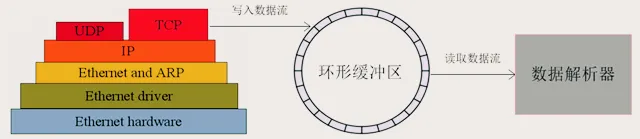
在实际的网络编程中,我们常常面临一边从 Socket 接收数据,一边解析数据的需求。例如:比如做视频流媒体播放,数据从 Socket 源源不断接收,播放端却要按固定帧率解析播放。一边是“急性子”的生产端疯狂输出数据,一边是“慢性子”的消费端按部就班处理,这种速度差很容易造成数据处理混乱。传统的缓冲区在应对这种场景时,频繁地进行内存分配和释放,就像在不停地搬家,消耗大量的时间和精力;数据拷贝操作也很冗余,就像做了很多重复的无用功,极大地降低了数据处理的效率。面对这些问题,我们急需一种更高效的数据缓冲方案,而环形缓冲区(Circular Buffer/Ring Buffer)应运而生。
一、 什么是环形缓冲区?
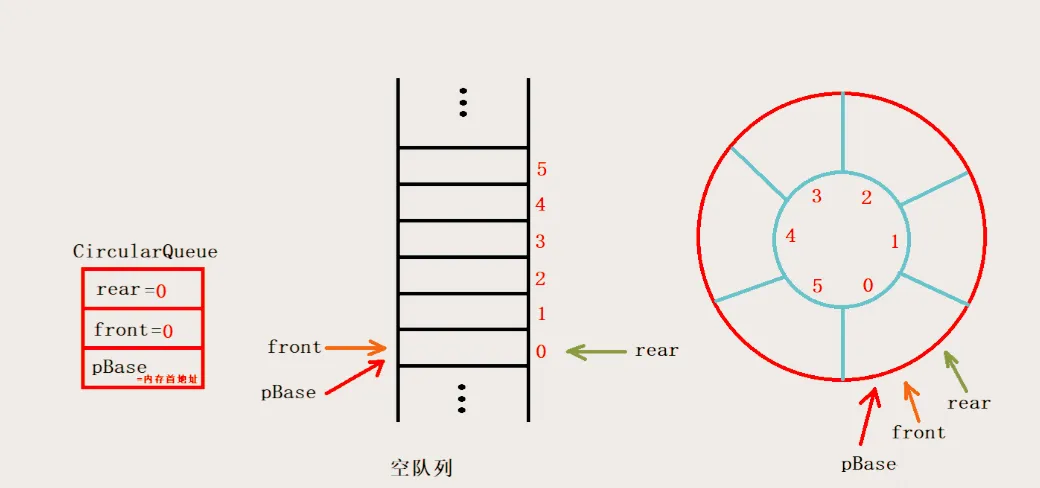
环形缓冲区,光听名字就能脑补出它的大致形态——它物理上是一段连续的内存空间,逻辑上却能实现首尾衔接,像个循环的环。
在这个环形的世界里,数据遵循 FIFO(先进先出)的原则进行存储和读取,就像排队一样,先来的先处理。它通过一对读写指针来管理数据的进出,写指针指向数据写入的位置,读指针指向数据读取的位置。当写指针到达缓冲区末尾时,会自动回到开头继续写入;读指针也是如此。这种独特的设计,使得它能够高效地循环复用内存空间,避免了传统缓冲区的诸多问题,成为了解决生产者 - 消费者模型中速度差异的有力工具。
二、环形缓冲区的 “底层逻辑”
2.1 核心结构
很多人会误以为环形缓冲区物理上就是环形,其实不然——它的本质是一段连续数组,之所以能实现“循环”效果,全靠读指针(tail)和写指针(head)的巧妙配合。
tail 指针指向的是当前最旧的、还未被读取的数据的位置,就像是队伍的排头;而 head 指针指向的是最新写入的数据的下一个位置,仿佛是紧跟在队伍末尾新成员后面的那个空位。当进行数据写入时,新数据会被放到 head 指针指向的位置,然后 head 指针向前移动一步;读取数据时,则从 tail 指针指向的位置取数据,取完后 tail 指针也向前移动一步。
这里有个巧妙的地方,当 head 或 tail 指针移动到数组末尾时,会通过取模运算(index = (index +1)% Size ,其中Size是缓冲区的大小)自动回到数组开头,就像在操场上跑步,跑到终点后又接着从起点继续跑,从而实现了逻辑上的环形效果。这种设计既简单又高效,让缓冲区能够循环利用内存,避免了传统数组在数据处理过程中需要频繁移动元素或重新分配内存的麻烦 。
2.2 关键状态判断:如何区分 “空” 与 “满”?
用好环形缓冲区,首要任务就是精准判断它的空满状态。
为什么是这样的判断逻辑呢?
为了理解这个,我们可以想象一下环形缓冲区就像一个圆形的轨道,head 和 tail 指针在上面 “奔跑”。当它们处于同一位置时,就好比运动员还没开始跑,赛道上自然没有 “数据选手”,也就是缓冲区为空。而当 head 指针比 tail 指针快一步,即将追上 tail 指针时(这里通过取模运算来实现环形的判断),就像赛道上的选手把所有位置都占满了,此时缓冲区就满了。
在实际的读写操作中,我们只需要移动这两个指针,就可以完成数据的进出管理,而不需要像传统缓冲区那样,在数据读写时进行大量的数据搬移操作,这大大提高了数据处理的效率,同时也减少了内存开销,实现了零额外内存开销的数据管理,是不是很巧妙?
2.3 为什么它是网络编程的 “最优解”?
环形缓冲区之所以在网络编程中脱颖而出,成为开发者们的首选方案,主要归功于它的三大核心特性。
1)、内存复用能力。
在网络数据的收发过程中,如果使用传统的缓冲区,随着数据量的变化,可能需要频繁地进行内存的分配和释放,这就像频繁地搬家,不仅耗费时间,还容易产生内存碎片。而环形缓冲区的大小是固定的,它通过指针的循环移动来复用内存空间,避免了这种频繁的内存操作,就像住在一个固定的房子里,东西可以循环摆放,既稳定又高效。
2)、环形缓冲区的顺序读写特性非常高效。
网络数据往往是按照顺序依次到达和被处理的,环形缓冲区的这种顺序读写方式,完美契合了 CPU 的缓存机制。CPU 在访问内存时,对于连续的内存区域访问效率更高,环形缓冲区的连续内存结构和顺序读写操作,使得数据能够更快速地被处理,就像在一条通畅的高速公路上行驶,数据传输的速度自然大大提升。
3)、环形缓冲区天然适配流式数据。
在网络编程中,像 TCP 协议传输的数据就是以字节流的形式出现的,数据源源不断地流入和流出。环形缓冲区能够很好地适应这种流式数据的处理,它就像一个源源不断的 “数据管道”,数据可以按照顺序依次流入流出,不会出现数据混乱或丢失的情况,为网络数据的稳定传输和处理提供了有力保障。 这些特性使得环形缓冲区在网络编程中具有无可比拟的优势,也为我们接下来探讨它在实际网络场景中的应用奠定了坚实的基础。
三、环形缓冲区在 Linux 网络编程中的核心应用
3.1 TCP/UDP 数据收发:边收边解析的 “刚需” 场景
TCP 和 UDP 是 Linux 网络编程的两大核心传输协议,而环形缓冲区,正是这两种协议实现高效数据收发的关键支撑。
以常见的网络服务器为例,当客户端通过 TCP 或 UDP 协议向服务器发送数据时,服务器不能傻等数据全部接收完毕后再进行解析处理。因为网络环境复杂多变,数据可能会分批次、分时段到达 ,如果采用传统的缓冲区,在数据未接收完整时就进行解析,很容易出现数据不完整、解析错误的情况;而等待全部数据接收完再处理,又会导致处理延迟,影响用户体验。
环形缓冲区就像是一个智能的 “数据仓库”,完美解决了这个问题。在数据接收过程中,接收线程(生产者)会持续不断地将从 Socket 接收到的数据写入环形缓冲区,就像不断地往仓库里存放货物。与此同时,解析线程(消费者)会根据数据的协议格式,从环形缓冲区中按需读取数据进行解析,就像从仓库中按需取货。这样一来,数据的接收和解析可以同时进行,大大提高了数据处理的效率。
当接收线程接收到一个 TCP 数据包时,它会迅速将数据包写入环形缓冲区,然后继续等待下一个数据包的到来;而解析线程则可以在缓冲区中寻找完整的 TCP 数据段进行解析,即使后续的数据还未到达,也不会影响已接收数据的解析工作。这种边收边解析的模式,不仅能够有效平衡数据收发速度的差异,还能降低用户的等待时间,提升系统的响应性能,让网络通信更加流畅高效。
3.2 流媒体处理:音视频数据的 “流畅保障”
在流媒体播放过程中,音视频数据以数据包的形式通过网络源源不断地传输到客户端。然而,网络状况并非总是一帆风顺,网络抖动、延迟等问题时有发生,这就可能导致音视频数据包的接收速度不稳定。如果没有一个有效的缓冲机制,当网络出现短暂卡顿,数据包接收不及时时,视频播放就会出现卡顿、掉帧甚至中断的情况,严重影响用户的观看体验。
环形缓冲区就像是一个 “数据蓄水池”,为音视频数据的稳定播放提供了保障。当网络状况良好时,接收线程会快速将音视频数据包写入环形缓冲区,缓冲区的水位逐渐上升;而播放线程(消费者)则按照正常的帧率从缓冲区中读取数据进行解码和播放,保证视频的流畅播放。当网络出现短暂波动,数据包接收速度变慢时,播放线程仍然可以从缓冲区中读取数据,因为缓冲区中已经提前存储了一定量的数据,就像蓄水池在水源充足时储存了水,在水源不足时可以继续供水,从而避免了因网络问题导致的播放卡顿 。
环形缓冲区在音视频数据的定界分析和结构化解析方面也具有明显优势。音视频数据通常具有特定的格式和结构,通过环形缓冲区,开发者可以方便地对数据进行按帧、按包的分析和处理,无需担心数据的完整性和连续性问题。这大大减少了开发者在缓冲区管理上的精力消耗,让他们能够将更多的注意力集中在音视频处理的核心逻辑上,进一步提升了流媒体处理的效率和质量。
3.3 多线程 / 进程通信:高效数据交互的 “桥梁”
多线程 Linux 网络程序中,线程间的高效通信的共享数据是重点,而环形缓冲区,恰好能搭建起一座低开销的“数据桥梁”。
想象一下,有一个多线程的网络爬虫程序,其中一个线程负责从网络上抓取网页数据(生产者),另一个线程负责对抓取到的数据进行解析和处理(消费者)。这两个线程之间需要进行高效的数据传递,以确保爬虫程序的顺利运行。如果没有一个合适的通信机制,直接在两个线程之间传递数据,很容易出现数据竞争、同步问题,导致程序崩溃或出现错误的结果。
环形缓冲区作为线程间共享的数据容器,很好地解决了这些问题。生产者线程将抓取到的网页数据写入环形缓冲区,消费者线程从缓冲区中读取数据进行处理。为了保证数据的安全访问,通常会结合互斥锁、条件变量等同步机制,确保在同一时刻只有一个线程能够对缓冲区进行读写操作 。当生产者线程写入数据时,它会先获取互斥锁,防止其他线程同时写入;写入完成后,通过条件变量通知消费者线程有新数据到来。消费者线程在读取数据前,同样先获取互斥锁,读取完成后释放锁。
与传统的管道、队列等线程间通信方案相比,环形缓冲区具有更低的开销。管道和队列在数据传输过程中,往往需要进行多次系统调用,涉及内核态与用户态的切换,这会带来一定的性能损耗。而环形缓冲区位于用户态,数据的读写操作直接在用户态内存中进行,减少了这种切换开销,提高了数据传输的效率,使得多线程网络程序能够更加高效地运行。
四、实战设计:Linux 环境下环形缓冲区的实现步骤
4.1 需求分析
首先,需要提供高效的数据写入和读取接口。在网络数据传输过程中,数据就像湍急的水流,源源不断地涌入。我们希望能够快速地将这些数据写入环形缓冲区,就像把水快速倒入蓄水池一样,并且在需要读取数据时,也能高效地获取,满足不同业务对数据处理的及时性要求。
在某些情况下,应用程序可能对某段数据不感兴趣,此时就需要环形缓冲区支持忽略指定长度的数据。例如,在处理网络协议包时,可能会有一些冗余的头部信息或者错误的数据段,我们希望能够直接跳过这些部分,而不是进行无效的数据拷贝和处理,从而节省宝贵的时间和系统资源。
为了方便解析程序处理数据,我们还需要封装常见的整形数据读取接口,使解析程序可以直接读取 1 - 4 字节的整形数据。在网络通信中,很多关键信息,如数据长度、数据包编号等,常常以整形数据的形式出现。通过封装这些读取接口,能够让解析工作更加便捷高效,就像为数据解析工作配备了一套专业的工具。
考虑到 Linux 系统的内存管理机制,环形缓冲区的内存空间最好是系统页面大小的整数倍。这样可以充分利用系统的内存映射机制,提高内存的使用效率,减少内存碎片的产生,就像把物品整齐地摆放在合适大小的货架上,充分利用每一寸空间。
4.2 数据结构设计
基于 POSIX 标准,我们为 Linux 网络编程场景定制了环形缓冲区结构体,兼顾性能与实用性,结构定义如下:
// 定义环形缓冲区结构体typedef struct ring_buffer { void *memory; // 指向内存的指针,内存大小为size的2倍,且为系统页面大小的整数倍 size_t offset_r; // 读偏移量 size_t offset_w; // 写偏移量 size_t size; // 缓冲区大小,实际可用大小为size,总内存为2*size} ring_buffer_t;
在这个结构体中,memory指针指向一段连续的内存空间,这段内存的大小为size的 2 倍,并且是系统页面大小的整数倍。这样的设计是为了更好地利用 Linux 系统的内存映射机制,提高内存访问效率。例如,在进行内存映射时,如果内存大小与系统页面大小对齐,就可以减少内存分页带来的开销,就像火车在平整的轨道上行驶,更加顺畅高效。
offset_r和offset_w分别表示读偏移量和写偏移量,它们记录了当前读取和写入数据在缓冲区中的位置。通过这两个偏移量,我们可以轻松地实现数据的读写操作,就像在一条环形跑道上,通过记录运动员的位置来确定他们的跑步进度。
size表示缓冲区的实际大小,虽然分配的内存是2*size,但实际可用的缓冲区大小为size。这种设计巧妙地利用了内存空间,在数据回绕时,无需复杂的边界判断和数据搬移操作,大大简化了代码逻辑,提高了数据处理的效率。
4.3 核心接口实现:从创建到销毁的完整链路
4.3.1 缓冲区创建:mmap 双映射的 “精妙操作”
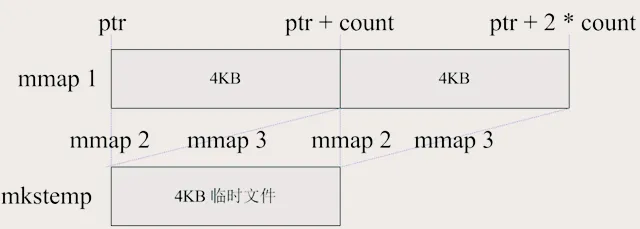
// 创建环形缓冲区ring_buffer_t* ring_buffer_create(size_t size){ // 创建临时文件 int fd = mkstemp("/tmp/ring-buffer-XXXXXX"); if (fd < 0) { perror("mkstemp"); return NULL; } // 修改文件大小为size if (ftruncate(fd, size) != 0) { perror("ftruncate"); close(fd); return NULL; } // 创建环形缓冲区结构体 ring_buffer_t* ring_buffer = (ring_buffer_t*)malloc(sizeof(ring_buffer_t)); if (ring_buffer == NULL) { perror("malloc"); close(fd); return NULL; } // 分配2倍大小的匿名内存 ring_buffer->memory = mmap(NULL, size * 2, PROT_NONE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0); if (ring_buffer->memory == MAP_FAILED) { perror("mmap"); free(ring_buffer); close(fd); return NULL; } // 进行两次映射 void *address1 = mmap(ring_buffer->memory, size, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_SHARED, fd, 0); if (address1 != ring_buffer->memory) { perror("mmap address1"); free(ring_buffer); close(fd); return NULL; } void *address2 = mmap((char*)ring_buffer->memory + size, size, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_SHARED, fd, 0); if (address2 != (char*)ring_buffer->memory + size) { perror("mmap address2"); free(ring_buffer); close(fd); return NULL; } // 删除临时文件的目录入口 if (unlink("/tmp/ring-buffer-XXXXXX") != 0) { perror("unlink"); free(ring_buffer); close(fd); return NULL; } // 初始化偏移量 ring_buffer->offset_r = 0; ring_buffer->offset_w = 0; ring_buffer->size = size; return ring_buffer;}
首先,通过mkstemp函数创建一个临时文件,这个临时文件就像是搭建房屋时的临时脚手架,为后续的内存映射提供了基础。然后,使用ftruncate函数将文件大小调整为指定的size,就像按照设计图纸裁剪布料一样。
接着,为环形缓冲区结构体分配内存,并通过mmap函数进行两次关键的映射操作。第一次映射将ring_buffer->memory的起始位置映射到临时文件,第二次映射则将ring_buffer->memory + size的位置也映射到临时文件。这两次映射就像是在同一块土地上搭建了两座相互关联的房子,使得我们在访问ring_buffer->memory和ring_buffer->memory + size时,实际上访问的是同一块物理内存。这样的设计避免了数据回绕时复杂的边界判断,大大简化了读写操作的实现。
最后,删除临时文件的目录入口,虽然文件的目录项被删除,但由于内存映射的存在,我们仍然可以通过映射的内存区域访问到文件的内容。这种操作就像是拆除了临时脚手架,但房子依然稳固,既节省了系统资源,又不影响环形缓冲区的正常使用。
4.3.2 读写核心接口:push 与 read 的高效实现
// 写入数据到环形缓冲区size_tring_buffer_push(ring_buffer_t* ring_buffer, constvoid* data, size_t len){ size_t available = ring_buffer_available(ring_buffer); if (len > available) { len = available; } size_t part1 = ring_buffer->size - ring_buffer->offset_w; if (len <= part1) { // 数据可以一次性写入 memcpy((char*)ring_buffer->memory + ring_buffer->offset_w, data, len); ring_buffer->offset_w = (ring_buffer->offset_w + len) % ring_buffer->size; } else { // 数据需要分两次写入 memcpy((char*)ring_buffer->memory + ring_buffer->offset_w, data, part1); memcpy(ring_buffer->memory, (char*)data + part1, len - part1); ring_buffer->offset_w = len - part1; } return len;}// 从环形缓冲区读取数据size_tring_buffer_read(ring_buffer_t* ring_buffer, void* data, size_t len){ size_t used = ring_buffer_used(ring_buffer); if (len > used) { len = used; } if (data == NULL) { // 直接忽略数据 ring_buffer->offset_r = (ring_buffer->offset_r + len) % ring_buffer->size; return len; } size_t part1 = ring_buffer->size - ring_buffer->offset_r; if (len <= part1) { // 数据可以一次性读取 memcpy(data, (char*)ring_buffer->memory + ring_buffer->offset_r, len); ring_buffer->offset_r = (ring_buffer->offset_r + len) % ring_buffer->size; } else { // 数据需要分两次读取 memcpy(data, (char*)ring_buffer->memory + ring_buffer->offset_r, part1); memcpy((char*)data + part1, ring_buffer->memory, len - part1); ring_buffer->offset_r = len - part1; } return len;}// 封装读取1字节数据的接口uint8_tring_buffer_read_u8(ring_buffer_t* ring_buffer){ uint8_t data; ring_buffer_read(ring_buffer, &data, 1); return data;}// 封装读取2字节数据的接口uint16_tring_buffer_read_u16(ring_buffer_t* ring_buffer){ uint16_t data; ring_buffer_read(ring_buffer, &data, 2); return ntohs(data);}// 封装读取4字节数据的接口uint32_tring_buffer_read_u32(ring_buffer_t* ring_buffer){ uint32_t data; ring_buffer_read(ring_buffer, &data, 4); return ntohl(data);}
数据的写入与读取是环形缓冲区的核心功能,ring_buffer_push和ring_buffer_read两个函数,就负责高效完成这两个操作。
ring_buffer_read函数则实现了从环形缓冲区读取数据的功能。它同样会先计算缓冲区中已使用的空间,以确定可以读取的数据量。这个函数有一个非常灵活的特性,当data参数为NULL时,它并不会进行数据拷贝,而是直接忽略指定长度的数据,将读偏移量向前移动相应的位置,这在我们需要跳过某些不感兴趣的数据时非常实用,就像在阅读一本书时,可以直接跳过某些章节,快速找到自己需要的内容。当data参数不为NULL时,它会根据读偏移量和缓冲区剩余空间的情况,进行数据的读取操作,与写入操作类似,也会处理数据需要分两次读取的情况。
基于ring_buffer_read函数,我们还封装了ring_buffer_read_u8、ring_buffer_read_u16和ring_buffer_read_u32等接口,用于方便地读取 1 - 4 字节的整形数据。这些接口在处理网络协议数据时非常常用,例如在解析 TCP/IP 协议包时,经常需要读取各种长度的整形字段,这些封装好的接口使得数据读取工作变得更加简单高效。
4.3.3 辅助接口:判空、清空与空间计算
// 判断环形缓冲区是否为空intring_buffer_empty(ring_buffer_t* ring_buffer){ return ring_buffer->offset_r == ring_buffer->offset_w;}// 重置环形缓冲区voidring_buffer_reset(ring_buffer_t* ring_buffer){ ring_buffer->offset_r = 0; ring_buffer->offset_w = 0;}// 计算环形缓冲区已使用的空间size_tring_buffer_used(ring_buffer_t* ring_buffer){ return (ring_buffer->offset_w >= ring_buffer->offset_r) ? ring_buffer->offset_w - ring_buffer->offset_r : ring_buffer->size - (ring_buffer->offset_r - ring_buffer->offset_w);}// 计算环形缓冲区的可用空间size_tring_buffer_available(ring_buffer_t* ring_buffer){ return ring_buffer->size - ring_buffer_used(ring_buffer);}
除了核心的读写接口,我们还需要一套辅助接口,帮我们快速掌控环形缓冲区的状态,简化业务层的逻辑处理。
ring_buffer_reset函数则用于重置环形缓冲区,将读偏移量和写偏移量都设置为 0,这就像是将一个装满东西的容器倒空,准备重新开始存储数据。
ring_buffer_used函数计算缓冲区中已使用的空间大小。它通过比较读偏移量和写偏移量的大小,根据不同情况进行计算。如果写偏移量大于等于读偏移量,说明数据没有回绕,已使用空间就是写偏移量减去读偏移量;如果写偏移量小于读偏移量,说明数据发生了回绕,已使用空间就是缓冲区大小减去读偏移量与写偏移量的差值,就像计算环形跑道上运动员跑过的路程,要考虑到是否跑了整圈。
ring_buffer_available函数用于计算缓冲区的可用空间,它通过用缓冲区的总大小减去已使用空间来得到,就像计算一个容器还能容纳多少物品,用容器的总容量减去已存放物品的体积即可。这些辅助接口为业务层提供了重要的状态判断和缓冲区管理能力,使得我们能够更好地掌控环形缓冲区的使用情况 。
五、C 语言 Linux 优化版
为了让大家更直观地感受环形缓冲区的工作原理,下面是 C 语言实现的环形缓冲区的头文件声明和部分关键函数的代码片段,清晰地展现了环形缓冲区的核心逻辑:
// ring_buffer.h#ifndef RING_BUFFER_H#define RING_BUFFER_H#include<stdint.h>// 定义环形缓冲区结构体typedef struct ring_buffer { void *memory; // 指向内存的指针,内存大小为size的2倍,且为系统页面大小的整数倍 size_t offset_r; // 读偏移量 size_t offset_w; // 写偏移量 size_t size; // 缓冲区大小,实际可用大小为size,总内存为2*size} ring_buffer_t;// 创建环形缓冲区ring_buffer_t* ring_buffer_create(size_t size);// 写入数据到环形缓冲区size_tring_buffer_push(ring_buffer_t* ring_buffer, constvoid* data, size_t len);// 从环形缓冲区读取数据size_tring_buffer_read(ring_buffer_t* ring_buffer, void* data, size_t len);// 封装读取1字节数据的接口uint8_tring_buffer_read_u8(ring_buffer_t* ring_buffer);// 封装读取2字节数据的接口uint16_tring_buffer_read_u16(ring_buffer_t* ring_buffer);// 封装读取4字节数据的接口uint32_tring_buffer_read_u32(ring_buffer_t* ring_buffer);// 判断环形缓冲区是否为空intring_buffer_empty(ring_buffer_t* ring_buffer);// 重置环形缓冲区voidring_buffer_reset(ring_buffer_t* ring_buffer);// 计算环形缓冲区已使用的空间size_tring_buffer_used(ring_buffer_t* ring_buffer);// 计算环形缓冲区的可用空间size_tring_buffer_available(ring_buffer_t* ring_buffer);#endif// RING_BUFFER_H// ring_buffer.c#include<stdio.h>#include<stdlib.h>#include<string.h>#include<sys/mman.h>#include<sys/types.h>#include<sys/stat.h>#include<fcntl.h>#include<unistd.h>#include"ring_buffer.h"// 创建环形缓冲区ring_buffer_t* ring_buffer_create(size_t size){ // 创建临时文件 int fd = mkstemp("/tmp/ring-buffer-XXXXXX"); if (fd < 0) { perror("mkstemp"); return NULL; } // 修改文件大小为size if (ftruncate(fd, size) != 0) { perror("ftruncate"); close(fd); return NULL; } // 创建环形缓冲区结构体 ring_buffer_t* ring_buffer = (ring_buffer_t*)malloc(sizeof(ring_buffer_t)); if (ring_buffer == NULL) { perror("malloc"); close(fd); return NULL; } // 分配2倍大小的匿名内存 ring_buffer->memory = mmap(NULL, size * 2, PROT_NONE, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0); if (ring_buffer->memory == MAP_FAILED) { perror("mmap"); free(ring_buffer); close(fd); return NULL; } // 进行两次映射 void *address1 = mmap(ring_buffer->memory, size, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_SHARED, fd, 0); if (address1 != ring_buffer->memory) { perror("mmap address1"); free(ring_buffer); close(fd); return NULL; } void *address2 = mmap((char*)ring_buffer->memory + size, size, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_SHARED, fd, 0); if (address2 != (char*)ring_buffer->memory + size) { perror("mmap address2"); free(ring_buffer); close(fd); return NULL; } // 删除临时文件的目录入口 if (unlink("/tmp/ring-buffer-XXXXXX") != 0) { perror("unlink"); free(ring_buffer); close(fd); return NULL; } // 初始化偏移量 ring_buffer->offset_r = 0; ring_buffer->offset_w = 0; ring_buffer->size = size; return ring_buffer;}// 写入数据到环形缓冲区size_tring_buffer_push(ring_buffer_t* ring_buffer, constvoid* data, size_t len){ size_t available = ring_buffer_available(ring_buffer); if (len > available) { len = available; } size_t part1 = ring_buffer->size - ring_buffer->offset_w; if (len <= part1) { // 数据可以一次性写入 memcpy((char*)ring_buffer->memory + ring_buffer->offset_w, data, len); ring_buffer->offset_w = (ring_buffer->offset_w + len) % ring_buffer->size; } else { // 数据需要分两次写入 memcpy((char*)ring_buffer->memory + ring_buffer->offset_w, data, part1); memcpy(ring_buffer->memory, (char*)data + part1, len - part1); ring_buffer->offset_w = len - part1; } return len;}// 从环形缓冲区读取数据size_tring_buffer_read(ring_buffer_t* ring_buffer, void* data, size_t len){ size_t used = ring_buffer_used(ring_buffer); if (len > used) { len = used; } if (data == NULL) { // 直接忽略数据 ring_buffer->offset_r = (ring_buffer->offset_r + len) % ring_buffer->size; return len; } size_t part1 = ring_buffer->size - ring_buffer->offset_r; if (len <= part1) { // 数据可以一次性读取 memcpy(data, (char*)ring_buffer->memory + ring_buffer->offset_r, len); ring_buffer->offset_r = (ring_buffer->offset_r + len) % ring_buffer->size; } else { // 数据需要分两次读取 memcpy(data, (char*)ring_buffer->memory + ring_buffer->offset_r, part1); memcpy((char*)data + part1, ring_buffer->memory, len - part1); ring_buffer->offset_r = len - part1; } return len;}// 封装读取1字节数据的接口uint8_tring_buffer_read_u8(ring_buffer_t* ring_buffer){ uint8_t data; ring_buffer_read(ring_buffer, &data, 1); return data;}// 封装读取2字节数据的接口uint16_tring_buffer_read_u16(ring_buffer_t* ring_buffer){ uint16_t data; ring_buffer_read(ring_buffer, &data, 2); return ntohs(data);}// 封装读取4字节数据的接口uint32_tring_buffer_read_u32(ring_buffer_t* ring_buffer){ uint32_t data; ring_buffer_read(ring_buffer, &data, 4); return ntohl(data);}// 判断环形缓冲区是否为空intring_buffer_empty(ring_buffer_t* ring_buffer){ return ring_buffer->offset_r == ring_buffer->offset_w;}// 重置环形缓冲区voidring_buffer_reset(ring_buffer_t* ring_buffer){ ring_buffer->offset_r = 0; ring_buffer->offset_w = 0;}// 计算环形缓冲区已使用的空间size_tring_buffer_used(ring_buffer_t* ring_buffer){ return (ring_buffer->offset_w >= ring_buffer->offset_r) ? ring_buffer->offset_w - ring_buffer->offset_r : ring_buffer->size - (ring_buffer->offset_r - ring_buffer->offset_w);}// 计算环形缓冲区的可用空间size_tring_buffer_available(ring_buffer_t* ring_buffer){ return ring_buffer->size - ring_buffer_used(ring_buffer);}
这个 C 语言版本的环形缓冲区通过精心设计的数据结构和高效的内存管理,以及专门为网络数据解析定制的接口,能够很好地满足 Linux 网络编程中对高性能和稳定性的要求,为实际的网络应用开发提供了强大的支持。
六、Linux 网络编程的进阶技巧
6.1 线程安全:多线程读写的同步策略
当多个线程同时对环形缓冲区进行读写操作时,如果没有合适的同步机制,很容易出现数据竞争问题,导致读写指针错乱,数据丢失或损坏。
为了确保线程安全,最常用的方法是使用互斥锁(Mutex)。
#include<pthread.h>// 定义环形缓冲区结构体typedef struct ring_buffer { void *memory; size_t offset_r; size_t offset_w; size_t size; pthread_mutex_t mutex; // 添加互斥锁} ring_buffer_t;// 创建环形缓冲区ring_buffer_t* ring_buffer_create(size_t size){ // 省略其他代码 pthread_mutex_init(&ring_buffer->mutex, NULL); // 初始化互斥锁 return ring_buffer;}// 写入数据到环形缓冲区size_tring_buffer_push(ring_buffer_t* ring_buffer, constvoid* data, size_t len){ pthread_mutex_lock(&ring_buffer->mutex); // 加锁 // 写入数据逻辑 pthread_mutex_unlock(&ring_buffer->mutex); // 解锁 return len;}// 从环形缓冲区读取数据size_tring_buffer_read(ring_buffer_t* ring_buffer, void* data, size_t len){ pthread_mutex_lock(&ring_buffer->mutex); // 加锁 // 读取数据逻辑 pthread_mutex_unlock(&ring_buffer->mutex); // 解锁 return len;}
除了互斥锁,还可以采用无锁设计,利用原子操作来实现线程安全。在 C++ 中,可以使用<atomic>库提供的原子类型和操作,如std::atomic<int>。原子操作能够保证在多线程环境下,对变量的读写操作是原子的,不会被其他线程打断,从而避免数据竞争问题。不过,无锁设计的实现相对复杂,需要对原子操作有深入的理解和运用能力。
6.2 内存优化:减少拷贝的 “黑科技”
在 Linux 网络编程中,内存拷贝是一个常见且开销较大的操作,特别是在数据量较大时,频繁的内存拷贝会严重影响程序的性能。为了减少内存拷贝的开销,我们可以利用 Linux 的内存映射(Memory - mapped I/O)机制。
内存映射允许将文件直接映射到进程的虚拟地址空间,使得进程可以像访问内存一样访问文件,而无需进行传统的read和write系统调用带来的数据拷贝操作。在环形缓冲区的实现中,通过mmap函数将文件映射到内存,不仅实现了内存的高效利用,还减少了数据在用户态和内核态之间的拷贝次数。
以我们之前的 C 语言实现为例,ring_buffer_create函数中使用mmap进行两次映射,将文件内容映射到ring_buffer->memory和ring_buffer->memory + size两个位置,这使得在读写数据时,直接操作内存即可,避免了传统文件 I/O 方式下的数据拷贝。
在某些情况下,我们还可以利用ring_buffer_read函数中data参数支持为NULL的特性,直接跳过无效数据,而不需要进行数据拷贝。当我们确定某些数据不需要处理时,直接将data设为NULL,调用ring_buffer_read函数,它会直接移动读指针,跳过这些数据,大大提升了数据解析的效率。
6.3 溢出处理:覆盖还是阻塞?
当环形缓冲区满时,我们需要考虑如何处理新到来的数据,这通常有两种策略:覆盖旧数据和阻塞等待。
覆盖旧数据策略适用于一些对数据实时性要求较高,但对少量数据丢失不太敏感的场景,如流媒体播放。在这种场景下,新的数据不断产生,而缓冲区的大小是有限的,如果缓冲区已满,为了保证新数据的及时处理,可以直接覆盖最早写入的、还未被读取的数据。在我们的 Python 实现中,enqueue方法中当缓冲区满时,直接更新tail指针,覆盖旧数据:
def enqueue(self, item): with self.lock: if self.count == self.size: print("Buffer is full, overwriting the oldest data.") self.tail = (self.tail + 1) % self.size else: self.count += 1 self.buffer[self.head] = item self.head = (self.head + 1) % self.size
阻塞等待策略则适用于关键数据传输场景,如金融交易数据的传输。在这些场景中,数据的完整性和准确性至关重要,不允许数据丢失。当缓冲区满时,新数据的写入操作会被阻塞,直到有数据被读取,缓冲区有足够的空间。在 C 语言实现中,可以通过条件变量(pthread_cond_t)来实现阻塞等待机制:
#include<pthread.h>// 定义环形缓冲区结构体typedef struct ring_buffer { void *memory; size_t offset_r; size_t offset_w; size_t size; pthread_mutex_t mutex; pthread_cond_t cond; // 添加条件变量} ring_buffer_t;// 创建环形缓冲区ring_buffer_t* ring_buffer_create(size_t size){ // 省略其他代码 pthread_mutex_init(&ring_buffer->mutex, NULL); pthread_cond_init(&ring_buffer->cond, NULL); // 初始化条件变量 return ring_buffer;}// 写入数据到环形缓冲区size_tring_buffer_push(ring_buffer_t* ring_buffer, constvoid* data, size_t len){ pthread_mutex_lock(&ring_buffer->mutex); while (ring_buffer_available(ring_buffer) < len) { pthread_cond_wait(&ring_buffer->cond, &ring_buffer->mutex); // 等待缓冲区有足够空间 } // 写入数据逻辑 pthread_cond_signal(&ring_buffer->cond); // 通知其他线程缓冲区有数据可读 pthread_mutex_unlock(&ring_buffer->mutex); return len;}