这学期选修了一门面向文科专业的人工智能素养课程。由于缺乏编程基础,笔者只能接触到一些可能连入门都算不上的内容。即使如此,在授课老师的鼓励下(同时出于好奇),还是做出了一些尝试。虽然不知专业人士对 AI 编程的评价如何,但它至少能让完全不懂代码的我成功编写出一些小程序。哪怕只是将之视作一次体验活动,哪怕只考虑其带来的趣味,我认为都是有益的。
我的尝试之一是借助ai完成一个从图像中识别并提取文字的应用。诚然,现在已有可以借助 AI 一键识别整个 pdf 文档的软件,甚至很多需求直接使用网页端就可以满足。但面对小体量的工作,例如处理近代早期报纸文章或通信集中的某份信件时,我们往往只需要提取图像中的一两个段落。在这种场景下,若用第一个办法,用户就需要将整个文件(无论拆不拆解)丢给软件,所耗时间过多、且反馈不够即时;而若是使用网页端,截图→粘贴到对话框并附上命令→等待大模型运行→复制粘贴回答结果,这一过程似乎有很大的简化空间。
因此,我尝试用 AI 编程完成了一个轻量应用,内容很简单,包含两个功能:其一,使用截图工具截图到剪贴板后,自动进行图像识别,转化为文本并直接复制到剪贴板;其二,将剪贴板的文字翻译为中文,并且自动复制到剪贴板。只需填好自己的api密钥和所使用的模型名称即可使用,我这里用的是 qwen 的模型,目前试下来基本可以满足我的要求:
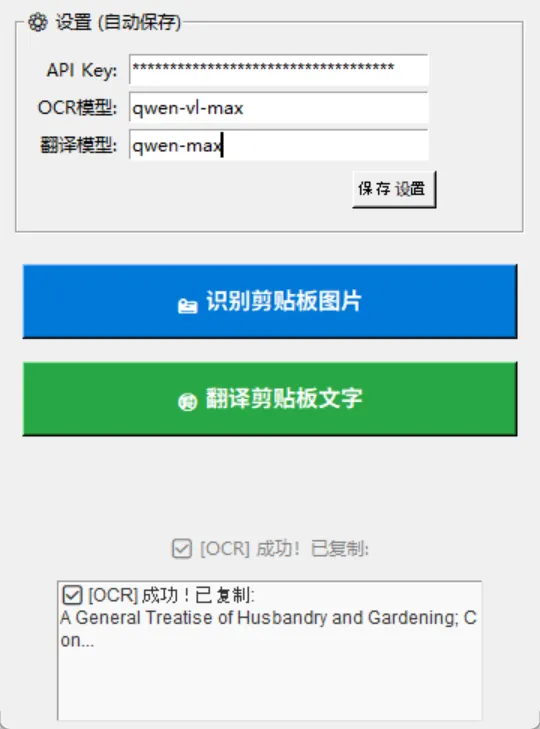
这是从一份近代早期报刊上截下的图片,诚然,按历史系学生的标准,这份扫描件已算质量上乘,离“战损版”还差得很远,不会过分影响阅读。但对传统 OCR 技术而言,识别起来已相当困难。而借助 qwen 模型,应用可以在数秒之内完成识别,识别后的内容如下:
A General Treatise of Husbandry and Gardening; Containing a new System of Vegetation, illustrated with many Observations and Experiments; formerly published Monthly; and now Methodized, and digested under proper Heads, with Additions, and great Alterations in Four Parts.
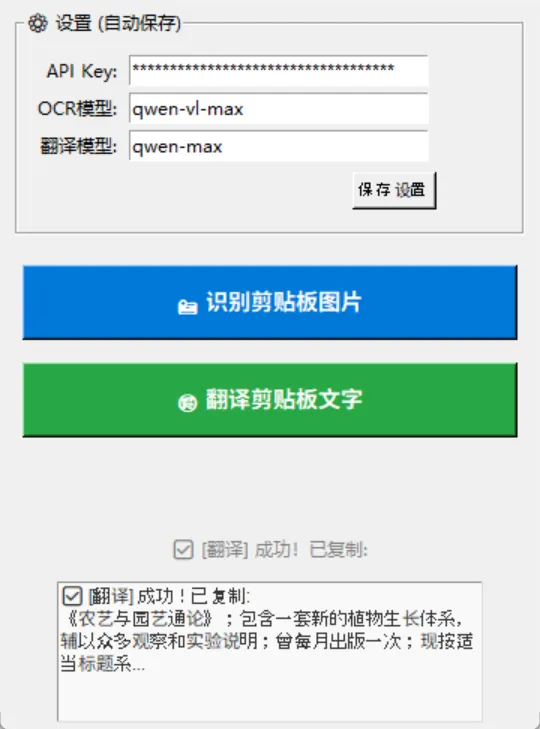
接着尝试将其翻译为中文,这一过程同样只耗费数秒(耗费时间和文本长度等因素有关,但总体而言还是较快的):
《农艺与园艺通论》;包含一套新的植物生长体系,辅以众多观察和实验说明;曾每月出版一次;现按适当标题系统化整理,并添加了大量内容和进行了重大修改,分为四个部分。
在标点符号上存在一些问题,例如这整段话其实都是书名的一部分,严格来说应该是一个书名号囊括所有的内容。然而考虑到需要翻译近代早期书名全称的情景不多,这样的小误差是可以容忍的。
处理完得到的文本可以放入文献笔记中,方便日后检索,这是文本较之扫描图像的一大优势。
识别和翻译的效果本质上取决于使用模型的水平,应用只是将这一操作过程进行了精简。也正因如此,除英语外,只要所使用的模型有相应能力,应用便可以处理其他语言的文本。经测试,qwen模型基本可以承担主流语言印刷体的识别工作,但在使用它识别和翻译拉丁语扫描图像时,哪怕是印刷体,效果都不尽人意。对于手稿图像和略小众的语言,应当借助这方面能力更突出的模型。以下是我的一个演示视频,可以展示本应用实际使用的场景:
在演示视频中,我尝试让应用识别并且翻译一个非常清晰的手稿信件,尽管识别的效果差强人意,但翻译近代早期英语对于模型来说或许还是有点困难。不过,这同样属于模型选用方面的问题,一般而言,外国模型对于非现代语言文本的识别能力会更强一些。
最后是两个英文文本之外的使用例:
识别文本内容:
De Pétersbourg, le 17 Novembre 1786.LA navigation est interrompue par les glaces; plusieurs Bâtiments chargés de fuit & de marchandises des manufactures Angloises, se trouvent pris dans la Newa, dont la navigation n'a été ouverte cette année que pendant 187 jours.
D'Upfal, le 20 Novembre 1786.LE ROI & le Prince Royal continuent à séjourner dans cette ville, & à fréquenter les Cours académiques.
此处成功识别了圣彼得堡的“long s”,但却将乌普萨拉的“long s”错误识别为了“f”。不过,地名的翻译是正确的:
从圣彼得堡,1786 年 11 月 17 日。航行因冰封而中断;许多装载着木材和英国制造商品的船只被困在涅瓦河中,今年该河的通航期只有 187 天。
从乌普萨拉,1786 年 11 月 20 日。国王和王储继续留在这座城市,并频繁参加学术课程。
识别文本内容:
裴駰司馬貞索隱曰駰字龍馹河東聞喜人宋中郎外兵曹參軍父松之字尗期太中大夫注三國志宋書父子同傳○正義曰裴駰採九經諸史幷漢書音義及衆書之目而解史記故題史記集解序序緒也孫炎云謂端緒也孔子作易卦子夏作詩序之義其來尚矣
这时使用翻译功能会将原文本部分转为简体中文并且加标点,存在的问题是,它会将一部分内容加标点、一部分不加;一部分内容翻译、一部分不翻译:裴骃司马贞索隐曰:骃字龙馹,河东闻喜人,宋中郎外兵曹参军。父松之,字尗期,太中大夫,注《三国志》。《宋书》父子同传。○正义曰:裴骃采九经诸史并《汉书》音义及众书之目而解《史记》,故题《史记集解序》。序,绪也。孙炎云:谓端绪也。孔子作《易卦》,子夏作《诗序》,其义由来已久。
这是由于我在代码中给翻译功能内嵌的提示词为“你是一个专业的翻译助手。请将用户输入的文字直接翻译成流畅的简体中文。不要解释,不要输出任何额外的对话内容,只输出译文。”根据自己的需求去修改提示词,能够实现更多的功能。比如将提示词改为“请为用户输入的文本添加现代标点符号,无需对原文内容进行改动。”即可将功能从“自动翻译”改造为“自动添加标点”。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
