[原子操作基础][CUDA 编程系列][传统软件工程师转行 AI 需要掌握的一千个知识点]
- 2026-07-04 02:06:24
经典模型+cuda知识
一手理论+一手实践→天下我有
列个提纲,一壶酒,一个手机,上班路上一小时,一写写一年👌🥊🥊
没有牛逼的人,只有坚持到底的人
这篇文章估计要写好久…
不对,写一点,发一点
简单,才足以坚持,坚持才足以完成
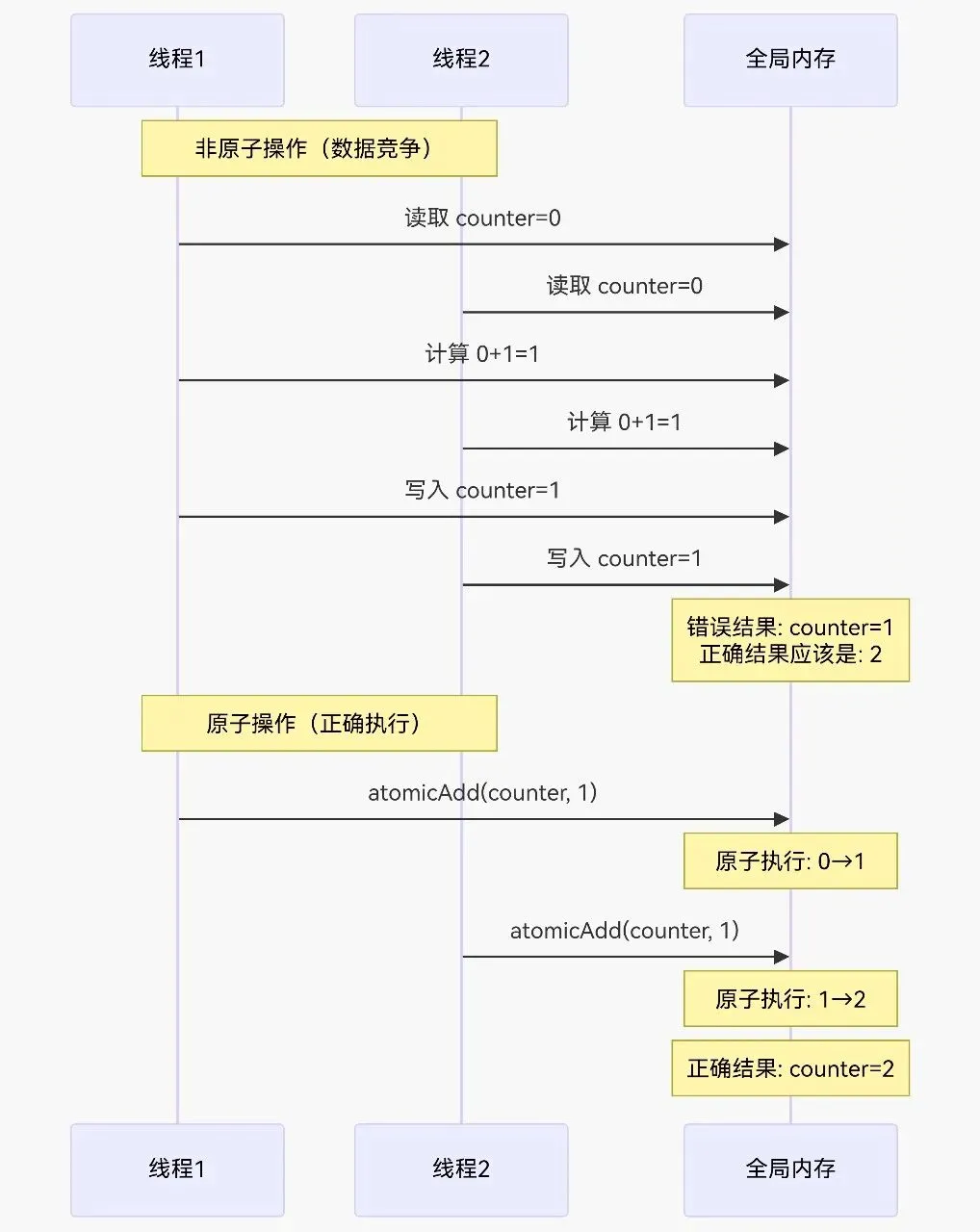
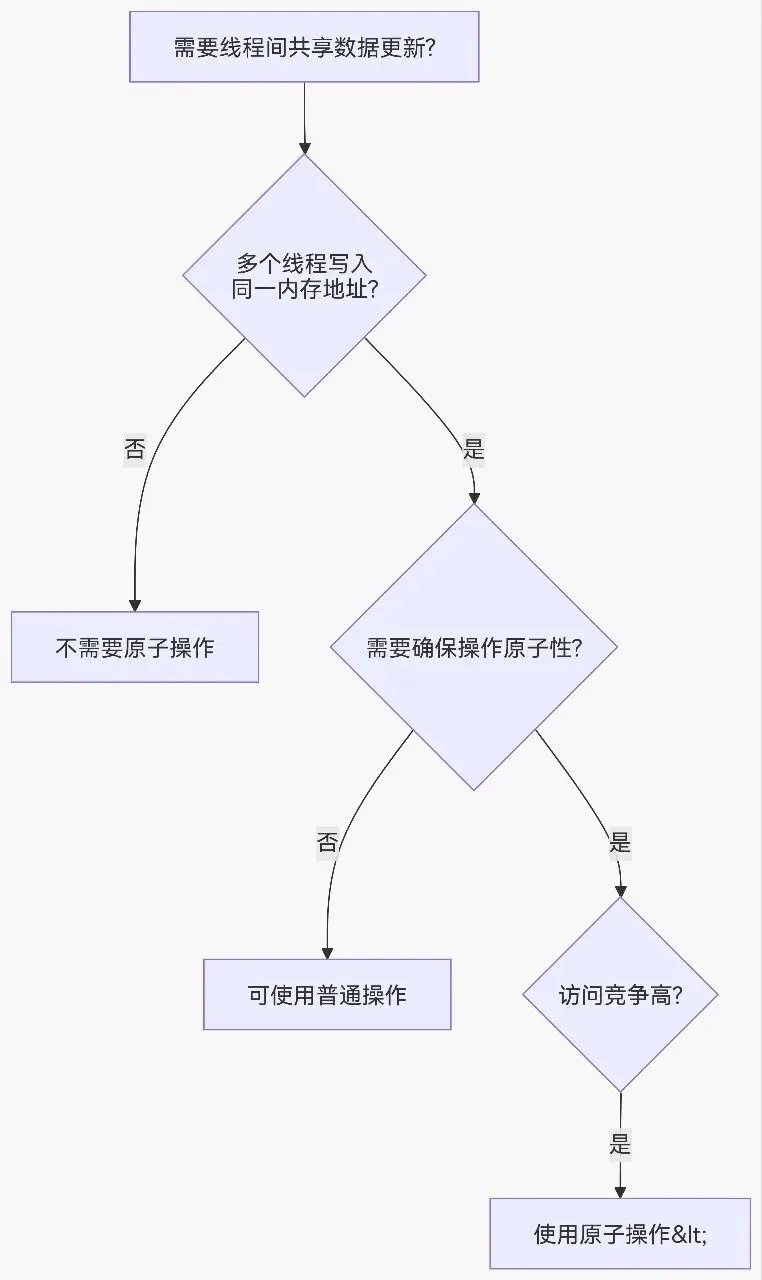
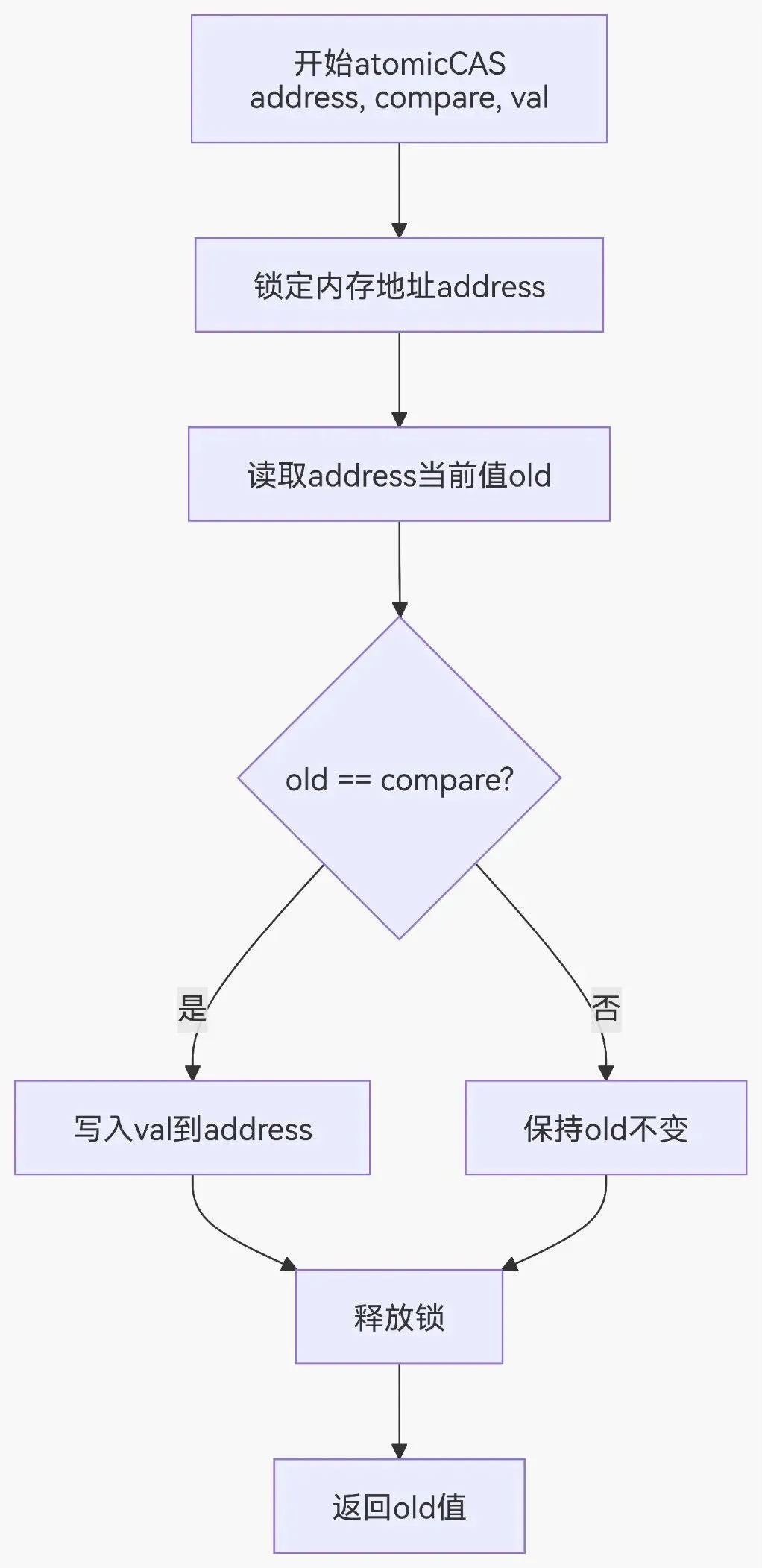
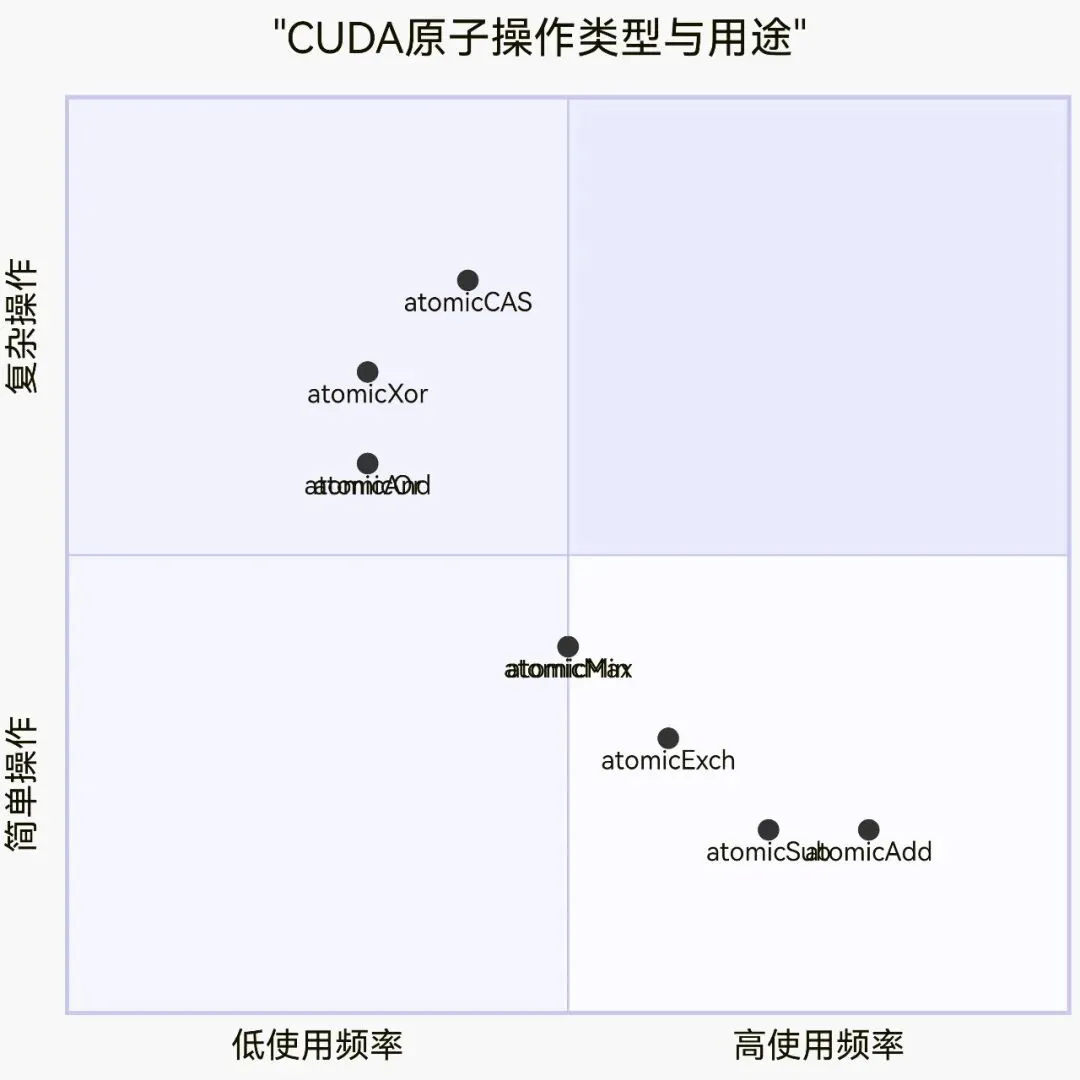
// 整数类型atomicAdd(int* address, int val); // 加法atomicSub(int* address, int val); // 减法atomicExch(int* address, int val); // 交换atomicMin(int* address, int val); // 最小值atomicMax(int* address, int val); // 最大值atomicInc(int* address, int val); // 增加到val后归0atomicDec(int* address, int val); // 减少到0后重置为valatomicCAS(int* address, int compare, int val); // 比较并交换// 64位整数(需要计算能力3.5+)atomicAdd(long long* address, long long val);// 浮点数(需要计算能力6.0+)atomicAdd(float* address, float val);atomicAdd(double* address, double val);加法示例__global__ void atomicAddKernel(int* counter, int* data, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { // 每个线程将data[idx]的值原子性地加到counter atomicAdd(counter, data[idx]); }}计算直方图__global__ void histogramKernel(int* input, int* histogram, int N, int bins) {int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) {int bin = input[idx] % bins; // 计算bin索引atomicAdd(&histogram[bin], 1); // 原子递增对应bin}}寻找最大值__global__ void findMaxKernel(int* input, int* maxValue, int N) {int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) {int old = *maxValue;int newVal = input[idx];// 原子比较并更新最大值while (newVal > old) {if (atomicCAS(maxValue, old, newVal) == old) {break;}old = *maxValue; // 如果失败,重试}}}
atomicAnd(int* address, int val); // 位与atomicOr(int* address, int val); // 位或atomicXor(int* address, int val); // 位异或
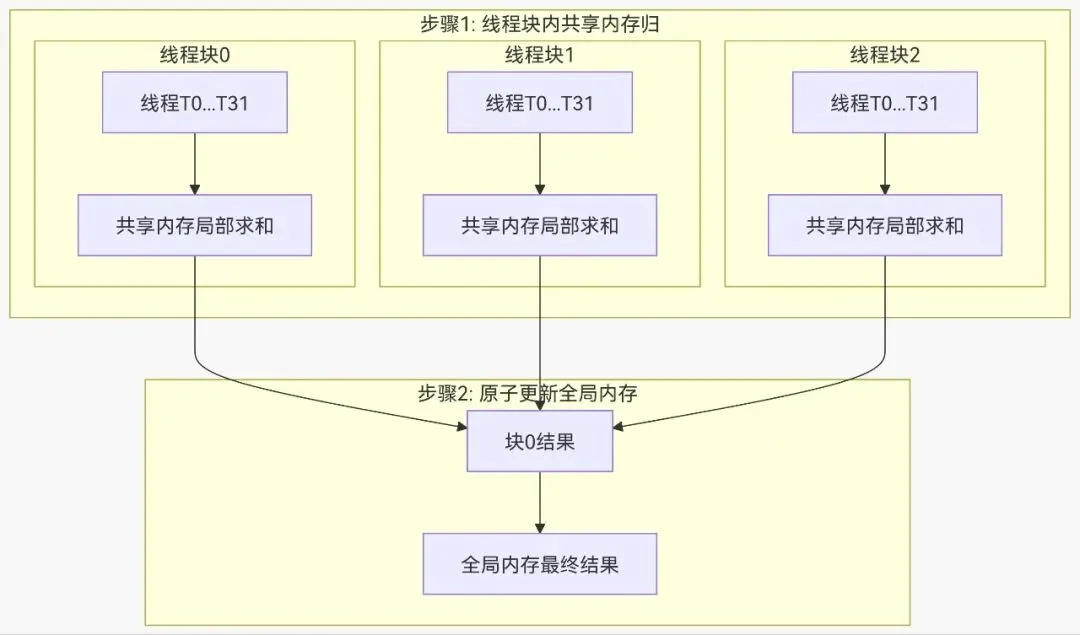
__global__ voidsharedMemoryAtomic(int* globalData, int N) {__shared__ int sharedCounter;if (threadIdx.x == 0) {sharedCounter = 0;}__syncthreads();int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) {// 对共享内存执行原子操作atomicAdd(&sharedCounter, 1);}__syncthreads();// 将结果写回全局内存if (threadIdx.x == 0) {atomicAdd(&globalData[blockIdx.x], sharedCounter);}}

#include<iostream>#include<cuda_runtime.h>// 使用原子操作的朴素实现__global__ voidnaiveAtomicSum(int* data, int* result, int N){int idx = blockIdx.x * blockDim.x + threadIdx.x;if (idx < N) {atomicAdd(result, data[idx]);}}// 使用共享内存优化的实现__global__ voidoptimizedAtomicSum(int* data, int* result, int N){__shared__ int blockSum[256];int tid = threadIdx.x;int idx = blockIdx.x * blockDim.x + threadIdx.x;blockSum[tid] = 0;if (idx < N) {blockSum[tid] = data[idx];}__syncthreads();// 在共享内存中归约for (int stride = blockDim.x / 2; stride > 0; stride >>= 1) {if (tid < stride) {blockSum[tid] += blockSum[tid + stride];}__syncthreads();}// 只有线程0原子更新全局结果if (tid == 0) {atomicAdd(result, blockSum[0]);}}intmain(){const int N = 1000000;int* h_data = new int[N];int* d_data, *d_result;// 初始化数据for (int i = 0; i < N; i++) {h_data[i] = 1;}// 分配设备内存cudaMalloc(&d_data, N * sizeof(int));cudaMalloc(&d_result, sizeof(int));// 拷贝数据到设备cudaMemcpy(d_data, h_data, N * sizeof(int), cudaMemcpyHostToDevice);// 测试朴素原子操作int h_result = 0;cudaMemset(d_result, 0, sizeof(int));naiveAtomicSum<<<(N+255)/256, 256>>>(d_data, d_result, N);cudaMemcpy(&h_result, d_result, sizeof(int), cudaMemcpyDeviceToHost);std::cout << "Naive atomic sum: " << h_result << std::endl;// 测试优化版本h_result = 0;cudaMemset(d_result, 0, sizeof(int));optimizedAtomicSum<<<(N+255)/256, 256>>>(d_data, d_result, N);cudaMemcpy(&h_result, d_result, sizeof(int), cudaMemcpyDeviceToHost);std::cout << "Optimized atomic sum: " << h_result << std::endl;// 清理delete[] h_data;cudaFree(d_data);cudaFree(d_result);return 0;}


DeepSeek R1
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→强化学习 DeepSeek :R1
强化学习
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ 强化学习 Q-Learning、DQN、PG、PPO
多模态
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ 多模态 CLIP
Diffusion
GPT 系列
GPT1 GPT2 GPT3 GPT3.5 GPT4
终于到了这个跨时代的GPT了,足以记录在人类文明史的一页
GPT1
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT1
GPT2 、GPT3
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT2、3
GPT3.5 、GPT4
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GPT3.5、4
Transformer传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ Transformers
GAN
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ GAN
AlphaGo
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ AlphaGo
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ ResNet
CNN AlexNet VGG
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ CNN AlexNet VGG
VAE
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ VAE
深度信念网络
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→深度信念网络
RNN Lstm传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→RNN
CNN Lenet-5传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→CNN
Hopfield网络&&玻尔兹曼机传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→ Hopfield网络&玻尔兹曼机
反向传播传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→反向传播
多层感知机
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→多层感知机
感知机
传统软件工程师转行 AI 需要掌握的一千个知识点→神经网络→感知机
MP 神经元

