我们在日常数据分析建模的数据探索分析阶段,面对一个繁杂的数据集,我们往往需要耗费大量时间编写大量的代码来进行数据预览、查看数据的分布情况、统计及相关性分析。这将消耗我们大量精力,以致于我们难以聚焦精力以更高维度去挖掘数据中隐藏的业务逻辑与价值。
今天,我将给大家极力推荐一个能极大解放大家生产力的一个工具 —— ydata-profiling,它能够一键生成专业、全面、交互式的数据分析报告,让我们彻底告别重复劳动,将精力真正聚焦于洞察与决策。
1、ydata-profiling 是什么?
ydata-profiling 对于数据科学家和分析师而言是一个宝贵的工具,因为它能简化探索性数据分析(EDA)、提供全面洞察、提升数据质量,并推广数据科学最佳实践。它具有以下优点:
(1)易于使用:它非常简单易用——你只需要一行代码就可以开始。还需要更多理由来说服你吗?😛
import pandas as pdfrom ydata_profiling import ProfileReport# 加载一个示例数据集,这里以经典的泰坦尼克号数据集为例df = pd.read_csv('data/titanic.csv')# 创建 ProfileReport 对象profile = ProfileReport(df, title='泰坦尼克号乘客数据分析报告')
(2)报告内容全面深刻:生成的报告包含广泛的统计数据和可视化图表,为你提供数据的整体视图。该报告可以以 HTML 文件形式分享,或作为小组件集成到 Jupyter Notebook 中。
(3)数据质量评估:它擅长识别缺失数据、重复条目和异常值。这些洞察对于数据清洗和准备至关重要,能确保分析的可靠性,并有助于及早发现问题。
(4)易于与其他流程集成:数据质量分析的所有指标都可以通过标准的 JSON 格式进行调用。
(5)支持大规模数据集探索:即使面对行数庞大的数据集,ydata-profiling 也能为你提供帮助,因为它同时支持 Pandas 数据框和 Spark 数据框。
2、快速安装与基本使用
我们可以通过使用 pip 快速安装 ydata-profiling,如果你在安装过程遇到下载比较慢的问题,还可以使用清华源进行下载,如下所示
pip install ydata-profiling -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后,我们就可以非常快速使用 ydata-profiling,使用非常简洁,只要直接将 pandas DataFrame 对象传递给 ProfileReport 这个类,然后就可快速生成报告。如下所示
# 导入必要的库import pandas as pdfrom ydata_profiling import ProfileReport# 加载一个示例数据集,这里以经典的泰坦尼克号数据集为例df = pd.read_csv('data/titanic.csv')# 创建 ProfileReport 对象profile = ProfileReport(df, title='泰坦尼克号乘客数据分析报告')# 将报告生成为 HTML 文件profile.to_file('titanic_report.html')
运行以上代码,ydata-profiling 会快速生成报告。报告结构清晰,通常包含概览、变量分析、交互变量关系、相关性和缺失值等几个核心部分。
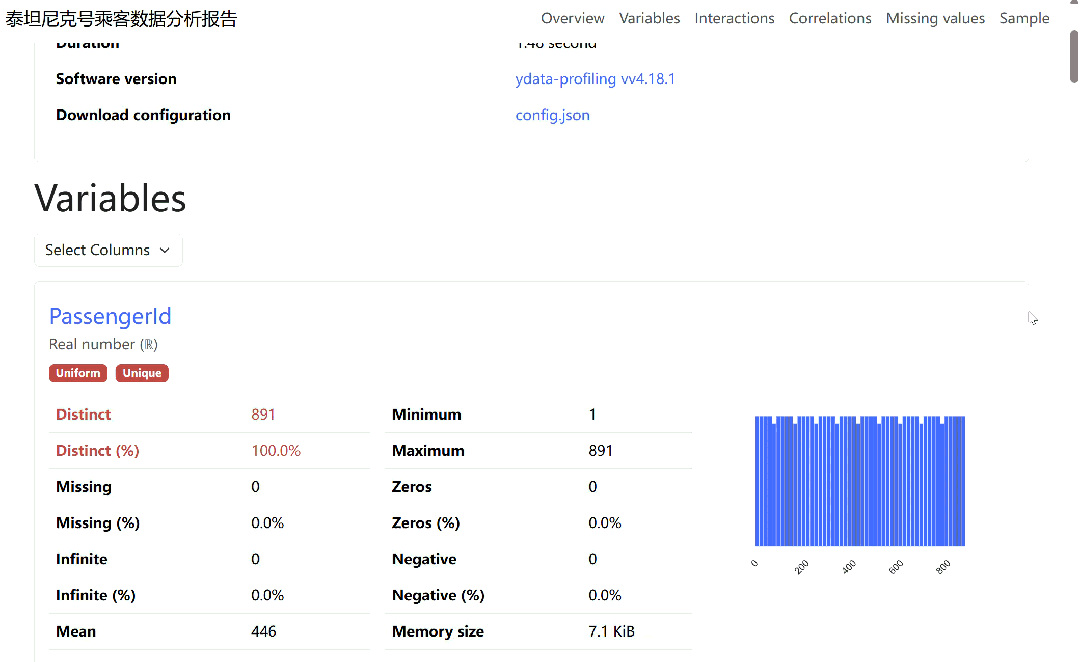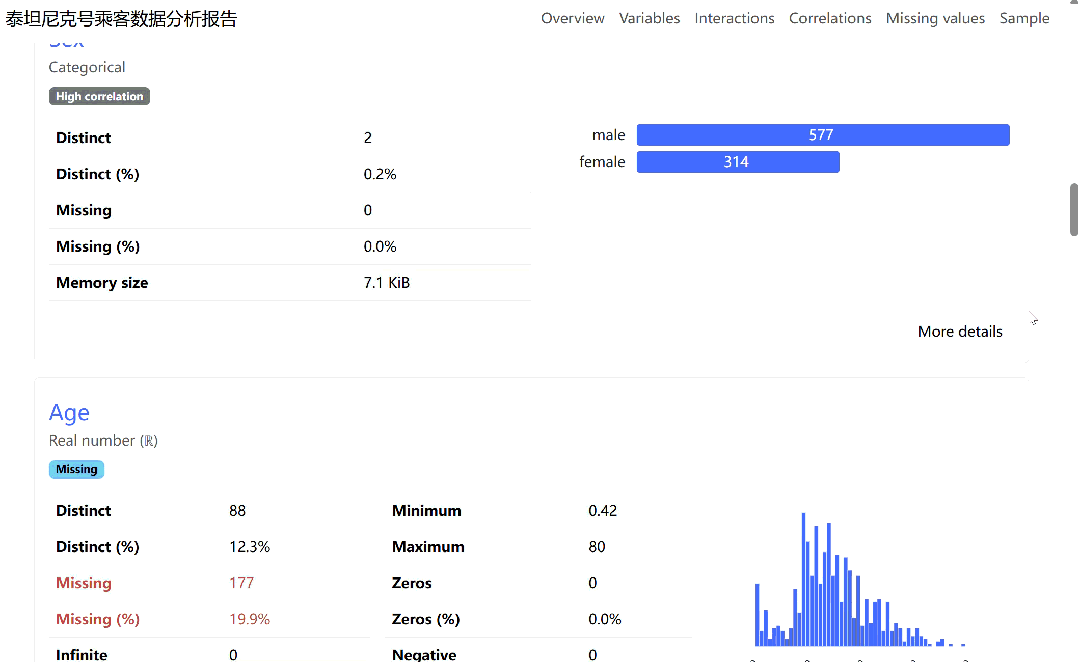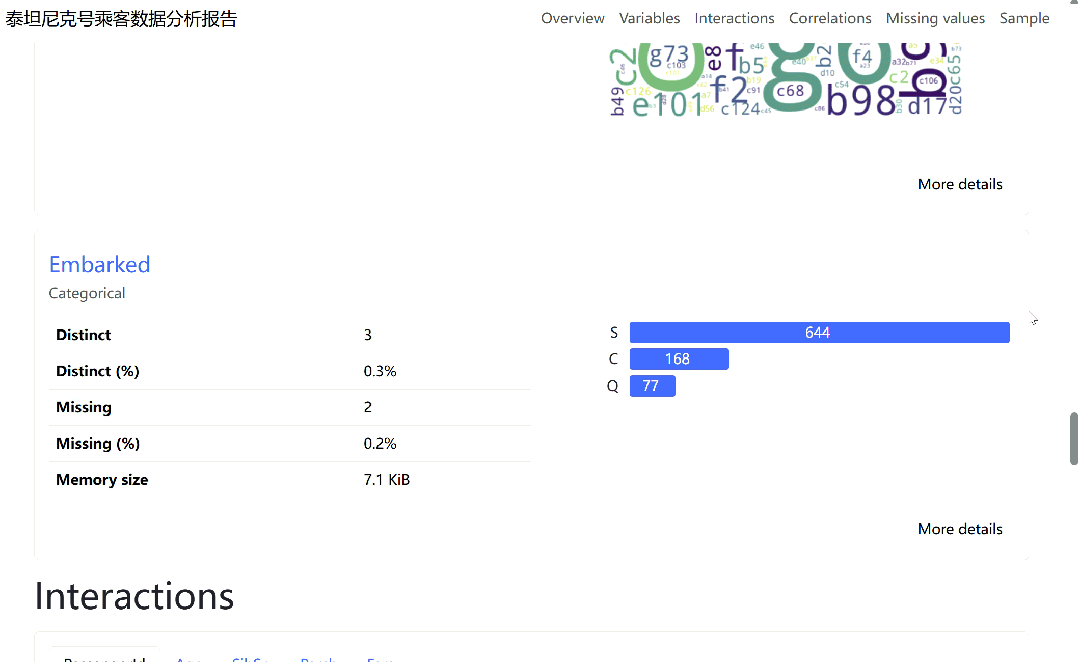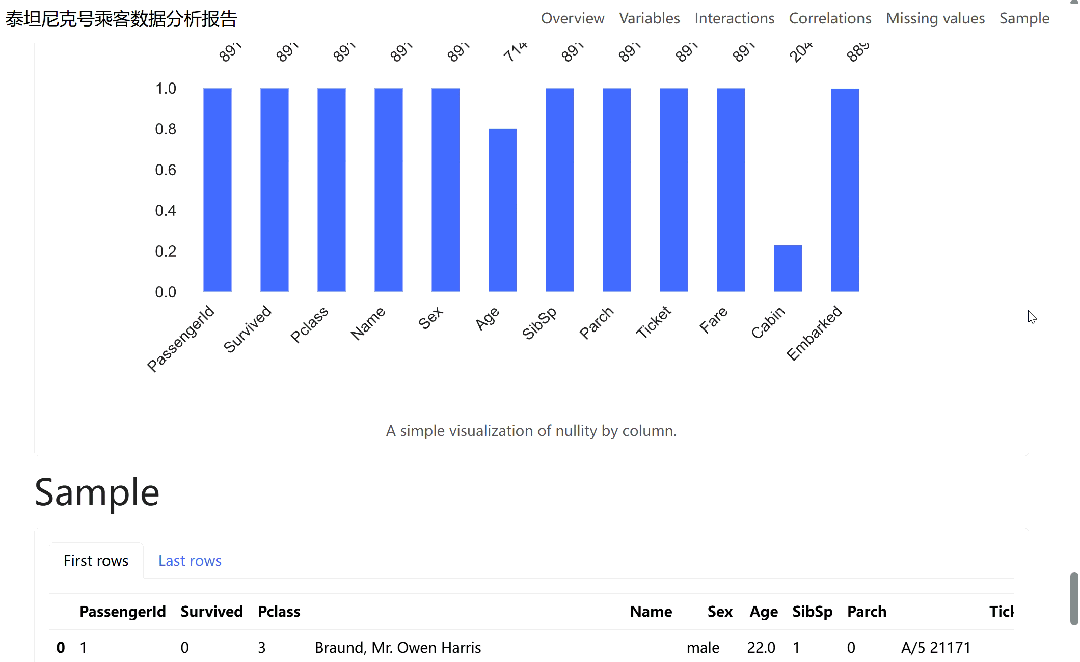
报告的概览部分会展示数据集的基本信息,如行数、列数、内存占用以及重复行情况。变量分析部分则对每一列进行深入剖析,对于数值型变量,它会展示其描述性统计量、直方图、分位数统计和常见统计值;对于类别型变量,则会展示其频数分布、众数、条形图等。
3、深入生成定制化报告
我们还可以通过配置丰富的参数来深度控制分析的内容、深度和输出格式。它允许数据科学家根据具体需求,在默认分析的基础上,启用更高级的统计方法、排除敏感数据,并生成包含特定可视化内容的专业报告。如下所示
# 在创建报告时,我们可以通过配置来深度定制分析过程# 例如,我们可能不希望分析某些敏感列,或者想启用更复杂的关联性分析profile = ProfileReport( df, title="定制化数据分析报告", explorative=True, # 启用探索性分析模式,提供更深入的分析和洞察 correlations={ "pearson": {"calculate": True}, # 计算皮尔逊相关系数,衡量线性相关性 "spearman": {"calculate": True}, # 计算斯皮尔曼相关系数,衡量单调关系 "kendall": {"calculate": True}, # 计算肯德尔相关系数,衡量有序变量关联性 "phi_k": {"calculate": True}, # 启用 Phik 相关性分析,适用于类别-数值混合数据 }, missing_diagrams={ "matrix": True, # 生成缺失值矩阵图,显示数据缺失模式 "dendrogram": True, # 生成缺失值树状图,聚类显示缺失模式 "heatmap": True, # 生成缺失值热力图,可视化缺失值相关性 }, # 可以排除某些列的分析(当前注释状态) # ignored_columns=['passenger_id', 'name'] # 忽略指定列,不进行分析)# 保存报告profile.to_file('customized_report.html') # 将分析报告保存为HTML文件
4、总结
ydata-profiling 其实不仅是一个工具,更代表了一种高效、全面的数据分析理念。它通过将繁琐、重复的数据探索过程自动化、标准化,让我们彻底告别重复劳动,将精力真正聚焦于洞察与决策。
ydata-profiling 官网:https://docs.profiling.ydata.ai/latest/
ydata-profiling 源码:https://github.com/ydataai/ydata-profiling
🔥 如果需要泰坦尼克号数据集的同学可以留言:”需要数据集“,我们将私信发送给你~~~
如果你喜欢本文,欢迎 赞同、关注、分享 三连 🔥🔥🔥 ~
添加作者微信(coder_0101),或者通过扫描下面二维码添加作者微信,拉你进入行业技术交流群,进行技术交流~

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
