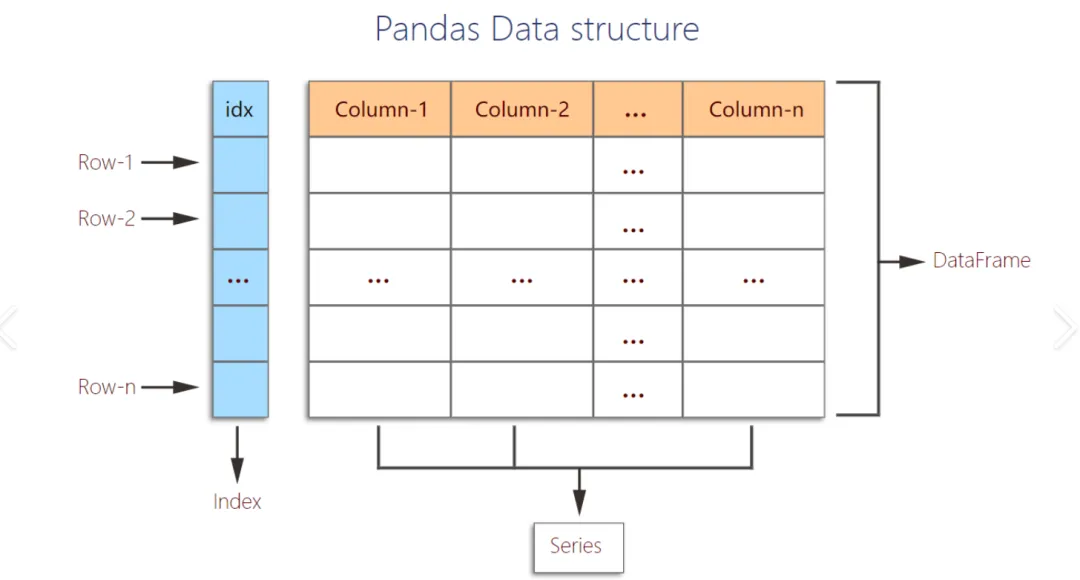
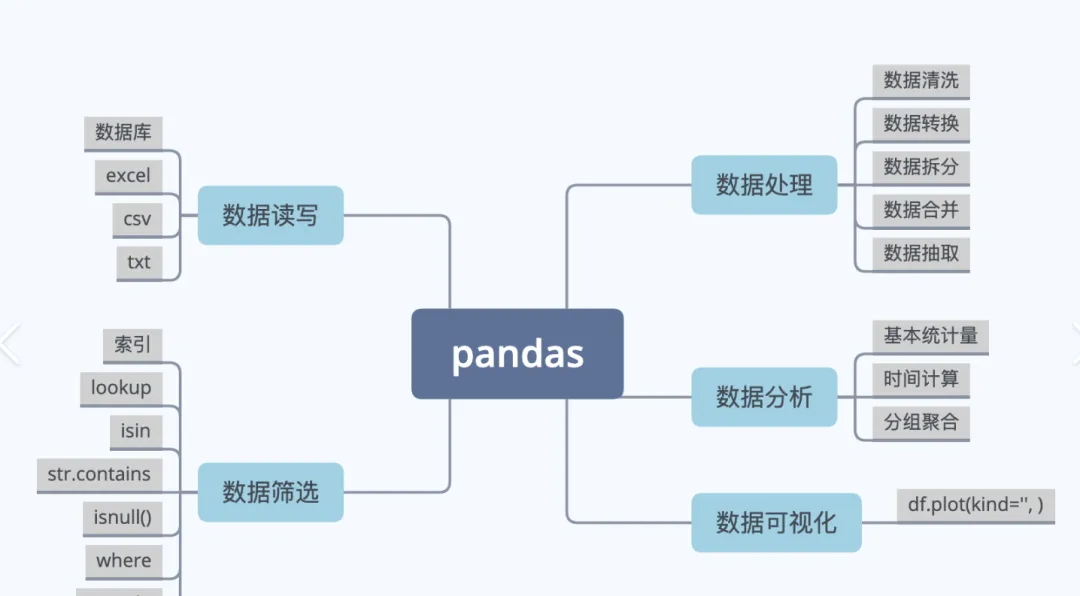
作为程序员,日常工作和生活中难免要和各类结构化数据打交道 —— 从整理个人月度消费账单、分析通勤时间规律,到处理企业级的电商订单报表、服务器监控日志,数据清洗、筛选、聚合这些基础操作如果纯靠 Python 原生列表 / 字典实现,不仅代码冗余、效率低下,还极易因数据格式不统一出现错误。而 Pandas 正是为解决这类问题而生的 Python 核心库,它基于 NumPy 构建,提供了 Series(一维数组)和 DataFrame(二维表格)两大核心数据结构,能以极简的代码完成海量数据的清洗、转换、分析和可视化前置处理。在日常生活中,你可以用它 5 分钟完成原本 1 小时的 Excel 手动统计;在工作中,数据分析师用它处理千万级用户行为日志,运维工程师用它解析服务器性能数据,电商运营用它实时汇总订单并生成销售报表 ——Pandas 几乎是 Python 数据处理领域的 “标配工具”,大幅降低了数据处理的门槛,让开发者从重复的代码编写中解放出来,聚焦于数据本身的价值挖掘。一、安装 Pandas
Pandas 的安装适配所有主流操作系统(Windows/Mac/Linux),只需通过 Python 包管理工具 pip 即可完成,步骤如下:基础安装(推荐)pip install pandas# 完整安装(包含数据可视化、数值计算依赖)pip install pandas numpy matplotlib openpyxl
安装完成后,在 Python 脚本中导入 Pandas 即可使用,行业通用别名是pd(便于代码简洁性和可读性):二、基本用法(分 4 个核心步骤)
步骤 1:创建核心数据结构
Pandas 的所有操作都围绕 Series(一维带索引数组)和 DataFrame(二维表格)展开,先从创建开始:import pandas as pdimport numpy as np1. 创建Series(一维数据,适合单维度数据,如每月消费总额)month_expense = pd.Series([2890, 3120, 2780, 3050], index=['一月', '二月', '三月', '四月'])print("一维消费数据(Series):")print(month_expense)# 2. 创建DataFrame(二维表格,适合结构化数据,如购物清单)shopping_data = { '商品名称': ['牛奶', '面包', '鸡蛋', '水果'], '单价(元)': [5.5, 3.2, 4.0, 8.8], '购买数量': [4, 10, 20, 5]}df_shopping = pd.DataFrame(shopping_data)print("\n二维购物数据(DataFrame):")print(df_shopping)
执行后会输出带自定义索引的一维数据,以及和 Excel 表格结构一致的二维数据,这是后续所有操作的基础。步骤 2:读取 / 保存日常数据文件
日常处理的账单、报表多为 CSV/Excel 格式,Pandas 可一键读写,无需手动解析格式:1. 读取CSV格式的个人消费账单(假设文件为expense.csv)# 文件内容示例:日期,消费金额,消费类型# 2026-02-01,25.5,餐饮;2026-02-02,15.0,交通;2026-02-03,89.0,购物df_expense = pd.read_csv('expense.csv', encoding='utf-8')print("\n读取的消费账单:")print(df_expense)# 2. 保存处理后的数据到Excel(避免手动复制粘贴)df_expense.to_excel('processed_expense.xlsx', index=False) # index=False不保存行索引
步骤 3:数据清洗(处理空值 / 重复值)
实际数据常存在空值、重复值,Pandas 可高效清洗:模拟带脏数据的消费记录df_dirty = pd.DataFrame({ '日期': ['2026-02-01', '2026-02-01', '2026-02-02', None, '2026-02-03'], '金额': [25.5, 25.5, np.nan, 15.0, 89.0], '类型': ['餐饮', '餐饮', '交通', '交通', '购物']})# 1. 去除重复行df_clean = df_dirty.drop_duplicates()# 2. 填充空值(金额空值用0填充,日期空值用前一行值填充)df_clean['金额'] = df_clean['金额'].fillna(0)df_clean['日期'] = df_clean['日期'].fillna(method='ffill')# 3. 筛选出餐饮类消费df_food = df_clean[df_clean['类型'] == '餐饮']print("\n清洗后的餐饮消费数据:")print(df_food)
步骤 4:数据统计与聚合
从清洗后的数据中提取核心信息,如总额、均值、分组统计:计算核心统计指标total = df_clean['金额'].sum() # 总消费avg = df_clean['金额'].mean() # 平均消费# 按消费类型分组统计总额grouped = df_clean.groupby('类型')['金额'].sum()print(f"\n总消费金额:{total} 元")print(f"平均单次消费:{avg:.2f} 元")print("\n按类型分组的消费总额:")print(grouped)
三、高级用法(时间序列分析)
针对日常高频的时间维度分析(如通勤时间、月度开销),Pandas 的时间序列功能能深度挖掘规律:模拟10天的通勤时间数据(日期为索引)dates = pd.date_range(start='2026-02-01', end='2026-02-10')commute_data = { '早通勤(分钟)': [35, 40, 38, 45, 32, 30, 42, 39, 37, 41], '晚通勤(分钟)': [42, 45, 40, 50, 38, 35, 48, 41, 39, 43]}df_commute = pd.DataFrame(commute_data, index=dates)# 1. 按周统计平均通勤时间(时间重采样)weekly_commute = df_commute.resample('W').mean()print("\n每周平均通勤时间:")print(weekly_commute)# 2. 计算早晚通勤时间差,标记超时通勤(>40分钟)df_commute['通勤差值'] = df_commute['晚通勤(分钟)'] - df_commute['早通勤(分钟)']df_commute['超时标记'] = df_commute['早通勤(分钟)'].apply(lambda x: '是' if x>40 else '否')print("\n带差值和超时标记的通勤数据:")print(df_commute)
四、实际应用场景
个人财务管理
:读取银行流水、微信 / 支付宝账单的 CSV 文件,按消费类型 / 时间维度统计,快速定位高消费项,优化消费结构;
电商小卖家运营
:每日读取订单数据,筛选高客单价订单、复购用户,分析不同地区销量,辅助制定精准促销策略;
职场考勤分析
:HR 可读取打卡数据,统计员工迟到次数、加班时长,自动生成月度考勤报表,替代手动 Excel 统计;
智能家居能耗分析
:解析智能家居设备的运行日志(如空调运行时长、灯光开启次数),分析能耗规律,优化使用习惯以节约电费。
Pandas 的核心价值并非只是 “简化代码”,而是重构了数据处理的逻辑 —— 它将原本需要数十行原生 Python 代码实现的功能,压缩为几行简洁的 API 调用,让开发者从 “编写解析代码” 转向 “挖掘数据价值”。无论是个人日常的数据整理,还是企业级的业务分析,Pandas 都能以高效、灵活的方式解决问题,是每个 Python 开发者都应掌握的核心工具。你在日常工作或生活中是否有过手动处理大量数据的烦恼?不妨试试用 Pandas 重构你的数据处理流程,比如先从整理一份个人月度消费账单开始。如果在使用过程中遇到任何问题(比如数据读取报错、筛选逻辑写不出来),都可以在评论区留言,我们一起探讨更优的解决方案!总结
Pandas 是 Python 数据处理的核心库,通过 Series/DataFrame 简化结构化数据的清洗、统计与分析,适配日常和工作中的各类数据场景;
基础用法聚焦 “创建 - 读写 - 清洗 - 统计” 四大步骤,高级用法可实现时间序列等复杂分析,覆盖个人财务、电商运营等高频场景;
Pandas 的核心优势是用极简代码替代重复的手动操作,让开发者聚焦数据价值而非格式解析。