了解Scrapy库
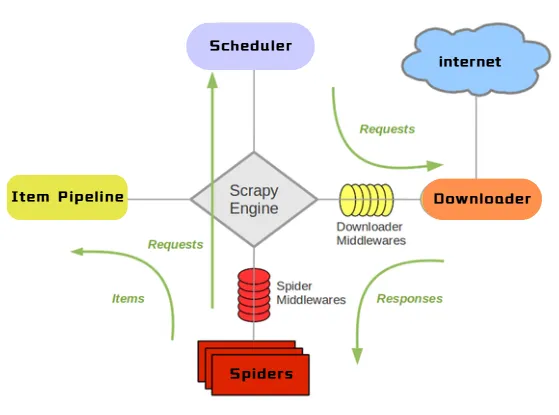
Scrapy 是一个功能强大的Python爬虫框架,专门用来抓取网页数据并提取信息。Scrapy经常被用于数据挖掘、信息处理或存储历史数据等应用。Scrapy 内置了许多有用的功能,如处理请求、跟踪状态、处理错误、处理请求频率限制等,非常适合进行高效、分布式的网页爬取。与简单的爬虫库(如 requests 和 BeautifulSoup)不同,Scrapy 是一个全功能的爬虫框架,具有高度的可扩展性和灵活性,适用于复杂和大规模的网页抓取任务。Scrapy官网:https://scrapy.org/。Scrapy特点与介绍:https://www.runoob.com/w3cnote/scrapy-detail.html。Spider:爬虫类,用于定义如何从网页中提取数据以及如何跟踪网页的链接。Item:用来定义和存储抓取的数据。相当于数据模型。Pipeline:用于处理抓取到的数据,常用于清洗、存储数据等操作。Middleware:用来处理请求和响应,可以用于设置代理、处理cookies、用户代理等。Settings:用来配置Scrapy项目的各项设置,如请求延迟、并发请求数等。安装Scrapy
Scrapy 项目结构
Scrapy项目是一个结构化的目录,其中包含多个文件夹和模块,就是想帮助你组织爬虫的代码。scrapy startproject myproject这将创建一个名为myproject的项目,项目结构大致如下:展示Scrapy如何从网页中抓取数据
创建一个爬虫项目:
scrapy startproject runoob_test_spiders
执行以上命令,如果成功会输出:
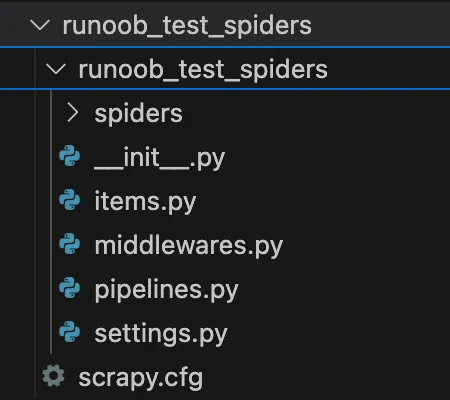
生成的项目结构如下:
接着进入该目录:
通过scrapy genspider命令来创建一个爬虫:scrapy genspider douban_spider movie.douban.com目录结构如下:
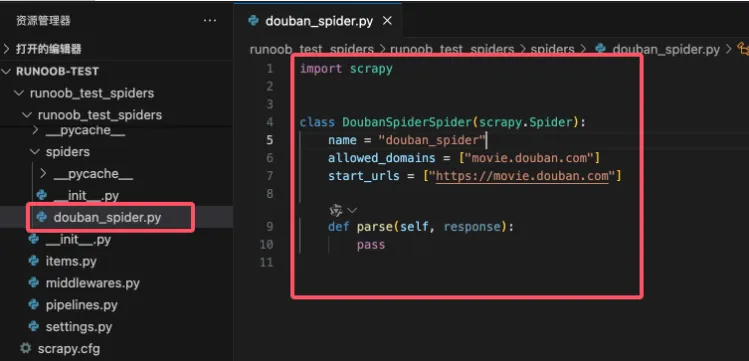
runoob_test_spiders目录下生成一个名为douban_spider.py的文件,代码如下:allowed_domains:限制爬虫的访问域名,防止爬虫爬取其他域名的网页。start_urls:定义爬虫的起始页面,爬虫将从这些页面开始抓取。parse:parse 方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个 response 对象,表示服务器返回的页面内容。编写爬虫代码
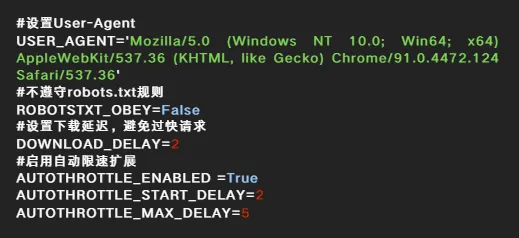
豆瓣等网站可能会检测爬虫行为,建议设置USER_AGENT和 DOWNLOAD_DELAY来模拟正常用户行为。一定要遵守目标网站的robots.txt文件规定,避免对服务器造成过大压力。修改settings.py配置
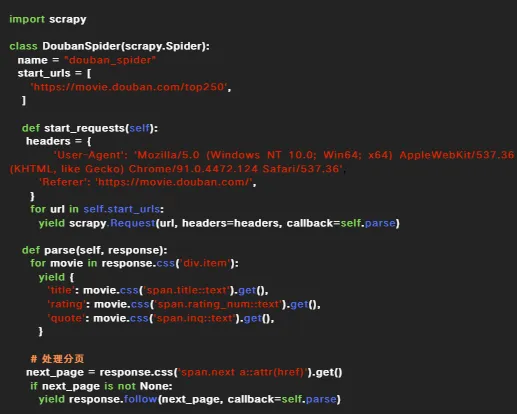
在settings.py中添加以下配置,模拟浏览器请求并绕过反爬虫机制:在爬虫代码中,添加自定义请求头(如 User-Agent 和 Referer),以进一步模拟浏览器行为。打开douban_spider.py文件,并修改其内容如下:代码解析:
- name="douban_spider": 定义爬虫的名称。
- start_urls: 定义爬虫开始爬取的初始URL(豆瓣电影Top250页面)。
- 使用 CSS 选择器提取每部电影的标题、评分和简介。
- span.rating_num::text:提取电影评分。
分页处理:
- 使用 span.next a::attr(href) 提取下一页的链接。
- 如果存在下一页,使用 response.follow 继续爬取。
在命令行中运行以下命令来启动爬虫:
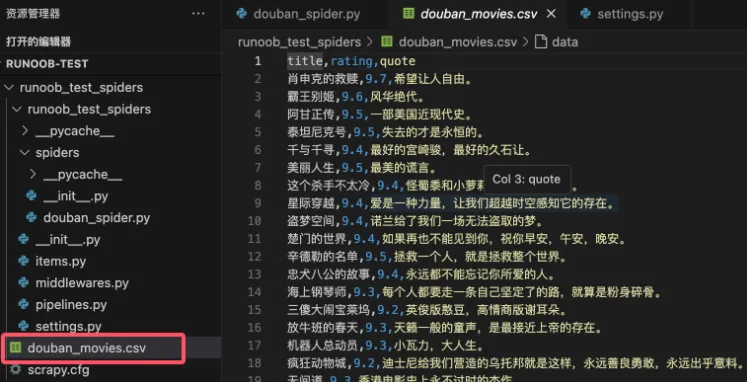
scrapy crawl douban_spider -o douban_movies.csv
这将启动爬虫并将提取的数据保存到 douban_movies.csv 文件中注意:以上内容仅供学习,请遵守网站的robots.txt文件要求
如果你觉得文章还不错,请大家支持
我还为大家准备了更多Python资料,感兴趣的小伙伴可以找我领取一起交流一下噢




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
