假设你有一个 materials.xlsx,里面有 Name, E, Nu, Rho 四列。
import pandas as pd
import hm
import hm.entities as ent
# 1. 读取 Excel (只需一行代码!)
# df 就是那个“内存里的 Excel”
df = pd.read_excel("D:/project/materials.xlsx")
print(f"成功读取 {len(df)} 种材料")
# 2. 遍历每一行,创建材料
# iterrows() 允许你逐行访问数据
model = hm.Model()
for index, row in df.iterrows():
# 创建材料 (假设 create_mat 是我们封装好的函数)
mat = ent.Material(model, name=row['Name'])
mat.E = row['E']
mat.Nu = row['Nu']
mat.Rho = row['Rho']
print("所有材料创建完毕!")
没有 open,没有 close,没有 COM 对象。干净利落。
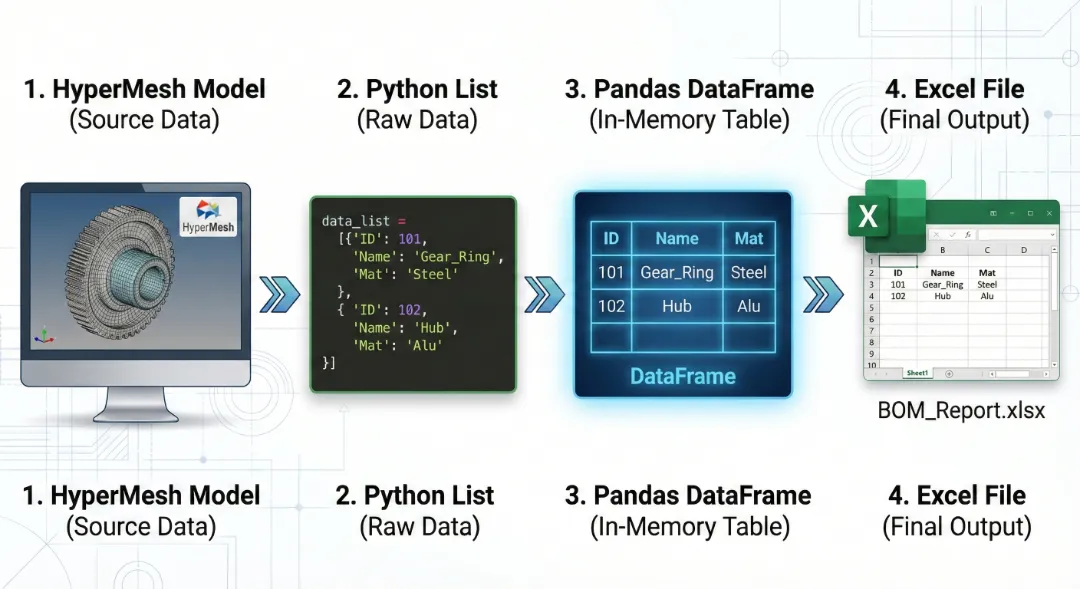
3.写入:生成 BOM 表 (Bill of Materials)
这是更常见的场景。我们需要统计模型里所有部件的信息,导出给设计部门。
关键技巧:先存列表,再转 Pandas不要在循环里写 Excel,那样太慢。
把数据存成 Python 字典列表 (List of Dicts)。
把列表转成 Pandas DataFrame。
保存为 Excel。
# 1. 准备一个空列表
data_list = []
comps = hm.Collection(model, ent.Component)
# 2. 收集数据 (这一步还在 HyperMesh 里)
for comp in comps:
# 把单个部件的信息打包成一个字典
info = {
"ID": comp.id,
"Name": comp.name,
"Color": comp.color,
"Element_Count": len(comp.elements) # 假设这是我们要统计的
}
data_list.append(info)
# 3. 转换为 Pandas DataFrame
df_result = pd.DataFrame(data_list)
# 4. 导出 Excel (又是一行代码!)
# index=False 表示不要那一列自动生成的序号
df_result.to_excel("D:/project/Model_BOM.xlsx", index=False)
既然数据进了 Pandas,你就不需要在 Excel 里做透视表了,Python 更快。
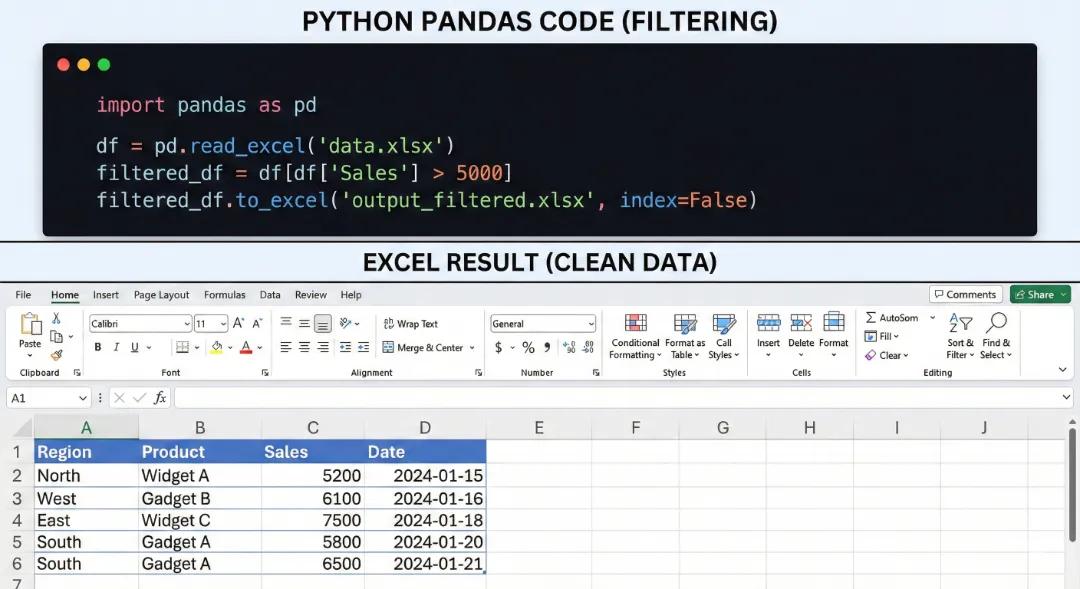
# 需求:找出所有单元数量大于 1000 的红色部件
# 1. 筛选 (Filtering)
# 语法直观:df[条件]
big_comps = df_result[df_result['Element_Count'] > 1000]
# 2. 统计 (Statistics)
# 按颜色分组统计平均单元数
avg_by_color = df_result.groupby('Color')['Element_Count'].mean()
print(avg_by_color)
数据 IO 是自动化的“最后一公里”。
使用 Pandas,你不仅是在操作 Excel,你是在进行数据科学处理。
Read: pd.read_excel 瞬间读取。
Process: 利用 DataFrame 进行筛选、统计。
Write: to_excel 一键导出。
掌握了这一期,你就打通了 HyperMesh 与外部世界的任督二脉。
👉 下期预告:
现在的脚本已经功能强大、界面美观、还能读写数据。但它还只是躺在你硬盘里的一个 .py 文件。
怎么把它变成 HyperMesh 界面上一个固定的按钮?怎么做成一个工具条 (Ribbon) 分发给全组同事使用?
下一期,我们将进入 《部署篇:自定义你的工具栏》,教你把脚本“安装”进 HyperMesh,打造专属的工作环境!