字数 3953,阅读大约需 20 分钟
油藏动态分析很多时候不是“缺方法”,而是“缺速度”。
你可能遇到过这种场景:
- • 领导临时问一句:“最近产量掉得快,是递减变陡了还是注水跟不上?”
- • 资料室给你一堆 Excel:日产油/日产液/含水/注水/井口压力/静压……
- • 你脑子里有一整套诊断套路,但真正卡在:数据清洗 + 指标计算 + 出图 + 写结论 太耗时间。
所以我写了一个“油藏动态快诊断”脚本:
输入一份标准化的生产数据表,自动输出——
✅ 核心 KPI(产量、含水、WOR、GOR、累计、移动平均、递减率等)
✅ 典型图(q-t、含水-t、WOR-t、累计-t、压力-t、VRR-t、诊断散点)
✅ 递减分析(Arps:指数/双曲/调和,自动拟合并给参数)
✅ VRR(Voidage Replacement Ratio,注采比)快评估
✅ 异常点提示(突变、离群、异常递减段)
✅ 自动生成 summary.md(一页纸结论)+ outputs/*.png
目标不是替代完整数值模拟/地质工程工作,而是:在 10 秒内把“动态状态”摸清楚,给下一步深入分析定方向。
1. 数据格式(最小可用)
脚本读取 CSV(或 Excel 另存 CSV),至少包含这些列(列名可按脚本要求):
只要数据自洽(同一单位体系),脚本就能跑。没气、没压力、没注水也没关系:脚本会自动跳过相关图和指标。
2. 快诊断逻辑:我们到底在看什么?
2.1 先把“状态”量化成几个最硬的指标
- • 液量 qL、油量 qO、含水 fw、WOR(水油比)
- • VRR = 注入 / 采出(用体积近似做快评估)
- • VRR < 1:大概率补给不足 / 压力支撑弱
- • VRR > 1:可能过注/窜流风险(要结合含水和压力)
2.2 递减分析(Arps)做“快定性”
脚本自动拟合三种 Arps 形式:
输出:qi、Di、b、拟合误差(RMSE),并把拟合曲线叠在产量图上。
注意:递减分析更适用于相对稳定制度下的生产段。脚本会默认用“后段数据”拟合,避免早期爬坡干扰。
2.3 异常点提示:把“需要人盯”的位置标出来
- • 递减率异常段
这些不是结论,只是提醒你:这里值得深挖(工艺/停井/措施/窜流/计量问题等)。
3. 使用方式(两行命令)
pip install pandas numpy matplotlib
python fast_reservoir_dynamics.py --input data.csv --outdir outputs
如果你没有数据,脚本还支持生成一份模拟样例数据(用于试跑):
python fast_reservoir_dynamics.py --demo --outdir outputs
4. 输出长什么样?
运行后你会得到:
- •
outputs/plots_rate.png:油/水/液产量随时间 - •
outputs/plots_watercut.png:含水、WOR - •
outputs/plots_cum.png:累计曲线 - •
outputs/plots_pressure.png(若有压力) - •
outputs/plots_vrr.png(若有注水) - •
outputs/decline_fit.png:递减拟合叠图 - •
outputs/summary.md:一页纸结论(可直接贴汇报)
5. 源码(可直接复制运行)
文件名建议:fast_reservoir_dynamics.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
fast_reservoir_dynamics.py
一个脚本实现油藏快速动态分析(生产/注水/压力快诊断 + 递减拟合 + 自动出图 + 结论摘要)
依赖:
pip install pandas numpy matplotlib
用法:
python fast_reservoir_dynamics.py --input data.csv --outdir outputs
python fast_reservoir_dynamics.py --demo --outdir outputs
输入 CSV 至少包含:
date, oil_rate, water_rate
可选:
gas_rate, inj_rate, pres
单位要求:
自洽即可(m3/d 或 bbl/d 都行),脚本不做单位换算。
"""
import argparse
import os
import math
from dataclasses import dataclass
from typing import Dict, Optional, Tuple
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# -----------------------------
# Utils
# -----------------------------
def ensure_outdir(outdir: str) -> None:
os.makedirs(outdir, exist_ok=True)
def safe_div(a, b):
a = np.asarray(a, dtype=float)
b = np.asarray(b, dtype=float)
out = np.full_like(a, np.nan, dtype=float)
mask = np.abs(b) > 1e-12
out[mask] = a[mask] / b[mask]
return out
def rolling_mean(s: pd.Series, window: int) -> pd.Series:
return s.rolling(window=window, min_periods=max(3, window // 3)).mean()
def rmse(y_true, y_pred) -> float:
y_true = np.asarray(y_true, dtype=float)
y_pred = np.asarray(y_pred, dtype=float)
mask = np.isfinite(y_true) & np.isfinite(y_pred)
if mask.sum() == 0:
return float("inf")
return float(np.sqrt(np.mean((y_true[mask] - y_pred[mask]) ** 2)))
def robust_zscore(x: np.ndarray) -> np.ndarray:
x = np.asarray(x, dtype=float)
med = np.nanmedian(x)
mad = np.nanmedian(np.abs(x - med)) + 1e-12
return 0.6745 * (x - med) / mad
# -----------------------------
# Decline Curve Analysis (Arps)
# -----------------------------
@dataclass
class DeclineFit:
model: str # "exp" | "hyper" | "harm"
qi: float
Di: float
b: float
rmse: float
def arps_rate(t: np.ndarray, qi: float, Di: float, b: float) -> np.ndarray:
"""
Arps:
b=0 -> exponential: q = qi * exp(-Di*t)
b=1 -> harmonic : q = qi / (1 + Di*t)
else hyperbolic : q = qi / (1 + b*Di*t)^(1/b)
"""
t = np.asarray(t, dtype=float)
qi = max(qi, 1e-12)
Di = max(Di, 1e-12)
if abs(b) < 1e-10:
return qi * np.exp(-Di * t)
if abs(b - 1.0) < 1e-10:
return qi / (1.0 + Di * t)
return qi / np.power(1.0 + b * Di * t, 1.0 / b)
def fit_arps_grid(t: np.ndarray, q: np.ndarray, prefer_tail: float = 0.7) -> Dict[str, DeclineFit]:
"""
不依赖 scipy,使用简单网格搜索拟合 b + Di,qi 用首点近似微调。
适合“快诊断”:稳健、够用、跑得快。
"""
t = np.asarray(t, dtype=float)
q = np.asarray(q, dtype=float)
mask = np.isfinite(t) & np.isfinite(q) & (q > 0)
t = t[mask]
q = q[mask]
if len(t) < 12:
return {}
# 使用后段数据拟合(避免早期爬坡/制度变化)
n = len(t)
start = int(max(0, math.floor((1 - prefer_tail) * n)))
t_fit = t[start:] - t[start]
q_fit = q[start:]
# 初值
qi0 = float(np.nanmax(q_fit[:3]))
qi0 = max(qi0, 1e-6)
# Di 搜索范围:按经验用 1e-5 ~ 5 (按 t 单位而定)
# 这里根据 t 的跨度自适应缩放
tspan = float(np.nanmax(t_fit) - np.nanmin(t_fit) + 1e-12)
# 如果 t 是天,tspan ~ 1000-3000;如果是月,tspan ~ 60-120
# 用 1/tspan 作为典型 Di 量级
Di_center = 1.0 / max(tspan, 1.0)
Di_grid = np.logspace(np.log10(Di_center / 50), np.log10(Di_center * 50), 60)
results: Dict[str, DeclineFit] = {}
# 1) Exponential (b=0)
best = (float("inf"), None)
for Di in Di_grid:
q_pred = arps_rate(t_fit, qi0, Di, 0.0)
e = rmse(q_fit, q_pred)
if e < best[0]:
best = (e, (qi0, Di))
if best[1]:
qi, Di = best[1]
results["exp"] = DeclineFit("exp", qi=qi, Di=Di, b=0.0, rmse=best[0])
# 2) Harmonic (b=1)
best = (float("inf"), None)
for Di in Di_grid:
q_pred = arps_rate(t_fit, qi0, Di, 1.0)
e = rmse(q_fit, q_pred)
if e < best[0]:
best = (e, (qi0, Di))
if best[1]:
qi, Di = best[1]
results["harm"] = DeclineFit("harm", qi=qi, Di=Di, b=1.0, rmse=best[0])
# 3) Hyperbolic (0<b<1.5)
b_grid = np.linspace(0.05, 1.5, 50)
best = (float("inf"), None)
for b in b_grid:
for Di in Di_grid:
q_pred = arps_rate(t_fit, qi0, Di, b)
e = rmse(q_fit, q_pred)
if e < best[0]:
best = (e, (qi0, Di, b))
if best[1]:
qi, Di, b = best[1]
results["hyper"] = DeclineFit("hyper", qi=qi, Di=Di, b=b, rmse=best[0])
return results
def pick_best_fit(fits: Dict[str, DeclineFit]) -> Optional[DeclineFit]:
if not fits:
return None
return sorted(fits.values(), key=lambda f: f.rmse)[0]
# -----------------------------
# Data & KPIs
# -----------------------------
def generate_demo_data(days: int = 900, seed: int = 7) -> pd.DataFrame:
rng = np.random.default_rng(seed)
date = pd.date_range("2023-01-01", periods=days, freq="D")
t = np.arange(days, dtype=float)
# 油递减(双曲 + 噪声 + 中后期措施)
qi, Di, b = 200.0, 0.0015, 0.7
qo = arps_rate(t, qi, Di, b)
qo *= (1 + 0.06 * (t > 420)) # 措施/制度变化
qo *= (1 + rng.normal(0, 0.05, size=days))
qo = np.clip(qo, 5, None)
# 含水上升(S 曲线)+ 噪声
fw = 1 / (1 + np.exp(-(t - 520) / 80))
fw = 0.15 + 0.75 * fw
fw += rng.normal(0, 0.02, size=days)
fw = np.clip(fw, 0.0, 0.98)
ql = qo / (1 - fw + 1e-12)
qw = ql - qo
# 注水:大体跟随液量,后期略不足
inj = 0.95 * ql
inj *= (1 - 0.15 * (t > 650))
inj *= (1 + rng.normal(0, 0.06, size=days))
inj = np.clip(inj, 0, None)
# 压力:随 VRR 偏低逐渐下降 + 噪声
vrr = safe_div(inj, ql)
pres = 20.0 - 2.0 * np.cumsum(np.clip(1 - np.nan_to_num(vrr, nan=1.0), 0, 2)) / days
pres += rng.normal(0, 0.05, size=days)
# 气:与油量相关(可选)
gor = 80 + 20 * np.tanh((t - 500) / 150) # 简单变化
qg = qo * gor
return pd.DataFrame({
"date": date,
"oil_rate": qo,
"water_rate": qw,
"gas_rate": qg,
"inj_rate": inj,
"pres": pres
})
def load_data(path: str) -> pd.DataFrame:
df = pd.read_csv(path)
if "date" not in df.columns:
raise ValueError("输入文件必须包含 date 列(例如 2025-01-01)")
df["date"] = pd.to_datetime(df["date"])
df = df.sort_values("date").reset_index(drop=True)
return df
def compute_kpis(df: pd.DataFrame) -> pd.DataFrame:
out = df.copy()
# 必要列检查
for c in ["oil_rate", "water_rate"]:
if c not in out.columns:
raise ValueError(f"输入必须包含列:{c}")
out["oil_rate"] = pd.to_numeric(out["oil_rate"], errors="coerce")
out["water_rate"] = pd.to_numeric(out["water_rate"], errors="coerce")
out["liq_rate"] = out["oil_rate"] + out["water_rate"]
out["watercut"] = safe_div(out["water_rate"], out["liq_rate"])
out["wor"] = safe_div(out["water_rate"], out["oil_rate"])
if "gas_rate" in out.columns:
out["gas_rate"] = pd.to_numeric(out["gas_rate"], errors="coerce")
out["gor"] = safe_div(out["gas_rate"], out["oil_rate"])
if "inj_rate" in out.columns:
out["inj_rate"] = pd.to_numeric(out["inj_rate"], errors="coerce")
out["vrr"] = safe_div(out["inj_rate"], out["liq_rate"])
if "pres" in out.columns:
out["pres"] = pd.to_numeric(out["pres"], errors="coerce")
# 累计(按相邻日期差分积分,默认 rate * dt_days)
dt_days = out["date"].diff().dt.total_seconds().div(86400.0)
dt_days.iloc[0] = np.nanmedian(dt_days.iloc[1:].values) if len(dt_days) > 1 else 1.0
dt_days = np.clip(dt_days, 0.5, 60) # 防止异常间隔
out["dt_days"] = dt_days
out["Np"] = (out["oil_rate"] * out["dt_days"]).cumsum()
out["Wp"] = (out["water_rate"] * out["dt_days"]).cumsum()
out["Lp"] = (out["liq_rate"] * out["dt_days"]).cumsum()
if "inj_rate" in out.columns:
out["Wi"] = (out["inj_rate"] * out["dt_days"]).cumsum()
# 平滑(7 点移动平均:日数据约等于一周)
w = 7
out["oil_ma"] = rolling_mean(out["oil_rate"], w)
out["liq_ma"] = rolling_mean(out["liq_rate"], w)
out["wc_ma"] = rolling_mean(out["watercut"], w)
# 递减率(基于平滑油量,避免日波动)
# decline_rate ≈ - d(ln q)/dt
q = out["oil_ma"].values.astype(float)
t = (out["date"] - out["date"].iloc[0]).dt.total_seconds().div(86400.0).values.astype(float)
lnq = np.log(np.clip(q, 1e-9, None))
dlnq = np.gradient(lnq, t, edge_order=1)
out["decline_rate_per_day"] = -dlnq
# 异常点(鲁棒 zscore)
out["oil_z"] = robust_zscore(out["oil_rate"].values)
out["wc_z"] = robust_zscore(out["watercut"].values)
return out
# -----------------------------
# Plotting
# -----------------------------
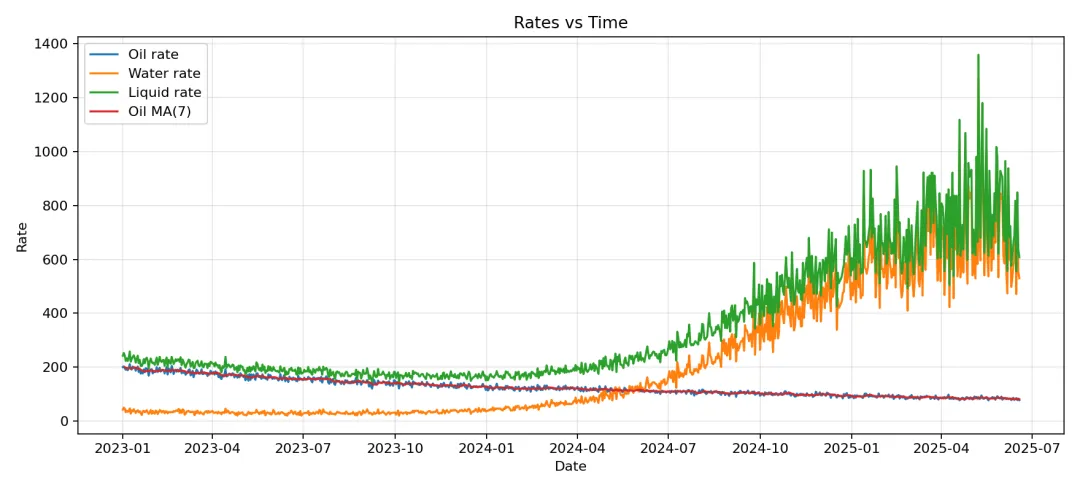
def plot_rates(df: pd.DataFrame, outdir: str) -> str:
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["oil_rate"], label="Oil rate")
ax.plot(df["date"], df["water_rate"], label="Water rate")
ax.plot(df["date"], df["liq_rate"], label="Liquid rate")
ax.plot(df["date"], df["oil_ma"], label="Oil MA(7)")
ax.set_title("Rates vs Time")
ax.set_xlabel("Date")
ax.set_ylabel("Rate")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "plots_rate.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
return path
def plot_watercut(df: pd.DataFrame, outdir: str) -> str:
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["watercut"], label="Water cut")
ax.plot(df["date"], df["wc_ma"], label="WC MA(7)")
ax.set_ylim(0, 1.02)
ax.set_title("Water Cut vs Time")
ax.set_xlabel("Date")
ax.set_ylabel("Water cut")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "plots_watercut.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
# WOR 单独画(对数更清晰)
fig, ax = plt.subplots(figsize=(11, 5))
wor = np.clip(df["wor"].values.astype(float), 1e-6, None)
ax.plot(df["date"], wor, label="WOR")
ax.set_yscale("log")
ax.set_title("WOR vs Time (log scale)")
ax.set_xlabel("Date")
ax.set_ylabel("WOR (log)")
ax.grid(True, which="both", alpha=0.3)
ax.legend()
path2 = os.path.join(outdir, "plots_wor.png")
fig.tight_layout()
fig.savefig(path2, dpi=160)
plt.close(fig)
return path
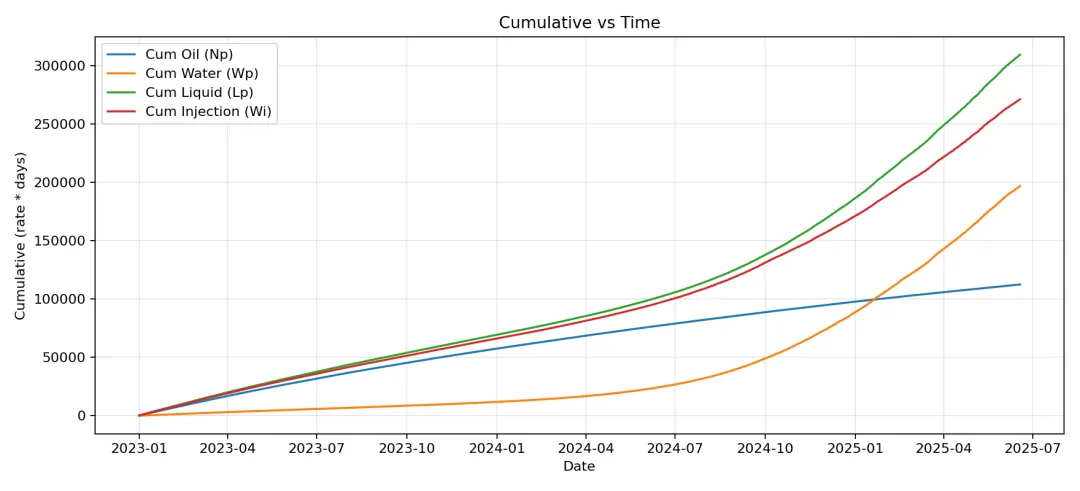
def plot_cum(df: pd.DataFrame, outdir: str) -> str:
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["Np"], label="Cum Oil (Np)")
ax.plot(df["date"], df["Wp"], label="Cum Water (Wp)")
ax.plot(df["date"], df["Lp"], label="Cum Liquid (Lp)")
if "Wi" in df.columns:
ax.plot(df["date"], df["Wi"], label="Cum Injection (Wi)")
ax.set_title("Cumulative vs Time")
ax.set_xlabel("Date")
ax.set_ylabel("Cumulative (rate * days)")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "plots_cum.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
return path
def plot_pressure(df: pd.DataFrame, outdir: str) -> Optional[str]:
if "pres" not in df.columns or df["pres"].notna().sum() < 5:
return None
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["pres"], label="Pressure")
ax.set_title("Pressure vs Time")
ax.set_xlabel("Date")
ax.set_ylabel("Pressure")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "plots_pressure.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
return path
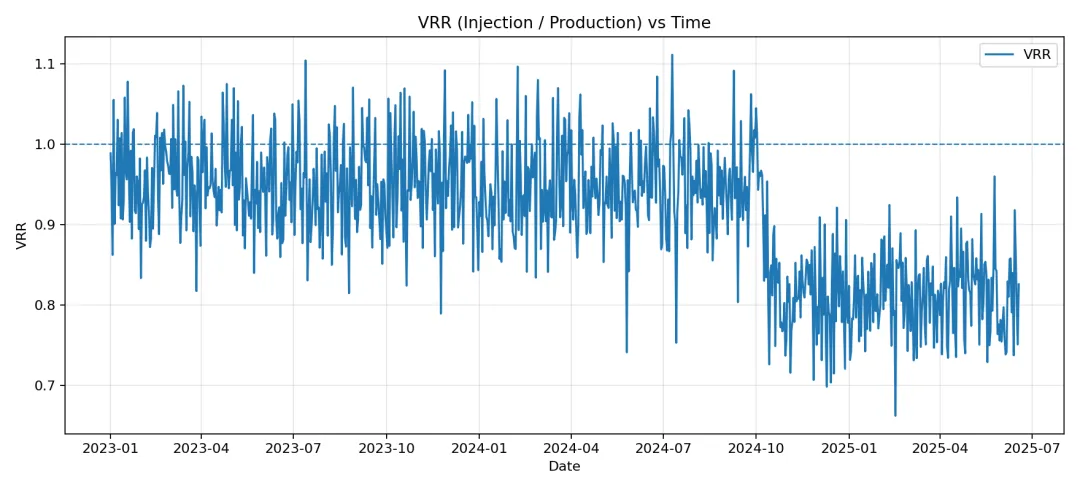
def plot_vrr(df: pd.DataFrame, outdir: str) -> Optional[str]:
if "vrr" not in df.columns or df["vrr"].notna().sum() < 5:
return None
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["vrr"], label="VRR")
ax.axhline(1.0, linestyle="--", linewidth=1)
ax.set_title("VRR (Injection / Production) vs Time")
ax.set_xlabel("Date")
ax.set_ylabel("VRR")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "plots_vrr.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
return path
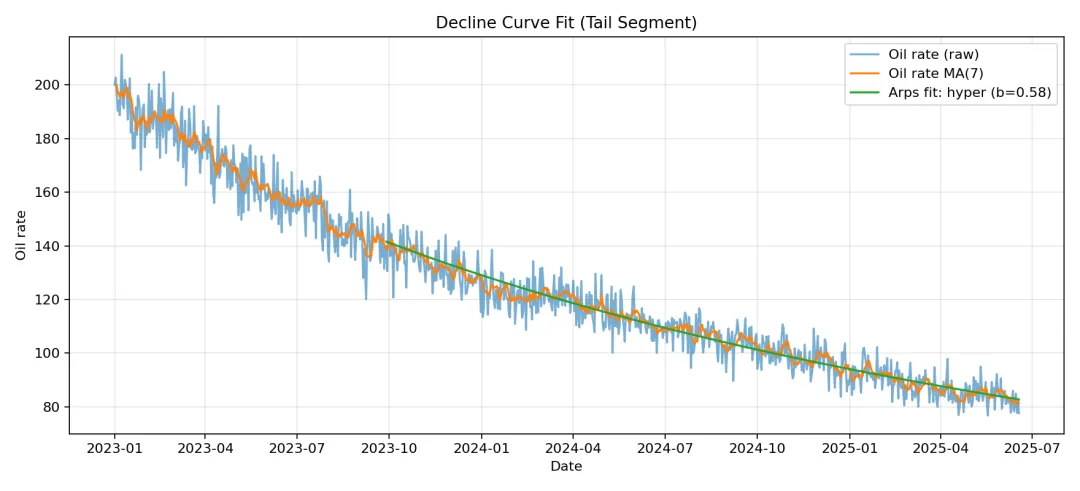
def plot_decline_fit(df: pd.DataFrame, outdir: str) -> Optional[Tuple[str, DeclineFit]]:
# 使用平滑油量拟合更稳健
q = df["oil_ma"].values.astype(float)
t = (df["date"] - df["date"].iloc[0]).dt.total_seconds().div(86400.0).values.astype(float)
fits = fit_arps_grid(t, q, prefer_tail=0.7)
best = pick_best_fit(fits)
if best is None:
return None
# 生成拟合曲线(对齐拟合段起点)
n = len(t)
start = int(max(0, math.floor((1 - 0.7) * n)))
t0 = t[start]
t_fit = t[start:] - t0
q_fit = q[start:]
q_pred = arps_rate(t_fit, best.qi, best.Di, best.b)
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(df["date"], df["oil_rate"], label="Oil rate (raw)", alpha=0.6)
ax.plot(df["date"], df["oil_ma"], label="Oil rate MA(7)")
ax.plot(df["date"].iloc[start:], q_pred, label=f"Arps fit: {best.model} (b={best.b:.2f})")
ax.set_title("Decline Curve Fit (Tail Segment)")
ax.set_xlabel("Date")
ax.set_ylabel("Oil rate")
ax.grid(True, alpha=0.3)
ax.legend()
path = os.path.join(outdir, "decline_fit.png")
fig.tight_layout()
fig.savefig(path, dpi=160)
plt.close(fig)
return path, best
# -----------------------------
# Summary (One-pager)
# -----------------------------
def build_summary(df: pd.DataFrame, decline: Optional[DeclineFit]) -> str:
last = df.dropna(subset=["oil_rate"]).iloc[-1]
first = df.dropna(subset=["oil_rate"]).iloc[0]
q_now = float(last["oil_rate"])
q0 = float(first["oil_rate"])
wc_now = float(last["watercut"]) if np.isfinite(last["watercut"]) else float("nan")
# 最近 30 天 vs 前 30 天(如果数据不足自动降级)
def window_slice(n):
return df.iloc[max(0, len(df)-n):]
recent = window_slice(30)
prev = df.iloc[max(0, len(df)-60):max(0, len(df)-30)] if len(df) >= 60 else df.iloc[:0]
q_recent = float(np.nanmean(recent["oil_rate"]))
wc_recent = float(np.nanmean(recent["watercut"]))
q_prev = float(np.nanmean(prev["oil_rate"])) if len(prev) else float("nan")
wc_prev = float(np.nanmean(prev["watercut"])) if len(prev) else float("nan")
# VRR
vrr_recent = float(np.nanmean(recent["vrr"])) if "vrr" in df.columns else float("nan")
# 压力趋势(近 90 天线性斜率)
pres_trend = None
if "pres" in df.columns and df["pres"].notna().sum() >= 10:
w90 = df.iloc[max(0, len(df)-90):].dropna(subset=["pres"])
if len(w90) >= 8:
t = (w90["date"] - w90["date"].iloc[0]).dt.total_seconds().div(86400.0).values.astype(float)
p = w90["pres"].values.astype(float)
# 线性回归斜率
A = np.vstack([t, np.ones_like(t)]).T
slope, _ = np.linalg.lstsq(A, p, rcond=None)[0]
pres_trend = slope # per day
# 异常点提示(最近 60 条记录)
tail = df.iloc[max(0, len(df)-60):]
oil_out = tail[np.abs(tail["oil_z"]) > 3][["date", "oil_rate"]].tail(5)
wc_out = tail[np.abs(tail["wc_z"]) > 3][["date", "watercut"]].tail(5)
lines = []
lines.append("# 油藏动态快诊断摘要\n")
lines.append(f"- 数据区间:{df['date'].min().date()} ~ {df['date'].max().date()}(共 {len(df)} 条)")
lines.append(f"- 当前日产油:{q_now:.2f}(起始:{q0:.2f})")
lines.append(f"- 当前含水:{wc_now*100:.1f}%")
lines.append("")
lines.append("## 近况对比(近30 vs 前30)")
lines.append(f"- 近30天平均日产油:{q_recent:.2f}" + (f"(前30:{q_prev:.2f})" if np.isfinite(q_prev) else ""))
lines.append(f"- 近30天平均含水:{wc_recent*100:.1f}%" + (f"(前30:{wc_prev*100:.1f}%)" if np.isfinite(wc_prev) else ""))
if "vrr" in df.columns:
lines.append(f"- 近30天平均 VRR:{vrr_recent:.2f}(<1 可能支撑不足,>1 需关注窜流/过注)")
if pres_trend is not None:
lines.append(f"- 近90天压力变化斜率:{pres_trend:.4f} /day(负值=下降,正值=回升)")
lines.append("")
lines.append("## 递减拟合(Arps,默认用后段数据)")
if decline is None:
lines.append("- 数据不足或质量不佳,未得到稳定拟合。")
else:
lines.append(f"- 最优模型:{decline.model}")
lines.append(f"- qi={decline.qi:.3f}, Di={decline.Di:.6f} (按时间单位), b={decline.b:.3f}, RMSE={decline.rmse:.3f}")
# 简单解读
if decline.model == "exp":
lines.append("- 解读:指数递减更像边界/能量支撑较弱或稳定制度下的均匀递减。")
elif decline.model == "harm":
lines.append("- 解读:调和递减偏“长尾”,常见于较强补给或受控压差条件。")
else:
lines.append("- 解读:双曲递减更常见于多数油气藏实际生产,b 值越大尾部越“长”。")
lines.append("")
lines.append("## 异常点提示(仅提醒,不直接下结论)")
if len(oil_out):
lines.append("- 产油离群点(|z|>3)最近示例:")
for _, r in oil_out.iterrows():
lines.append(f" - {r['date'].date()}: oil_rate={float(r['oil_rate']):.2f}")
else:
lines.append("- 产油离群点:未见显著(|z|>3)")
if len(wc_out):
lines.append("- 含水离群点(|z|>3)最近示例:")
for _, r in wc_out.iterrows():
lines.append(f" - {r['date'].date()}: watercut={float(r['watercut'])*100:.1f}%")
else:
lines.append("- 含水离群点:未见显著(|z|>3)")
lines.append("")
lines.append("## 建议下一步(按优先级)")
lines.append("1) 若 VRR 持续 <1 且压力下降:优先核查注水制度/配注、井网连通与见效滞后。")
lines.append("2) 若 WOR 突增且产油同步跳变:优先排查措施/窜流/含水突进通道、计量与工况。")
lines.append("3) 若递减段明显分段变陡:分段拟合 + 对应工况事件(停井、压差、泵况、节流)复盘。")
lines.append("")
return "\n".join(lines)
def write_summary(summary: str, outdir: str) -> str:
path = os.path.join(outdir, "summary.md")
with open(path, "w", encoding="utf-8") as f:
f.write(summary)
return path
# -----------------------------
# Main
# -----------------------------
def main():
parser = argparse.ArgumentParser(description="Fast Reservoir Dynamics Analyzer")
parser.add_argument("--input", type=str, default=None, help="Input CSV path")
parser.add_argument("--outdir", type=str, default="outputs", help="Output directory")
parser.add_argument("--demo", action="store_true", help="Generate demo data and run")
args = parser.parse_args()
ensure_outdir(args.outdir)
if args.demo:
df = generate_demo_data()
demo_path = os.path.join(args.outdir, "demo_data.csv")
df.to_csv(demo_path, index=False)
print(f"[OK] Demo data saved: {demo_path}")
else:
if not args.input:
raise SystemExit("请提供 --input data.csv,或使用 --demo 生成样例数据。")
df = load_data(args.input)
kpi = compute_kpis(df)
# Plots
p1 = plot_rates(kpi, args.outdir)
plot_watercut(kpi, args.outdir)
plot_cum(kpi, args.outdir)
plot_pressure(kpi, args.outdir)
plot_vrr(kpi, args.outdir)
decline_result = plot_decline_fit(kpi, args.outdir)
decline = decline_result[1] if decline_result else None
# Summary
summary = build_summary(kpi, decline)
s_path = write_summary(summary, args.outdir)
# Save KPI table
kpi_path = os.path.join(args.outdir, "kpi_enriched.csv")
kpi.to_csv(kpi_path, index=False)
print("[DONE] Outputs:")
print(f" - {p1}")
print(f" - {kpi_path}")
print(f" - {s_path}")
print(f" - (and more png files in {args.outdir}/)")
if __name__ == "__main__":
main()
6. 你可以怎么把它“变成你们油田能用的版本”?
这个脚本目前是油藏层面的快诊断骨架。如果你要工程化落地,通常会加三类增强:
- 1. 事件体系:把“措施/停井/切换层系/转注/酸化压裂”等事件表合并进来,图上自动标注
- 2. 分井/分区:同一脚本支持“区块汇总 + 单井批量输出”
- • 物质平衡快速直线法(需要 PVT/压缩系数等)
- • 递减分段/制度识别(Change-point detection)
以下是示例数据跑完的结果和快速分析结果:
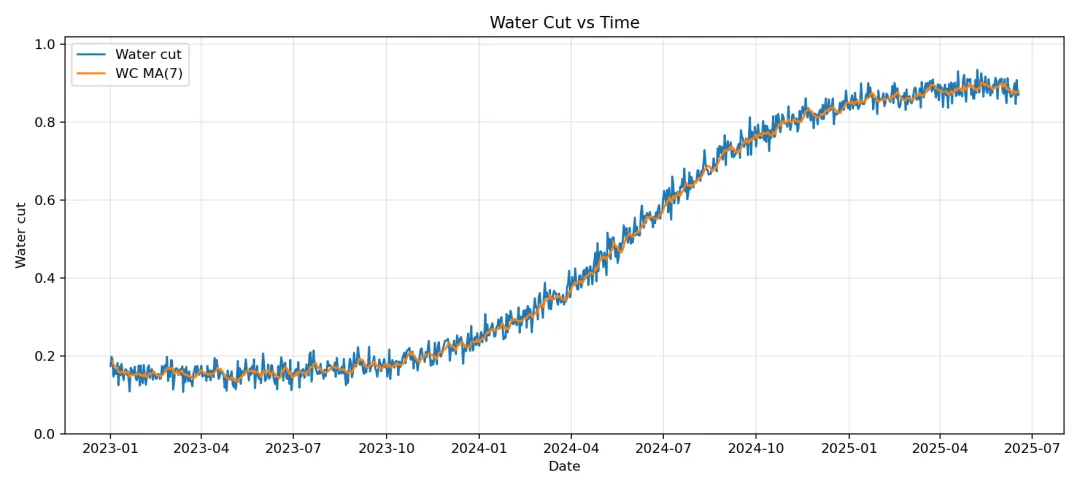
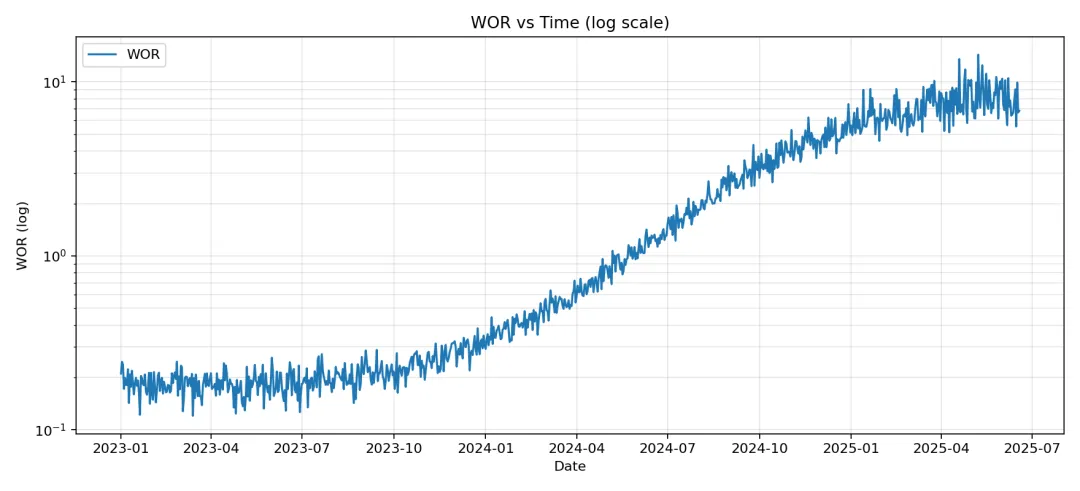
油藏动态快诊断摘要
- • 数据区间:2023-01-01 ~ 2025-06-18(共 900 条)
近况对比(近30 vs 前30)
- • 近30天平均日产油:83.56(前30:84.72)
- • 近30天平均含水:88.5%(前30:89.1%)
- • 近30天平均 VRR:0.81(<1 可能支撑不足,>1 需关注窜流/过注)
- • 近90天压力变化斜率:-0.0001 /day(负值=下降,正值=回升)
递减拟合(Arps,默认用后段数据)
- • qi=141.546, Di=0.001001 (按时间单位), b=0.583, RMSE=2.308
- • 解读:双曲递减更常见于多数油气藏实际生产,b 值越大尾部越“长”。
异常点提示(仅提醒,不直接下结论)
建议下一步(按优先级)
- 1. 若 VRR 持续 <1 且压力下降:优先核查注水制度/配注、井网连通与见效滞后。
- 2. 若 WOR 突增且产油同步跳变:优先排查措施/窜流/含水突进通道、计量与工况。
- 3. 若递减段明显分段变陡:分段拟合 + 对应工况事件(停井、压差、泵况、节流)复盘。



