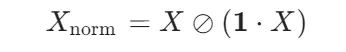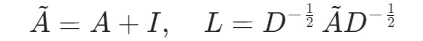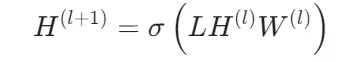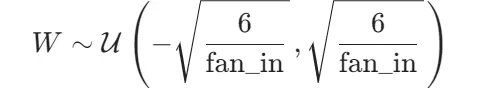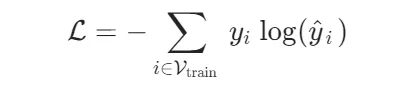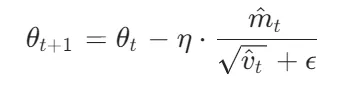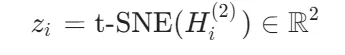本代码实现了一个两层GCN模型,用于在Cora学术文献引用数据集上进行节点分类(预测论文主题类别)。核心流程分为数据预处理→模型架构→训练优化→评估可视化四部分。以下从算法原理和数学公式展开:
1. 数据预处理
Cora数据集包含2708篇论文(节点),每篇论文有1433维词袋特征(x),标签为7个主题类别(y)。邻接矩阵A表示引用关系(边)。关键预处理步骤:
特征归一化:对节点特征矩阵X按行归一化,使每行和为1:
其中⊘表示逐元素除法,1是全1向量。这避免特征尺度差异影响模型。
邻接矩阵规范化:添加自连接并对称归一化,解决节点度分布不均问题:
D是度矩阵(对角元素Dii=∑jA~ij),L是最终使用的拉普拉斯矩阵。此步骤确保信息传播时邻居节点权重平衡。
2. GCN模型架构
模型核心是两层图卷积层(GraphConvolution),每层执行以下操作:
1.图卷积操作:
H(l)是第l层的节点表示(输入层H(0)=Xnorm)
W(l)是可训练权重矩阵
σ是激活函数(第一层用ReLU,第二层用Softmax)此公式源于谱图理论,将傅里叶变换推广到图上,实现节点特征的局部聚合。
2.参数初始化:权重W使用He初始化(Kaiming Uniform),偏置b初始化为0:
其中fan_in是输入维度,此方法缓解梯度消失问题。
3. 训练机制
训练目标是最小化交叉熵损失,衡量预测类别与真实标签的差异:
1.损失函数:
其中y^i=Softmax(logitsi),Vtrain是训练集节点。
2.优化过程:
使用Adam优化器,结合权重衰减(L2正则化)防止过拟合:
m^t和v^t是梯度一阶矩和二阶矩的偏差校正估计,η=0.1是学习率。
反向传播时,计算损失对权重W的梯度∇WL,通过链式法则更新参数。
4. 评估与可视化
1.准确率计算:
I是指示函数,Vtest是测试集节点。
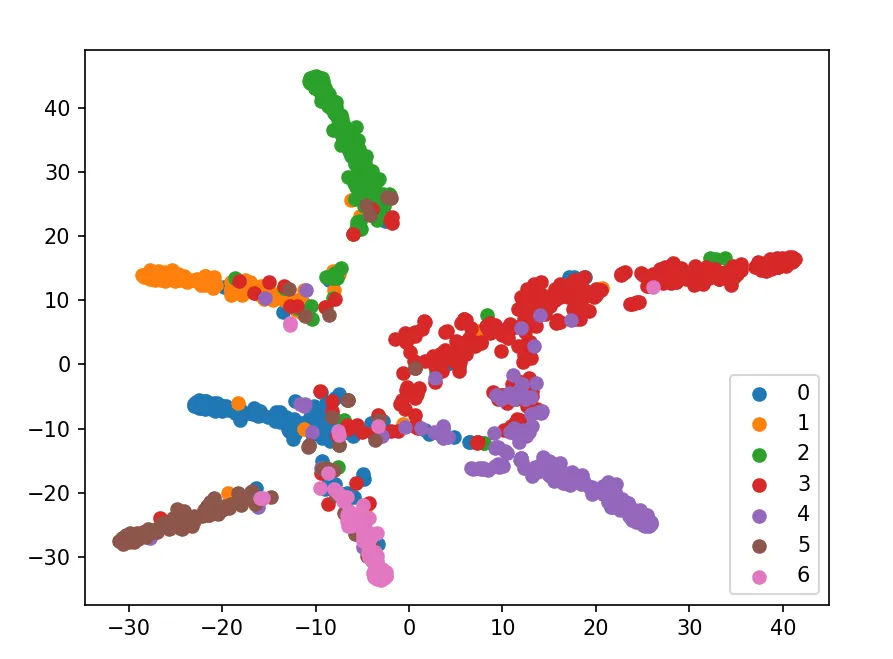
2.t-SNE可视化:
将最终层输出(7维logits)降维至2D:
通过KL散度最小化保留样本间相似性,直观展示不同类别节点的聚类效果。
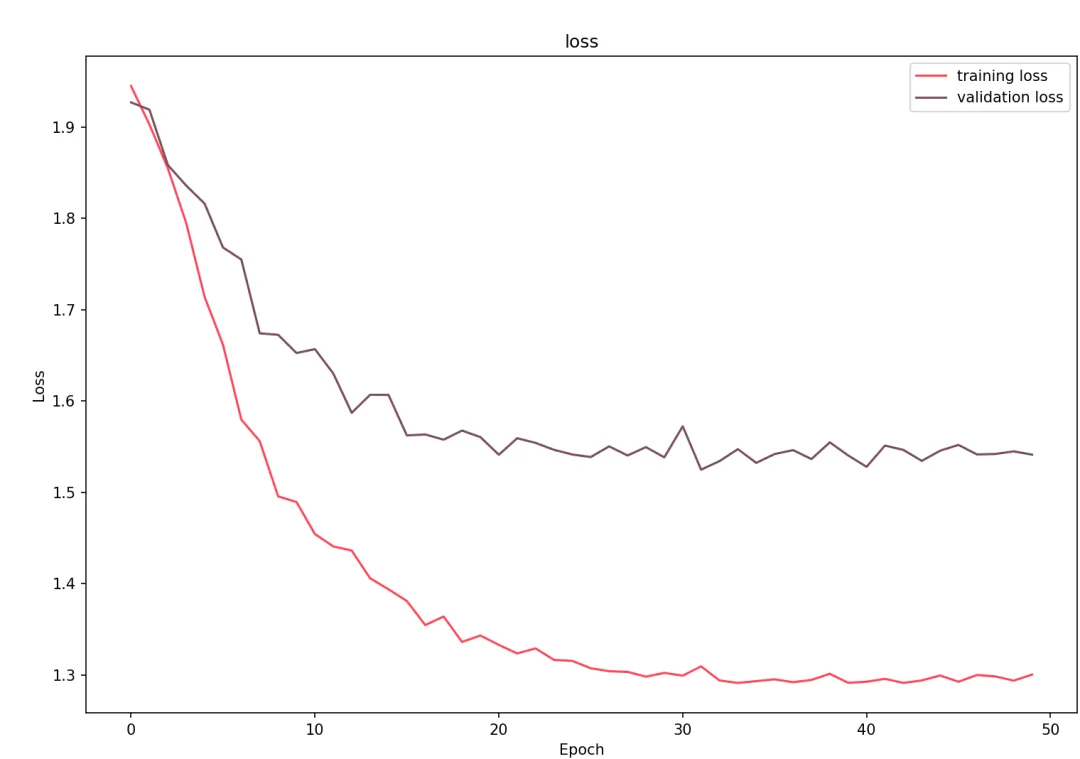
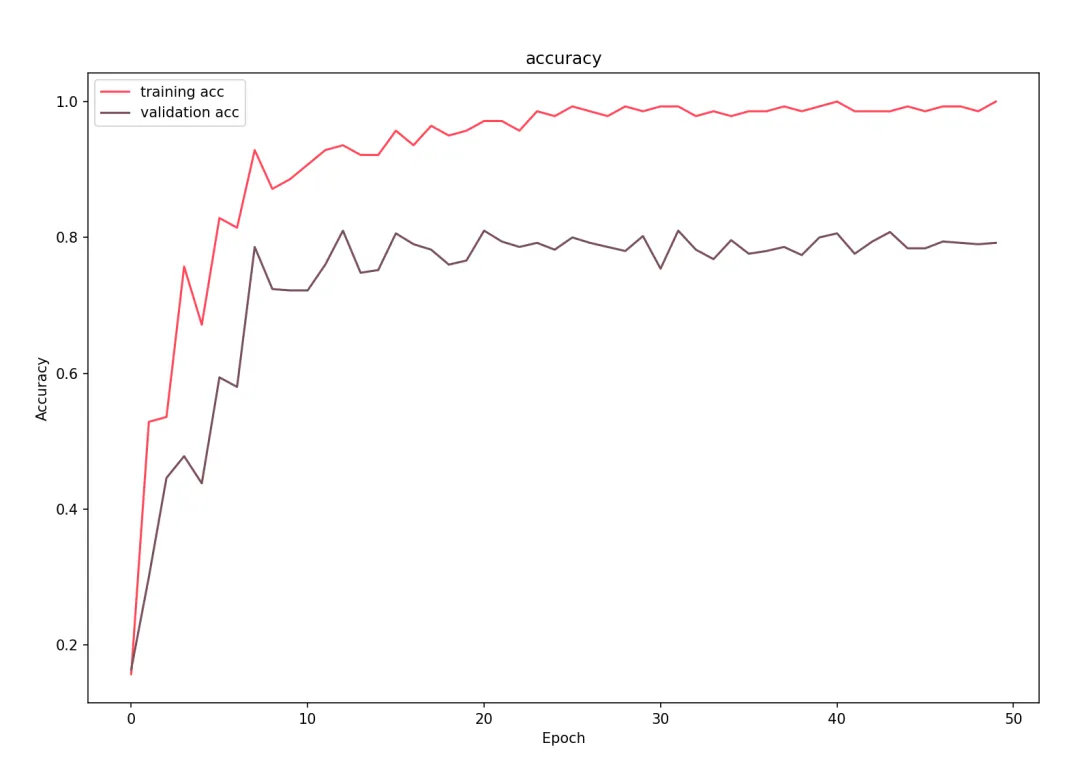
3.学习曲线:绘制训练/验证集的损失与准确率随epoch的变化,监控过拟合(如验证损失上升时需早停)。
5. 关键数学挑战与GCN特性
1.过平滑问题:深层GCN中,节点表示趋向收敛至相同值。本模型仅用两层缓解此现象。
2.稀疏矩阵优化:邻接矩阵L以稀疏格式存储,计算LH时使用稀疏乘法,复杂度从O(N^2 )降至O(nnz)(非零元素数)。
半监督学习:仅训练集节点参与损失计算(通过train_mask),验证集用于超参数调优,体现图数据的传播特性。
6.总结
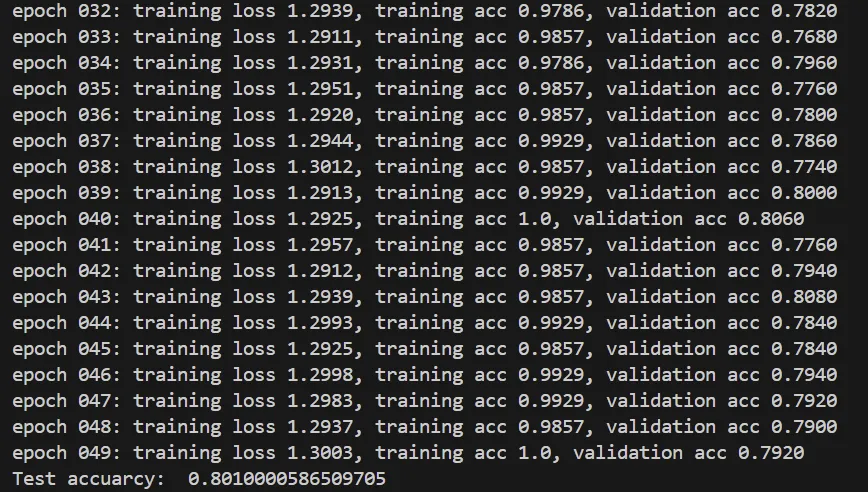
本实现展示了GCN在图数据上的完整流程:通过拉普拉斯矩阵规范化实现邻居信息聚合,利用两层图卷积提取特征,结合交叉熵损失与Adam优化进行端到端训练。最终在Cora数据集上达到约80%的测试准确率,t-SNE可视化验证了类别可分性。与您熟悉的GraphSAGE相比,GCN更依赖全局图结构而非采样邻居,适合全图监督任务。建议进一步探索层数增加对过平滑的影响,或结合注意力机制(如GAT)提升性能。
与我交流(为方便长期交流合作,加好友请按要求备注行业/专业,不胜感激))
微信号|wx18813053116
常用马甲|Grandfissure