一、学前花絮
我们之前介绍了多种数据库与python的结合,数据库在大数据处理方面有着重要的地位。而数据库又多种多样,一般分为关系型、非关系型。我们常见的mysql等都是关系型数据库,而之前提到的图数据库kuzu就是非关系型。按照存储方式,又分为行存和列存,mysql是典型的行存数据库,而kuzu、Duckdb是列存数据库。
我们个人学习的时候,一般用比较简单的如sqlite、mysql、postgresql等数据库,占用空间小,个人电脑运行起来不太耗内存。
但是在企业服务器,有更多的数据库可以选择,如并行数据库、集群数据库等,当然也可以装单机版。企业服务器配置比较高,而且数量多,所以可以配置成主从模式,简单理解就是一台服务器故障,另一台服务器的数据库可以继续运行,不影响业务使用。而如果多台服务器组成一个集群,那么集群版的数据库在高并发等方面更具优势。
列存储数据库在最近一些年受到重视,因为随着IT相关行业的发展,大数据处理、数据分析等得到广泛应用。列存储数据库比起行存出来说,最大的优势是可以按照字段(一列或多列)进行查询,可以不涉及其他无关字段,所以查询性能好。
今天介绍Duckdb这款列存储数据库,这款数据库安装极为便捷,可以嵌入到python中。
二、python连接列存数据库Duckdb进行数据分析
2.1 DuckDB 简介
DuckDB 是一个开源的、嵌入式、列式、关系型 OLAP 数据库,专为交互式数据分析设计。它常被称为 “OLAP 版的 SQLite” —— 轻量、无需服务器、单文件、支持标准 SQL,但针对分析查询做了极致优化。
2.2 核心特性与数据存储结构
1.列式存储(Columnar Storage)
l数据按列而非行组织(如 age 列所有值连续存储)。
l优势:
① 查询只需读取涉及的列(如 SELECT age FROM users 不读 name)
② 更高的压缩率
③ 向量化执行(SIMD 指令加速)
2.向量化执行引擎
l使用 批处理(batch)方式处理数据(通常 1024 行/批)
l避免传统解释型 SQL 引擎的逐行开销
l支持现代 CPU 的 SIMD 并行计算
3.零配置 & 嵌入式
l无后台进程,直接在应用进程中运行
l数据可存为单个 .duckdb 文件,或纯内存(:memory:)
4.高性能分析能力
l支持复杂聚合、窗口函数、CTE、子查询
l对 GROUP BY、JOIN、ORDER BY 等 OLAP 操作高度优化
l在 TPC-H 基准测试中,性能远超 SQLite,接近 ClickHouse
2.3 典型应用场景
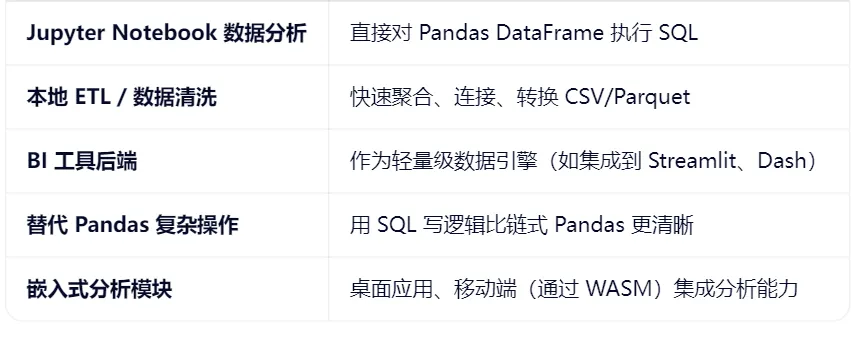
特别适合:单机、中等规模数据(GB 级)
2.4 Python 调用示例
1. 安装
2.基础用法:连接与查询
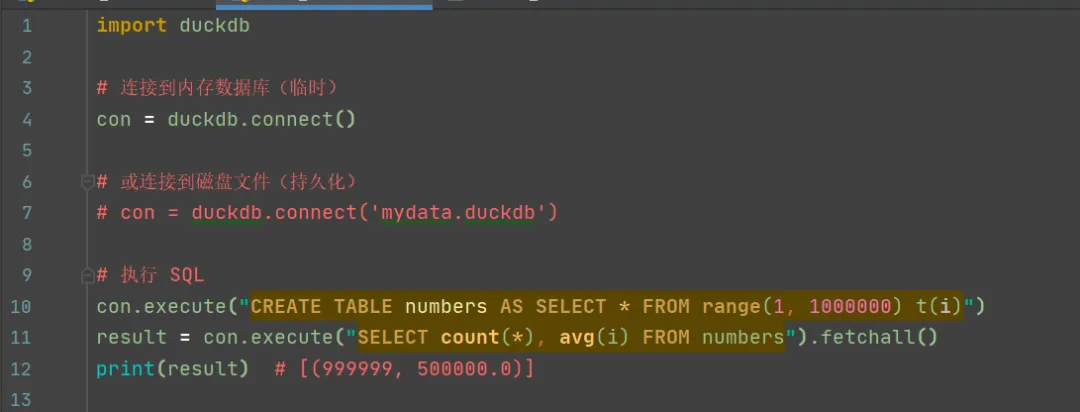
我们看到上面的代码发现,有2种使用模式,一是在内存中,一是在本地存储。这与之前的sqlite非常相似。唯一的不同后者是行存储数据库。
3. duckdb与 Pandas 无缝集成及持久化和复用
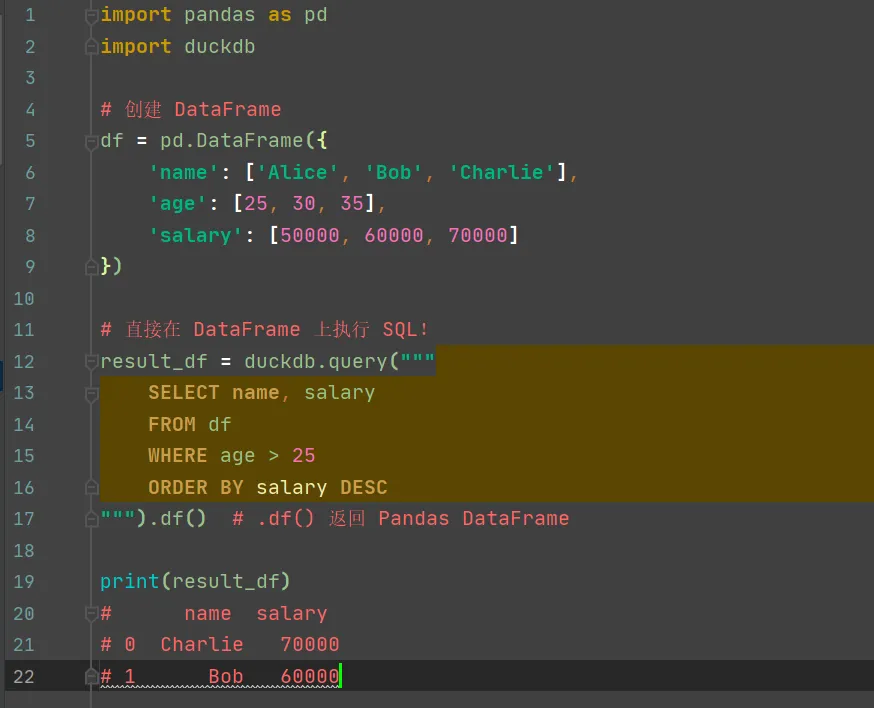
从上面代码可以看出,duckdb的sql语句直接把pandas的dataframe(df)当做表来查询。确实是无缝集成。即便是mysql也不能这样使用,而是要将df数据导入mysql的表才可以!

从上面的表格看出duckdb与python的结合优点太丝滑了。
4. 直接查询 Parquet / CSV 文件
lParquet 是什么?
Apache Parquet 是一种开源的、列式存储
它被设计用来高效存储和读取大规模结构化数据(如日志、用户行为、销售记录等)。
① 不是数据库,只是一个文件格式(就像 .csv、.json)
② 文件扩展名通常是 .parquet
③ 被几乎所有大数据工具支持:Spark, Pandas, DuckDB, ClickHouse, Snowflake, BigQuery 等
lParquet vs MySQL Table:关键区别

l简单说:
MySQL 表 = 活着的、可读写的数据库对象
Parquet 文件 = 冻结的、高效的“数据快照”
这也是列存数据与行存数据库最明显的区别!
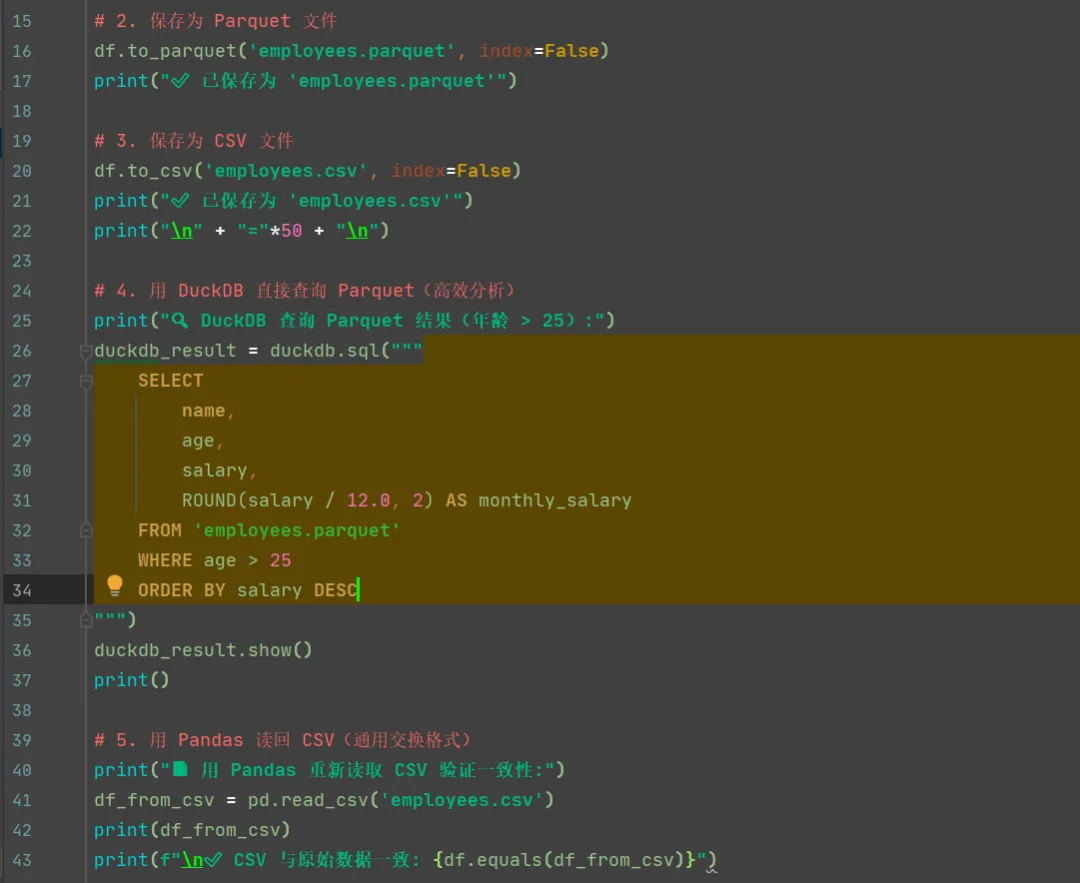
以上程序完成了把df写入duckdb的parquet文件及csv,然后再查询的功能。也就是说python的pandas的df可以直接在duckdb中使用,也可以写入磁盘文件再次调用。这对于数据处理和数据存储、数据查询、数据分析来说简直太方便了。
输出结果如下:
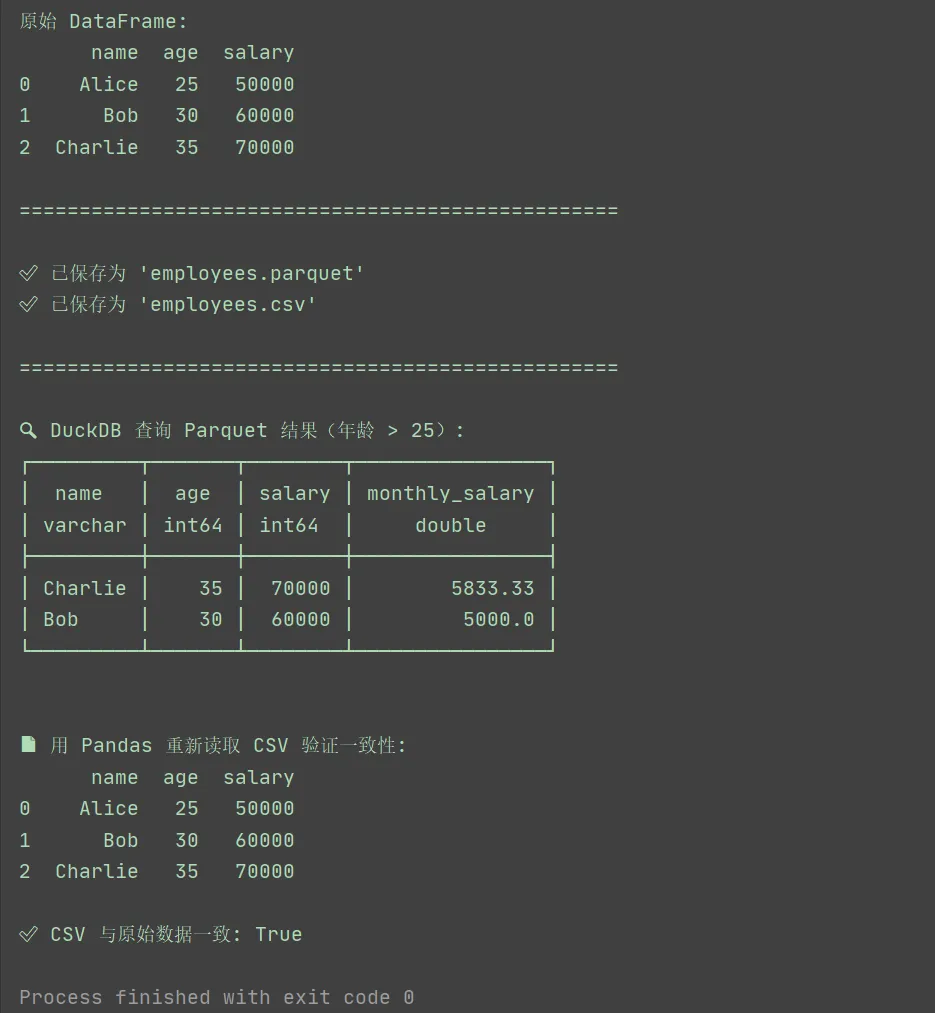
2.5 为什么 duckdb的Parquet 在数据分析中如此流行?
1. 列式存储 → 极省 I/O
假设你有 100 列的数据,但只查 region 和 sales:
CSV/行存:必须读整行(100 列)
Parquet:只读 region 列 + sales 列 → I/O 减少 98%
2. 高压缩比
同一列数据类型相同(如全是整数),压缩率极高
10GB CSV → 可能变成 2GB Parquet
3. 自带元数据(统计信息)
每列保存 min/max/null count
查询引擎可跳过无关数据块(谓词下推)
4. 语言无关 & 生态广泛
Python、Java、C++、Rust 都有读写库
是 数据湖(Data Lake) 的事实标准格式
三、小结
我们今天对数据库知识进行了一个简单整理,在之前的文章中已经用到了多种数据库。这次主要是针对列存数据库的特点进行了总结,并以python编写相关程序代码,让我们了解到duckdb不同于行存数据库的特性。
让我们保持学习热情,多做练习。我们下期再见!


