点击上方「蓝字」关注我们
数字土壤制图(Digital Soil Mapping,DSM),简单说,就是用数据和模型“算”出土壤在空间上的分布。它不再只依赖少量样点和经验外推,而是将实地土壤样点与环境协变量(如地形、气候、遥感指数、土地利用、母质等)结合,利用统计模型或机器学习方法(如随机森林、XGBoost、GAM 等),在连续空间上预测土壤属性(如 SOC、SIC、pH、质地等)的分布及其不确定性。数字土壤制图的核心思想是:土壤是环境因子的函数,通过量化“土壤—环境”关系,实现高分辨率、可重复、可更新的土壤信息制图,已成为全球土壤碳评估、生态模型和土地管理的重要技术基础。
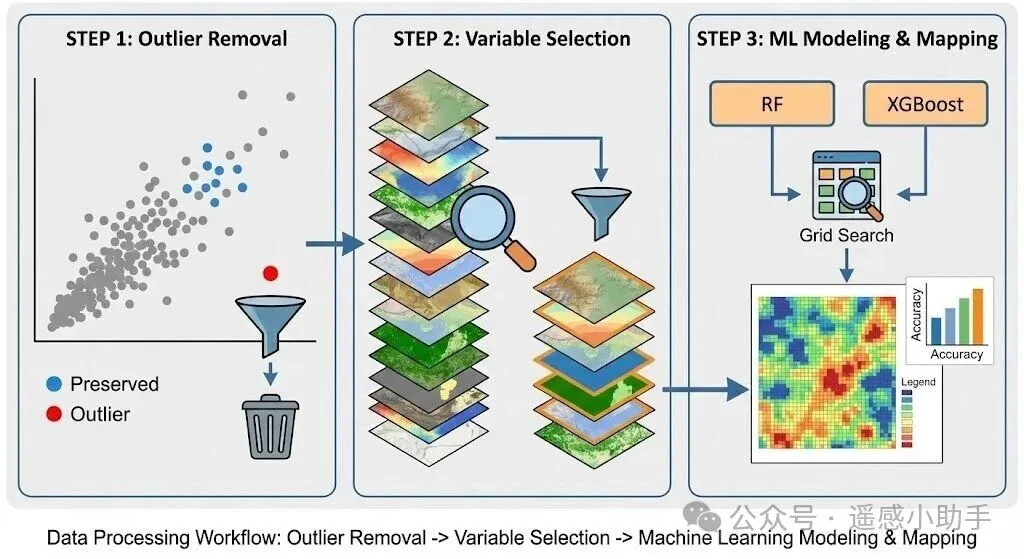
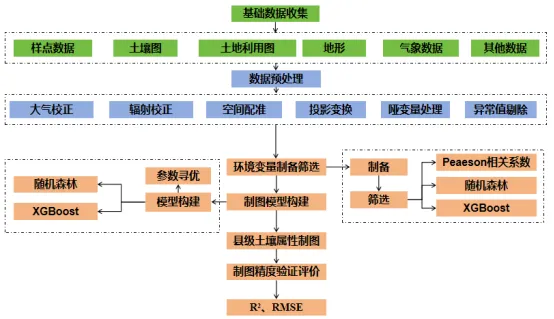
二、整体技术路线
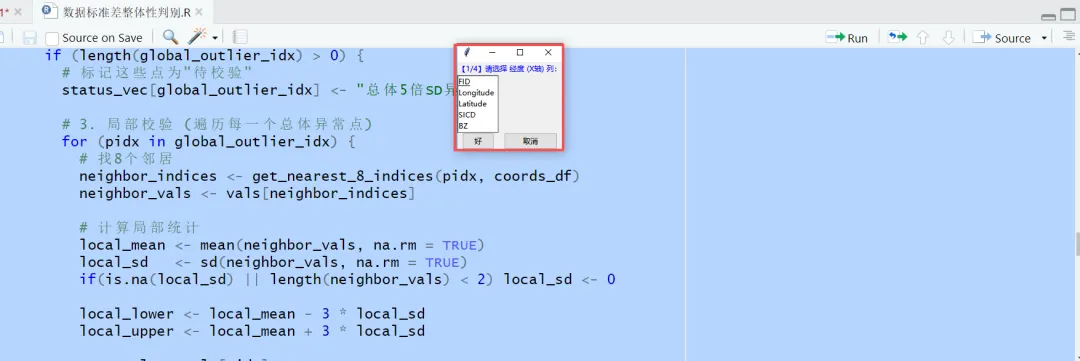
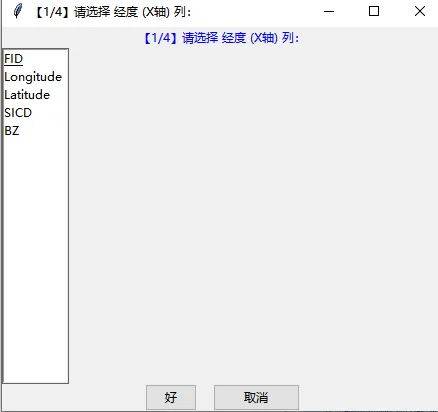
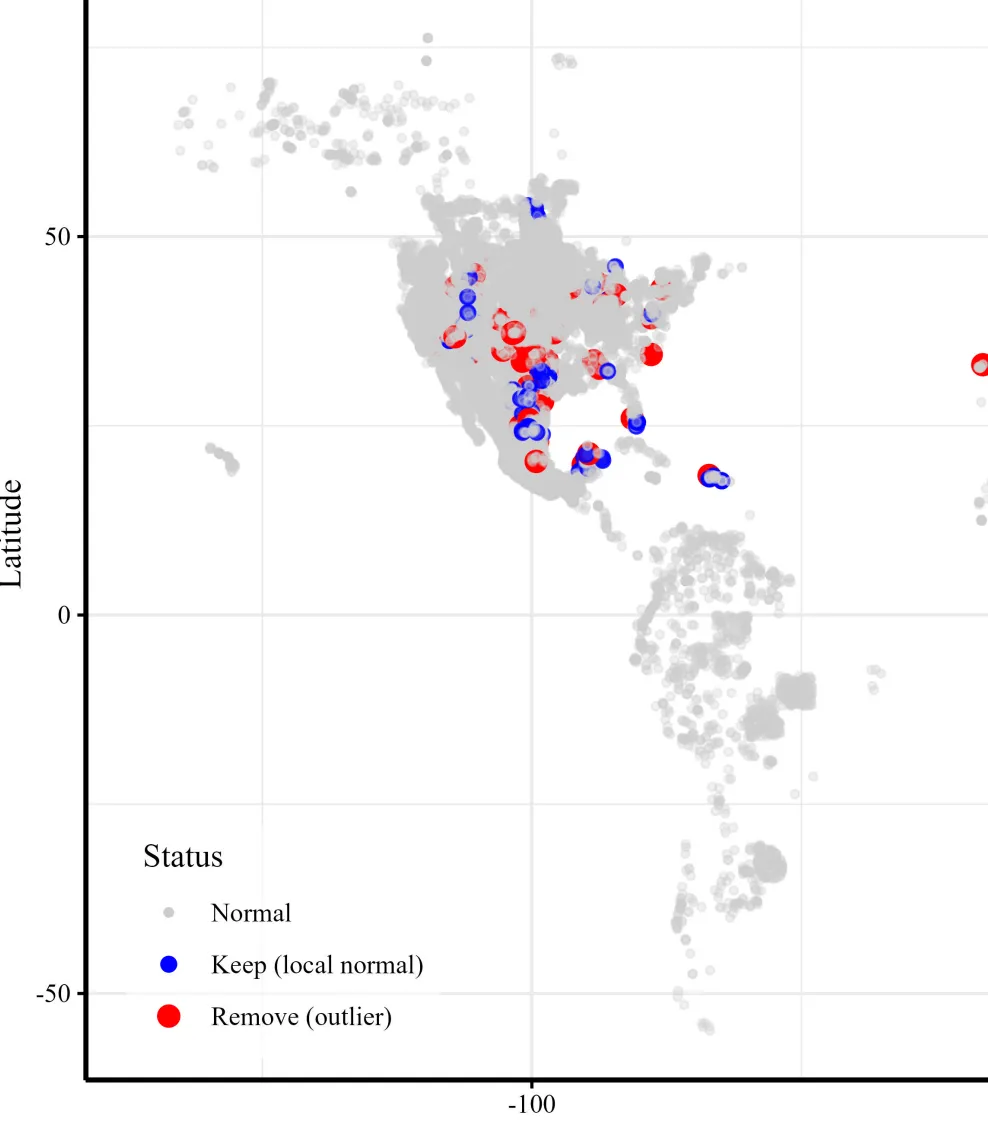
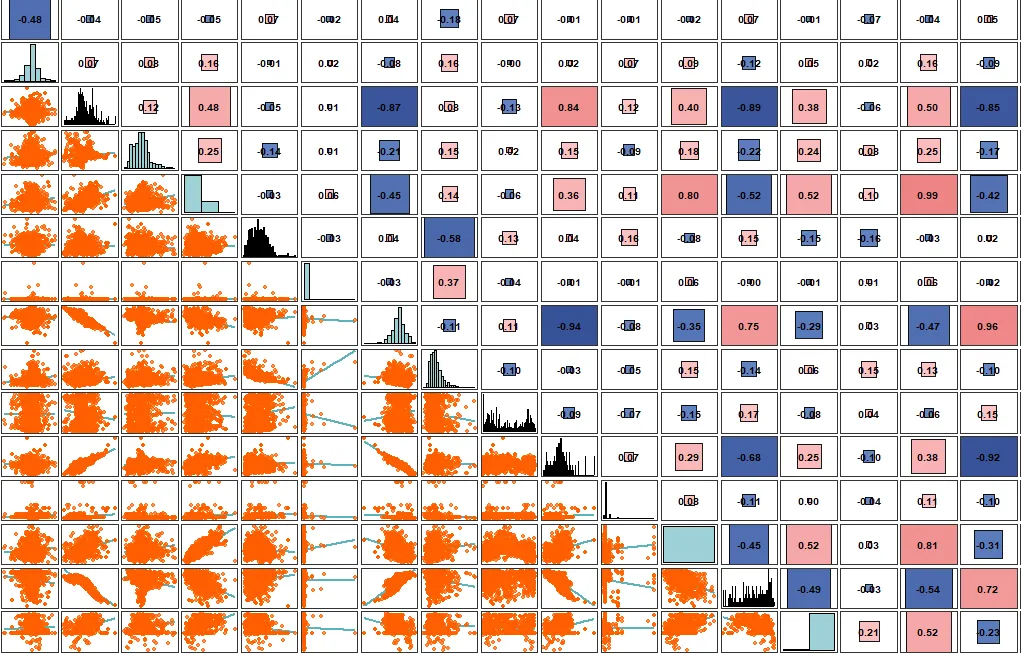
异常值检验。由于样点采集与化学分析过程的不确定性,需对土壤属性数值进行正态分布检验后做异常值剔除处理,结合数据的常规统计学特征和空间位置,将每个样点的属性值与总体及其邻近8个样点的均值和标准差进行比较,如果样点值在总体均值的5倍标准差之外,且大于或是小于邻近样点均值的3倍标准差,则需对异常值进行核验后剔除。
为了方便,我们也是把代码制作成了小工具,方便数据剔除与成图
模拟数据示意图
计算代码:(1)自动计算距河流距离:
https://code.earthengine.google.com/f0dfb8946697d834b1d9869d538965ef
(2)计算植被指数:https://code.earthengine.google.com/3c0aee52db3aceb618df7a952a724738
筛选环境变量主要是为了剔除两两变量之间存在共线性,对模型造成信息冗余。我们主要是利用张甘霖老师文献中的思路,对于相关系数大于0.8的环境变量进行剔除。
张甘霖老师文献链接:
https://doi.org/10.1016/j.still.2025.106457
(1)按照三普规范要求,依据地形地貌使用2-3个模型进行制图,但是在模型制图时候记得对土地利用类型和土壤类型进行变量哑变量处理,被模型认成数值连续变量可就影响最后结果呢。因为类别变量不存在数值大小问题。
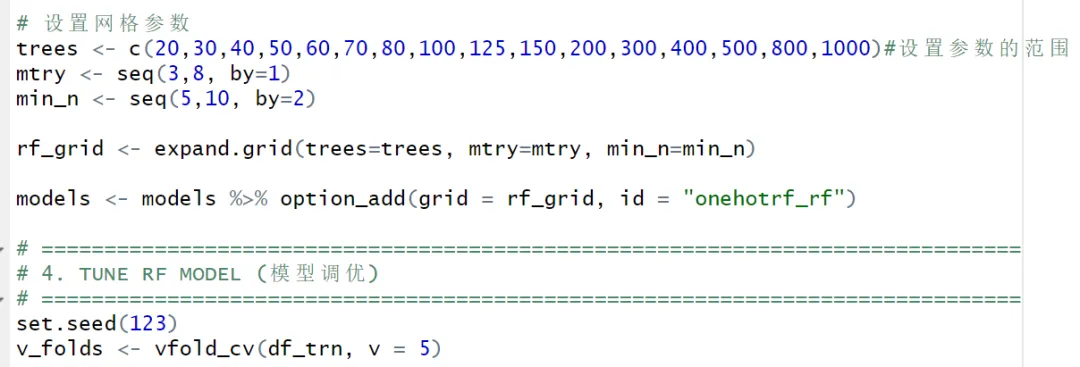
(2)模型最小网格参数寻优
在机器学习建模中,参数寻优并不是“网格越大越好”,而是要在效率与泛化能力之间取得平衡。所谓“最小网格参数寻优”,指的是在理解模型机理的基础上,仅对最关键、最敏感的参数进行有限范围的系统搜索,避免无目的、计算成本极高的全参数暴力调参。以随机森林(RF)为例,其性能主要受树的数量(ntree)和每次分裂使用的变量数(mtry)控制,在样本量有限或变量较多的情况下,合理收敛 mtry 的搜索范围往往比盲目增加树数更重要。而在 XGBoost 中,模型复杂度和过拟合风险高度依赖学习率(eta)、树深(max_depth)和子采样比例(subsample、colsample_bytree),通过小范围、分阶段的参数组合搜索,既能显著提升模型稳定性,也能减少计算时间。实践中,最小网格寻优强调“先理解模型,再调整参数”,其目标不是追求极限精度,而是获得稳健、可解释、可推广的预测结果。
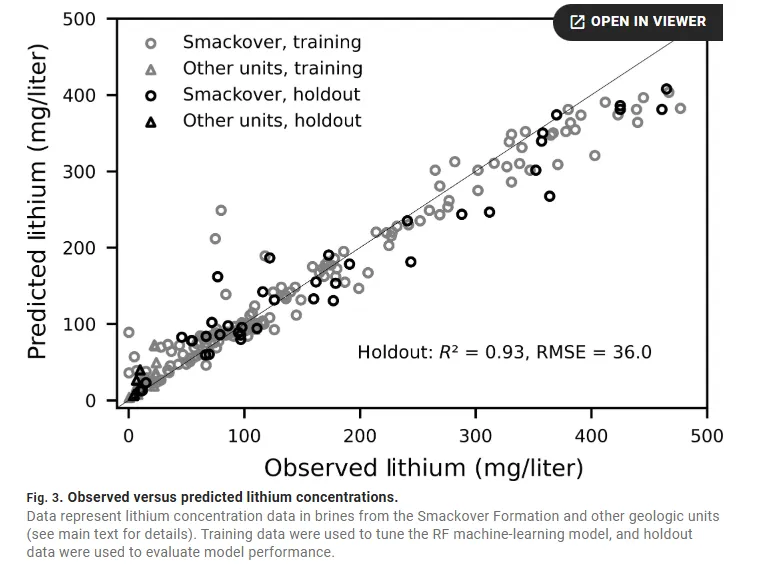
在机器学习建模中,模型对比与交叉验证是保证结果可靠性的关键环节。不同模型对数据结构和噪声的敏感性不同,单一模型往往难以全面刻画复杂的土壤—环境关系。因此,通过在统一数据集和相同验证框架下对比多种模型(如随机森林、XGBoost、GAM 等),可以更客观地评估模型性能与稳定性。交叉验证则通过反复划分训练集和验证集,有效减少偶然样本组合带来的不确定性,避免模型“恰好拟合某一次划分”的假象。尤其在样本数量有限、空间异质性强的土壤研究中,交叉验证能够更真实地反映模型的泛化能力,使模型对比结果更具说服力。最终,模型优劣的判断不应仅基于单次精度指标,而应综合考虑多次验证下的平均性能、稳定性和解释一致性。
为了给大家营造一个良好的交流平台,我们搭建了土壤遥感交流群。
遥感交流群是一群具有土壤学、遥感、环境科学背景的高校老师、在读博士、生产单位技术负责人群体,入群可以交流讨论三普、科研及技术问题、相关文献下载、升学与招聘等。
由于群人数超过500人,想要入群的小伙伴可以在公众号右侧添加小编微信邀请进群。
推文若对各位有帮助记得点赞、关注、转发!
小编能力有限,在努力学习中...
希望投稿&合作请联系小编
点个「在看」,你最好看