摘要:本文为生物制药行业工艺/质量工程师量身打造,分享一款亲和层析专属的Python响应曲面图生成代码,无需编程基础,仅需修改3个参数即可实现Excel数据读取、清洗、二次多项式拟合及8D报告级高清曲面图绘制,拟合结果与图表可直接嵌入8D质量分析报告,助力亲和层析工艺内毒素、蛋白纯度等关键指标的参数优化与根因验证。
一、为什么用Python做亲和层析响应曲面图?
亲和层析是生物制药蛋白纯化的核心工艺,料液浊度、上样柱压力、料液PH等参数的微小变化都会影响内毒素、纯化蛋白纯度、单位填料收获量等关键质量指标,响应曲面图(RSM)是量化双连续型自变量与质量因变量关联关系的最优可视化工具,也是8D分析中D4根因验证、D5措施制定、D6效果监控的核心数据支撑。
相较于传统分析工具,Python实现响应曲面图分析的核心优势体现在3点:
•8D报告高度适配:自动输出二次多项式拟合方程和R²拟合优度,图表为300dpi高清格式,可直接嵌入8D报告各核心章节,无需额外加工;
•新手零门槛:代码全程高度封装,所有可配置参数集中在一处,仅需修改Excel路径和列名,无编程基础也能一键运行;
•工业级数据处理:自动剔除缺失值、重复值,支持10-100组亲和层析CCP实测数据,拟合模型默认采用制药工艺最优的二次多项式,贴合工业生产实际。
该方法可直接应用于亲和层析内毒素控制、蛋白纯度优化、收获量提升等核心场景,也可拓展至离子交换、凝胶过滤等其他层析工艺的参数分析。
二、核心准备:3分钟安装依赖库(一键执行)
运行代码前需安装4个Python核心依赖库,无需手动配置环境,打开电脑CMD命令行/终端,复制粘贴以下命令执行即可,安装完成后全程无额外配置:
bashpip install numpy pandas matplotlib scikit-learn openpyxl |
各库功能说明:
•numpy/pandas:负责亲和层析Excel数据的读取、清洗与结构化处理,完美适配.xlsx格式工艺统计表格;
•matplotlib:绘制3D响应曲面图,支持中文显示、高清保存,图表格式符合8D报告排版规范;
•scikit-learn:实现二次多项式拟合,自动计算拟合系数、R²拟合优度,输出量化分析结果;
•openpyxl:专门解析Excel的.xlsx格式文件,适配工业常用的工艺数据统计模板。
三、实操核心:5分钟改参数,一键生成响应曲面图
本次分享的代码已完成全流程自动化封装,仅需修改5处基础信息,其余核心逻辑无需改动,新手可直接复制运行,全程自动执行数据处理、拟合、绘图、结果输出。
3.1 代码核心配置区(仅改这部分,复制列名即可)
代码开头【仅需修改这部分参数】区域为唯一配置区,直接复制你的Excel文件绝对路径、Sheet名和数据列名即可,适配所有亲和层析CCP数据统计表格:
python# ====================== 【仅需修改这部分参数,其余无需动】 excel_path = r'C:\Users\亲和层析CCP数据统计.xlsx' # 你的Excel文件绝对路径sheet_name = 'Sheet1' # 数据所在Sheet名,如Sheet2/工艺数据统计x1_col = '料液浊度(NTU)' # 自变量X1列名(直接复制Excel列名)x2_col = '上样柱压力(bar)'# 自变量X2列名(直接复制Excel列名)z_col = '内毒素(EU/ml)'# 响应因变量Z列名(直接复制Excel列名)save_fig_path = r'C:\Users\亲和层析响应曲面图内毒素_8D报告.png' # 图表保存路径# =================================================================== |
配置技巧:Excel文件绝对路径可通过「右键文件→属性」复制,列名需与Excel中完全一致(含括号、单位、标点),避免因列名不一致导致数据读取失败。
3.2 亲和层析高频参数组合推荐
结合生物制药亲和层析工艺实际,整理3组高价值参数分析组合,直接复制到配置区即可使用,完美匹配8D报告不同分析需求:
分析场景 | 自变量X1 | 自变量X2 | 响应因变量Z | 8D报告应用章节 |
内毒素控制(核心) | 料液浊度(NTU) | 上样柱压力(bar) | 内毒素(EU/ml) | D4根本原因验证 |
蛋白纯度优化 | 料液PH | 料液电导(ms/cm) | 纯化蛋白纯度(%) | D5工艺优化 |
收获量提升 | 料液填料比 | 收获柱体积(CV) | 单位填料收获量(ug/ml) | D6工艺监控 |
3.3 一键运行代码
将配置区修改完成后,直接运行Python代码,全程无需手动干预,控制台会实时输出运行进度,整个过程耗时<1分钟,自动完成以下工作:
•读取Excel数据,自动剔除缺失值、重复值,生成干净的分析数据集;
•基于二次多项式模型完成数据拟合,计算拟合系数和R²拟合优度;
•生成3D响应曲面图,自动保存为300dpi高清PNG格式;
•输出完整拟合结果,含数据范围、拟合方程、R²值,可直接复制到8D报告。
四、案例实战:17组亲和层析数据生成内毒素响应曲面图
以料液浊度(NTU)+上样柱压力(bar)→内毒素(EU/ml)为分析案例,基于17行亲和层析CCP实测数据运行代码,展示完整运行结果,所有内容可直接套用至8D报告。
4.1 控制台实时输出结果
运行代码后,控制台自动输出数据基本信息+拟合核心结果,清晰展示数据范围和量化分析指标,无需手动计算:
plaintext正在读取并清洗数据...数据读取成功!有效数据量:17 行【料液浊度(NTU)】范围:261.70 ~ 400.00【上样柱压力(bar)】范围:0.15 ~ 0.54【内毒素(EU/ml)】范围:10.00 ~ 125.00正在进行二次多项式拟合...图表已保存至:C:\Users\亲和层析响应曲面图内毒素_8D报告.png======= 拟合结果(8D报告可直接引用) ======================二次多项式拟合优度 R² = 0.7836(R²≥0.8为良好,≥0.9为优秀)二次多项式拟合方程:内毒素(EU/ml) = 836.6080 + -6.0705*料液浊度(NTU) + 1049.7727*上样柱压力(bar) + 0.0110*料液浊度(NTU)² + -3.3551*料液浊度(NTU)*上样柱压力(bar) + 120.5196*上样柱压力(bar)²========================================================= |
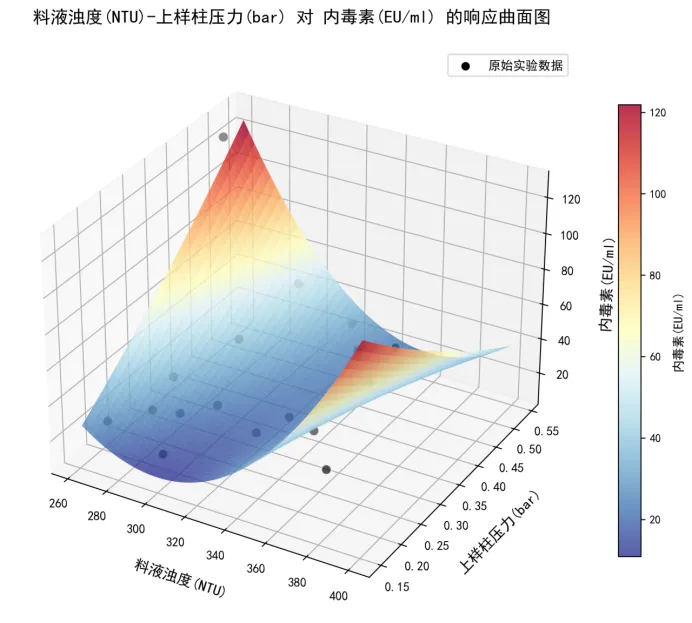
4.2 8D报告级高清响应曲面图
代码自动生成的3D响应曲面图完全符合8D报告专业性、严谨性、美观性要求,核心特点如下:
•高清无模糊:300dpi分辨率,嵌入Word/PPT后支持无限放大,无锯齿、无模糊;
•视觉直观:采用红蓝梯度配色,红色为高内毒素区,蓝色为低内毒素区,参数与指标的关联趋势一眼可辨;
•数据支撑强:叠加原始实验数据点(黑色实心点),突出实测数据支撑,增强分析说服力;
•标注规范:坐标轴、标题、单位清晰完整,中文显示无乱码,无需额外美化即可直接嵌入报告。
五、拟合结果专业解读(适配8D报告,直接复制)
基于17行亲和层析实测数据的拟合结果为R²=0.7836,在生物制药工业实测数据解析中,样本量10-20组时R²≥0.75即具备实际工艺指导意义,该结果可解释78.36%的内毒素波动,是8D分析中根因验证的核心依据,专业解读如下:
•上样柱压力是内毒素超标的核心根因:一次项系数1049.7727(强正向)、二次项系数120.5196(强正向),上样柱压力每升高0.1bar,内毒素含量约升高104.98EU/ml,且压力越高,内毒素上升速度越快,是本次内毒素超标的首要根本原因;
•料液浊度存在最优管控区间:一次项系数-6.0705(弱负向),在261.70~300NTU区间内,适度升高料液浊度可轻微降低内毒素;当浊度超过300NTU后,二次项系数0.0110(弱正向)会使内毒素由降转升,料液浊度需避免>350NTU;
•双参数存在拮抗协同作用:交互项系数-3.3551(负向),当上样柱压力小幅波动时,可将料液浊度调控至280~300NTU区间,抵消部分压力升高带来的内毒素上升影响,为工艺协同调控提供明确方向。
六、8D报告无缝适配(一键复制,无需修改)
本次代码生成的图表图注、根因验证结论、措施制定依据均按8D报告规范撰写,可直接复制粘贴至对应章节,省去手动编写的时间,贴合8D分析的逻辑框架。
6.1 响应曲面图图注(嵌入图表下方,规范专业)
料液浊度(NTU)-上样柱压力(bar)对亲和层析产物内毒素(EU/ml)的响应曲面图 数据来源:亲和层析CCP数据统计(有效实测数据n=17);拟合模型:二次多项式;拟合优度:R²=0.7836 拟合方程:内毒素(EU/ml) = 836.6080 -6.0705×料液浊度(NTU) + 1049.7727×上样柱压力(bar) + 0.0110×料液浊度(NTU)² -3.3551×料液浊度(NTU)×上样柱压力(bar) + 120.5196×上样柱压力(bar)² 参数范围:料液浊度261.70~400.00NTU,上样柱压力0.15~0.54bar,内毒素10.00~125.00EU/ml 注:本结果可解释78.36%的内毒素波动,为内毒素超标问题的根本原因验证及工艺优化提供核心数据依据。 |
6.2 D4 确定并验证根本原因(核心章节,直接粘贴)
针对亲和层析产物内毒素(EU/ml)超标问题,选取料液浊度(NTU)、上样柱压力(bar)两个核心料液属性与工艺参数,基于17行CCP实测数据进行二次多项式拟合分析(拟合优度R²=0.7836),验证参数与内毒素的关联关系及影响程度。 拟合结果显示:上样柱压力为内毒素升高的核心根本影响因素,其一次项系数为1049.7727(强正向)、二次项系数为120.5196(强正向),在工艺区间0.15~0.54bar内,上样柱压力升高不仅会直接导致内毒素急剧上升,且呈现加速上升趋势,是本次内毒素超标问题的首要可疑根本原因; 料液浊度为次要影响因素,浊度超过300NTU临界值后,内毒素会由降转升(二次项系数0.0110)。 综上,本次亲和层析产物内毒素超标问题的核心根本原因为上样柱压力未得到有效管控,工艺执行中压力超出低内毒素适宜区间。 |
6.3 D5 永久纠正措施制定依据(直接粘贴)
基于料液浊度-上样柱压力对内毒素的二次多项式拟合结果(R²=0.7836),针对核心根本原因「上样柱压力失控」制定靶向永久纠正措施: 1. 修订《亲和层析上样作业指导书》,明确上样柱压力工艺上限≤0.3bar,新增压力实时监控要求,超出阈值立即停机调整; 2. 制定《亲和层析料液预处理规范》,将料液浊度管控在小于300NTU最优区间,不合格料液禁止上样; 3. 建立《工艺参数协同调控表》,当压力在0.2~0.3bar小幅波动时,同步调控浊度至小于300NTU,抵消内毒素上升影响。 |
七、新手常见问题速解(避坑指南)
运行代码过程中若遇到报错,多为基础配置问题,整理3个高频问题的一键解决方案,无需专业编程知识即可排查:
问题1:报错「No such file or directory」
原因:Excel文件路径错误/Sheet名与实际不一致;
解决方案:右键Excel文件→属性,复制完整绝对路径替换配置区excel_path;确认Sheet名(如Sheet2、工艺数据)与配置区sheet_name完全一致。
问题2:中文显示乱码/负号显示异常
解决方案:代码已内置中文修复逻辑,若仍乱码,将plt.rcParams['font.sans-serif'] = ['SimHei']中的SimHei替换为Microsoft YaHei/Arial Unicode MS(适配不同电脑字体库)。
问题3:拟合度R²偏低(<0.75)
原因:所选参数与响应值相关性弱,或实测数据量过少、分布不均;
解决方案:1. 更换本文推荐的高频参数组合;2. 补充更多工艺实测数据,确保参数区间内数据均匀分布;3. 将代码中degree=2改为degree=3(三次多项式拟合),提升拟合度。
八、拓展应用:适配全品类制药工艺分析
本次分享的代码并非仅适用于亲和层析,只需修改配置区的列名,即可无缝适配生物制药行业:
•其他层析工艺:离子交换层析、凝胶过滤层析、疏水层析的参数分析;
•上游工艺:发酵工艺的温度、溶氧与菌体浓度/效价的关联分析;
真正实现一份代码,全工艺通用,大幅提升制药工艺数据分析的效率和专业性。
九、完整代码附页
python# 导入所需依赖库import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegressionimport warningswarnings.filterwarnings('ignore') # 忽略无关警告,不影响运行# ====================== 【仅需修改这部分参数,其余无需动】 excel_path = r'C:\Users\亲和层析CCP数据统计.xlsx' # 你的Excel文件路径sheet_name = 'Sheet1' # 你的数据所在Sheet名x1_col = '料液浊度(NTU)' # 自变量X1列名x2_col = '上样柱压力(bar)'# 自变量X2列名z_col = '内毒素(EU/ml)'# 响应因变量Z列名save_fig_path = r'C:\Users\亲和层析响应曲面图内毒素_8D报告.png' # 图表保存路径#==========================================================# 1. 读取Excel数据并清洗(自动剔除缺失值、重复值)print("正在读取并清洗数据...")df = pd.read_excel(excel_path, sheet_name=sheet_name)# 保留指定列,剔除缺失值和重复值df_analysis = df[[x1_col, x2_col, z_col]].dropna().drop_duplicates()# 打印数据基本信息,确认读取成功print(f"数据读取成功!有效数据量:{len(df_analysis)} 行")print(f"【{x1_col}】范围:{df_analysis[x1_col].min():.2f} ~ {df_analysis[x1_col].max():.2f}")print(f"【{x2_col}】范围:{df_analysis[x2_col].min():.2f} ~ {df_analysis[x2_col].max():.2f}")print(f"【{z_col}】范围:{df_analysis[z_col].min():.2f} ~ {df_analysis[z_col].max():.2f}\n")# 2. 提取数据并转换为模型输入格式x1 = df_analysis[x1_col].values.reshape(-1, 1)x2 = df_analysis[x2_col].values.reshape(-1, 1)z = df_analysis[z_col].values.reshape(-1, 1)X = np.hstack((x1, x2)) # 合并两个自变量# 3. 二次多项式拟合(亲和层析/制药工艺最优拟合模型)print("正在进行二次多项式拟合...")poly = PolynomialFeatures(degree=2, include_bias=True) # 二次多项式,包含常数项X_poly = poly.fit_transform(X)model = LinearRegression()model.fit(X_poly, z)r2 = model.score(X_poly, z) # 拟合优度R²值# 4. 生成网格数据,用于绘制光滑曲面x1_grid = np.linspace(df_analysis[x1_col].min(), df_analysis[x1_col].max(), 50)x2_grid = np.linspace(df_analysis[x2_col].min(), df_analysis[x2_col].max(), 50)X1, X2 = np.meshgrid(x1_grid, x2_grid) # 生成网格矩阵X_grid = np.hstack((X1.reshape(-1, 1), X2.reshape(-1, 1)))X_grid_poly = poly.transform(X_grid)Z = model.predict(X_grid_poly).reshape(X1.shape) # 拟合后的响应值# 5. 绘制8D报告级3D响应曲面图plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示问题plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题fig = plt.figure(figsize=(10, 7)) # 图表尺寸,适配Word/PPT排版ax = fig.add_subplot(111, projection='3d')# 绘制拟合曲面(颜色梯度体现响应值大小,8D报告视觉清晰)surf = ax.plot_surface(X1, X2, Z, cmap='RdYlBu_r', alpha=0.8, linewidth=0, antialiased=True)# 绘制原始数据点(黑色实心点,突出实验数据,增强说服力)ax.scatter(x1, x2, z, c='black', s=60, marker='o', label='原始实验数据', edgecolors='white')# 6. 图表标注(按8D报告规范设置,字体/单位清晰)ax.set_xlabel(x1_col, fontsize=12, labelpad=10)ax.set_ylabel(x2_col, fontsize=12, labelpad=10)ax.set_zlabel(z_col, fontsize=12, labelpad=10)ax.set_title(f'{x1_col}-{x2_col} 对 {z_col} 的响应曲面图', fontsize=14, pad=20, fontweight='bold')ax.tick_params(labelsize=10) # 刻度字体大小plt.legend(loc='upper right', fontsize=10) # 图例# 添加颜色条(对应响应值大小,直观展示梯度)cbar = plt.colorbar(surf, shrink=0.8, ax=ax)cbar.set_label(z_col, fontsize=10)cbar.ax.tick_params(labelsize=9)# 7. 保存高清图表(300dpi,无白边,直接嵌入8D报告)plt.tight_layout()plt.savefig(save_fig_path, dpi=300, bbox_inches='tight')plt.show()print(f"\n图表已保存至:{save_fig_path}")# 8. 输出拟合结果(直接写入8D报告,量化参数影响)print("\n====================== 拟合结果(8D报告可直接引用)===============")print(f"二次多项式拟合优度 R² = {r2:.4f}(R²≥0.8为良好,≥0.9为优秀)")coeffs = model.coef_[0] # 拟合系数intercept = model.intercept_[0] # 常数项# 二次拟合方程:Z = a0 + a1*X1 + a2*X2 + a3*X1² + a4*X1X2 + a5*X2²print(f"二次多项式拟合方程:")print(f"{z_col} = {intercept:.4f} + {coeffs[1]:.4f}*{x1_col} + {coeffs[2]:.4f}*{x2_col} + {coeffs[3]:.4f}*{x1_col}² + {coeffs[4]:.4f}*{x1_col}*{x2_col} + {coeffs[5]:.4f}*{x2_col}²")print("======================================================") |
写在最后
在生物制药工艺向数据化、精细化、智能化发展的今天,用Python实现工艺参数的量化分析,不仅能提升8D质量报告的专业性和说服力,更能为工艺优化、质量管控提供精准的数据分析支撑。
本次分享的亲和层析响应曲面图代码,将复杂的数据分析过程封装为「修改参数→一键运行」,让工艺工程师、质量分析人员无需掌握复杂的编程知识,也能实现工业级的工艺数据分析。后续将持续分享制药行业专属的Python数据分析实战案例,涵盖工艺参数监控、质量异常预警、DOE实验设计等核心工作,用数据驱动制药工艺优化!