在日常工作中,经常要处理各种文件,Python到底怎么操作CSV、Word、Excel这些办公文件呢?有很多简单重复的劳动如何交给 Python 程序来处理呢?今天就给大家做一个系统的总结,把Python操作各种办公文件的核心要点都梳理清楚,记得收藏!
一、CSV文件操作
CSV是最简单、最通用的数据格式。Python内置的csv模块就够用了。
核心代码
import csv# 写入CSV文件with open('output.csv', 'w', encoding='utf-8', newline='') as f:# w 为写 writer = csv.writer(f) writer.writerow(['姓名', '年龄', '城市']) # 写表头 writer.writerow(['张三', 25, '北京']) # 写数据行 writer.writerows([['李四', 30, '上海'], # 批量写多行 ['王五', 28, '广州']])# 读取CSV文件with open('output.csv', 'r', encoding='utf-8') as f:# r为读 reader = csv.reader(f) for row in reader: print(row) # 每一行是一个列表
注意:如果读取文件时,文件不存在会报错。因此,这里采用先建(写入)一个CSV文件,再读取的步骤,如果已有文件,可以直接读取。
使用字典形式(推荐)
# 写入字典数据with open('output.csv', 'w', encoding='utf-8', newline='') as f: fieldnames = ['姓名', '年龄', '城市'] writer = csv.DictWriter(f, fieldnames=fieldnames) writer.writeheader() # 写表头 writer.writerow({'姓名': '张三', '年龄': 25, '城市': '北京'})# 读取为字典with open('data.csv', 'r', encoding='utf-8') as f: reader = csv.DictReader(f) for row in reader: print(row['姓名'], row['城市']) # 通过列名访问
运行结果
张三 北京
要点总结:
二、Excel文件操作
Python 操作 Excel 需要三方库的支持,如果要兼容 Excel 2007 以前的版本,也就是xls格式的 Excel 文件,可以使用三方库xlrd和xlwt,前者用于读 Excel 文件,后者用于写 Excel 文件。如果使用较新版本的 Excel,即xlsx格式的 Excel 文件,可以使用openpyxl库,当然这个库不仅仅可以操作Excel,还可以操作其他基于 Office Open XML 的电子表格文件。推荐使用openpyxl(处理.xlsx)或pandas(数据分析场景)。
安装环境
pip install openpyxl pandas
使用openpyxl
import openpyxl# 写入Excelwb = openpyxl.Workbook()sheet = wb.activesheet.title = '员工信息'# 写入表头sheet['A1'] = '姓名'sheet['B1'] = '年龄'sheet['C1'] = '城市'# 写入数据sheet.append(['张三', 25, '北京'])sheet.append(['李四', 30, '上海'])# 设置样式from openpyxl.styles import Font, Alignmentsheet['A1'].font = Font(bold=True) # 加粗sheet['A1'].alignment = Alignment(horizontal='center') # 居中# 保存wb.save('output.xlsx')# 读取Excelwb = openpyxl.load_workbook('data.xlsx')sheet = wb.active # 获取活动工作表# 或 sheet = wb['Sheet1'] # 按名称获取# 读取单元格cell_value = sheet['A1'].valuecell_value = sheet.cell(row=1, column=1).value# 遍历所有行for row in sheet.iter_rows(min_row=1, values_only=True):# min_row=1 从第1行开始,如果改为 min_row=2 则第1行表头不显示 name, age, city = row # 假设第一行是表头 print(name, age, city)
运行结果:(min_row=1,)
运行结果:(min_row=2,)
使用pandas(更简洁)
import pandas as pd# 写入Exceldf = pd.DataFrame({ '姓名': ['张三', '李四', '王五'], '年龄': [25, 30, 28], '城市': ['北京', '上海', '广州']})df.to_excel('output.xlsx', index=False) # index=False不写行号# 读取Exceldf = pd.read_excel('data.xlsx', sheet_name='Sheet1')print(df.head()) # 默认查看前5行,查看更多行在括号中加入行数
运行结果:
姓名 年龄 城市0 张三 25 北京1 李四 30 上海2 王五 28 广州
要点总结:
三、Word文件操作
操作Word主要用python-docx库。
安装
读取Word
from docx import Document# 打开文档doc = Document('example.docx')# 读取所有段落for para in doc.paragraphs: print(para.text)# 读取表格for table in doc.tables: for row in table.rows: for cell in row.cells: print(cell.text)
创建和修改Word
from docx import Documentfrom docx.shared import Pt, Inchesfrom docx.enum.text import WD_ALIGN_PARAGRAPH# 创建新文档doc = Document()# 添加标题doc.add_heading('工作报告', level=1)# 添加段落p = doc.add_paragraph('这是第一段内容。')# 更完整的字体样式控制run = p.add_run('带样式的文本')run.bold = True # 加粗run.italic = True # 斜体run.underline = True # 下划线run.font.size = Pt(14) # 字体大小run.font.name = '微软雅黑' # 字体run.font.color.rgb = RGBColor(255, 0, 0) # 红色# 段落对齐方式p.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中# 可选:LEFT, RIGHT, JUSTIFY 等# 段落缩进from docx.shared import Inchesp.paragraph_format.left_indent = Inches(0.5) # 左缩进p.paragraph_format.first_line_indent = Inches(0.3) # 首行缩进p.paragraph_format.space_before = Pt(12) # 段前间距p.paragraph_format.space_after = Pt(12) # 段后间距# 添加表格table = doc.add_table(rows=3, cols=3)table.style = 'Table Grid' # 设置表格样式table.cell(0,0).text = '姓名'table.cell(0,1).text = '年龄'table.cell(0,2).text = '城市'# 表格样式列表table.style = 'Light Grid Accent 1' # 可选样式:# 'Table Grid' - 标准网格# 'Light List' - 浅色列表# 'Medium Grid 3' - 中等网格# 'Dark List' - 深色列表# 合并单元格table = document.add_table(rows=3, cols=3)table.cell(0, 0).merge(table.cell(0, 2)) # 合并第一行前三列# 设置列宽for cell in table.columns[0].cells: cell.width = Cm(3)# 添加图片doc.add_picture('chart.png', width=Inches(5))# 添加页眉section = document.sections[0]header = section.headerheader_para = header.paragraphs[0]header_para.text = "这是页眉内容"# 添加页脚footer = section.footerfooter_para = footer.paragraphs[0]footer_para.text = "第 1 页"# 保存doc.save('output.docx')
要点总结:
完整的实用示例
from docx import Documentfrom docx.shared import Cm, Pt, RGBColor, Inchesfrom docx.enum.text import WD_ALIGN_PARAGRAPHfrom docx.enum.table import WD_TABLE_ALIGNMENTfrom datetime import datetimedef create_work_report(title, author, content_list, table_data): """ 创建工作报告的完整示例 """ doc = Document() # 1. 设置页边距 sections = doc.sections for section in sections: section.top_margin = Cm(2.5) section.bottom_margin = Cm(2.5) section.left_margin = Cm(2.5) section.right_margin = Cm(2.5) # 2. 添加标题 title_para = doc.add_paragraph() title_para.alignment = WD_ALIGN_PARAGRAPH.CENTER run = title_para.add_run(title) run.font.size = Pt(20) run.font.bold = True run.font.name = '黑体' # 3. 添加作者和日期信息 info_para = doc.add_paragraph() info_para.alignment = WD_ALIGN_PARAGRAPH.CENTER info_para.add_run(f"报告人:{author} ") info_para.add_run(f"日期:{datetime.now().strftime('%Y年%m月%d日')}") # 4. 添加内容 for i, content in enumerate(content_list, 1): # 添加小标题 heading = doc.add_heading(f'{i}. {content["title"]}', level=2) # 添加正文 p = doc.add_paragraph(content['text']) p.paragraph_format.first_line_indent = Inches(0.3) # 如果有列表项 if 'items' in content: for item in content['items']: doc.add_paragraph(item, style='List Bullet') # 如果有图片 if 'image' in content: doc.add_picture(content['image'], width=Cm(12)) # 添加图片说明 caption = doc.add_paragraph(content.get('caption', '')) caption.alignment = WD_ALIGN_PARAGRAPH.CENTER caption.runs[0].italic = True # 5. 添加数据表格 doc.add_heading('数据统计', level=1) if table_data: table = doc.add_table(rows=len(table_data), cols=len(table_data[0])) table.style = 'Light Grid Accent 1' table.alignment = WD_TABLE_ALIGNMENT.CENTER # 填充表格数据 for i, row_data in enumerate(table_data): row = table.rows[i] for j, cell_data in enumerate(row_data): row.cells[j].text = str(cell_data) # 设置表头样式 if i == 0: row.cells[j].paragraphs[0].runs[0].font.bold = True # 6. 添加页眉页脚 section = doc.sections[0] # 添加页眉 header = section.header header_para = header.paragraphs[0] header_para.text = f"{title} - 内部资料" header_para.alignment = WD_ALIGN_PARAGRAPH.CENTER # 添加页脚(使用页码字段) footer = section.footer footer_para = footer.paragraphs[0] footer_para.text = "内部资料" footer_para.alignment = WD_ALIGN_PARAGRAPH.CENTER # 7. 保存文档 filename = f"{title}_{datetime.now().strftime('%Y%m%d')}.docx" doc.save(filename) print(f"报告已生成:{filename}") return filename
运行结果:
报告已生成:2025年2月工作报告_20260213.docx
在文件目录中,多一个名为2025年2月工作报告_20260213的docx文件,打开后如下图所示
四、PowerPoint文件操作
使用python-pptx库操作PPT。
安装
读取PPT
from pptx import Presentation# 打开演示文稿prs = Presentation('example.pptx')# 遍历所有幻灯片for slide in prs.slides: # 遍历幻灯片中的所有形状 for shape in slide.shapes: if hasattr(shape, "text"): # 如果是文本框 print(shape.text) if shape.has_table: # 如果是表格 table = shape.table for row in table.rows: for cell in row.cells: print(cell.text)
创建PPT
from pptx import Presentationfrom pptx.util import Inches, Ptfrom pptx.enum.text import PP_ALIGNfrom pptx.dml.color import RGBColor# 创建演示文稿prs = Presentation()# 选择布局(0是标题幻灯片,1是标题和内容,等等)slide_layout = prs.slide_layouts[1]slide = prs.slides.add_slide(slide_layout)# 设置标题title = slide.shapes.titletitle.text = "Python自动化办公"# 设置内容content = slide.placeholders[1]text_frame = content.text_frametext_frame.text = "主要知识点:"# 添加项目符号p = text_frame.add_paragraph()p.text = "CSV文件操作"p.level = 1 # 缩进级别p = text_frame.add_paragraph()p.text = "Excel文件操作"p.level = 1# 添加新幻灯片slide2 = prs.slides.add_slide(prs.slide_layouts[5]) # 空白幻灯片left = top = Inches(1)width = Inches(8)height = Inches(1)# 添加文本框txBox = slide2.shapes.add_textbox(left, top, width, height)tf = txBox.text_frametf.text = "这是新添加的文本框"# 保存prs.save('output.pptx')
运行结果:
在文件目录中,多一个名为output的PPT文件,打开后如下图所示
要点总结:
PPT有布局概念,选择合适布局很重要
占位符(placeholder)是预定义好的位置
添加内容前要先获取或创建形状
五、PDF文件操作
PDF操作分为:读取内容(PyPDF2/pdfplumber)和创建PDF(reportlab/fpdf)。
安装
pip install PyPDF2 pdfplumber reportlab
读取PDF(PyPDF2 - 适合基础操作)
import PyPDF2# 读取PDFwith open('example.pdf', 'rb') as file: reader = PyPDF2.PdfReader(file) # 获取页数 num_pages = len(reader.pages) print(f'总页数: {num_pages}') # 读取第一页内容 page = reader.pages[0] text = page.extract_text() print(text) # 合并PDF writer = PyPDF2.PdfWriter() writer.add_page(page) # 保存新PDF with open('output.pdf', 'wb') as output: writer.write(output)
读取PDF(pdfplumber - 适合表格和复杂布局)
import pdfplumberwith pdfplumber.open('example.pdf') as pdf: # 获取第一页 page = pdf.pages[0] # 提取文本 text = page.extract_text() # 提取表格 table = page.extract_table() for row in table: print(row)
创建PDF(reportlab)
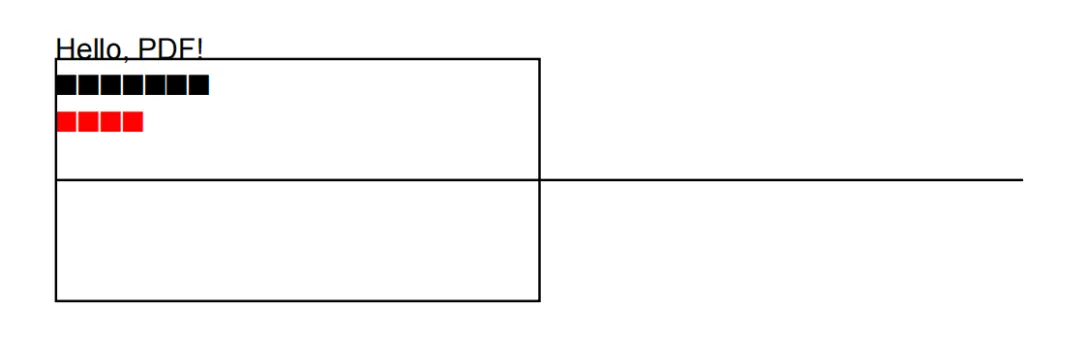
from reportlab.lib.pagesizes import letterfrom reportlab.pdfgen import canvasfrom reportlab.lib.units import inch# 创建PDFc = canvas.Canvas("output.pdf", pagesize=letter)# 设置字体c.setFont("Helvetica", 12)# 写文本c.drawString(100, 750, "Hello, PDF!")c.drawString(100, 735, "这是第二行文本")# 设置颜色c.setFillColorRGB(1,0,0) # 红色c.drawString(100, 720, "红色文字")# 画线c.line(100, 700, 500, 700)# 画矩形c.rect(100, 650, 200, 100)# 保存c.save()
运行结果:
在文件目录中,多一个名为output的pdf文件
打开后如下图所示
要点总结:
六、实战小技巧
1. 异常处理
try: # 文件操作代码 with open('file.xlsx', 'rb') as f: # ...except FileNotFoundError: print("文件不存在")except Exception as e: print(f"出错啦:{e}")
2. 批量处理
import osimport glob# 批量处理Excel文件for file in glob.glob('data/*.xlsx'): df = pd.read_excel(file) # 处理数据... df.to_excel(f'processed/{os.path.basename(file)}')
3. 路径处理
from pathlib import Path# 现代路径处理方式data_dir = Path('data')output_dir = Path('output')# 确保目录存在output_dir.mkdir(exist_ok=True)# 组合路径file_path = data_dir / 'report.xlsx'
Python操作办公文件的生态已经非常成熟,记住这几条原则:
最关键的还是多练习!把常用的代码片段整理成自己的工具函数库,以后工作中遇到就能信手拈来。




