kvm_arm_init的初始化过程如下:
static __initintkvm_arm_init(void){ int err; bool in_hyp_mode; // 1. 检查硬件虚拟化支持 if (!is_hyp_mode_available()) { kvm_info("HYP mode not available\n"); return -ENODEV; } // 2. 检查KVM是否被禁用 if (kvm_get_mode() == KVM_MODE_NONE) { kvm_info("KVM disabled from command line\n"); return -ENODEV; } // 3. 初始化系统寄存器表 err = kvm_sys_reg_table_init(); in_hyp_mode = is_kernel_in_hyp_mode(); // 4. 设置IPA(中间物理地址)大小限制 err = kvm_set_ipa_limit(); // 5. 初始化SVE支持 err = kvm_arm_init_sve(); // 6. 初始化VMID分配器 err = kvm_arm_vmid_alloc_init(); // 7. 初始化Hypervisor模式(非VHE模式) if (!in_hyp_mode) { err = init_hyp_mode(); if (err) goto out_err; } // 8. 初始化向量槽(用于Spectre缓解) err = kvm_init_vector_slots(); // 9. 初始化子系统(VGIC, timer等) err = init_subsystems(); // 10. 注册到通用KVM框架 err = kvm_init(sizeof(struct kvm_vcpu), 0, THIS_MODULE); // 11. 完成Hypervisor初始化 if (!in_hyp_mode) finalize_init_hyp_mode(); kvm_arm_initialised = true; return 0;}
首先会调用is_hyp_mode_available,检查硬件虚拟化支持:
/* Reports the availability of HYP mode */staticinlineboolis_hyp_mode_available(void){ /* * If KVM protected mode is initialized, all CPUs must have been booted * in EL2. Avoid checking __boot_cpu_mode as CPUs now come up in EL1. */ if (is_pkvm_initialized()) return true; return (__boot_cpu_mode[0] == BOOT_CPU_MODE_EL2 && __boot_cpu_mode[1] == BOOT_CPU_MODE_EL2);}
__boot_cpu_mode在刚刚进入Linux的汇编代码/arch/arm64/kernel/head.S设置:
SYM_FUNC_START(init_kernel_el) mrs x1, CurrentEL cmp x1, #CurrentEL_EL2 b.eq init_el2 ........./* * Sets the __boot_cpu_mode flag depending on the CPU boot mode passed * in w0. See arch/arm64/include/asm/virt.h for more info. */SYM_FUNC_START_LOCAL(set_cpu_boot_mode_flag) adr_l x1, __boot_cpu_mode cmp w0, #BOOT_CPU_MODE_EL2 b.ne 1fadd x1, x1, #41: str w0, [x1] // Save CPU boot moderetSYM_FUNC_END(set_cpu_boot_mode_flag)
为什么要判断 "Booted in EL2"? ARM 架构规定:如果你想运行KVM,Linux 内核必须在启动时就已经处于EL2模式。简单说下VHE。VHE (Virtualization Host Extensions) 是 ARMv8.1 架构引入的特性。它的核心目的是:让Type-2 型Hypervisor(如 Linux KVM)能够以近乎原生的性能运行。在没有 VHE 之前,Linux 内核必须运行在 EL1,而 KVM 的核心控制逻辑必须运行在 EL2。这种“跨级办公”导致了巨大的上下文切换开销。
只有启动的时候Linux在EL2才可能开启KVM支持,主要是因为虚拟化需要EL2的例程的支持,但是Linux Kernel是运行在EL1的,那么这里意味着:
/arch/arm64/kernel/head.S:
/* Hypervisor stub */adr_l x0, __hyp_stub_vectorsmsr vbar_el2, x0isb
Hyp Stub定义在/arch/arm64/kernel/hyp-stub.S,主要是HVC调用elx_sync:
SYM_CODE_START(__hyp_stub_vectors) ventry el2_sync_invalid // Synchronous EL2t ventry el2_irq_invalid // IRQ EL2t ventry el2_fiq_invalid // FIQ EL2t ventry el2_error_invalid // Error EL2t ventry elx_sync // Synchronous EL2h ventry el2_irq_invalid // IRQ EL2h ventry el2_fiq_invalid // FIQ EL2h ventry el2_error_invalid // Error EL2h ventry elx_sync // Synchronous 64-bit EL1 ventry el1_irq_invalid // IRQ 64-bit EL1 ventry el1_fiq_invalid // FIQ 64-bit EL1 ventry el1_error_invalid // Error 64-bit EL1 ventry el1_sync_invalid // Synchronous 32-bit EL1 ventry el1_irq_invalid // IRQ 32-bit EL1 ventry el1_fiq_invalid // FIQ 32-bit EL1 ventry el1_error_invalid // Error 32-bit EL1SYM_CODE_END(__hyp_stub_vectors)
接着,kvm_arm_init会判断kvm_mode是否被设置成了NONE。kvm_mode可以在Linux内核启动的命令行参数设置:staticint __init early_kvm_mode_cfg(char *arg){ if (!arg) return -EINVAL; if (strcmp(arg, "none") == 0) { kvm_mode = KVM_MODE_NONE; return 0; } if (!is_hyp_mode_available()) { pr_warn_once("KVM is not available. Ignoring kvm-arm.mode\n"); return 0; } if (strcmp(arg, "protected") == 0) { if (!is_kernel_in_hyp_mode()) kvm_mode = KVM_MODE_PROTECTED; else pr_warn_once("Protected KVM not available with VHE\n"); return 0; } if (strcmp(arg, "nvhe") == 0 && !WARN_ON(is_kernel_in_hyp_mode())) { kvm_mode = KVM_MODE_DEFAULT; return 0; } if (strcmp(arg, "nested") == 0 && !WARN_ON(!is_kernel_in_hyp_mode())) { kvm_mode = KVM_MODE_NV; return 0; } return -EINVAL;}early_param("kvm-arm.mode", early_kvm_mode_cfg);
| 模式 | 描述 | 运行级别 | 核心语义 |
KVM_MODE_DEFAULT | VHE | Linux Kernel @ EL2 | 高性能模式。内核直接跑在EL2,Host 和Guest 切换开销极小。ARMv8.1+ 标配。 |
| Non-VHE | Linux Kernel @ EL1 | 传统模式。内核跑在 EL1,通过 Hyp-stub 与 EL2 交互。适用于较旧的 ARMv8.0 硬件。 |
| Protected | pKVM (Protected KVM) | Linux Kernel@ EL1 / Hyp @ EL2 | Google 为Android 设计的安全加强模式。EL2 变成了一个“安全代理”,即使Host内核(Linux)被攻破,也无法访问Guest虚拟机的内存。 |
| Nested | Nested Virtualization | Guest @ EL1/EL2 | 嵌套虚拟化。允许在虚拟机里再跑一个虚拟机(在 VM 里跑 KVM)。需要硬件支持 ARMv8.3+。 |
接下来调用kvm_sys_reg_table_init。ARM处理器的寄存器排序成列表的形式,虚拟机访问的时候,会Trap到Linux Kernel,进行处理。kvm_sys_reg_table_init检查列表是否按照一定顺序:int __initkvm_sys_reg_table_init(void){ const struct sys_reg_desc *gicv3_regs; bool valid = true; unsigned int i, sz; int ret = 0; /* ========== 步骤1: 验证所有系统寄存器表 ========== */ // 验证主系统寄存器表(需要reset检查) valid &= check_sysreg_table(sys_reg_descs, ARRAY_SIZE(sys_reg_descs), true); // 验证CP14协处理器寄存器表(用于AArch32兼容) valid &= check_sysreg_table(cp14_regs, ARRAY_SIZE(cp14_regs), false); // 验证CP14 64位寄存器表 valid &= check_sysreg_table(cp14_64_regs, ARRAY_SIZE(cp14_64_regs), false); // 验证CP15协处理器寄存器表 valid &= check_sysreg_table(cp15_regs, ARRAY_SIZE(cp15_regs), false); // 验证CP15 64位寄存器表 valid &= check_sysreg_table(cp15_64_regs, ARRAY_SIZE(cp15_64_regs), false); // 验证系统指令描述符表 valid &= check_sysreg_table(sys_insn_descs, ARRAY_SIZE(sys_insn_descs), false); // 获取并验证GICv3系统寄存器表 gicv3_regs = vgic_v3_get_sysreg_table(&sz); valid &= check_sysreg_table(gicv3_regs, sz, false); // 如果任何表验证失败,返回错误 if (!valid) return -EINVAL; /* ========== 步骤2: 初始化实现相关ID寄存器 ========== */ init_imp_id_regs(); /* ========== 步骤3: 配置嵌套虚拟化陷入 ========== */ ret = populate_nv_trap_config(); /* ========== 步骤4: 检查特性映射完整性 ========== */ check_feature_map(); /* ========== 步骤5: 为系统寄存器填充配置 ========== */ // 填充主系统寄存器表的配置 for (i = 0; !ret && i < ARRAY_SIZE(sys_reg_descs); i++) ret = populate_sysreg_config(sys_reg_descs + i, i); // 填充系统指令表的配置 for (i = 0; !ret && i < ARRAY_SIZE(sys_insn_descs); i++) ret = populate_sysreg_config(sys_insn_descs + i, i); return ret;}
其中sys_reg_descs列表示例如下,是个大数组:static const struct sys_reg_desc sys_reg_descs[] = { // 1. 调试寄存器 (DBGBCR, DBGBVR, DBGWCR, DBGWVR) DBG_BCR_BVR_WCR_WVR_EL1(0), DBG_BCR_BVR_WCR_WVR_EL1(1), // ... 共16组 // 2. 调试控制寄存器 { SYS_DESC(SYS_MDCCINT_EL1), trap_debug_regs, reset_val, ... }, { SYS_DESC(SYS_MDSCR_EL1), trap_debug_regs, reset_val, ... }, // 3. 实现相关ID寄存器 IMPLEMENTATION_ID(MIDR_EL1, GENMASK_ULL(31, 0)), { SYS_DESC(SYS_MPIDR_EL1), NULL, reset_mpidr, MPIDR_EL1 }, IMPLEMENTATION_ID(REVIDR_EL1, GENMASK_ULL(63, 0)), // 4. AArch32 ID寄存器映射 AA32_ID_WRITABLE(ID_PFR0_EL1), AA32_ID_WRITABLE(ID_PFR1_EL1), // ... // 5. AArch64 ID寄存器 ID_FILTERED(ID_AA64PFR0_EL1, id_aa64pfr0_el1, ~(...)), ID_FILTERED(ID_AA64PFR1_EL1, id_aa64pfr1_el1, ~(...)), // ... // 6. 通用系统控制寄存器 { SYS_DESC(SYS_SCTLR_EL1), access_vm_reg, reset_val, SCTLR_EL1, 0x00C50078 }, { SYS_DESC(SYS_CPACR_EL1), NULL, reset_val, CPACR_EL1, 0 }, { SYS_DESC(SYS_TTBR0_EL1), access_vm_reg, reset_unknown, TTBR0_EL1 }, { SYS_DESC(SYS_TTBR1_EL1), access_vm_reg, reset_unknown, TTBR1_EL1 }, { SYS_DESC(SYS_TCR_EL1), access_vm_reg, reset_val, TCR_EL1, 0 }, // 7. 异常处理寄存器 { SYS_DESC(SYS_ESR_EL1), access_vm_reg, reset_unknown, ESR_EL1 }, { SYS_DESC(SYS_FAR_EL1), access_vm_reg, reset_unknown, FAR_EL1 }, { SYS_DESC(SYS_PAR_EL1), NULL, reset_unknown, PAR_EL1 }, // 8. 内存属性寄存器 { SYS_DESC(SYS_MAIR_EL1), access_vm_reg, reset_unknown, MAIR_EL1 }, { SYS_DESC(SYS_AMAIR_EL1), access_vm_reg, reset_amair_el1, AMAIR_EL1 }, // 9. 上下文ID寄存器 { SYS_DESC(SYS_CONTEXTIDR_EL1), access_vm_reg, reset_val, CONTEXTIDR_EL1, 0 }, { SYS_DESC(SYS_TPIDR_EL1), NULL, reset_unknown, TPIDR_EL1 }, // 10. 性能监控寄存器 { PMU_SYS_REG(PMCR_EL0), .access = access_pmcr, .reset = reset_pmcr, ... }, { PMU_SYS_REG(PMCNTENSET_EL0), .access = access_pmcnten, ... }, // ... // 11. 通用定时器寄存器 { SYS_DESC(SYS_CNTKCTL_EL1), NULL, reset_val, CNTKCTL_EL1, 0}, { SYS_DESC(SYS_CNTP_TVAL_EL0), access_arch_timer }, { SYS_DESC(SYS_CNTP_CTL_EL0), access_arch_timer }, { SYS_DESC(SYS_CNTP_CVAL_EL0), access_arch_timer }, // 12. 虚拟定时器寄存器 { SYS_DESC(SYS_CNTV_TVAL_EL0), access_arch_timer }, { SYS_DESC(SYS_CNTV_CTL_EL0), access_arch_timer }, { SYS_DESC(SYS_CNTV_CVAL_EL0), access_arch_timer }, // 13. 指针认证寄存器 { SYS_DESC(SYS_APIAKEYLO_EL1), NULL, reset_unknown, APIAKEYLO_EL1 }, { SYS_DESC(SYS_APIAKEYHI_EL1), NULL, reset_unknown, APIAKEYHI_EL1 }, // ... // 14. SVE寄存器 { SYS_DESC(SYS_ZCR_EL1), NULL, reset_val, ZCR_EL1, 0, .visibility = sve_visibility }, // 15. MTE寄存器 { SYS_DESC(SYS_TFSRE0_EL1), undef_access }, { SYS_DESC(SYS_TFSR_EL1), undef_access }, { SYS_DESC(SYS_RGSR_EL1), undef_access }, { SYS_DESC(SYS_GCR_EL1), undef_access }, // ... 更多寄存器};
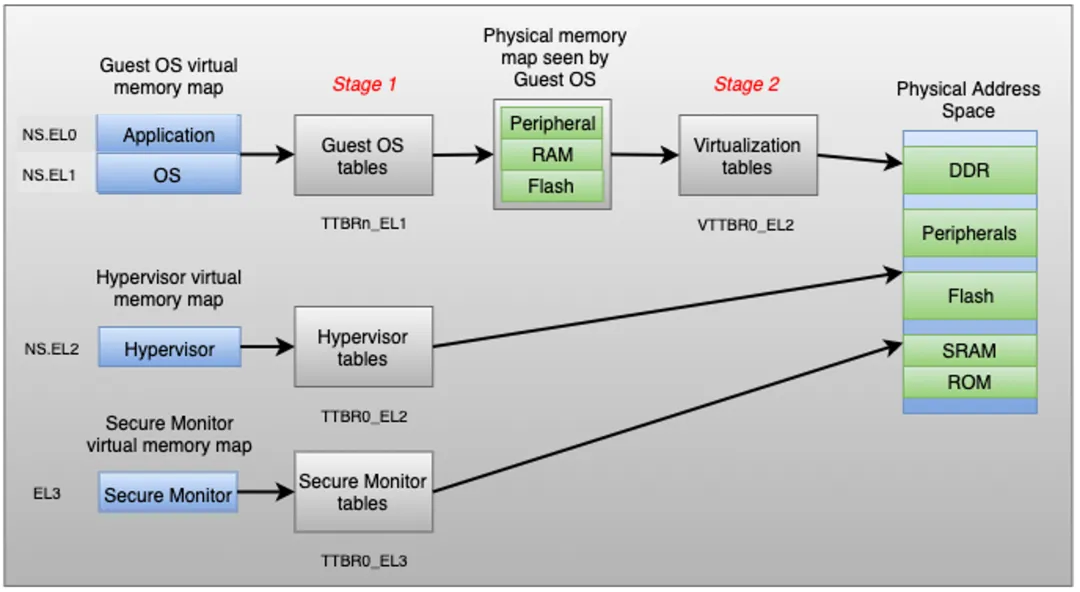
虚拟机里面CPU发出的访问,需要经过两个阶段的转换,第二个阶段GPA(Guest Physical Address或者IPA即Intermediate Physical Address)到HPA(Host Physical Address)的转换,其页表配置由KVM完成:
kvm_set_ipa_limit主要设置Linux在进行第二个阶段转换的时候的限制,要保证从Guest出来的配置比如页面大小与第二个阶段支持的配置相匹配:
int __init kvm_set_ipa_limit(void){ unsigned int parange; u64 mmfr0; /* ========== 步骤1: 读取CPU物理地址范围能力 ========== */ // 读取ID_AA64MMFR0_EL1寄存器 // 这个寄存器描述了ARMv8内存模型特性 mmfr0 = read_sanitised_ftr_reg(SYS_ID_AA64MMFR0_EL1); // 提取PARange字段 (bits [3:0]) // PARange定义了物理地址的范围 parange = cpuid_feature_extract_unsigned_field(mmfr0, ID_AA64MMFR0_EL1_PARANGE_SHIFT); /* ========== 步骤2: 检查LPA2支持并调整PARange ========== */ /* * 对于4K和16K页面大小,超过48位的IPA大小 * 只有在LPA2可用时才支持。 * 如果我们有LPA2,启用它,否则限制到48位, * 即使系统报告支持更大的范围。 */ if (!kvm_lpa2_is_enabled() && PAGE_SIZE != SZ_64K) parange = min(parange, (unsigned int)ID_AA64MMFR0_EL1_PARANGE_48); /* ========== 步骤3: 检查Stage-2页表粒度支持 ========== */ /* * 使用ARMv8.5-GTG检查我们的PAGE_SIZE * 在Stage-2是否被支持。如果不支持,系统将快速停止。 */ switch (cpuid_feature_extract_unsigned_field(mmfr0, ID_AA64MMFR0_EL1_TGRAN_2_SHIFT)) { case ID_AA64MMFR0_EL1_TGRAN_2_SUPPORTED_NONE: // Stage-2不支持当前PAGE_SIZE kvm_err("PAGE_SIZE not supported at Stage-2, giving up\n"); return -EINVAL; case ID_AA64MMFR0_EL1_TGRAN_2_SUPPORTED_DEFAULT: // 使用默认支持 kvm_debug("PAGE_SIZE supported at Stage-2 (default)\n"); break; case ID_AA64MMFR0_EL1_TGRAN_2_SUPPORTED_MIN ... ID_AA64MMFR0_EL1_TGRAN_2_SUPPORTED_MAX: // 明确声明支持 kvm_debug("PAGE_SIZE supported at Stage-2 (advertised)\n"); break; default: // 无效的TGRAN_2值 kvm_err("Unsupported value for TGRAN_2, giving up\n"); return -EINVAL; } /* ========== 步骤4: 计算并设置IPA限制 ========== */ // 将PARange值转换为实际的物理地址位数 kvm_ipa_limit = id_aa64mmfr0_parange_to_phys_shift(parange); // 输出信息 kvm_info("IPA Size Limit: %d bits%s\n", kvm_ipa_limit, ((kvm_ipa_limit < KVM_PHYS_SHIFT) ? " (Reduced IPA size, limited VM/VMM compatibility)" : "")); return 0;}
kvm_arm_init_sve 函数的主要任务是:探测物理CPU的SVE能力,并决定是否允许虚拟机使用SVE。SVE (Scalable Vector Extension)是ARMv8.2-A架构引入的一项扩展。
为什么 KVM 需要特别处理 SVE? 这涉及到上下文切换(Context Switch)的开销:SVE 寄存器(Z0-Z31)非常大,一次上下文切换要保存/恢复的数据量很大。只有当虚拟机真的在用SVE 指令时才去切换这些大寄存器,否则会严重拖慢CPU效率。
kvm_arm_vmid_alloc_init读取系统寄存器ID_AA64MMFR1_EL1,确认硬件支持多少位的VMID。初始化一个位图来记录哪些VMID已经被分配,哪些是空闲的。
staticinlineunsignedintkvm_get_vmid_bits(void){ int reg = read_sanitised_ftr_reg(SYS_ID_AA64MMFR1_EL1); return get_vmid_bits(reg);}/* * Initialize the VMID allocator */int __init kvm_arm_vmid_alloc_init(void){ kvm_arm_vmid_bits = kvm_get_vmid_bits(); /* * Expect allocation after rollover to fail if we don't have * at least one more VMID than CPUs. VMID #0 is always reserved. */ WARN_ON(NUM_USER_VMIDS - 1 <= num_possible_cpus()); atomic64_set(&vmid_generation, VMID_FIRST_VERSION); vmid_map = bitmap_zalloc(NUM_USER_VMIDS, GFP_KERNEL); if (!vmid_map) return -ENOMEM; return 0;}
kvm_arm_init在VHE模式下,Linux内核直接运行在EL2,该函数不会调用。在会VHE模式下,kvm_arm_init负责在EL2安装一个名为"World Switcher"的小程序,专门负责CPU上下文在Host和Guest之间来回切换,这里暂且略过:static __always_inline boolis_kernel_in_hyp_mode(void){ BUILD_BUG_ON(__is_defined(__KVM_NVHE_HYPERVISOR__) || __is_defined(__KVM_VHE_HYPERVISOR__)); return read_sysreg(CurrentEL) == CurrentEL_EL2;}/* Initialize Hyp-mode and memory mappings on all CPUs */static __initintkvm_arm_init(void){ ........... in_hyp_mode = is_kernel_in_hyp_mode(); ........... if (!in_hyp_mode) { err = init_hyp_mode(); if (err) goto out_err; } ...........}
在ARM64架构中,当虚拟机发生异常退出(Trap)时,硬件会跳转到EL2的异常向量表(Exception Vector Table)。传统做法中所有CPU核心共享一个全局的异常向量表地址,这会产生漏洞风险,攻击者可以通过分支目标缓冲区(BTB)污染,预测到Host向量表的跳转地址,从而窃取Host内存数据(即Spectre变体2,幽灵漏洞)。kvm_init_vector_slots的主要职责是为系统中的每个物理CPU分配并初始化专门的向量表插槽(Vector Slots)。
staticintkvm_init_vector_slots(void){ int err; void *base; /* ========== 步骤1: 初始化直接向量槽位 ========== */ // 获取主向量表的Hypervisor虚拟地址 base = kern_hyp_va(kvm_ksym_ref(__kvm_hyp_vector)); // 初始化HYP_VECTOR_DIRECT槽位 // 这是默认的向量表,不需要Spectre缓解 kvm_init_vector_slot(base, HYP_VECTOR_DIRECT); /* ========== 步骤2: 初始化Spectre直接向量槽位 ========== */ // 获取Spectre缓解向量表的Hypervisor虚拟地址 base = kern_hyp_va(kvm_ksym_ref(__bp_harden_hyp_vecs)); // 初始化HYP_VECTOR_SPECTRE_DIRECT槽位 // 使用SMC调用进行分支预测器加固 kvm_init_vector_slot(base, HYP_VECTOR_SPECTRE_DIRECT); /* ========== 步骤3: 创建idmap映射 (条件性) ========== */ /* * 如果系统需要身份映射的向量表,并且不是Protected KVM模式, * 则在idmap页面旁边创建特殊的映射 */ if (kvm_system_needs_idmapped_vectors() && !is_protected_kvm_enabled()) { // 在idmap区域创建可执行映射 err = create_hyp_exec_mappings(__pa_symbol(__bp_harden_hyp_vecs), __BP_HARDEN_HYP_VECS_SZ, &base); if (err) return err; } /* ========== 步骤4: 初始化间接向量槽位 ========== */ // 使用前面获取的base地址(可能是idmap映射) // 初始化HYP_VECTOR_INDIRECT槽位 // 通过idmap区域的特殊映射间接跳转 kvm_init_vector_slot(base, HYP_VECTOR_INDIRECT); // 初始化HYP_VECTOR_SPECTRE_INDIRECT槽位 // 结合idmap间接跳转和SMC Spectre缓解 kvm_init_vector_slot(base, HYP_VECTOR_SPECTRE_INDIRECT); return 0;}
init_subsystems建立Host与虚拟化硬件之间的通信协议。它告诉中断控制器(GIC)、定时器(Timer)等:“我要开始搞虚拟化了,请把你们的虚拟化支持接口准备好。”ARM64的定时器分配如下:
物理定时器 (Physical Timer):├── EL1 Physical Timer (CNTP)│ └── 宿主机和Guest都可使用│└── EL2 Physical Timer (CNTHP) └── 仅Hypervisor使用虚拟定时器 (Virtual Timer):├── EL1 Virtual Timer (CNTV)│ └── Guest使用,可以被trap│└── EL2 Virtual Timer (CNTHV) └── Nested virtualization使用
static int __initinit_subsystems(void){ int err = 0; /* ========== 步骤1: 在所有CPU上启用Hypervisor ========== */ /* * 启用硬件,以便子系统初始化可以访问EL2。 */ on_each_cpu(cpu_hyp_init, NULL, 1); /* ========== 步骤2: 注册CPU低功耗通知器 ========== */ /* * 注册CPU低功耗通知器 */ hyp_cpu_pm_init(); /* ========== 步骤3: 初始化VGIC的Hypervisor视图 ========== */ /* * 初始化VGIC的HYP视图 */ err = kvm_vgic_hyp_init(); switch (err) { case 0: // 成功初始化VGIC vgic_present = true; break; case -ENODEV: case -ENXIO: /* * 没有VGIC? 没有pKVM。 * * Protected模式假设GICv3存在,所以如果vgic初始化失败, * 就没有必要尝试继续。 */ if (is_protected_kvm_enabled()) goto out; /* * 否则,用户空间可以选择在非协作硬件上 * 为其guest实现GIC。 */ vgic_present = false; err = 0; break; default: // 其他错误,直接退出 goto out; } /* ========== 步骤4: 检查嵌套虚拟化的VGIC要求 ========== */ ......... /* ========== 步骤5: 初始化Hypervisor架构定时器支持 ========== */ /* * 初始化HYP架构定时器支持 */ err = kvm_timer_hyp_init(vgic_present); /* ========== 步骤6: 注册性能监控回调 ========== */ kvm_register_perf_callbacks(NULL); return err;}
kvm_init主要是创建vCPU的slab缓存;初始化通用KVM子系统 (irqfd、async_pf、vfio等);注册 /dev/kvm字符设备。async_pf是异步缺页处理;irqfd机制允许用户空间通过eventfd注入中断,绕过ioctl调用以提高性能,可用于设备直通 (VFIO):
intkvm_init(unsigned vcpu_size, unsigned vcpu_align, structmodule *module){ int r; int cpu; /* ========== 步骤1: 创建vCPU slab缓存 ========== */ /* kmem cache让我们满足fx_save的对齐要求 */ if (!vcpu_align) vcpu_align = __alignof__(struct kvm_vcpu); kvm_vcpu_cache = kmem_cache_create_usercopy("kvm_vcpu", vcpu_size, vcpu_align, SLAB_ACCOUNT, offsetof(struct kvm_vcpu, arch), offsetofend(struct kvm_vcpu, stats_id) - offsetof(struct kvm_vcpu, arch), NULL); /* ========== 步骤2: 为每个CPU分配kick掩码 ========== */ for_each_possible_cpu(cpu) { if (!alloc_cpumask_var_node(&per_cpu(cpu_kick_mask, cpu), GFP_KERNEL, cpu_to_node(cpu))) { r = -ENOMEM; goto err_cpu_kick_mask; } } /* ========== 步骤3: 初始化irqfd子系统 ========== */ r = kvm_irqfd_init(); /* ========== 步骤4: 初始化异步缺页子系统 ========== */ r = kvm_async_pf_init(); /* ========== 步骤5: 设置文件操作所有者 ========== */ kvm_chardev_ops.owner = module; kvm_vm_fops.owner = module; kvm_vcpu_fops.owner = module; kvm_device_fops.owner = module; /* ========== 步骤6: 设置抢占操作 ========== */ kvm_preempt_ops.sched_in = kvm_sched_in; kvm_preempt_ops.sched_out = kvm_sched_out; /* ========== 步骤7: 初始化调试文件系统 ========== */ kvm_init_debug(); /* ========== 步骤8: 初始化VFIO操作 ========== */ r = kvm_vfio_ops_init(); /* ========== 步骤9: 初始化Guest内存文件 ========== */ kvm_gmem_init(module); /* ========== 步骤10: 初始化虚拟化 ========== */ r = kvm_init_virtualization(); /* ========== 步骤11: 注册misc设备 ========== */ /* * 注册_必须_是最后完成的事情,因为这会将/dev/kvm暴露给 * 用户空间,即所有基础设施都必须设置好! */ r = misc_register(&kvm_dev); return 0;}