前言
在java中,要说又去重又有序好用的集合框架,第一时间就会想到基于红黑树实现的TreeSet,紧接着就能想到同样大家熟知的CME(ConcurrentModificationException)。今天就再来扒一扒这个异常的老底。
这时你可能会问:“这个异常这么常见,还有必要再拿出来单独说一下吗?”
哎,有必要!!!
因为前段时间我们线上遇到了(O_o),
而且藏的还比较隐蔽……
背景
业务场景是转发场景,服务接收新转发feed消息,把feed加载到转发树中。 其中树节点的子节点集合使用的数据结构正是TreeSet,方便子节点去重排序和二分快速查找。
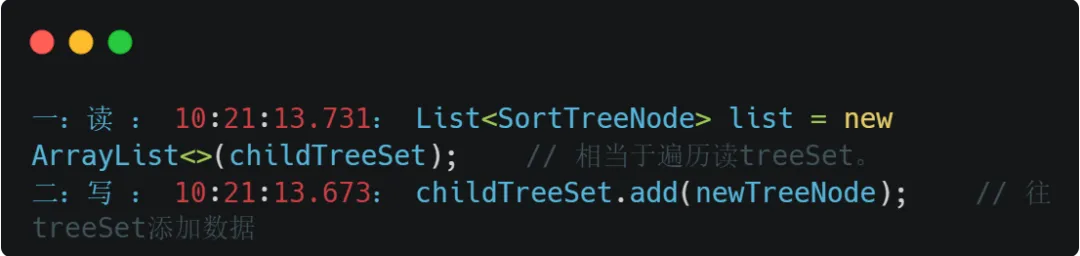
那TreeSet不是正正好?线上也美美的平稳运行着,直到那天错误不期而遇:ConcurrentModificationException!确定冲突的地方也废了一番功夫,经过一番测试发现了冲突的两端代码:
在这并发读写下,就出现了CME异常。这两段代码其实离了十万八千里,也是很小概率会出现,一个不小心就把这个异常疏忽了,所以今天就接着这个异常来重新盘一盘常见的集合框架。
一
复现一下
Reproduce it again
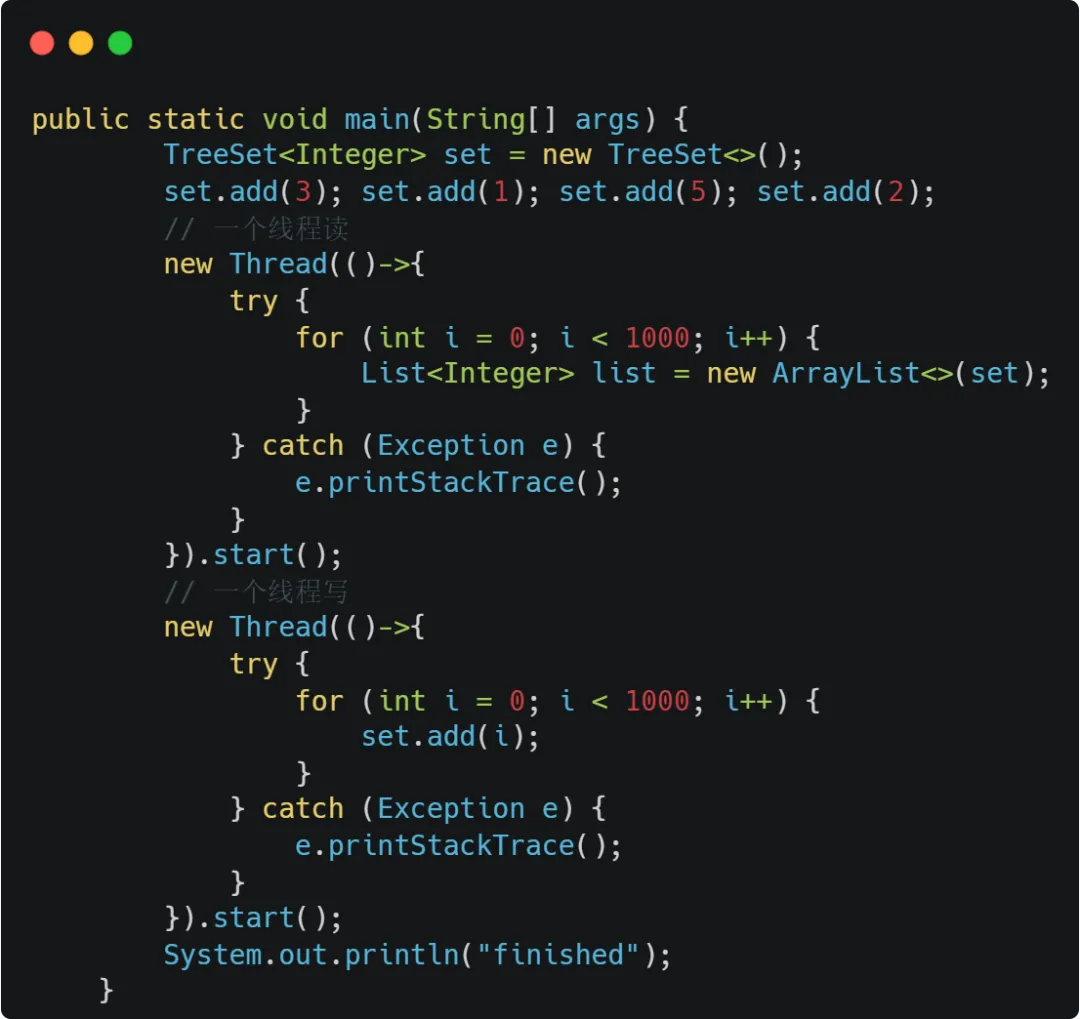
测试代码:
不出意外就能得到心心念念的CME异常。
有意思的现象:循环次数调整到100,在jdk17下出现CME的概率就会小很多,在jdk8的下执行却很容易出现。
循环100次时,JDK8异常概率反而更高。
这是因为 100 次操作的执行时间极短(微秒级),JDK 17 的 JIT 编译器(尤其是分层编译与 C2 优化)和线程调度器更为高效:两个线程往往在极短时间内先后完成任务,形成“错峰执行”——线程 2 快速完成全部 add 操作后,线程 1 才开始迭代,从而避开了危险的竞态窗口。而 JDK 8 的 JIT 预热较慢(100 次可能仅触发 C1 编译),线程执行速度存在波动,加上线程池调度存在微秒级延迟,反而使修改与迭代操作在时间轴上更容易重叠,触发 fail-fast 检测。
循环1000次时,JDK17异常概率显著上升。
此时操作时间延长至毫秒级,JDK 17 的多项优化开始放大冲突:C2 JIT 对循环体的深度内联与逃逸分析使 add 操作速度大幅提升;G1 GC 在 JDK 17 中的并发标记与回收效率更高,减少了线程停顿,使两个线程能更长时间地“并行奔跑”;同时,JDK 17 对内存屏障的优化增强了修改操作的可见性,使 modCount 的变化更快被迭代线程感知。这些因素共同导致修改与迭代的重叠窗口更密集、更持久,fail-fast 检测几乎必然触发。相比之下,JDK 8 因 GC 停顿稍长、JIT 优化较弱,线程执行存在更多“自然间隙”,反而降低了冲突概率。
二
异常根源剖析
Analysis of the root cause of the anomaly
01
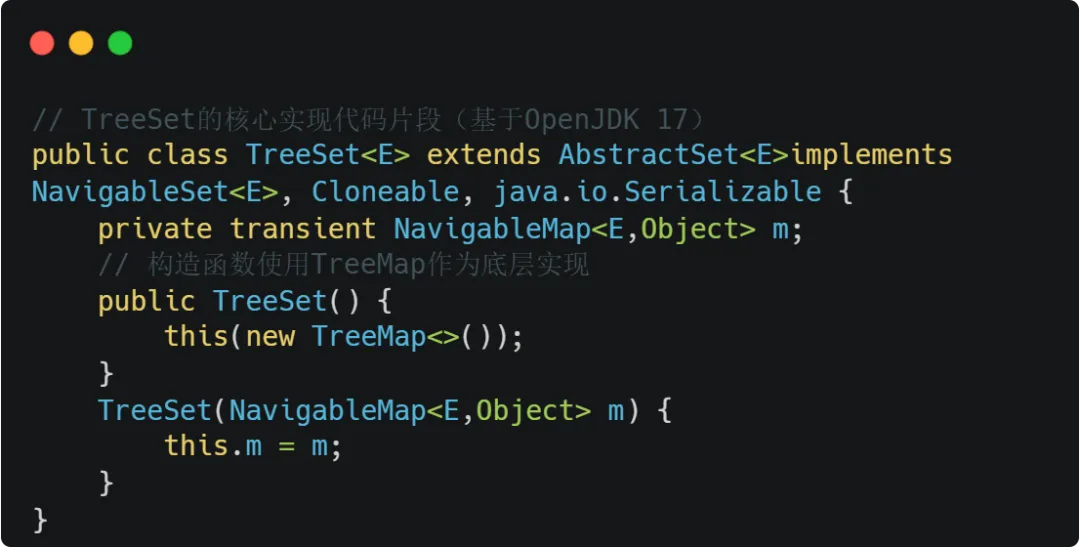
TreeSet的底层数据结构与实现机制
TreeSet本质上是一个基于TreeMap实现的导航集合,其内部维护了一个红黑树数据结构。红黑树是一种自平衡的二叉查找树,它通过一系列复杂的旋转和重新着色操作来维持树的平衡性。
这种树结构的复杂性为并发访问埋下了隐患。红黑树的插入、删除操作通常需要从被操作节点回溯到根节点,沿途可能需要进行多次旋转操作,这个过程不是原子性的。
02
并发异常的技术根源:
红黑树的非原子性操作
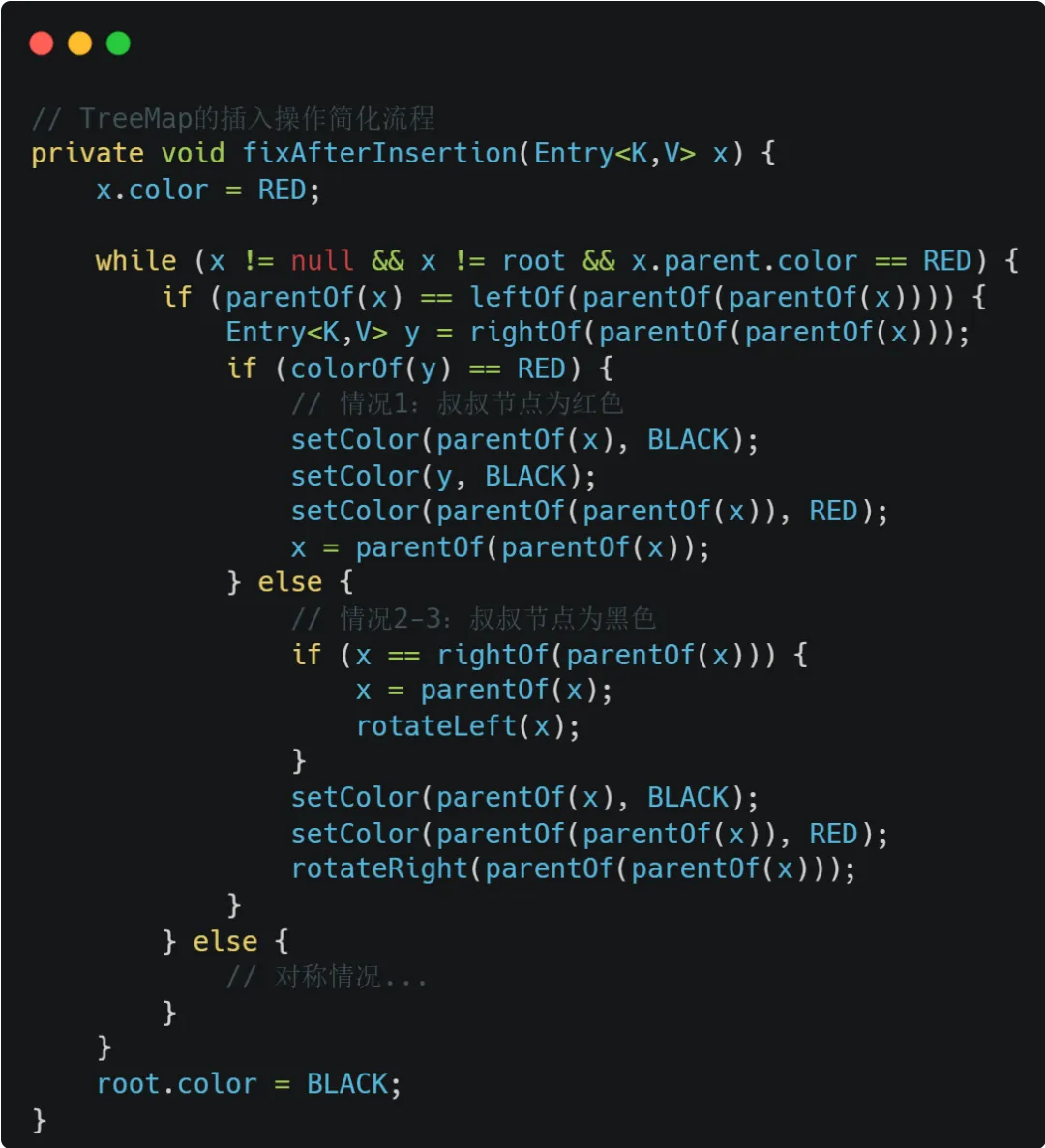
红黑树的平衡操作包含多个步骤,不是原子操作。以插入操作为例:
这个过程涉及多个节点的颜色修改和旋转操作,如果在中间状态被其他线程访问,就会看到不一致的树结构。基于上面这个插入的例子,我们来回顾下红黑树的相关知识:
红黑树的核心规则
节点颜色只能是红色(RED)或黑色(BLACK);
根节点必须是黑色;
红色节点的父 / 子节点不能是红色(红节点不能相邻);
从任意节点到其所有后代叶子的路径上,黑色节点数量(黑高)必须一致;
所有叶子节点(NIL)为黑色。
reeMap 的fixAfterInsertion就是为了在插入新节点后,通过颜色修改和旋转恢复这些规则。如果执行到一半被打断,树结构会违反上述规则,形成 “不一致状态”。
具体例子说明:
1. 初始合法红黑树结构
先构造一个完全符合红黑树规则的初始树(数字为节点key,括号内为颜色):
此时各路径黑高一致:
40→20→10:黑高 = 2(40、20)
40→20→30:黑高 = 2(40、20)
40→50:黑高 = 2(40、50)
2. 插入新节点并触发修复(执行到一半被打断)
现在插入节点5,触发fixAfterInsertion流程:
步骤1:新节点5被设为红色(x.color = RED),父节点是10(RED);
步骤2:进入循环(x≠root且x.parent.color=RED);
步骤3:判断10是20的左子,叔叔节点是30(RED),进入 “情况 1”;
步骤4:执行setColor(10, BLACK)(把 10 设为黑);
步骤5:执行setColor(30, BLACK)(把 30 设为黑);
线程被打断:还没执行setColor(20, RED)和x=20,修复流程中断。
3. 中断后的 “不一致树结构”
此时树的状态变成:
4. 违反的红黑树规则(不一致的核心体现)
黑高不一致:
40→20→10→5:黑高 = 3(40、20、10)
40→20→30:黑高 = 3(40、20、30)
40→50:黑高 = 2(40、50)→ 违反 “黑高一致” 规则;
后续如果修复线程继续执行,还会因中间状态错误,导致旋转操作破坏指针关系(比如父 / 子指针指向错误)。
不一致结构会引发的具体错误
其他线程访问这个 “半成品” 树时,会触发各种异常行为,常见的有:
1. 查找功能错误
TreeMap 的get()方法依赖红黑树的有序性和黑高规则遍历节点。比如线程尝试查找60(不存在):
正常逻辑:从根 40→右子 50→右子(null),判定 60 不存在;
异常逻辑:因黑高不一致,遍历逻辑可能误判路径,比如无限递归查找左子树,或直接返回错误结果(比如误判 60 存在);
更严重的是:查找本应存在的节点(如30)时,因结构异常导致找不到。
2. 遍历异常(keySet/entrySet遍历)
缺失节点:遍历到20时,因黑高异常,遍历逻辑提前终止,导致30、50等节点无法被遍历到;
重复节点:指针混乱时,同一个节点被多次遍历;
死循环:如果旋转操作执行到一半(比如只修改了父节点的子指针,没修改子节点的父指针),会形成 “环”(如节点 A 的子是 B,B 的父却是 C),遍历过程中无限循环。
3. 数据丢失或结构彻底损坏
如果后续修复线程继续执行,会基于错误的中间状态进行旋转 / 变色,导致:
节点成为 “孤儿”(无父节点引用,无法被访问);
父子指针互相指向(形成环);
红节点相邻,最终导致整个红黑树崩溃,后续所有增删改查操作都失效。
在这里,我们来回顾下,为什么修复流程可能被中断,也就是在红黑树fixAfterInsertion修复流程中,为什么会出现 “执行完setColor(10, BLACK)和setColor(30, BLACK)后,还没执行setColor(20, RED)和x=20就被线程打断” 的情况。
核心原因有两个方面:Java 线程的 “抢占式调度”+ 修复代码非原子性。
首先要明确两个关键前提:
1.Java 线程是抢占式调度:操作系统(OS)会为每个线程分配 “时间片”(通常几毫秒到几十毫秒),线程在时间片内执行指令,时间片用完后,OS 会暂停当前线程,切换到其他就绪的线程执行(“上下文切换”);
2.修复代码是多步非原子操作:fixAfterInsertion中 “情况 1” 的逻辑(改父节点颜色→改叔叔颜色→改祖父颜色→更新 x)是四个独立的操作,CPU 执行时是 “一条指令接一条指令” 执行,没有任何机制保证这四个操作 “要么全执行,要么全不执行”—— 这意味着中间任何一步都可能被 OS 暂停。
以下是最常见的、会导致修复流程中断
在 “设 20 为红” 之前的场景:
1. 线程时间片耗尽(最常见)
这是操作系统层面最基础的调度行为:
假设当前执行修复逻辑的线程(线程 A)拿到的时间片是 10ms;
线程 A 执行setColor(10, BLACK)(耗时 0.1ms)、setColor(30, BLACK)(耗时 0.1ms)后,剩余时间片已用完;
OS 立即暂停线程 A,将 CPU 资源分配给其他线程(比如线程 B,正在执行 TreeMap 的get()操作);
此时线程 A 的执行停在 “设 20 为红” 之前,树处于不一致状态,线程 B 访问时就会看到错误的树结构。
2. 垃圾回收(GC)触发
Java 的垃圾回收会触发 “Stop-The-World(STW)”(即使是 G1/ZGC 等低停顿 GC,也有短暂 STW):
线程 A 执行完setColor(10, BLACK)和setColor(30, BLACK)后,JVM触发 Minor GC(新生代回收);
GC 会暂停所有用户线程(包括线程 A),优先执行垃圾回收;
GC 完成后,JVM重新调度线程,但不一定立即恢复线程 A——可能先调度线程 C(执行 TreeMap 的put()),此时线程 A 的修复流程仍停在中断点,树结构不一致。
3. 高优先级线程抢占
线程有优先级(Java 中 1-10 级),OS 会优先调度高优先级线程:
线程 A(优先级 5)执行到 “设 30 为黑” 后,一个高优先级线程 D(优先级 9,比如业务核心线程)进入 “就绪状态”;
OS 会立即暂停低优先级的线程 A,切换到线程 D 执行;
线程 A 的修复流程中断,直到线程 D 执行完(或时间片用完),线程 A 才可能恢复 —— 但在此期间,其他线程已访问到不一致的树。
4. 线程自身触发阻塞 / 中断
虽然 TreeMap 源码中没有主动阻塞的逻辑,但业务场景中可能间接触发:
场景 A:线程 A 执行修复逻辑时,被其他线程调用Thread.interrupt()(中断),线程 A 响应中断(比如抛出InterruptedException),导致修复流程提前终止;
场景 B:如果 TreeMap 的操作被包裹在带锁的逻辑中(比如业务层加了synchronized),线程 A 执行到中断点时,尝试获取另一个锁失败,被阻塞在lock()方法上,修复流程暂停。
5. 硬件 / OS 层面的干扰
比如 CPU 执行中断(如 IO 中断、时钟中断):
线程 A 执行到 “设 30 为黑” 后,硬盘完成 IO 操作,触发硬件中断;
CPU 暂停当前线程 A,优先处理 IO 中断的回调逻辑;
回调处理完成后,OS 重新调度线程,线程 A 的修复流程已中断。
补充:为什么 “原子性” 是关键?
如果fixAfterInsertion的 “情况 1” 逻辑是原子操作(比如用synchronized包裹,或通过 CAS 实现),那么 OS 即使切换线程,也只会在 “所有步骤执行完” 或 “一步都没执行” 时切换 —— 不会出现 “执行一半” 的情况。
三
高并发下集合方案分析
Analysis of Aggregation Schemes under High Concurrency
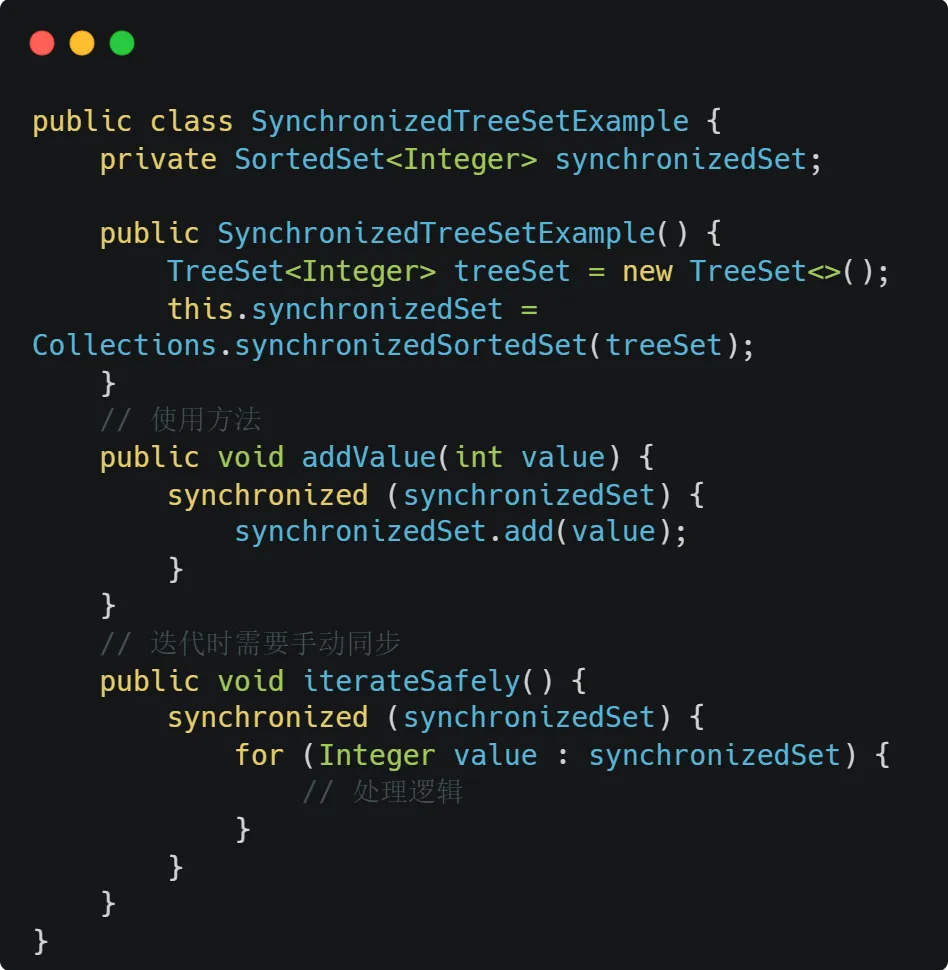
同步包装器:
Collections.synchronizedSortedSet()
这是最简单的解决方案,但存在严重的性能问题:
优点:实现简单,保证强一致性
缺点:完全串行化访问,并发性能极差
适用场景:低并发、读多写少或集合操作频率低的场景
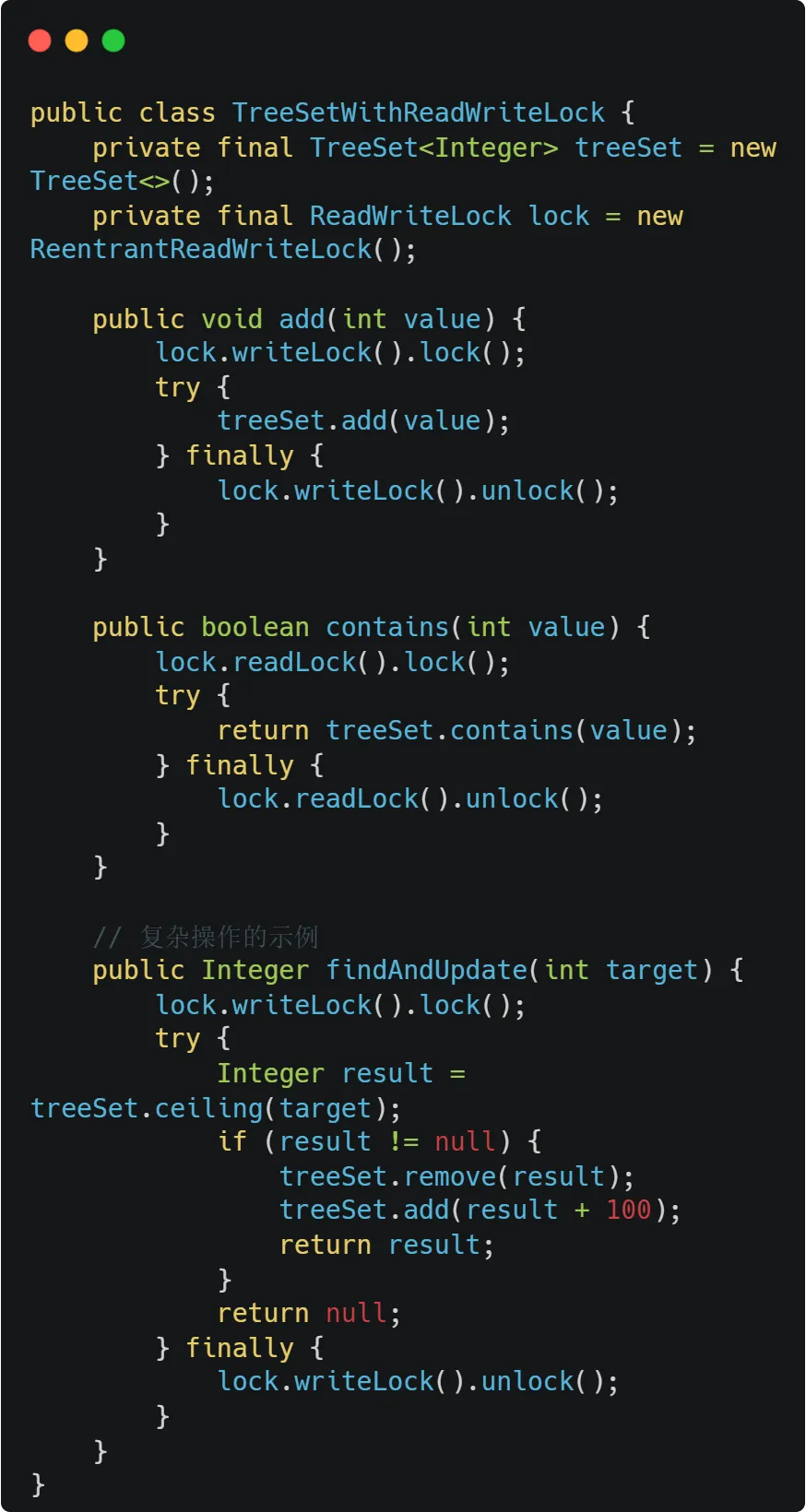
读写锁方案:更细粒度的控制
性能对比:
读-读不互斥,适合读多写少的场景
写操作仍然完全互斥
在大量写操作或读操作需要遍历整个集合时,性能仍不理想
03
ConcurrentSkipListSet:
完全并发的替代方案
ConcurrentSkipListSet基于跳表实现,提供了真正的并发访问能力。
技术深度分析:
1.跳表数据结构:
多层索引结构,查找时间复杂度O(log n)
插入操作只需局部更新,减少了锁竞争
2.并发控制机制:
使用CAS操作实现无锁更新
细粒度的锁策略,不同部分的修改可以并发进行
3.与TreeSet的性能对比:
场景
TreeSet
+
同步锁
Concurrent
SkipListSet
纯读
操作
中等(读锁可共享)
优秀
(完全无锁读)
纯写
差(完全串行)
良好
(CAS操作)
读写
混合
差(写锁独占)
(读写不互斥)
内存
占用
较低
较高
(多层索引)
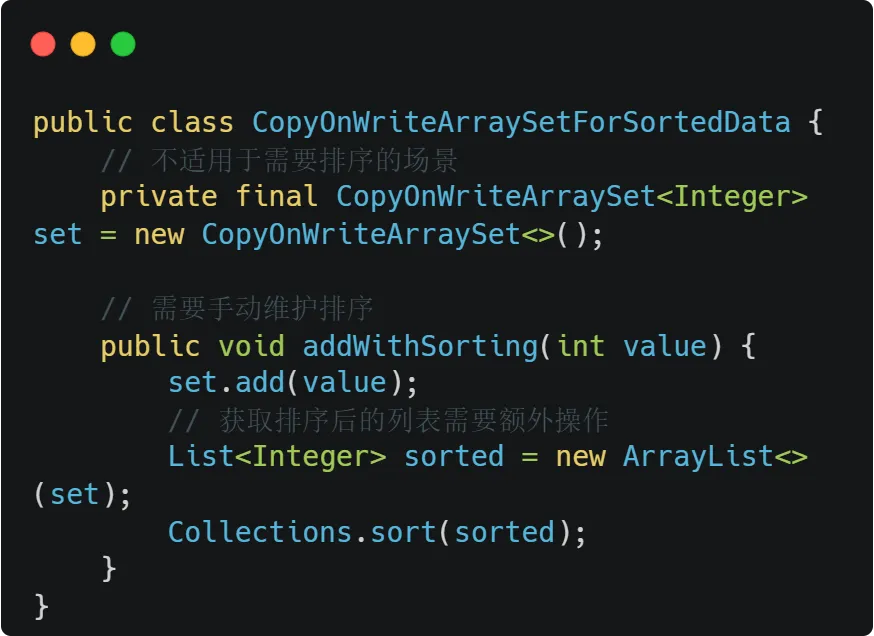
4.CopyOnWriteArraySet
虽然CopyOnWriteArraySet也是并发安全的,但它基于数组而非树结构,不保证顺序。
适用场景:
集合大小较小
读操作远多于写操作
不需要实时排序
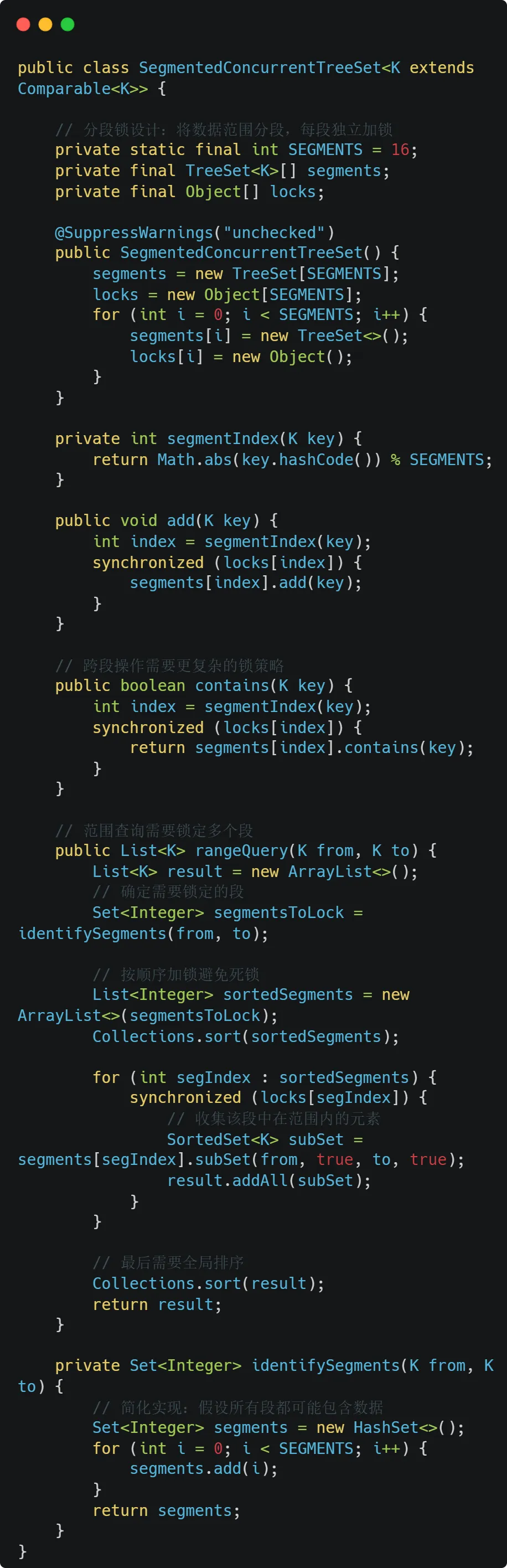
5.自定义并发TreeSet:分段锁与乐观锁策略
对于特殊需求场景,可以设计自定义的并发TreeSet
设计考量:
分段粒度:段数太少则竞争激烈,太多则内存开销大
负载均衡:数据分布不均可能导致热点段
跨段操作:复杂操作需要精心设计锁获取顺序
四
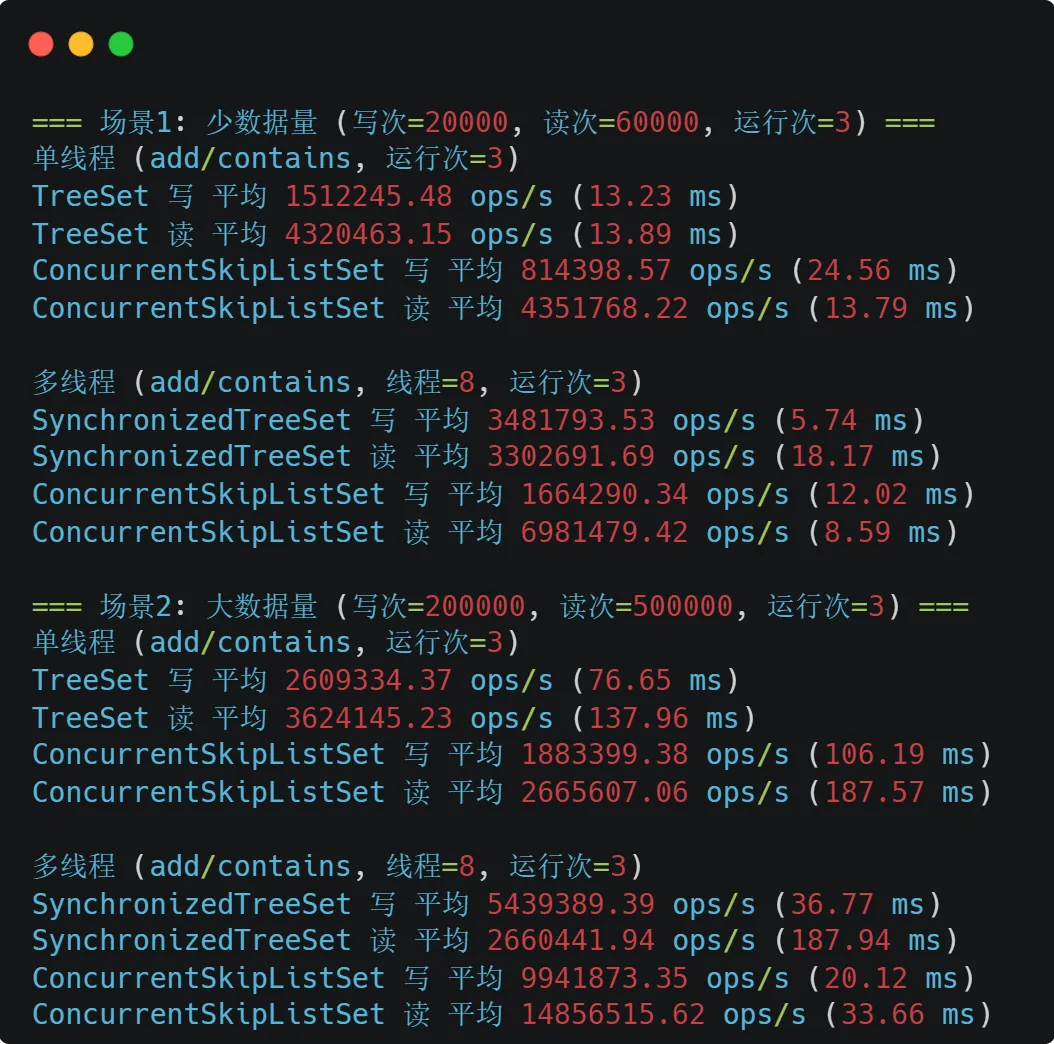
TreeSet、ConcurrentSkipListSet和SynchronizedTreeSet性能测试对比(jdk17)
测试方法:
测试结果:
基于测试可以看出:
单线程/低并发 :优先 TreeSet(红黑树在无锁竞争是读写开销很低)
高并发读写(尤其大数据量下):优先 ConcurrentSkipListSet
小数据量但写入高并发 : SynchronizedTreeSet可能写吞吐不差,但读性能通常不如 ConcurrentSkipListSet,且锁竞争风险更高
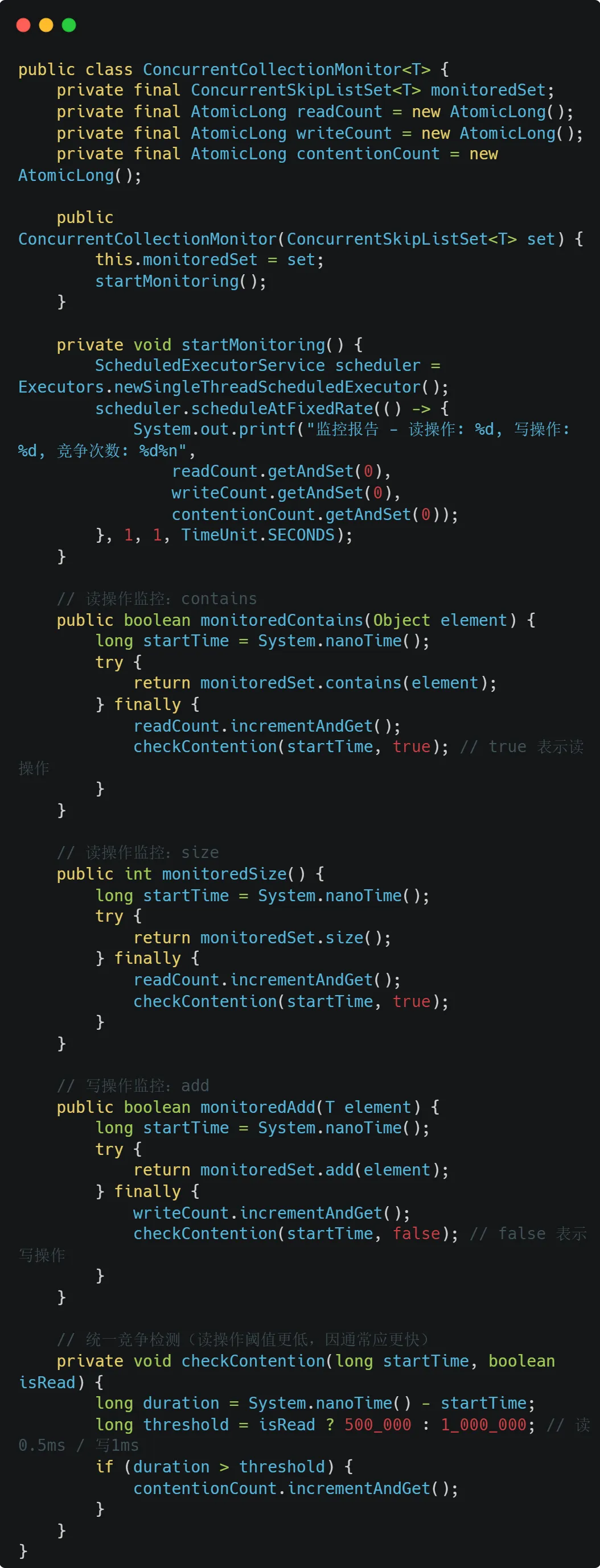
所以在高并发场景下可以直接使用ConcurrentSkipListSet,如果需要顺便加上一个监控诊断:
五
结论:
合适的才是最好的
Conclusion: The right is the best
通过分析,我们可以得出以下结论:
理解需求优先:在选择并发有序集合方案前,必须明确具体的业务需求,包括并发级别、读写比例、数据规模、一致性要求等。
默认推荐ConcurrentSkipListSet:对于大多数需要并发有序集合的场景,ConcurrentSkipListSet是最佳选择,它在并发性能和功能完整性之间取得了良好平衡。
特殊场景特殊处理:
极度读多写少:考虑CopyOnWriteArraySet + 外部排序
写操作极其频繁:考虑自定义分段锁方案
需要强一致性事务:考虑数据库解决方案
4.监控与调优不可少:无论选择哪种方案,都必须建立完善的监控和性能测试体系,根据实际运行情况持续调优。
5.AI等review工具的使用:寻找适当的工具或者方法,将可能的问题提前抛出,防患于未然。
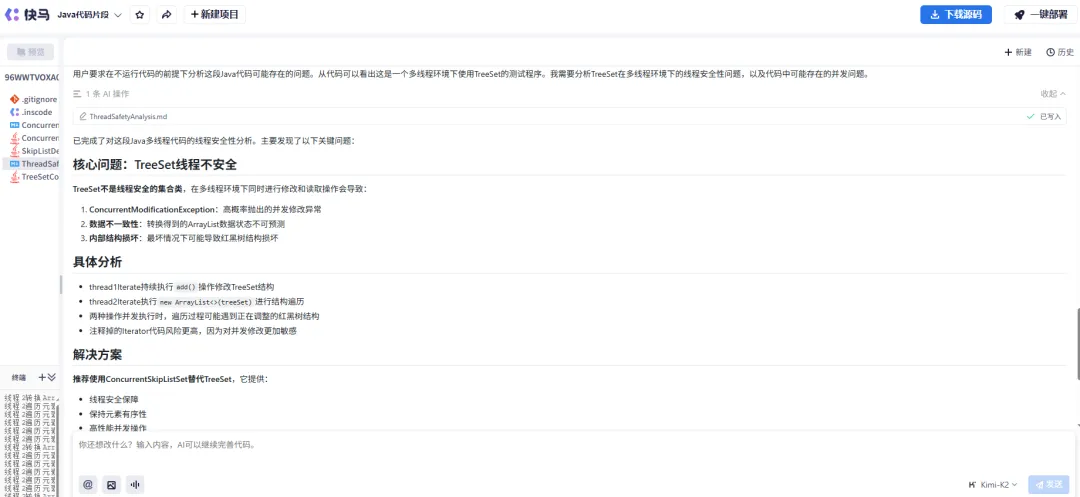
例如:把测试代码给InsCode AI给出的分析结果:
Java并发编程的精髓在于理解各种工具的特性和适用场景,避免"一把锤子敲所有钉子"的思维。TreeSet的并发问题及其解决方案正是这一理念的生动体现,希望本文的分析能为大家提供有价值的参考。