超全的Python基础作图 | 散点/折线/柱状/箱线图/热图
- 2026-07-03 23:19:43
超全的Python基础作图 | 散点/折线/柱状/箱线图/热图
讲师招募 | 免费数据资源 |最新最热

柱状图excel中的格式 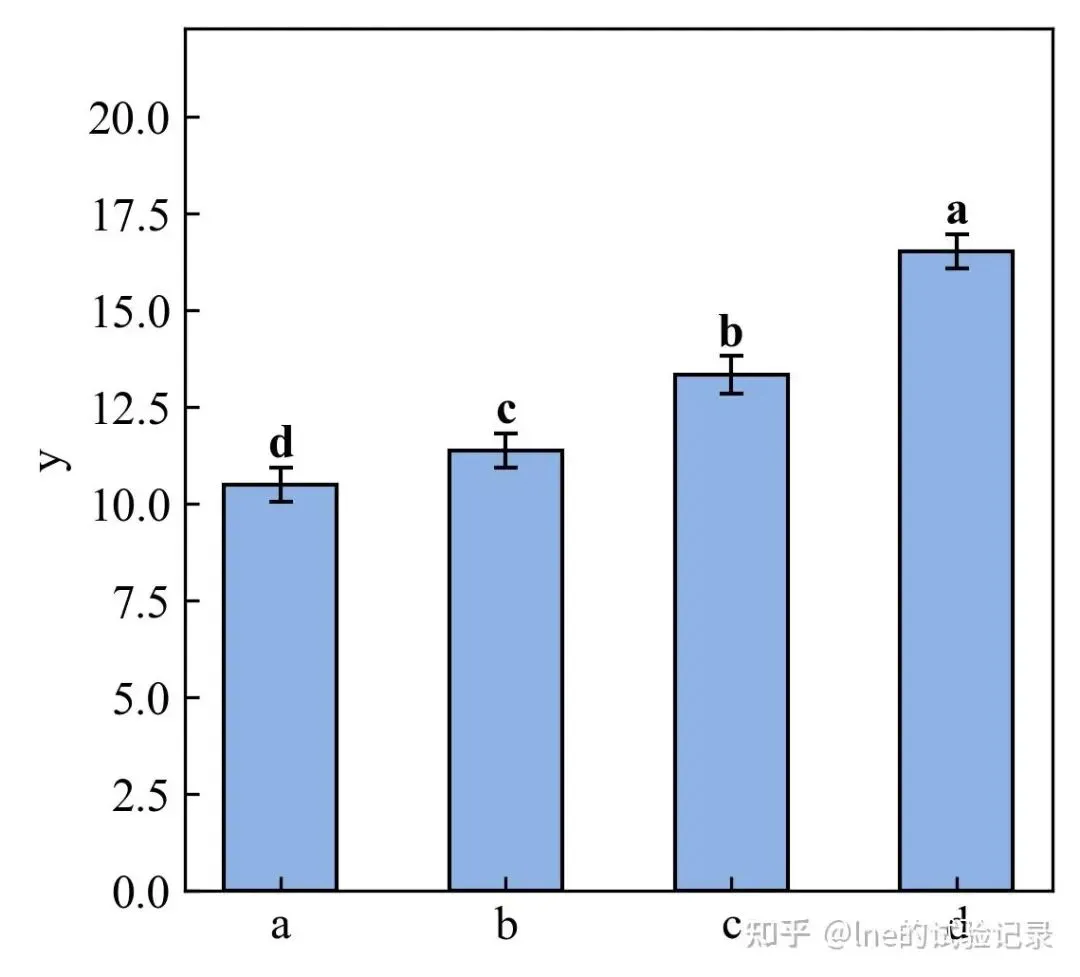
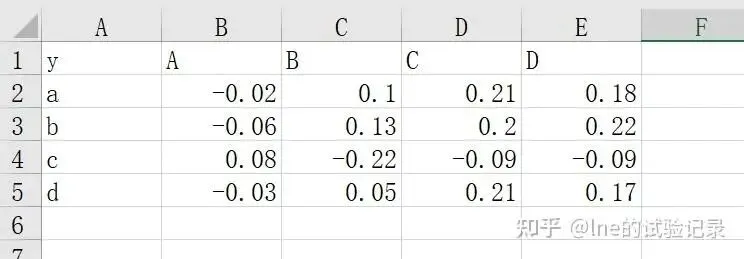
热图数据格式 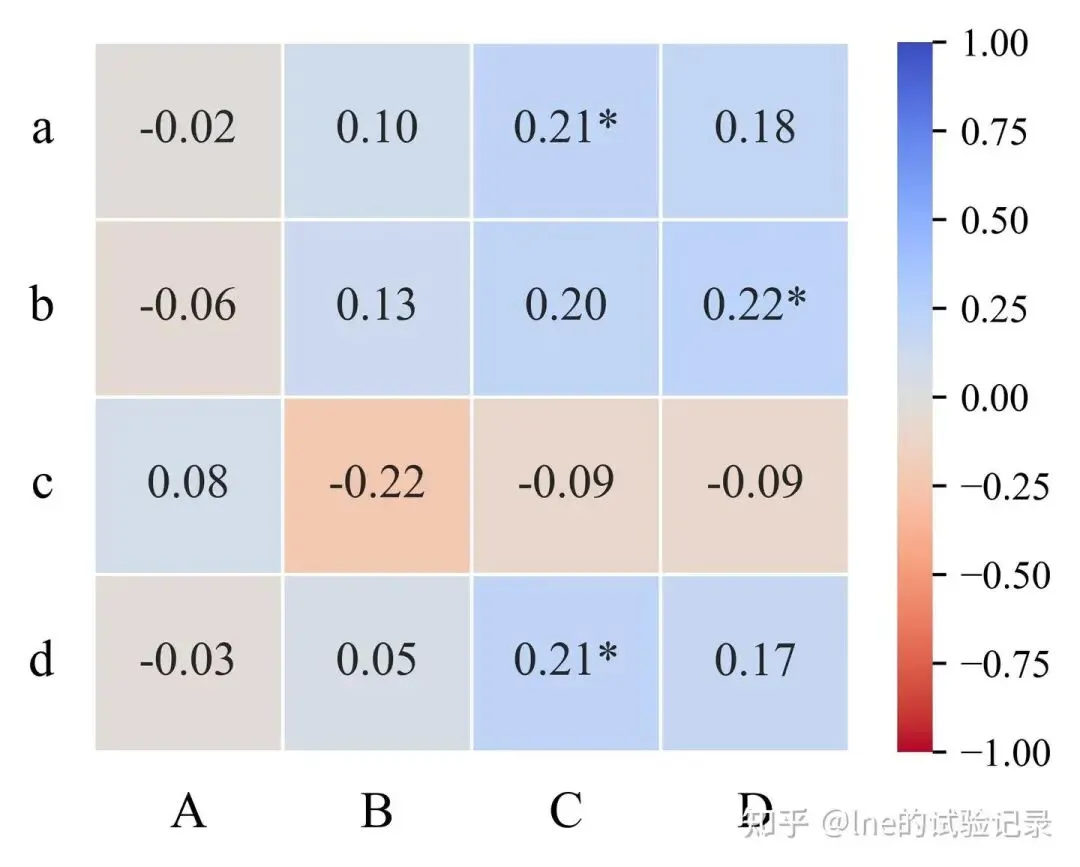
原文链接: Python基础作图 | 超全的,拿去直接用?!!----散点/折线/柱状/箱线图/热图 - 知乎 来源:【lne的试验记录】的知乎文章。内容仅做学术分享之用,不代表本号观点,版权归原作者所有,若涉及侵权等行为,请联系我们删除,万分感谢! 



推荐阅读 1、农林生态、大气、遥感、水文等系统教程通道——点击文末"阅读全文"进入 2、地学领域数据、年鉴、地图、课件资料等免费资源下载——点击进入 3、百余门教程在线免费观看——点击文末"阅读全文"进入 4、会员超值福利领取——点击文末"阅读全文"进入 如何加快课题组人才梯队建设与人才培养? 
Ai尚研修长期招募讲师——诚邀您的加入 扫描下方二维码,关注我们 

Ai尚研修客服 
公众号 
| 课程安排 |
| 最新AI-Python自然科学领域机器学习与深度学习技术高级培训班 | |
| 高水平学术论文写作的“破局”之道暨AI人机协同从前沿选题挖掘、智能写作工程、顶刊图表可视化、到精准选刊投稿与审稿博弈策略的一站式实践高级培训班 | |
1、散点图
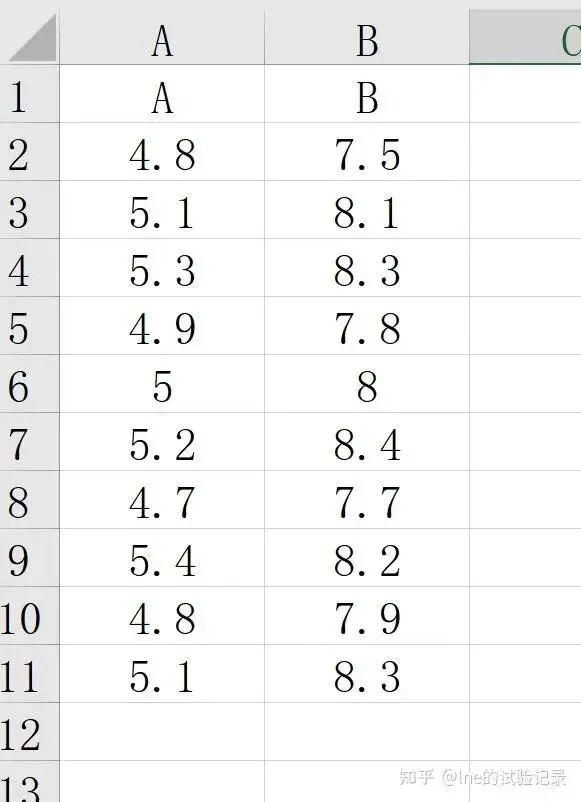
excel中所用数据
1.1 散点图+回归线
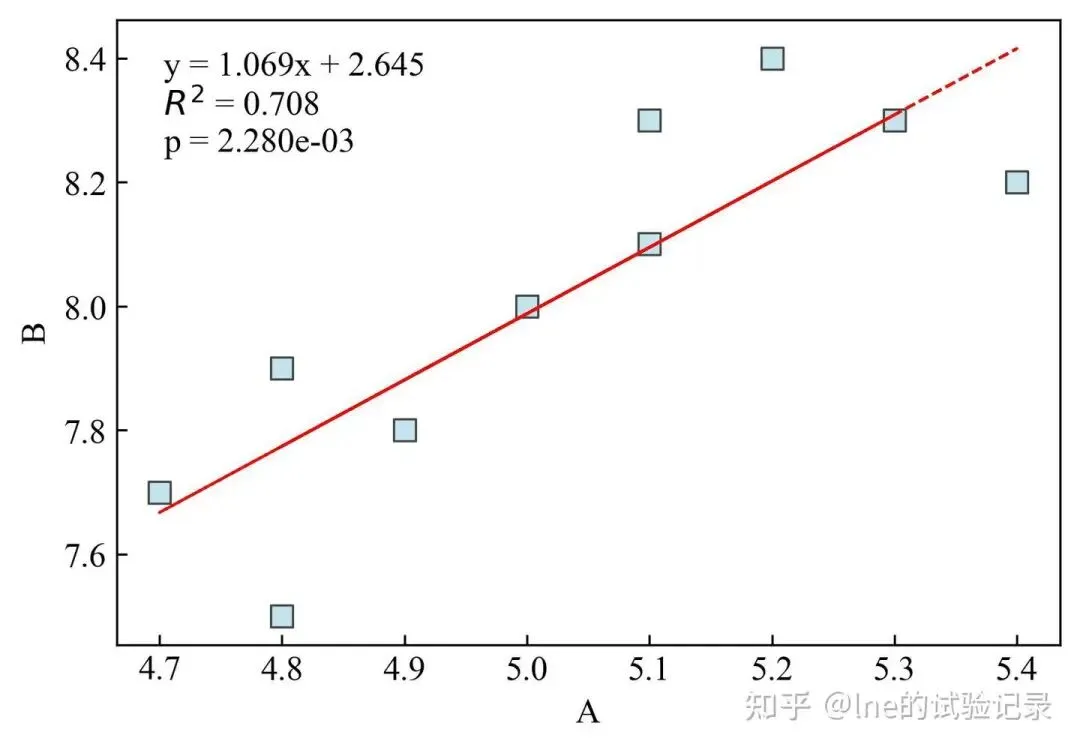
importmatplotlib.pyplotaspltimportnumpyasnpimportpandasaspdfromscipyimportstatsfromstatsmodels.stats.multicompimportpairwise_tukeyhsdimportseabornassns# 字体设置plt.rcParams.update({'font.sans-serif':['SimSun'],'font.family':['Times New Roman'],'axes.unicode_minus':False})# plt.rcParams['For Sale Page'] = ['Times New Roman', 'SimSun']# excel数据读取file_path=r'F:\知乎\2025.12基础绘图\data.xlsx'sheet_name='散点图'df=pd.read_excel(file_path,sheet_name=sheet_name,skiprows=0)x,y=df['A'],df['B']# 画布设置fig,ax=plt.subplots(figsize=(15/2.54,10/2.54))# 单位 inch# 绘制散点ax.scatter(x,y,s=60,marker='s',color='lightblue',alpha=0.7,edgecolor='black',linewidths=0.8)# 计算回归参数slope,intercept,r_value,p_value,std_err=stats.linregress(x,y)y_pred=slope*x+intercept# 绘制回归线ax.plot(x,y_pred,color='red',linewidth=1,linestyle='--')# 添加回归方程和 R²、p 值textstr=(f"y = {slope:.3f}x + {intercept:.3f}\n"f"$R^2$ = {r_value**2:.3f}\n"f"p = {p_value:.3e}")ax.text(0.05,0.95,textstr,transform=ax.transAxes,fontsize=12,verticalalignment='top',bbox=dict(facecolor='white',alpha=0.6,edgecolor='none'))ax.tick_params(axis='both',labelsize=12,direction='in')ax.set_xlabel('A',fontsize=12)ax.set_ylabel('B',fontsize=12)ax.legend(frameon=False)# 保存图片plt.savefig('散点图-带回归线.jpg',dpi=300,bbox_inches='tight',facecolor='white')plt.show()1.2 散点图+回归线+置信区间
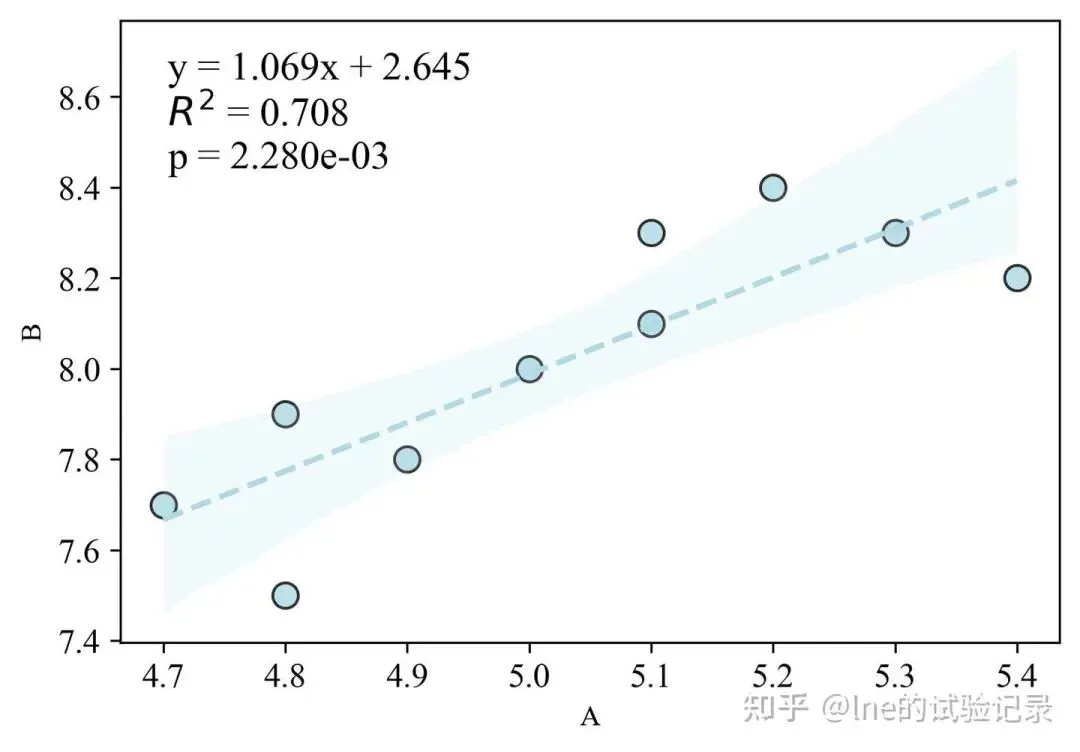
importmatplotlib.pyplotaspltimportnumpyasnpimportpandasaspdfromscipyimportstatsfromstatsmodels.stats.multicompimportpairwise_tukeyhsdimportseabornassns# 字体设置plt.rcParams.update({'font.sans-serif':['SimHei'],'font.family':['Times New Roman'],'axes.unicode_minus':False})# excel数据读取file_path=r'F:\知乎\基础绘图\data.xlsx'sheet_name='散点图'df=pd.read_excel(file_path,sheet_name=sheet_name,skiprows=0)x,y=df['A'],df['B']# 画布设置fig,ax=plt.subplots(figsize=(15/2.54,10/2.54))sns.regplot(x=x,y=y,ci=95,ax=ax,scatter_kws={'s':80,'color':'lightblue','marker':'o','edgecolor':'black'},line_kws={'color':'lightblue','linewidth':2,'linestyle':'--'})ax.tick_params(axis='both',labelsize=12)slope,intercept,r_value,p_value,std_err=stats.linregress(x,y)textstr=(f"y = {slope:.3f}x + {intercept:.3f}\n"f"$R^2$ = {r_value**2:.3f}\n"f"p = {p_value:.3e}")# 添加回归方程 ax.text(0.05,0.95,textstr,transform=ax.transAxes,fontsize=14,verticalalignment='top',bbox=dict(facecolor='white',alpha=0.6,edgecolor='none'))plt.savefig('散点图置信区间加回归方程.jpg',dpi=300,bbox_inches='tight',facecolor='white')plt.show()2、折线图
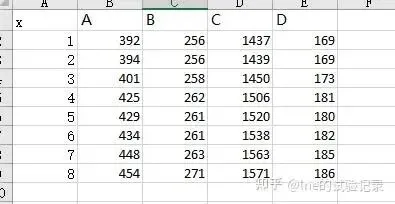
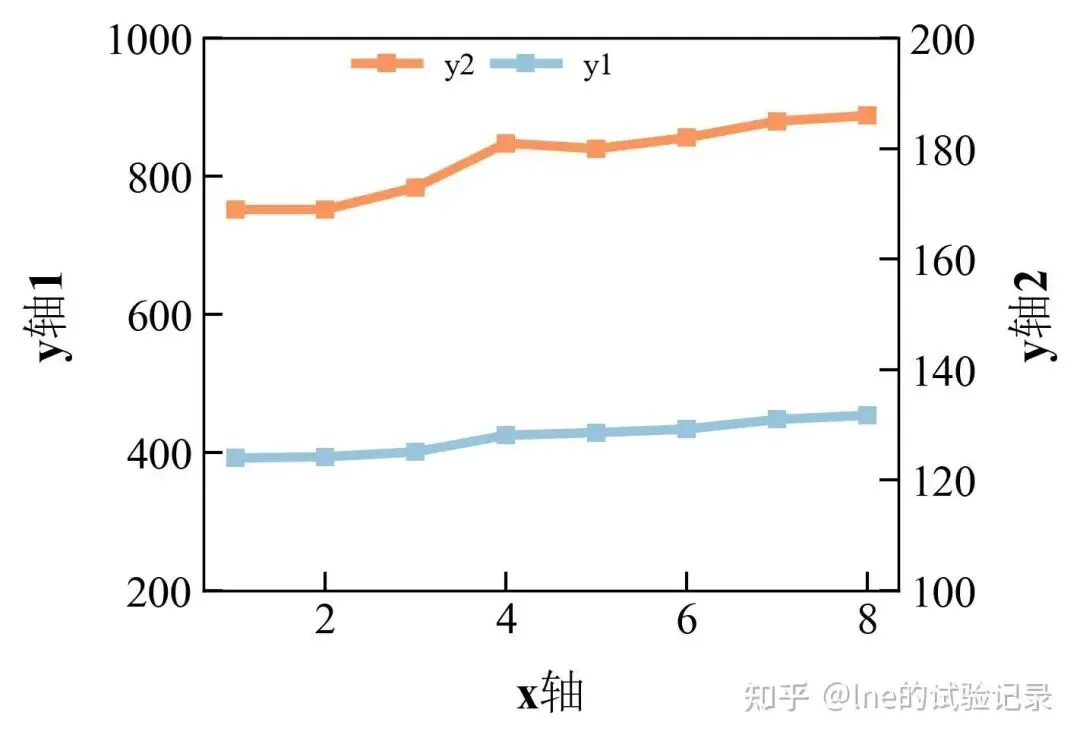
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom scipy import statsfrom statsmodels.stats.multicomp import pairwise_tukeyhsdimport seaborn as sns# 字体设置plt.rcParams['font.family'] = ['Times New Roman', 'SimSun']plt.rcParams['axes.unicode_minus'] = Falsefile_path = r'F:\知乎\基础绘图\data.xlsx'sheet_name = "折线图"df = pd.read_excel(file_path, sheet_name=sheet_name, skiprows=0)x, y1,y2 = df['x'], df['A'],df['D']fig, ax = plt.subplots(figsize=(10/2.54, 8/2.54))ax1 = ax.twinx() #双y轴设置ax.plot(x,y1,label="y1", linewidth=3, marker='s', markersize=5, color="#97c3dd")ax1.plot(x,y2,label="y2", linewidth=3, marker='s', markersize=5, color="#fc945d")ax.set_ylabel("y轴1", labelpad=10, size=15, fontweight='bold')ax1.set_ylabel("y轴2", labelpad=10, size=15, fontweight='bold')ax.set_xlabel("x轴", labelpad=10, size=15, fontweight='bold')ax1.set_ylim(100,200)ax.set_ylim(200,1000)for ax in [ax1, ax]: ax.tick_params(axis='both', direction='in', length=6, width=1, labelsize=14)ax.legend( loc=(0.4,0.9),frameon=False,ncol=4,labelspacing=1.2)ax1.legend( loc=(0.2,0.9),frameon=False,ncol=4,labelspacing=1.2)plt.savefig('双坐标轴折线图.jpeg', dpi=300, bbox_inches='tight')3、柱状图
3.1 简单柱状图+误差线
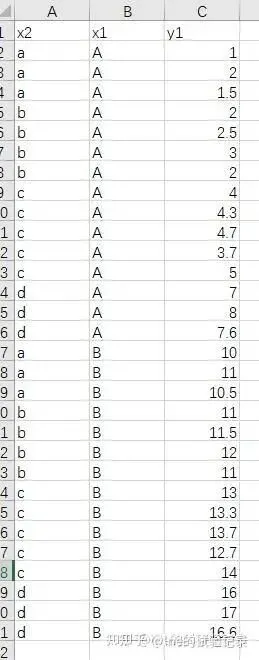
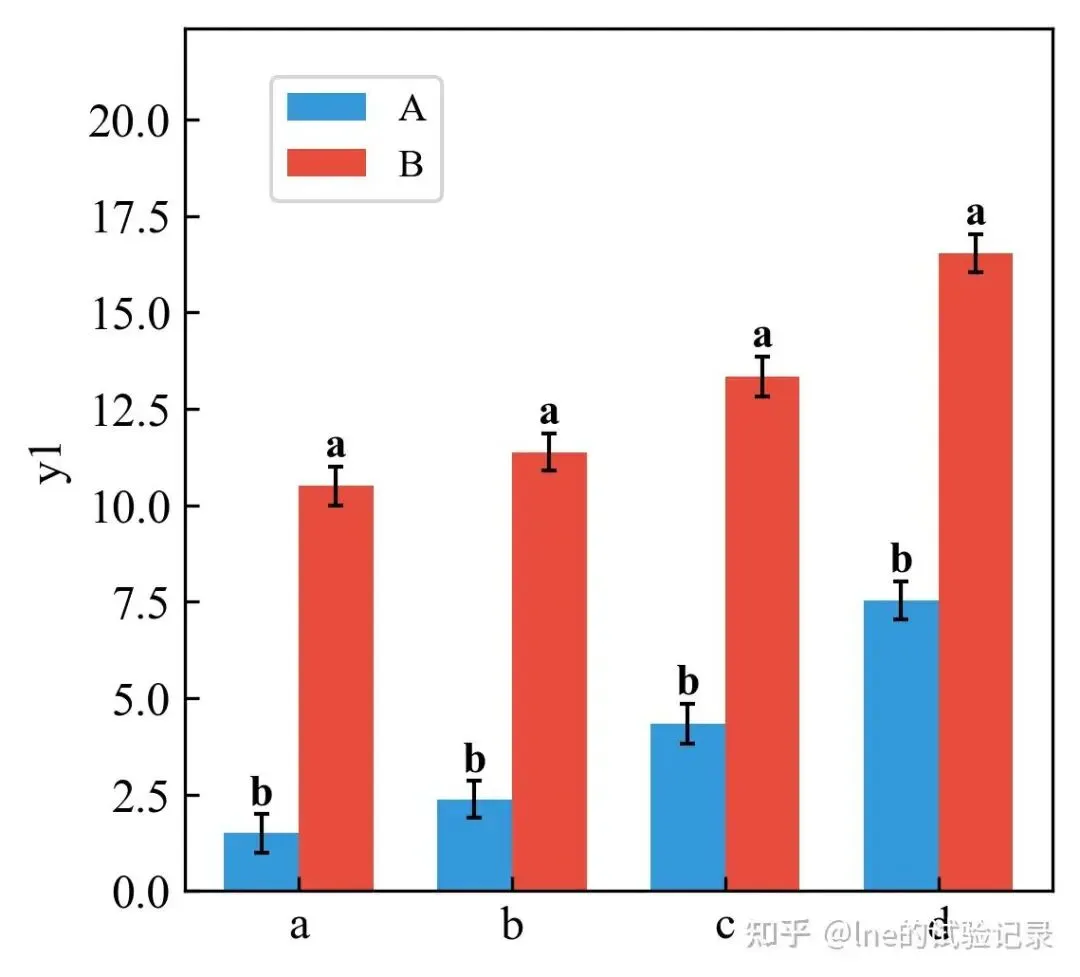
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom statsmodels.stats.multicomp import pairwise_tukeyhsdplt.rcParams['axes.unicode_minus'] = Falseplt.rcParams['font.family'] = ['Times New Roman', 'SimSun']X_VAR = 'x2'Y_VAR = 'y'file_path =r'F:\知乎\基础绘图\data.xlsx'data = pd.read_excel(file_path, sheet_name='柱状图', skiprows=0)stats_df = data.groupby(X_VAR)[Y_VAR].agg(['mean', 'std'])x_categories = stats_df.index.tolist()means = stats_df['mean'].valuesstds = stats_df['std'].valuesx = np.arange(len(x_categories))plt.figure(figsize=(10/2.54, 10/2.54))plt.bar( x, means, yerr=stds, capsize=3, width=0.5, color='#8FB2E5', edgecolor='black', error_kw={'elinewidth': 1, 'capthick': 1})plt.xticks(x, x_categories, fontsize=12)plt.ylabel(Y_VAR, fontsize=12)plt.tick_params(direction='in', labelsize=12)def tukey_cld_strict(tukey, means): sorted_groups = means.sort_values(ascending=False).index.tolist() all_groups = list(tukey.groupsunique) sig = pd.DataFrame( np.zeros((len(all_groups), len(all_groups)), dtype=bool), index=all_groups, columns=all_groups ) k = 0 for i in range(len(all_groups) - 1): for j in range(i + 1, len(all_groups)): g1 = all_groups[i] g2 = all_groups[j] sig.loc[g1, g2] = tukey.reject[k] sig.loc[g2, g1] = tukey.reject[k] k += 1 letters = {} current_letter = 'a' for g in sorted_groups: placed = False for letter, gs in letters.items(): if all(not sig.loc[g, gg] for gg in gs): gs.append(g) placed = True break if not placed: letters[current_letter] = [g] current_letter = chr(ord(current_letter) + 1) result = {} for letter, gs in letters.items(): for g in gs: result.setdefault(g, '') result[g] += letter return resulttukey = pairwise_tukeyhsd( endog=data[Y_VAR], groups=data[X_VAR], alpha=0.05)means_for_letters = data.groupby(X_VAR)[Y_VAR].mean()letters = tukey_cld_strict(tukey, means_for_letters)for i, group in enumerate(x_categories): plt.text( x[i], means[i] + stds[i], letters[group], ha='center', va='bottom', fontsize=12, fontweight='bold' )ylim = plt.ylim()plt.ylim(ylim[0], ylim[1] * 1.25)plt.savefig('简单柱状图_Tukey显著性.png', dpi=300, bbox_inches='tight')plt.show()3.2 分组柱状图
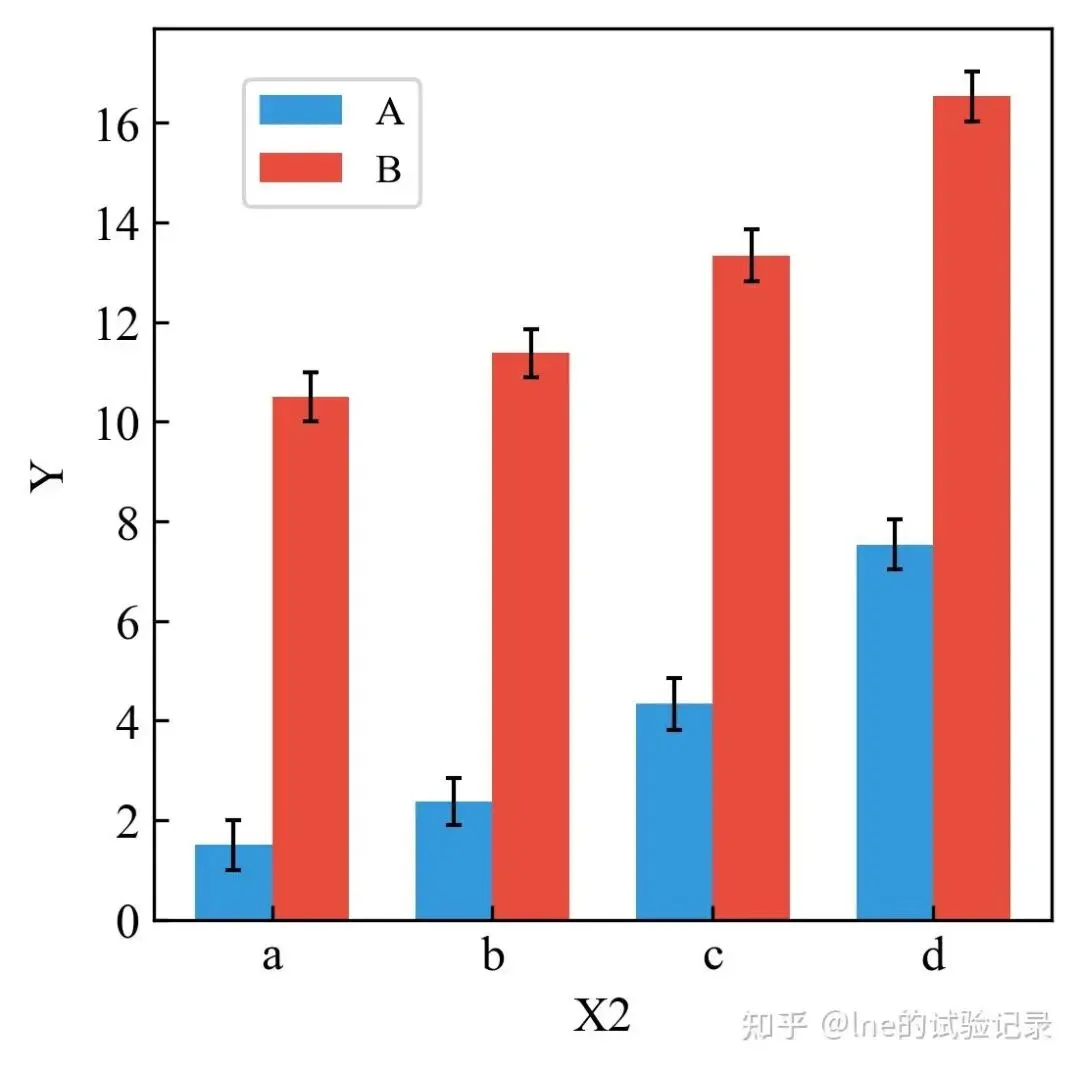
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom scipy import statsfrom statsmodels.stats.multicomp import pairwise_tukeyhsdfrom matplotlib.font_manager import FontPropertiesplt.rcParams['axes.unicode_minus'] = Falsefont = FontProperties(fname='C:/Windows/Fonts/simkai.ttf')file_path = r'F:\知乎\基础绘图\data.xlsx'data = pd.read_excel(file_path, sheet_name='柱状图', skiprows=0)agg_data = data.groupby(['x2', 'x1'])['y1'].agg(['mean', 'std']).unstack()x2_categories = agg_data.index.tolist()x1_categories = agg_data.columns.levels[1].tolist()bar_width = 0.35index = np.arange(len(x2_categories))width_cm = 10height_cm = 10width, height = width_cm / 2.54, height_cm / 2.54plt.figure(figsize=(width, height))bar_colors = ['#3498db', '#e74c3c']for i, x1 in enumerate(x1_categories): means = agg_data[('mean', x1)] stds = agg_data[('std', x1)] plt.bar( index + i * bar_width, means, bar_width, color=bar_colors[i], yerr=stds, capsize=2, label=f'{x1}', error_kw={'ecolor': 'black', 'capthick': 1, 'elinewidth': 1} ) plt.tick_params( axis='both', labelsize=12, labelcolor='black', direction='in' )plt.xlabel('X2', fontsize=12)plt.ylabel('Y', fontsize=12)plt.xticks(index + bar_width / 2, x2_categories, fontsize=12)plt.legend(loc=(0.1, 0.8), fontsize=10)plt.savefig('分组柱状图-误差棒.png', dpi=300, bbox_inches='tight')plt.show()3.3 柱状图+误差线+显著性分析
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom statsmodels.stats.multicomp import pairwise_tukeyhsdplt.rcParams['axes.unicode_minus'] = FalseX_MAIN = 'x2'X_GROUP = 'x1'Y_VAR = 'y1'file_path = r'F:\知乎\基础绘图\data.xlsx'data = pd.read_excel(file_path, sheet_name='柱状图', skiprows=0)agg_data = ( data .groupby([X_MAIN, X_GROUP])[Y_VAR] .agg(['mean', 'std']) .unstack())x2_categories = agg_data.index.tolist()x1_categories = agg_data.columns.get_level_values(1).unique().tolist()bar_width = 0.35index = np.arange(len(x2_categories))bar_colors = ['#3498db', '#e74c3c']plt.figure(figsize=(10/2.54, 10/2.54))for i, x1 in enumerate(x1_categories): means = agg_data[('mean', x1)] stds = agg_data[('std', x1)] plt.bar( index + i * bar_width, means, bar_width, color=bar_colors[i], yerr=stds, capsize=2, label=f'{x1}', error_kw={'ecolor': 'black', 'elinewidth': 1, 'capthick': 1} )plt.xticks(index + bar_width / 2, x2_categories, fontsize=12)plt.ylabel(Y_VAR, fontsize=12)plt.legend(loc=(0.1, 0.8), fontsize=10)plt.tick_params(direction='in', labelsize=12)def tukey_cld_strict(tukey, means): sorted_groups = means.sort_values(ascending=False).index.tolist() all_groups = list(tukey.groupsunique) sig = pd.DataFrame( np.zeros((len(all_groups), len(all_groups)), dtype=bool), index=all_groups, columns=all_groups ) k = 0 for i in range(len(all_groups) - 1): for j in range(i + 1, len(all_groups)): g1 = all_groups[i] g2 = all_groups[j] sig.loc[g1, g2] = tukey.reject[k] sig.loc[g2, g1] = tukey.reject[k] k += 1 letters = {} current_letter = 'a' for g in sorted_groups: placed = False for letter, gs in letters.items(): if all(not sig.loc[g, gg] for gg in gs): gs.append(g) placed = True break if not placed: letters[current_letter] = [g] current_letter = chr(ord(current_letter) + 1) result = {} for letter, gs in letters.items(): for g in gs: result.setdefault(g, '') result[g] += letter return resultletters_dict = {}for x2 in x2_categories: sub = data[data[X_MAIN] == x2] tukey = pairwise_tukeyhsd( endog=sub[Y_VAR], groups=sub[X_GROUP], alpha=0.05 ) means = sub.groupby(X_GROUP)[Y_VAR].mean() cld = tukey_cld_strict(tukey, means) for x1, letter in cld.items(): letters_dict[(x2, x1)] = letterfor x2_idx, x2 in enumerate(x2_categories): for i, x1 in enumerate(x1_categories): mean = agg_data[('mean', x1)][x2] std = agg_data[('std', x1)][x2] letter = letters_dict[(x2, x1)] plt.text( index[x2_idx] + i * bar_width, mean + std, letter, ha='center', va='bottom', fontsize=11, fontweight='bold' )ylim = plt.ylim()plt.ylim(ylim[0], ylim[1] * 1.25)plt.savefig('分组柱状图-显著性分析.png', dpi=300, bbox_inches='tight')plt.show()4、热图
importpandasaspdimportseabornassnsimportmatplotlib.pyplotaspltimportnumpyasnpimportreplt.rcParams['font.family']=['Times New Roman','SimSun']# 绘图时优先使用 Times New Roman,如果没有,再使用 SimSun。file_path=r'F:\知乎\基础绘图\data.xlsx'df_raw=pd.read_excel(file_path,sheet_name='热图',header=0)defconvert_number(x):ifisinstance(x,str):x=x.strip()# 匹配括号内数字ifre.match(r'^\(\s*[\d\.]+\s*\)$',x):return-float(x.replace('(','').replace(')',''))# 普通数字try:returnfloat(x)except:returnnp.nanreturnxdf=df_raw.copy()df.iloc[:,1:]=df.iloc[:,1:].applymap(convert_number)# 从第二列开始转换数字# 字体设置plt.rcParams['font.family']='Times New Roman'tick_labels={'fontsize':13,'fontname':'Times New Roman','color':'black'}fontdict_labels={'fontsize':13,'fontname':'Times New Roman','color':'black','fontweight':'bold'}threshold1=0.2threshold2=0.3defannotate_value(x):ifpd.isna(x):return""ifx>threshold2:returnf"{x:.2f}**"elifx>threshold1:returnf"{x:.2f}*"else:returnf"{x:.2f}"annot_df=df.iloc[:,1:].applymap(annotate_value)width_cm=10height_cm=8width,height=width_cm/2.54,height_cm/2.54fig,ax=plt.subplots(1,1,figsize=(width,height))# 热图数据(不包含第一列标签)sns.heatmap(df.iloc[:,1:],ax=ax,annot=annot_df,fmt="",vmin=-1,vmax=1,cmap="coolwarm_r",cbar=True,xticklabels=df.columns[1:],annot_kws={"size":12},linewidths=0.6)# 设置 X 和 Y 轴标签ax.set_xticklabels(df.columns[1:],rotation=0,ha='center',fontdict=tick_labels)ax.set_yticklabels(df.iloc[:,0],rotation=0,ha='right',fontdict=tick_labels)ax.tick_params(axis='both',which='both',length=0,pad=10)# Y 轴标题ax.set_ylabel('',fontdict=fontdict_labels,labelpad=10)plt.tight_layout()plt.savefig(r'热图输出.jpg',dpi=500,bbox_inches='tight',pad_inches=0.1)plt.show()5、箱线图
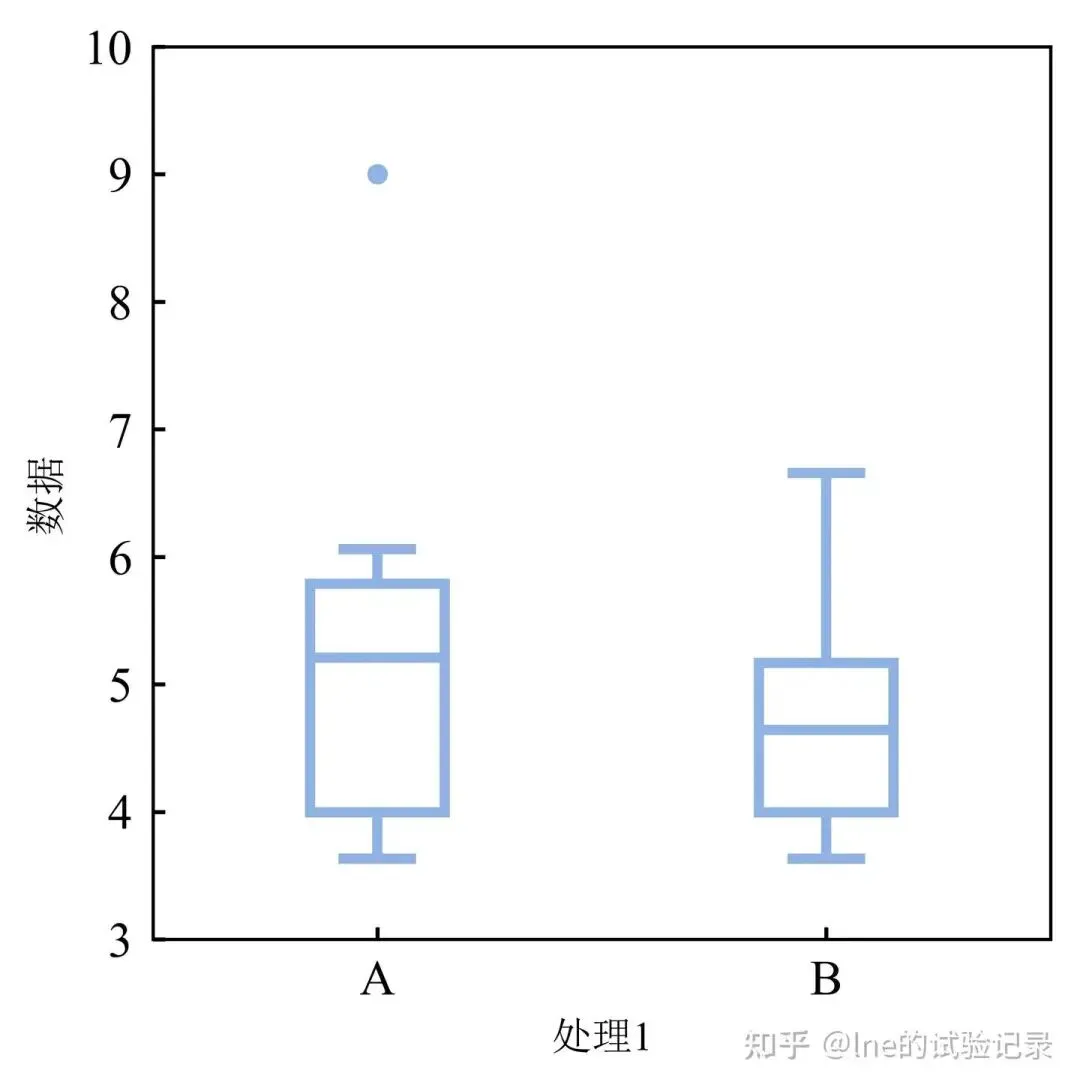
分组箱线图参考:Python - 箱线图/分组箱线图
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltplt.rcParams['font.family'] = ['Times New Roman', 'SimSun']plt.rcParams['axes.unicode_minus'] = Falsefile_path = r'F:\知乎\基础绘图\data.xlsx'df = pd.read_excel(file_path, sheet_name='箱线图', skiprows=0)width_cm = 10height_cm = 10width, height = width_cm / 2.54, height_cm / 2.54fig, ax = plt.subplots(figsize=(width, height), sharex=True)sns.boxplot( x=df['处理1'], y=df['数据'], data=df, ax=ax, width=0.3, linewidth=0.5, boxprops=dict(facecolor='none', edgecolor='#8FB2E5', linewidth=2.5), medianprops=dict(color='#8FB2E5', linewidth=2.5), capprops=dict(color='#8FB2E5', linewidth=2.5), whiskerprops=dict(color='#8FB2E5', linewidth=2.5), flierprops=dict( marker='o', markerfacecolor='#8FB2E5', markersize=4, markeredgecolor='#8FB2E5' ))ax.tick_params( axis='both', which='both', length=3, color='black', pad=5, direction='in', width=1, labelsize=10, labelcolor='black', rotation=0)ax.set_xticklabels(ax.get_xticklabels(), fontsize=12)ax.set_yticklabels(ax.get_yticklabels(), fontsize=12)ax.set_ylim(3, 10)plt.savefig('箱线图.jpeg', dpi=800, bbox_inches='tight')plt.show()版权声明
| AI多领域融合课程、论文写作、科研绘图类 |
4月10日-11日、 17日-18日 | |
3月28日-29日、 4月4日-5日 | |
高水平学术论文写作的“破局”之道暨AI人机协同从前沿选题挖掘、智能写作工程、顶刊图表可视化、到精准选刊投稿与审稿博弈策略的一站式实践高级培训班 |
| 农林生态、水文、气象、遥感 |
2月11日-14日 | |
| 3月20日-21日、27日-28日 | 面向科研与产业的智慧农林核心遥感技术与AI实战:99案例精讲(空天地)多源数据预处理、高光谱AI智能精准提取、多模态模型构建、不确定性分析、WebGIS平台开发及高水平科研论文撰写全流程培训班 |
4月4日-5日 |
| 统计、语言、人工智能类 |
| 最新AI-Python自然科学领域机器学习与深度学习技术高级培训班 | |
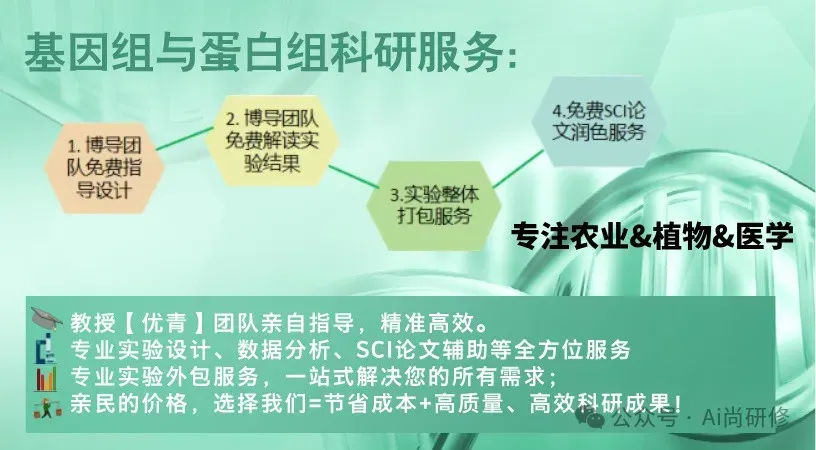
科研技术服务
快来Ai尚研修【Easy Scientific Research】点亮科研简学践行-您的随行导师平台
官 网:www.aishangyanxiu.com;
公众号:关注“Ai尚研修”公众号,点击“Ai尚课堂”进入也可以哦!
Ai尚研修,倾力打造您的专属发展道路,这里有丰富的客户资源,专业的授课平台,强大的推广力度,全员的热血支持!
Ai尚研修期待您的加入,共同打造精品课程,助力科研!
结束
声明: 本号旨在传播、传递、交流,对相关文章内容观点保持中立态度。涉及内容如有侵权或其他问题,请与本号联系,第一时间做出撤回。
结束
Ai尚研修丨专注科研领域
技术推广,人才招聘推荐,科研活动服务
科研技术云导师,Easy cientfic Research
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

