在Linux设备驱动开发中,并发与竞态是绕不开的核心痛点——尤其是在多核普及、内核调度机制不断优化的当下,稍有疏忽就可能导致数据错乱、系统崩溃等严重问题。本文基于最新的Linux 6.6内核,结合驱动开发实战场景,拆解并发与竞态的本质、常见场景,并明确Linux 6.6中相关机制的变化,帮你快速掌握互斥防护的核心逻辑。
一、核心概念:并发与竞态的本质
先厘清两个基础概念,避免混淆:
并发(Concurrency):多个执行单元(进程、中断、软中断等)在“同一时间段”内被执行,注意Linux 6.6中,并发分为两种场景——SMP架构下多CPU的真正并行,以及单核下“宏观并行、微观串行”的伪并行(由内核抢占、中断切换实现)。简单说,就是“多个任务看似同时在跑”。
竞态(Race Conditions):当多个并发执行单元同时访问共享资源(硬件资源、全局变量、静态变量、设备缓冲区等),且至少有一个执行单元是“写操作”时,就可能出现数据访问冲突,这种冲突就是竞态。竞态的本质是“共享资源的非互斥访问”。
实战示例:globalmem设备的竞态场景
以经典的globalmem字符设备为例,更容易理解竞态的危害。先给出无任何防护的globalmem驱动核心代码(Linux 6.6内核),该代码未做互斥处理,会直接引发前文描述的读写竞态问题:
// Linux 6.6 无防护globalmem驱动(会引发竞态)#include<linux/module.h>#include<linux/fs.h>#include<linux/cdev.h>#include<linux/device.h>#include<linux/uaccess.h>// 1. 定义globalmem设备结构体(无任何互斥锁)structglobalmem_dev {dev_t devid; // 设备号structcdevcdev;// cdev结构体structclass *class;// 设备类structdevice *device;// 设备节点unsignedchar mem[1024*4]; // 设备缓冲区(4KB,共享资源)unsignedint mem_size; // 缓冲区大小,初始化为4KB};structglobalmem_dev *globalmem_devp;// 全局设备指针staticint globalmem_major = 0; // 主设备号,自动分配// 2. read函数(无防护,直接访问共享缓冲区)staticssize_tglobalmem_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos){structglobalmem_dev *dev = filp->private_data;ssize_t ret = 0;// 直接访问共享资源(缓冲区mem),无任何互斥防护if (count > dev->mem_size - *ppos) { count = dev->mem_size - *ppos; }// 内核空间到用户空间拷贝(无防护,可能被中断、其他进程打断)if (copy_to_user(buf, dev->mem + *ppos, count)) { ret = -EFAULT; } else { *ppos += count; ret = count; }return ret;}// 3. write函数(无防护,直接写入共享缓冲区)staticssize_tglobalmem_write(struct file *filp, constchar __user *buf, size_t count, loff_t *ppos){structglobalmem_dev *dev = filp->private_data;ssize_t ret = 0;// 直接访问共享资源(缓冲区mem),无任何互斥防护if (count > dev->mem_size - *ppos) { count = dev->mem_size - *ppos; }// 用户空间到内核空间拷贝(无防护,可能被中断、其他进程打断)if (copy_from_user(dev->mem + *ppos, buf, count)) { ret = -EFAULT; } else { *ppos += count; ret = count; }return ret;}// 4. 文件操作结构体staticconststructfile_operationsglobalmem_fops = { .owner = THIS_MODULE, .read = globalmem_read, .write = globalmem_write,};// 5. 驱动加载函数staticint __init globalmem_init(void){int ret;// 分配设备结构体内存 globalmem_devp = kzalloc(sizeof(struct globalmem_dev), GFP_KERNEL);if (!globalmem_devp) {return -ENOMEM; } globalmem_devp->mem_size = 1024 * 4; // 初始化缓冲区大小// 自动分配设备号 ret = alloc_chrdev_region(&globalmem_devp->devid, 0, 1, "globalmem");if (ret < 0) {goto fail_devid; } globalmem_major = MAJOR(globalmem_devp->devid);// 初始化cdev并注册 cdev_init(&globalmem_devp->cdev, &globalmem_fops); globalmem_devp->cdev.owner = THIS_MODULE; ret = cdev_add(&globalmem_devp->cdev, globalmem_devp->devid, 1);if (ret < 0) {goto fail_cdev; }// 创建类和设备节点 globalmem_devp->class = class_create(THIS_MODULE, "globalmem_class");if (IS_ERR(globalmem_devp->class)) { ret = PTR_ERR(globalmem_devp->class);goto fail_class; } globalmem_devp->device = device_create(globalmem_devp->class, NULL, globalmem_devp->devid, NULL, "globalmem");if (IS_ERR(globalmem_devp->device)) { ret = PTR_ERR(globalmem_devp->device);goto fail_device; } printk(KERN_INFO "globalmem init success (Linux 6.6, no lock)\n");return0;// 错误处理(省略部分冗余逻辑,符合Linux 6.6驱动规范)fail_device: class_destroy(globalmem_devp->class);fail_class: cdev_del(&globalmem_devp->cdev);fail_cdev: unregister_chrdev_region(globalmem_devp->devid, 1);fail_devid: kfree(globalmem_devp);return ret;}// 6. 驱动卸载函数staticvoid __exit globalmem_exit(void){ device_destroy(globalmem_devp->class, globalmem_devp->devid); class_destroy(globalmem_devp->class); cdev_del(&globalmem_devp->cdev); unregister_chrdev_region(globalmem_devp->devid, 1); kfree(globalmem_devp); printk(KERN_INFO "globalmem exit success\n");}module_init(globalmem_init);module_exit(globalmem_exit);MODULE_LICENSE("GPL");MODULE_DESCRIPTION("Linux 6.6 globalmem without lock (race condition example)");
上述代码的问题的核心:read/write函数直接访问共享缓冲区mem,无任何互斥防护,当出现以下场景时,必然引发竞态:
假设存在三个执行单元:A往设备缓冲区写入3000个字符“a”,B往同一缓冲区写入4000个字符“b”,C读取缓冲区所有内容。
具体竞态表现(对应代码逻辑):
若A、B的write操作顺序执行,C的read函数会完整读取A/B写入的内容,逻辑正常;
若A、B的write操作交错执行,比如A执行copy_from_user写入1000个“a”后,被B的write函数抢占,B写入2000个“b”,之后A继续写入剩余2000个“a”,此时C的read函数会读出“a(1000个)+b(2000个)+a(2000个)”的混乱数据,甚至可能读取到未写完整的字符——这就是典型的竞态问题。
注:Linux 6.6中,globalmem这类简单字符设备的竞态的场景未变,但防护机制(如自旋锁、互斥体)的底层实现有优化,后续会详细说明如何通过自旋锁、互斥体修复上述代码的竞态问题。
二、Linux 6.6 中竞态的常见发生场景
Linux内核的竞态场景,核心围绕“并发执行单元的共享资源访问”展开。结合Linux 6.6的内核特性(如无中断嵌套、内核抢占默认开启),主要分为以下4类场景,其中前3类与传统内核一致,第4类是基于新版本的补充。
1. 对称多处理器(SMP)的多核竞态(最常见)
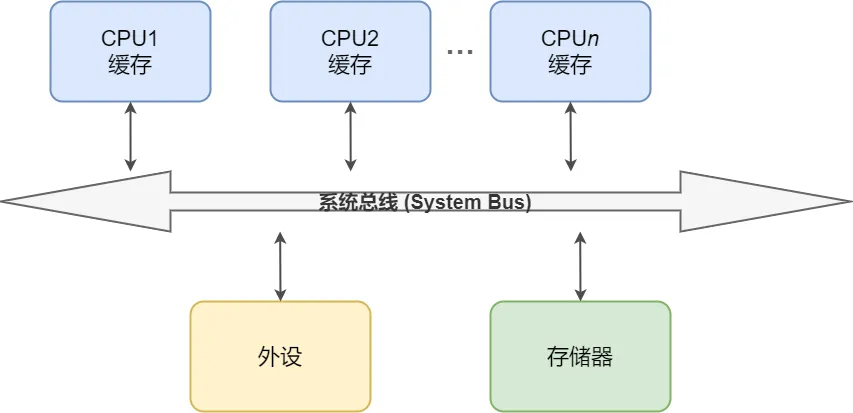
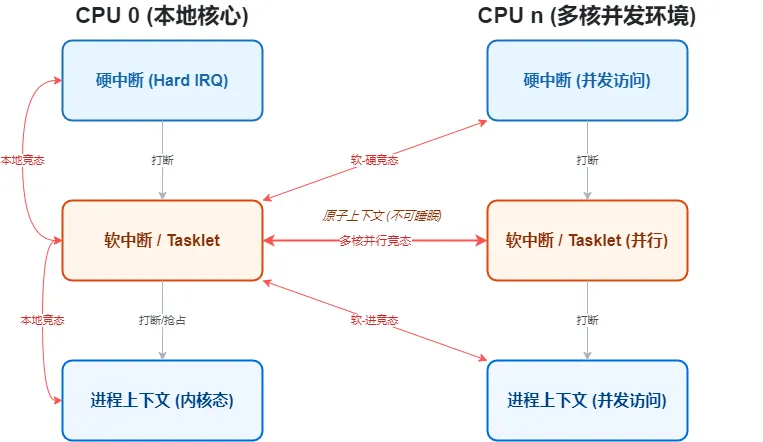
SMP是当前服务器、嵌入式设备的主流架构(如多核ARM、x86服务器),其体系结构如图7.3所示:多个CPU通过系统总线连接,共享外设和存储器——这就意味着,不同CPU上的执行单元,会直接并行访问同一共享资源。
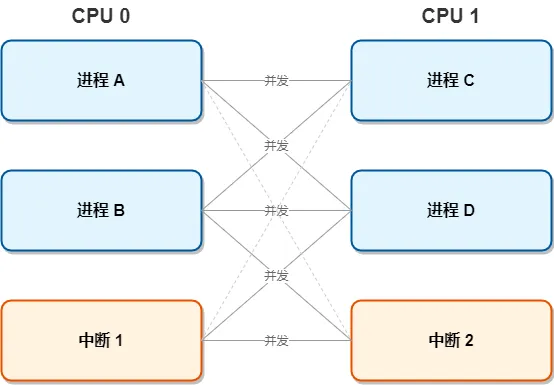
在Linux 6.6中,SMP架构下的多核竞态,主要发生在以下3种组合:
CPU0的进程 ↔ CPU1的进程(如两个用户进程同时操作同一个设备);
CPU0的进程 ↔ CPU1的中断(如进程正在写设备寄存器,另一核的中断触发后也操作该寄存器);
CPU0的中断 ↔ CPU1的中断(如两个核的不同中断,同时访问全局共享的中断状态变量)。
下图清晰展示了SMP下多核之间的竞态关联,只要是图中连线的两个实体,都存在核间并发的可能,进而引发竞态。
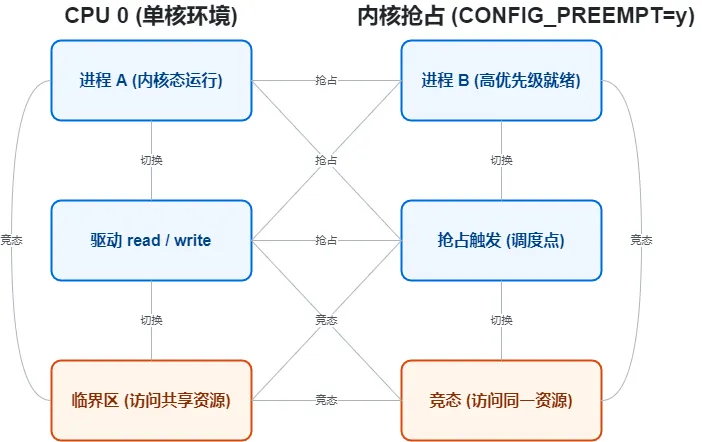
2. 单CPU内的进程抢占竞态
Linux 2.6以后就支持内核抢占,Linux 6.6延续了这一特性,且内核抢占默认开启(除非编译内核时关闭CONFIG_PREEMPT)。
这种场景下,一个进程在内核态执行时(如驱动的read/write函数),可能因为两种原因被抢占:① 时间片耗尽;② 有更高优先级的进程就绪。此时,抢占前的进程和抢占它的进程,若访问同一共享资源,就会引发竞态——其本质和SMP多核竞态一致,只是“并行”变成了单核上的“快速切换”。
补充:Linux 6.6中,内核抢占的触发时机更精细(如在调度点、中断返回时),但对驱动开发者而言,防护逻辑不变,只需关注“临界区的互斥”即可。
3. 中断与进程/其他中断的竞态
中断的核心特性是“可打断正在执行的进程”,这也是竞态的重要来源。结合Linux 6.6的特性,具体分为两种情况:
(1)中断 ↔ 进程:中断服务程序(ISR)会打断正在执行的用户进程或内核进程,若ISR和进程同时访问同一共享资源(如进程写设备缓冲区,ISR也写该缓冲区),就会引发竞态。
(2)中断 ↔ 中断:这里需要重点注意——Linux 6.6中依然不支持中断嵌套(自2.6.35以后就取消了中断嵌套)。也就是说,一个中断正在执行时,不会被更低优先级的中断打断,但会被更高优先级的中断打断吗?
答案是:不会。Linux 6.6中,中断执行期间,会自动屏蔽同CPU上的所有中断(通过本地中断屏蔽字实现),因此同一CPU上的中断之间不会嵌套,也不会引发竞态;但不同CPU上的中断之间,依然可能并发访问共享资源(属于SMP多核竞态的一种)。
补充:旧版本内核中,可通过设置IRQF_DISABLED标记避免中断嵌套,但Linux 6.6中该标记已完全废弃(无用),内核默认禁止中断嵌套,无需开发者额外设置(参考LWN文档《Disabling IRQF_DISABLED》)。
4. 软中断、Tasklet与进程/中断的竞态(Linux 6.6重点关注)
Linux 6.6中,软中断、Tasklet(基于软中断实现)依然是中断底半部的核心机制,它们的执行时机是“中断上下文结束后、进程调度前”,属于原子上下文的一种。
这类竞态主要发生在:
软中断/Tasklet ↔ 进程:软中断执行时,会屏蔽同类型的软中断,但不会屏蔽进程,若软中断和进程访问同一共享资源,会引发竞态;
软中断/Tasklet ↔ 中断:中断会打断软中断的执行(软中断属于原子上下文,但优先级低于硬中断),若两者访问共享资源,会引发竞态;
不同CPU上的软中断之间:可并行执行,访问共享资源时会引发竞态。
三、Linux 6.6 竞态解决方案:互斥访问与临界区防护
解决竞态的核心思路很简单:保证共享资源的互斥访问——即一个执行单元访问共享资源时,禁止其他所有执行单元访问该资源。
关键概念:临界区
访问共享资源的那段代码,称为临界区(Critical Sections)。驱动开发的核心防护动作,就是对临界区进行保护,确保同一时间只有一个执行单元进入临界区。
注意:临界区的范围要“最小化”——只包含访问共享资源的代码,多余的代码(如无关的计算、延时)不要放入临界区,否则会降低系统并发性能(这是Linux 6.6驱动优化的重点之一)。
Linux 6.6 支持的互斥防护机制(驱动常用)
Linux内核提供了多种互斥机制,适配不同的竞态场景。结合Linux 6.6的特性,以下5种是设备驱动中最常用的,重点说明新版本的变化:
1. 中断屏蔽
核心作用:屏蔽当前CPU上的所有中断(硬中断、软中断),避免中断与进程、中断与中断(同CPU)的竞态。
Linux 6.6中常用接口:local_irq_disable()(屏蔽中断)、local_irq_enable()(开启中断),需成对使用。
局限:仅适用于单CPU场景,无法解决SMP多核竞态;且屏蔽中断时间不能过长(会导致系统响应变慢),仅适合短期、快速的临界区(如操作设备寄存器)。
2. 原子操作
核心作用:针对“单个变量”(如计数器、标志位)的读写操作,保证其原子性(不可被打断),避免竞态。
Linux 6.6中,原子操作分为两类:
原子整数操作:如atomic_inc()(自增)、atomic_dec_and_test()(自减并判断是否为0);
原子位操作:如set_bit()(置位)、clear_bit()(清位)、test_bit()(测试位)。
优势:无上下文切换开销,性能最优;局限:仅适用于单个变量,无法保护复杂的临界区(如多句代码、多个变量)。
3. 自旋锁(最常用,重点)
核心作用:基于“忙等待”机制,当一个执行单元获取自旋锁后,其他执行单元会一直循环等待(自旋),直到锁被释放。适用于“临界区执行时间短、CPU资源充足”的场景(如驱动中的中断上下文、多核场景)。
Linux 6.6中,自旋锁的核心变化:
默认禁止内核抢占:获取自旋锁后,内核会自动禁止当前CPU的内核抢占(避免同一CPU上的进程抢占导致死锁);
支持中断安全自旋锁:如spin_lock_irq()(获取锁并屏蔽中断)、spin_unlock_irq()(释放锁并开启中断),用于保护“中断与进程/软中断”的临界区;
废弃旧接口:spin_lock_irqsave()/spin_unlock_irqrestore()在Linux 6.6中依然可用,但推荐使用更简洁的接口(如spin_lock_irq()),除非需要保存中断屏蔽字。
注意:自旋锁不能在进程上下文的睡眠函数(如msleep())中使用,否则会导致死锁(自旋锁忙等待时,无法调度,睡眠函数无法执行)。
4. 信号量
核心作用:基于“阻塞等待”机制,当一个执行单元获取信号量失败时,会进入睡眠状态(放弃CPU),直到信号量被释放后被唤醒。适用于“临界区执行时间长、CPU资源紧张”的场景(如用户进程上下文的驱动函数)。
Linux 6.6中,信号量的接口无重大变化,常用接口:down()(获取信号量,可中断)、up()(释放信号量)。
优势:不浪费CPU资源;局限:不能在中断上下文(如ISR)中使用(中断上下文不能睡眠)。
5. 互斥体(推荐,替代信号量)
核心作用:专门用于“互斥访问”,是信号量的简化版本(仅允许一个执行单元获取锁),在Linux 6.6中,互斥体已成为进程上下文的首选防护机制。
Linux 6.6中互斥体的优势:
接口简洁:mutex_lock()(获取锁)、mutex_unlock()(释放锁),成对使用;
死锁检测:内核会自动检测互斥体的死锁场景,并输出日志(方便调试);
适配进程上下文:支持睡眠,适合长临界区;也可通过mutex_lock_interruptible()支持可中断等待。
注意:互斥体同样不能在中断上下文使用,若需在中断上下文与进程上下文共享资源,需结合自旋锁。
实战代码:globalmem驱动中自旋锁与互斥体的应用(Linux 6.6)
以下基于Linux 6.6内核,给出globalmem字符设备驱动的核心代码片段,分别实现自旋锁(适配中断+进程上下文)和互斥体(适配进程上下文)的防护,解决前文提到的缓冲区读写竞态问题。
1. 自旋锁实现(适配中断+进程上下文,短临界区)
适用场景:globalmem缓冲区读写操作简单(短临界区),且存在中断上下文(如中断服务程序读写缓冲区)与进程上下文的竞态,采用Linux 6.6推荐的spin_lock_irq()/spin_unlock_irq()接口。
// 1. 定义globalmem设备结构体(包含自旋锁和缓冲区)structglobalmem_dev {dev_t devid; // 设备号structcdevcdev;// cdev结构体structclass *class;// 设备类structdevice *device;// 设备节点unsignedchar mem[1024*4]; // 设备缓冲区(4KB)spinlock_t spinlock; // 自旋锁(Linux 6.6默认非调试版本)};structglobalmem_dev *globalmem_devp;// 全局设备指针// 2. 驱动加载函数(初始化自旋锁)staticint __init globalmem_init(void){int ret;// 初始化自旋锁(Linux 6.6推荐spin_lock_init,替代旧版SPIN_LOCK_UNLOCKED) spin_lock_init(&globalmem_devp->spinlock);// 设备号、cdev、类和设备节点初始化(省略,与常规驱动一致)// ...return0;}// 3. read函数(进程上下文,自旋锁防护)staticssize_tglobalmem_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos){structglobalmem_dev *dev = filp->private_data;ssize_t ret = 0;// 进入临界区:获取自旋锁并屏蔽当前CPU中断(Linux 6.6推荐接口) spin_lock_irq(&dev->spinlock);// 临界区:访问共享资源(缓冲区mem),仅包含必要操作(临界区最小化)if (count > dev->mem_size - *ppos) { count = dev->mem_size - *ppos; }// 内核空间到用户空间拷贝(避免在临界区做多余计算)if (copy_to_user(buf, dev->mem + *ppos, count)) { ret = -EFAULT; } else { *ppos += count; ret = count; }// 退出临界区:释放自旋锁并开启当前CPU中断 spin_unlock_irq(&dev->spinlock);return ret;}// 4. 中断服务程序(ISR,自旋锁防护,与进程上下文共享缓冲区)staticirqreturn_tglobalmem_irq_handler(int irq, void *dev_id){structglobalmem_dev *dev = (structglobalmem_dev *)dev_id;// 进入临界区:ISR中使用自旋锁,同样屏蔽中断(与read函数接口一致) spin_lock_irq(&dev->spinlock);// 临界区:中断中写缓冲区(共享资源),仅做必要的写入操作 dev->mem[0] = 0x01; // 示例:中断触发时,往缓冲区首地址写标记 dev->irq_flag = 1; // 共享标志位(原子操作也可实现,此处演示自旋锁)// 退出临界区:释放自旋锁并开启中断 spin_unlock_irq(&dev->spinlock);return IRQ_HANDLED;}// 驱动卸载函数(省略,无需额外释放自旋锁,内核自动回收)staticvoid __exit globalmem_exit(void){// ... 设备注销、类销毁等操作}module_init(globalmem_init);module_exit(globalmem_exit);MODULE_LICENSE("GPL");
2. 互斥体实现(适配进程上下文,长临界区)
适用场景:globalmem缓冲区读写操作复杂(长临界区,如包含数据解析、多步写入),仅存在进程上下文的竞态(无中断参与),采用Linux 6.6推荐的互斥体接口,支持死锁检测。
// 1. 定义globalmem设备结构体(替换自旋锁为互斥体)structglobalmem_dev {dev_t devid; // 设备号structcdevcdev;// cdev结构体structclass *class;// 设备类structdevice *device;// 设备节点unsignedchar mem[1024*4]; // 设备缓冲区(4KB)structmutexmutex;// 互斥体(Linux 6.6默认支持死锁检测)};structglobalmem_dev *globalmem_devp;// 全局设备指针// 2. 驱动加载函数(初始化互斥体)staticint __init globalmem_init(void){int ret;// 初始化互斥体(Linux 6.6推荐mutex_init,替代旧版DEFINE_MUTEX) mutex_init(&globalmem_devp->mutex);// 设备号、cdev、类和设备节点初始化(省略,与常规驱动一致)// ...return0;}// 3. write函数(进程上下文,互斥体防护,长临界区)staticssize_tglobalmem_write(struct file *filp, constchar __user *buf, size_t count, loff_t *ppos){structglobalmem_dev *dev = filp->private_data;ssize_t ret = 0;// 进入临界区:获取互斥体(可中断等待,适合进程上下文)// 若需不可中断等待,使用mutex_lock(&dev->mutex)if (mutex_lock_interruptible(&dev->mutex)) {return -ERESTARTSYS; // 被信号中断,返回重启系统调用 }// 临界区:复杂写入操作(长临界区,适合互斥体,支持睡眠)if (count > dev->mem_size - *ppos) { count = dev->mem_size - *ppos; }// 1. 用户空间到内核空间拷贝if (copy_from_user(dev->mem + *ppos, buf, count)) { ret = -EFAULT; } else {// 2. 复杂数据处理(示例:将写入的数据转为大写,模拟长操作)int i;for (i = 0; i < count; i++) {if (dev->mem[*ppos + i] >= 'a' && dev->mem[*ppos + i] <= 'z') { dev->mem[*ppos + i] -= 32; } } *ppos += count; ret = count; }// 退出临界区:释放互斥体 mutex_unlock(&dev->mutex);return ret;}// 4. read函数(与write函数一致,互斥体防护,省略重复代码)// static ssize_t globalmem_read(...) { ... }// 驱动卸载函数(省略)staticvoid __exit globalmem_exit(void){// ... 设备注销、类销毁等操作}module_init(globalmem_init);module_exit(globalmem_exit);MODULE_LICENSE("GPL");
代码关键说明(贴合Linux 6.6特性)
自旋锁:使用Linux 6.6推荐的spin_lock_irq()/spin_unlock_irq(),替代旧版spin_lock_irqsave(),无需手动保存中断屏蔽字(简化接口);初始化使用spin_lock_init(),避免使用废弃的宏定义。
互斥体:使用mutex_init()初始化,支持内核死锁检测(Linux 6.6默认开启CONFIG_MUTEX_DEBUG_SUPPORT,调试时可快速定位死锁问题);进程上下文推荐使用mutex_lock_interruptible(),支持信号中断,提升系统稳定性。
临界区最小化:自旋锁临界区仅包含缓冲区读写和必要判断,互斥体虽支持长临界区,但也避免多余操作,符合Linux 6.6驱动性能优化要求。
场景适配:自旋锁适配“中断+进程”上下文,互斥体适配纯进程上下文,对应前文讲解的机制选型原则,避免滥用导致性能损耗。
四、Linux 6.6 驱动开发实战建议
结合前文的场景和机制,给大家3条实战建议,避免踩坑:
先判断竞态场景,再选防护机制:比如多核场景+短临界区,用自旋锁;进程上下文+长临界区,用互斥体;单个变量,用原子操作。
临界区最小化:这是Linux 6.6驱动性能优化的重点,比如读取设备状态后,立即释放锁,避免在锁持有期间做无关计算。
避免使用废弃接口:如IRQF_DISABLED、旧版自旋锁接口,优先使用Linux 6.6推荐的接口(如spin_lock_irq()、mutex_lock()),减少兼容性问题。
五、总结
Linux 6.6的并发与竞态,本质上和传统内核一致——核心是“共享资源的非互斥访问”,但在细节上有优化(如中断嵌套的彻底禁止、自旋锁接口简化、互斥体性能提升)。
对驱动开发者而言,掌握竞态的核心场景,记住“临界区最小化”和“场景匹配机制”两个原则,就能轻松应对大部分竞态问题。
附:参考资料
Linux 6.6内核源码(kernel/sched/、kernel/locking/目录);
LWN文档《Disabling IRQF_DISABLED》(https://lwn.net/Articles/380931/);
《Linux设备驱动开发详解》(基于Linux 6.x修订版)。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
