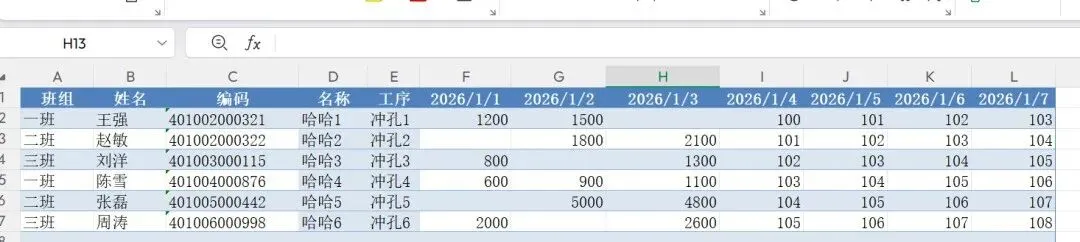
今天为大家分享的是,在生产日报Excel是工厂日常最常用的报表之一,常规格式大多是这样:前几列固定记录班组、姓名、工序等基础信息,后续一长串列均为日期,每列填写对应日期的生产产量。
但是上面的报表本身填写比较方便,但一旦需要做数据统计分析,就会暴露诸多痛点:
- 按班组、工序做维度拆解分析,需要编写大量Excel函数
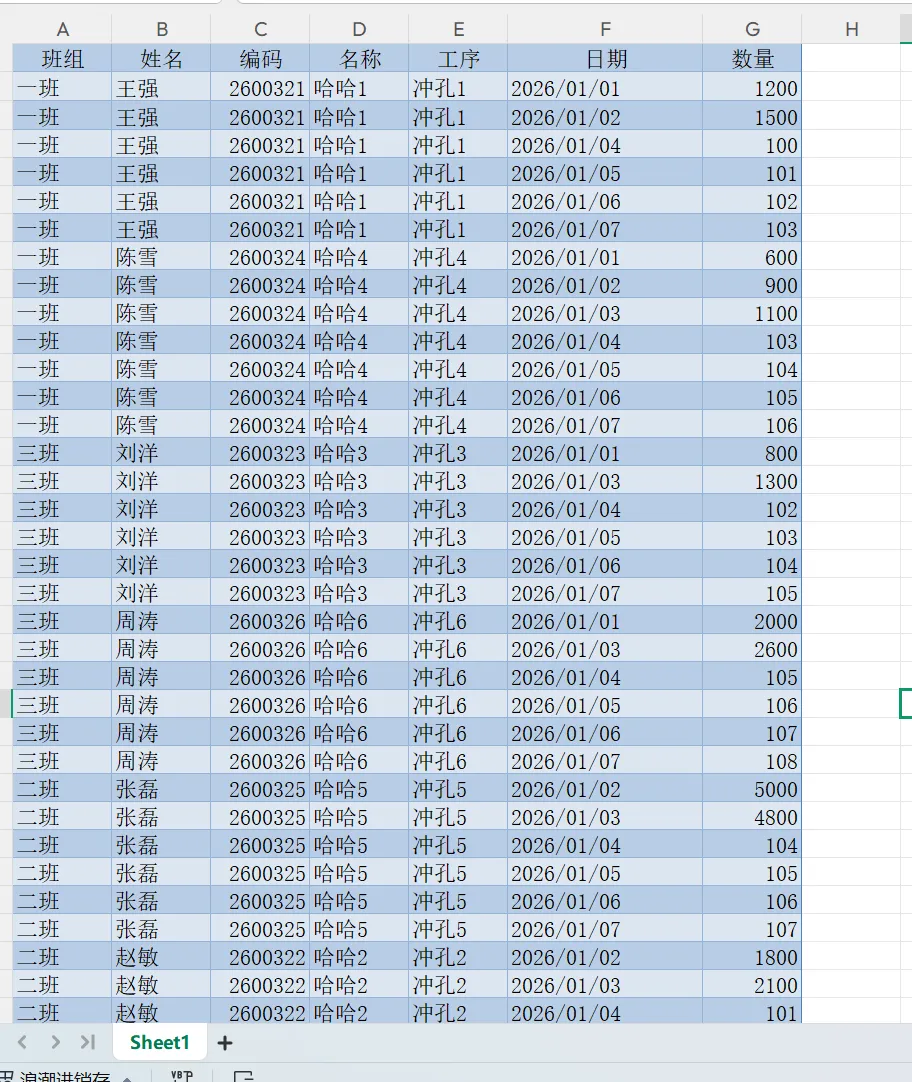
所以我们需要处理成下面这样的:
一、直接上代码
无需复杂算法和自定义逻辑,借助pandas库的melt()函数,即可快速完成格式转换,全程分5步实现:
1️⃣、 读取源Excel数据
导入依赖库,读取本地生产日报文件,支持.xlsx/.xls格式:
import pandas as pd# 读取原始生产日报Excel文件df = pd.read_excel('xxx0206.xlsx')
2️⃣、 行列格式转换(核心步骤)
通过melt()函数,将横向的日期列,重塑为纵向的行数据,保留基础维度字段:
# 宽表转长表:固定维度字段,合并日期与产量列df_long = pd.melt( df,# 固定不变的基础维度列(可根据实际表格字段调整) id_vars=['班组', '姓名', '编码', '名称', '工序'],# 转换后日期字段的列名 var_name='日期',# 转换后产量数值的列名 value_name='数量')
该步骤的核心作用:将分散在多列的日期数据,纵向整合为标准维度列。
3️⃣、 数据清洗过滤
剔除无产量的空值记录,并统一产量字段的数据类型,保证后续计算准确性:
# 删除产量为空的无效行(无生产记录)df_long = df_long.dropna(subset=['数量'])# 将产量转换为整数类型,适配数值统计df_long['数量'] = df_long['数量'].astype(int)
4️⃣、 修复Excel日期格式问题
Excel日期字段读取后,常会携带00:00:00时间戳,统一格式化日期格式:
# 标准化日期格式:YYYY/MM/DD,可根据需求修改格式规则df_long['日期'] = pd.to_datetime(df_long['日期']).dt.strftime('%Y/%m/%d')
5️⃣、 导出标准化结果文件
生成可直接用于分析的Excel文件,关闭默认索引列,避免冗余数据:
# 导出最终结果,不保留行索引df_long.to_excel('标准化生产日报.xlsx', index=False)
二、全部实现源代码:
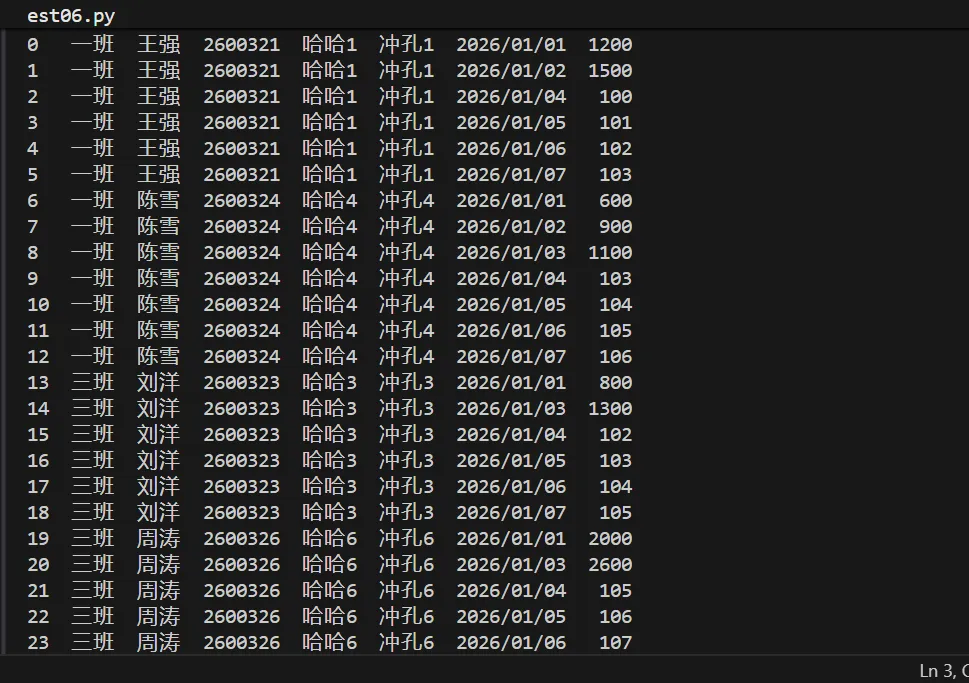
import pandas as pd# 1. 读取 Exceldf = pd.read_excel('数据0206.xlsx')# 2. 宽表转长表df_long = pd.melt( df, id_vars=['班组', '姓名', '编码', '名称', '工序'], var_name='日期', value_name='数量')# 3. 删除数量为空的数据df_long = df_long.dropna(subset=['数量'])# 4. 数量转为整数df_long['数量'] = df_long['数量'].astype(int)# 关键修复:日期去掉时分秒df_long['日期'] = pd.to_datetime(df_long['日期']).dt.strftime('%Y/%m/%d')# 5. 排序df_long = df_long.sort_values( by=['班组', '姓名', '编码', '工序', '日期']).reset_index(drop=True)# 6. 导出 Exceldf_long.to_excel('最终结果.xlsx', index=False)print(df_long)
后续报表新增日期列,无需修改任何代码,脚本可直接复用。还可以无缝导入数据库、Tableau/Power BI等BI系统做深度分析,直接绘制产量趋势图、对比图等可视化图表。快速按班组、工序、人员维度汇总产量。
🔮 获取和交流
需要本文源码和数据集的同学,关注公众号 + 点赞 + 在看 + 转发(三连),评论区回复 666,即可获取!
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
