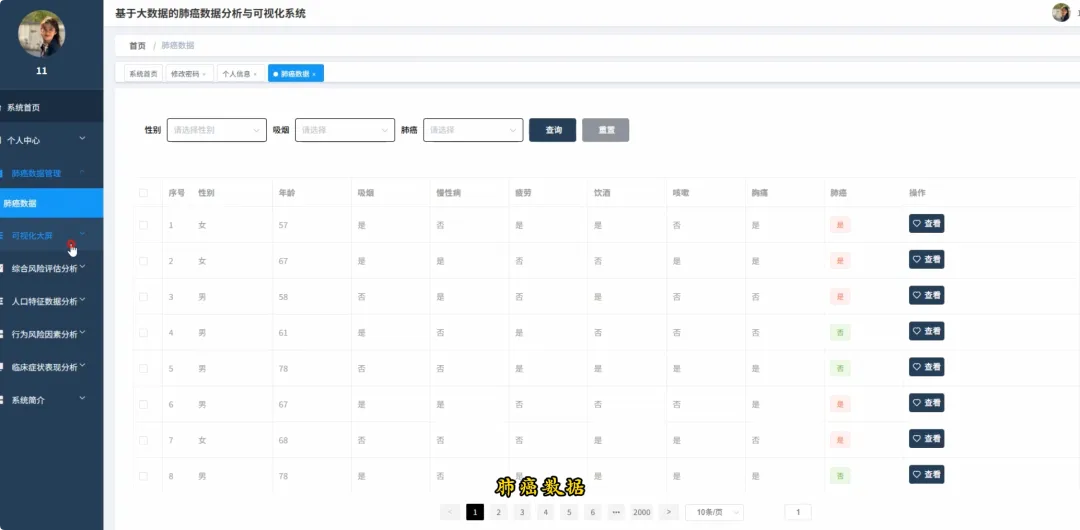
from pyspark.sql import SparkSession, functions as Ffrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.classification import RandomForestClassifierspark = SparkSession.builder.appName("LungCancerAnalysis").getOrCreate()def analyze_age_gender_prevalence(df): df = df.withColumn("age_group", F.when(F.col("AGE").between(30, 40), "30-40") .when(F.col("AGE").between(41, 50), "41-50") .when(F.col("AGE").between(51, 60), "51-60") .when(F.col("AGE").between(61, 70), "61-70") .when(F.col("AGE").between(71, 80), "71-80") .otherwise("81+")) result_df = df.groupBy("age_group", "GENDER").agg( F.count("LUNG_CANCER").alias("total_count"), F.sum("LUNG_CANCER").alias("cancer_count") ).withColumn("prevalence_rate", (F.col("cancer_count") / F.col("total_count")).cast("double")) result_df = result_df.orderBy("age_group", "GENDER") return result_df.collect()def analyze_smoking_alcohol_interaction(df): smoking_effect = df.groupBy("SMOKING").agg( (F.sum("LUNG_CANCER") / F.count("LUNG_CANCER")).alias("prevalence_rate") ) alcohol_effect = df.groupBy("ALCOHOL_CONSUMING").agg( (F.sum("LUNG_CANCER") / F.count("LUNG_CANCER")).alias("prevalence_rate") ) combined_effect = df.filter((F.col("SMOKING") == 1) & (F.col("ALCOHOL_CONSUMING") == 1)).agg( F.count("*").alias("combined_count"), (F.sum("LUNG_CANCER") / F.count("*")).alias("combined_prevalence") ) return {"smoking": smoking_effect.collect(), "alcohol": alcohol_effect.collect(), "combined": combined_effect.collect()}def calculate_feature_importance_with_sparkml(df): feature_cols = [c for c in df.columns if c not in ["LUNG_CANCER"]] assembler = VectorAssembler(inputCols=feature_cols, outputCol="features") data = assembler.transform(df).select("features", F.col("LUNG_CANCER").alias("label")) rf = RandomForestClassifier(featuresCol="features", labelCol="label", numTrees=10, seed=42) model = rf.fit(data) importances = model.featureImportances.toArray() feature_importance_list = [(feature_cols[i], importances[i]) for i in range(len(feature_cols))] sorted_importances = sorted(feature_importance_list, key=lambda x: x[1], reverse=True) return sorted_importances

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
