如何用 Python 全栈技术栈实现 Palantir 核心的'本体建模(Ontology)'逻辑
- 2026-07-04 03:53:27
如何用 Python 全栈技术栈实现 Palantir 核心的'本体建模(Ontology)'逻辑告别臃肿:Python全栈+AI,正在重塑企业的“数字化骨骼” 选择Python全栈还是Java全栈? 要理解如何用 Python 实现 Palantir 的Ontology(本体建模),首先要明白它与传统数据库开发的核心区别:传统开发是“面向表(Table)”的,而 Ontology 是“面向对象(Object)”的。 在 Palantir Foundry 中,Ontology 将杂乱的原始数据(ERP、Excel、日志)抽象为真实世界的实体(如:零件、订单、员工)及其相互关系。 以下是利用 Python 全栈技术栈实现这一逻辑的架构方案:
要实现本体建模,你的 Python 后端不能直接把数据库字段丢给前端,而是需要一个“语义层”。 工具:Pandas / PySpark 逻辑:利用 Python 的数据处理能力,从不同的异构数据源(发票 OCR 结果、WCS 数据库、BOM Excel)中清洗数据。 目标:将“原始数据”转化为“干净的行”。 这是最关键的一步。你需要使用 Python 的类(Class)和装饰器(Decorator)来定义业务对象。 技术栈:Pydantic + SQLAlchemy / Tortoise-ORM 逻辑:*对象化:不再叫 table_invoice,而是定义一个 class Invoice。 工具:FastAPI + Vue.js 逻辑:前端不再请求特定的 SQL 查询,而是请求“对象”。例如:GET /objects/Invoice/123,返回的不只是基础数据,还有它关联的所有节点。
我们可以利用 Python 的类型系统来模拟 Palantir 的对象建模: 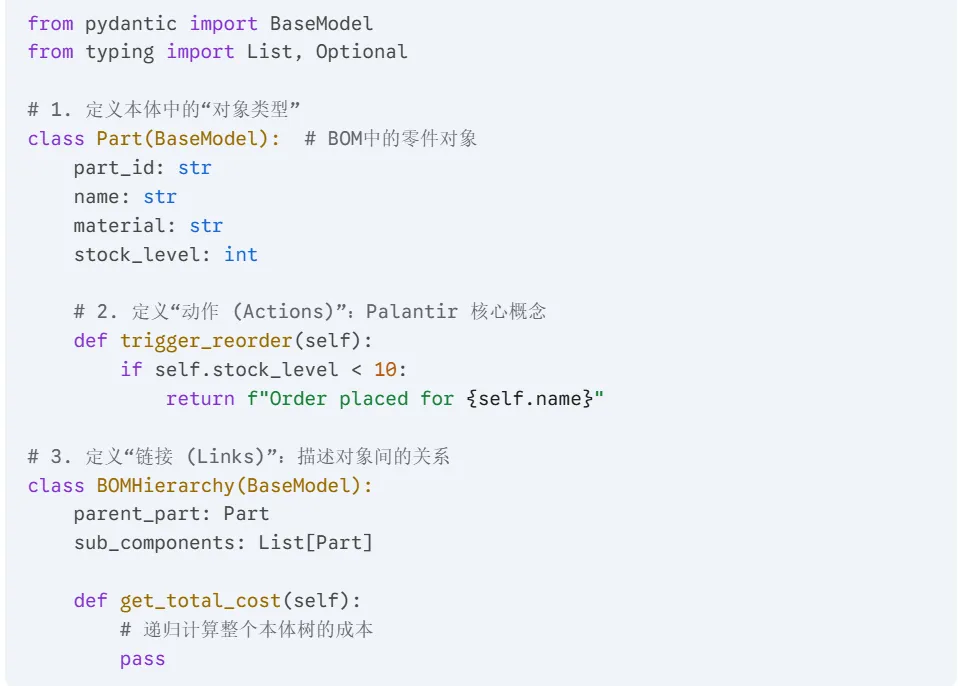
场景:发票管理与 BOM 自动对账 在 Palantir 逻辑下,一个“全栈 Python 工程师”会这样构建系统: 对象定义:在 Python 中建立 Invoice 对象和 BOM_Item 对象。 AI 增强属性:使用 Python 调用 OCR 库(如 PaddleOCR),将图片转化为 Invoice 对象的属性。 本体关联:逻辑脚本自动寻找 Invoice.supplier_id 与 BOM_Item.provider 的关联。 前端呈现:使用 Vue + RelationGraph 插件,将这些关系以“知识图谱”的形式展示,而不是枯燥的表格。
胶水特性:Python 能轻易调用机器学习库(处理发票 OCR)和数学优化库(处理 BOM 排产),并将这些结果直接封装进“本体对象”中。 开发效率:相比 Java,Python 的 FastAPI 或 Django 能以极快的速度完成业务对象的增删改查和逻辑定义,符合 Palantir“前线部署(Forward Deployed)”快速迭代的要求。 数据科学无缝对接:当你需要做销量预测时,你的模型可以直接读取“本体对象”,而不需要重新写复杂的 SQL 关联。 “未来的企业管理系统不再是单纯的增删改查。像 Palantir 一样,用 Python 重新定义你的‘业务本体’,让每一行代码都直接对应现实中的零件、订单和决策。这就是 Python 全栈工程师给企业带来的降维打击。” 2026:IT行业已死,但“生产力红利”才刚刚爆发
1. 核心架构:三层转换模型
A. 数据集成层 (Data Integration)
B. 本体映射层 (Ontology Mapping) —— 核心所在
C. 消费层 (Application/API)
2. Python 代码实现思路(简化版)
3. 关键组件:如何落地到业务场景
4. 为什么 Python 全栈是最佳选择?
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

