【Python】新手学 Python 爬虫:用 requests+BeautifulSoup 爬取豆瓣电影,附完整代码和避坑指南
作为刚接触 Python 爬虫的新手,我最近尝试爬取豆瓣电影 TOP250 的数据(电影名、评分、评价人数),过程中踩了不少 “入门级坑”—— 比如被反爬机制拦截、解析 HTML 时标签定位错误、数据存储格式混乱等。现在把完整的实现过程和解决方法整理出来,适合和我一样的爬虫新手参考。
首先说下环境准备:Python 3.9(建议用 Anaconda 管理环境),需要安装三个库:requests(发送 HTTP 请求)、BeautifulSoup4(解析 HTML)、pandas(存储数据到 Excel),用 pip 安装的命令是pip install requests beautifulsoup4 pandas。
接下来是核心逻辑:豆瓣电影 TOP250 分 10 页,每页 25 部电影,URL 规律是https://movie.douban.com/top250?start=0&filter=(start 参数从 0 开始,每页加 25,比如第 2 页是 start=25,第 10 页是 start=225)。我们需要循环请求 10 页数据,每次请求后解析页面,提取目标信息,最后把所有数据存到 Excel 里。
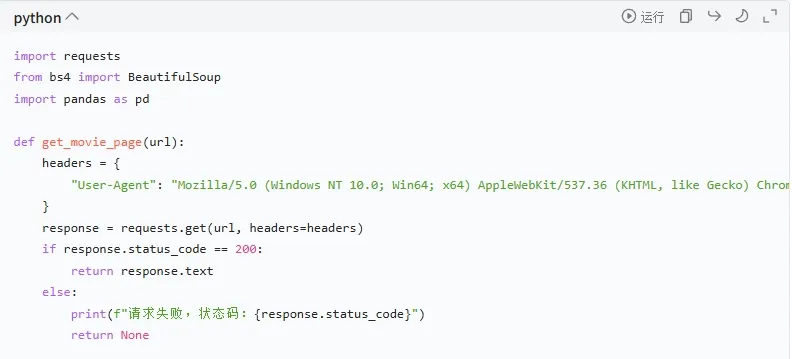
先写请求页面的代码,但一开始直接用 requests.get () 请求,返回的是 403 Forbidden—— 这是豆瓣的反爬机制,识别出我们是爬虫程序。解决方法是给请求加 “User-Agent” 头,模拟浏览器访问。User-Agent 可以在浏览器里查:打开豆瓣 TOP250 页面,按 F12 打开开发者工具,在 “Network” 里找任意一个请求,复制 “Request Headers” 里的 “User-Agent”,代码里用 headers 参数传入:
然后是解析页面数据。用 BeautifulSoup 解析 HTML 后,先定位到每部电影的容器 —— 在页面里看源码,发现每部电影都在class="item"的 div 标签里。循环遍历每个 item,提取电影名(在class="title"的 span 标签里,注意过滤掉英文标题,只保留中文)、评分(class="rating_num"的 span 标签)、评价人数(在class="inq"旁边的 span 标签里,需要用字符串处理提取数字):这里再分享两个新手容易踩的坑:一是解析评价人数时,容易定位错标签 —— 一定要用find_all("span")[-1]取最后一个 span,因为前面的 span 是星级图标;二是爬取速度太快会被封 IP,建议在循环里加time.sleep(1)(需要导入 time 库),每次请求后暂停 1 秒,模拟人工浏览速度。
最后是循环请求 10 页数据,汇总后用 pandas 存到 Excel:

最后提醒:爬虫要遵守网站的 robots 协议(豆瓣的 robots 协议允许爬取 TOP250 数据,但不要频繁请求),不要爬取敏感信息,更不要用于商业用途。这个小项目虽然简单,但能帮新手熟悉 HTTP 请求、HTML 解析、数据存储的完整流程,建议大家动手试试!