前言
- 六年多以前,我第一次爬取了Instagram上周杰伦的所有帖子内容,写了这篇文章:python爬取Instagram上偶像的帖子(包括图片和视频)(https://blog.csdn.net/sinat_39629323/article/details/103178633)
- 但最近收到了好几个粉丝朋友的反馈,说以前的代码已经不能用了,不用想那是必然的了,因为这么多年过去了,接口的调用逻辑肯定会有变化的
- 所以这次我决定满足一下粉丝的期待,重新爬取一下,并再次把这个过程记录下来
一、接口分析
| | |
|---|
| https://www.instagram.com/graphql/query | https://www.instagram.com/graphql/query |
| | post |
| | |
| | 少了评论内容 |
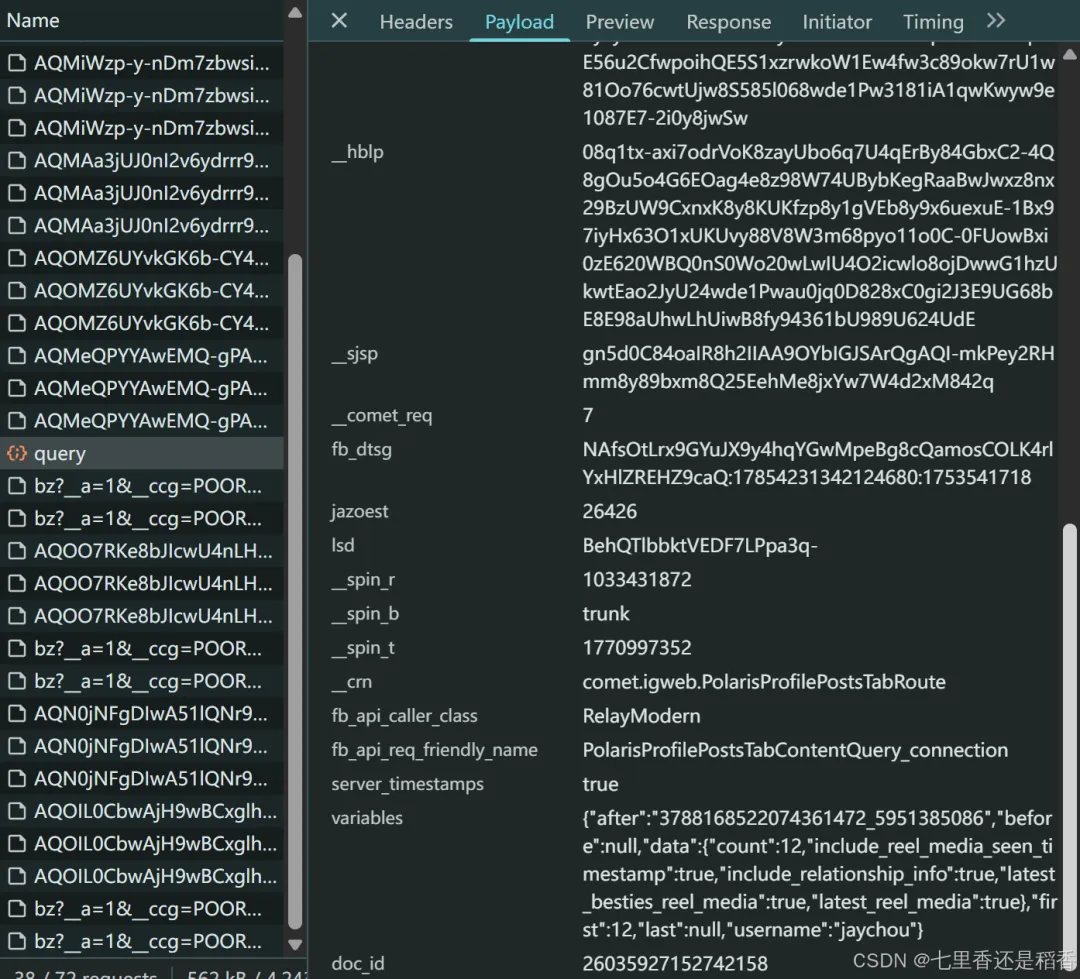
总的来说,虽然接口url没变,但现在需要传更多加密的参数了,需要逐个击破才行,
而以前只需修改qvf一个参数值,并且下一次请求需要传的qvf值就在本次返回的json数据结果中,
并且现在的接口返回中少了评论内容,需求再去请求一个专门获取评论数据的接口才行。
一顿分析过后,我决定另辟蹊径,找到了一个绝佳的方案!!
二、抓包工具
我使用的是开源的抓包工具:proxypin(https://github.com/wanghongenpin/proxypin)
发现它有一个很好的功能:上报服务器,它可以按照配置好的上报规则,将对应接口中所有请求的内容和返回的结果,全部打包发送到自己定义的一个服务器上
通过上面的接口分析,我们知道,只要能请求到这个接口并获取其返回的json数据,就能拿到我们所需要的字段信息了
然后在网页中向下滚动页面时,新的帖子就会加载出来,因为网站会自动给这个接口发送一次AJAX请求,以获取新的数据进行渲染
那么自然而然地,就能想到一个完美的解决方案:就是写一个flask服务器来接收proxypin抓到的请求,并将请求里面的所有内容保存下来,同时用自动化模拟工具操作页面,使它一直向下滚动 ,从而不断加载出新的数据,让proxypin抓包并且上报服务器即可!!
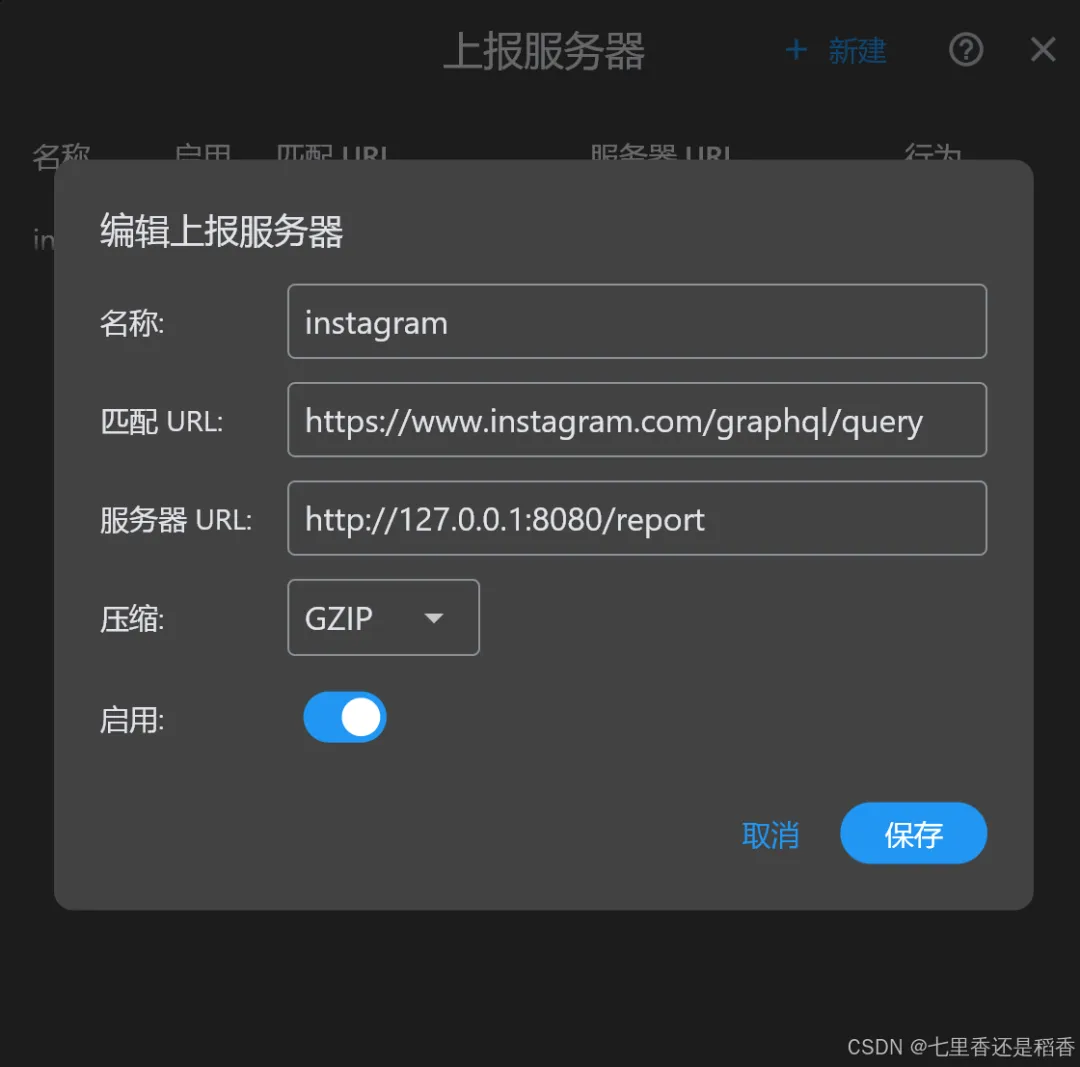
这个接口是用flask框架写的,proxypin的wiki中也提供了完整的示例代码(https://github.com/wanghongenpin/proxypin/wiki/上报服务器),直接复制就能用。
另外,proxypin相关的配置也需要设置一下,比如添加外部代理、启用HTTPS、安装证书等等。
三、接口信息保存
- 用
DrissionPage接管浏览器,从而实现自动模拟页面向下滚动的操作 - 打开
proxypin抓包,按配置自动上报接口的请求结果详细数据 - 当
flask服务接口接收数据包后,处理与保存到 HAR文件中 - 最后再处理保存的
HAR文件,提取文案、发布日期、点赞数、评论数、图片链接、视频链接等数据
模拟页面向下滚动:
import timefrom DrissionPage import Chromiumtab = Chromium('127.0.0.1:9527').latest_tabtab.get('https://www.instagram.com/jaychou')for _ in range(10000): tab.actions.scroll(10000) time.sleep(15)
提取由flask服务接口处理后保存的HAR文件:
import zstandard,os,jsonfrom tqdm import tqdmdctx=zstandard.ZstdDecompressor()result=[]root_path='../data/received_har'for path in tqdm(sorted([f'{root_path}/{i}'for i in os.listdir(root_path)])):with open(path, 'r',encoding='utf-8') as f: res=json.load(f) dctx_res=dctx.decompress(res['log']['entries'][-1]['response']['content']['text'].encode('latin1')).decode() res=json.loads(dctx_res)# res即Instagram原始接口返回的json数据了,提取需要的字段即可。
四、图片和视频下载
通过上一步骤,已经处理并提取完所有帖子的内容了,但是还没有开始爬取每个帖子中的图片和视频,因为只是提取了对应的链接,又因为这些链接一般不会改变,因此可以分开单独进行爬取
另外,在处理接口返回的json数据时,发现图片会有多个尺寸,视频也会有多个清晰度,于是我这里只提取了最大尺寸的图片链接和最高清的视频链接,并且还发现了,有些视频和该视频中的音频是分开的,分别有各自的链接,因此后续还需要再处理一下,将视频和音频进行合成
由于图片和视频非常多,因此,非常有必要使用多线程下载,加快数据爬取的效率:
defdownload_file(url, filename, timeout=180, retry=10):if os.path.exists(filename):return'existed.'for _ in range(retry): time.sleep(np.random.uniform(1,10))try: response = requests.get(url, headers=HEADERS, stream=True, timeout=timeout, proxies=proxies) response.raise_for_status()with open(filename, 'wb') as f:for chunk in response.iter_content(chunk_size=8192):if chunk: f.write(chunk)except:passelse:return'done.'else:returnf"retry {retry} times all failed."HEADERS = {'Referer': 'https://www.instagram.com/','Accept-Language': 'en-US,en;q=0.5','Connection': 'keep-alive',"origin": "https://www.instagram.com","sec-ch-ua": "\"Not(A:Brand\";v=\"8\", \"Chromium\";v=\"144\", \"Google Chrome\";v=\"144\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\"","upgrade-insecure-requests": "1","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36","accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7","sec-fetch-site": "none","sec-fetch-mode": "navigate","sec-fetch-user": "?1","sec-fetch-dest": "document","accept-encoding": "gzip, deflate","accept-language": "zh-CN,zh;q=0.9","priority": "u=0, i"}executor=ThreadPoolExecutor(max_workers=6)task_list = []task_params = {}urls=set()for idx,row in result.iterrows(): url=None media_urls_map={'jpg':{},'mp3':{},'mp4':{}} pk=row['pk'] save_dir=f'../data/Instagram/JayChou/{pk}' os.makedirs(save_dir,exist_ok=True) caption=''if row['caption'] isnotNoneand row['caption'] == row['caption']: caption=row['caption']with open(f'{save_dir}/caption.txt','w',encoding='utf-8') as f: f.write(caption)if row['medias'] isnotNoneand row['medias'] == row['medias']:for jdx,media in enumerate(row['medias']):if'url'in media: url=media['url']elif'media'in media: url=media['media']['url']else:raiseassert url notin urls urls.add(url) suffix=urlparse(url).path.split('.')[-1] suffix='jpg'if suffix == 'heic'else suffix filename=f'{save_dir}/{len(media_urls_map[suffix])+1}.{suffix}' media_urls_map[suffix].update({url:filename}) task = executor.submit(download_file, url, filename) task_params[task] = {'idx':f'{idx+1}/{len(result)}{jdx+1}/{len(row["medias"])}','url':url,'filename':filename} task_list.append(task)if row['video/mp4'] isnotNoneand row['video/mp4'] == row['video/mp4']:if'base_url'in row['video/mp4']: url=row['video/mp4']['base_url']elif'url'in row['video/mp4']: url=row['video/mp4']['url']else:raiseassert url notin urls urls.add(url) suffix=urlparse(url).path.split('.')[-1] suffix='jpg'if suffix == 'heic'else suffix filename=f'{save_dir}/{len(media_urls_map[suffix])+1}.{suffix}' media_urls_map[suffix].update({url:filename}) task = executor.submit(download_file, url, filename) task_params[task] = {'idx':f'{idx+1}/{len(result)} 1/1','url':url,'filename':filename} task_list.append(task)if row['audio/mp4'] isnotNoneand row['audio/mp4'] == row['audio/mp4']:if'base_url'in row['audio/mp4']: url=row['audio/mp4']['base_url']elif'url'in row['audio/mp4']: url=row['audio/mp4']['url']else:raiseassert url notin urls urls.add(url) suffix=urlparse(url).path.split('.')[-1]assert suffix == 'mp4' suffix='mp3' filename=f'{save_dir}/{len(media_urls_map[suffix])+1}.{suffix}' media_urls_map[suffix].update({url:filename}) task = executor.submit(download_file, url, filename) task_params[task] = {'idx':f'{idx+1}/{len(result)} 1/1','url':url,'filename':filename} task_list.append(task)assert url isnotNoneerror_params=[]for task in as_completed(task_list): msg = task.result() params = task_params[task] print(f"[{params['idx']}] msg={msg} filename={params['filename']} url={params['url']}")if msg notin ['done.','existed.']: error_params.append(params)executor.shutdown()len(error_params),error_params
五、数据结果展示
从返回的json数据中可以分析出:每个帖子会有一个唯一的pk字段,这个应该是就相当于ID字段,因此可以用它来区分帖子,可以直接用它来创建对应的文件夹,用于保存该帖子的全部图片和视频文件。
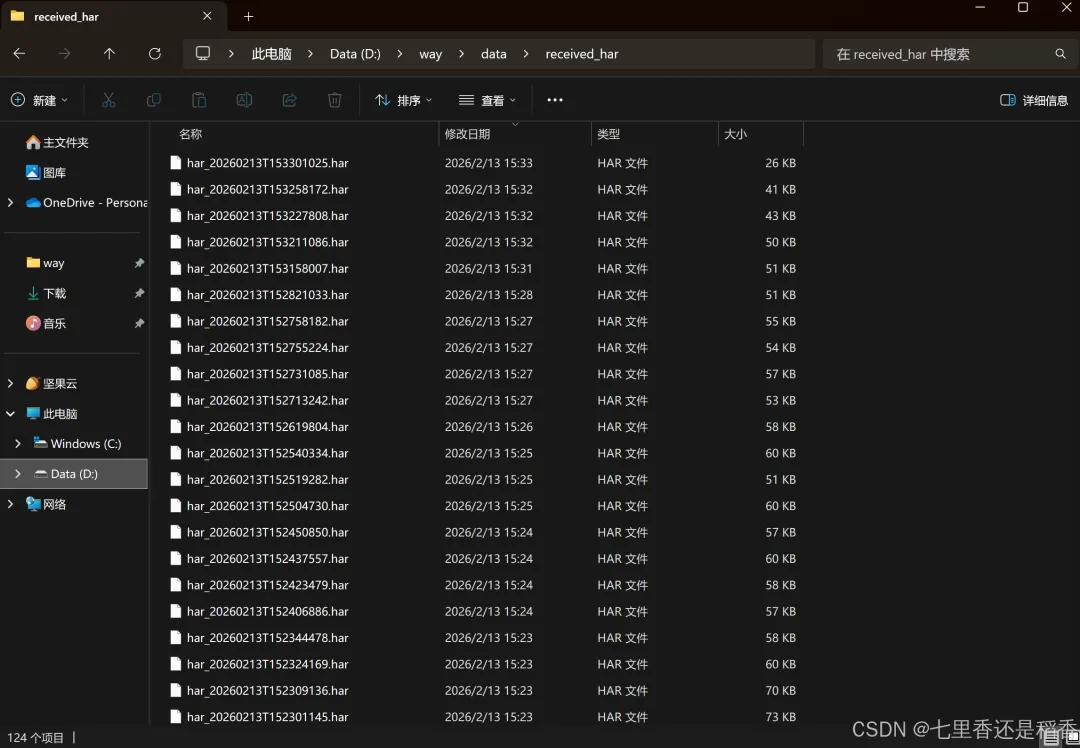
flask服务处理proxypin抓包上报的数据,所有保存的HAR文件:
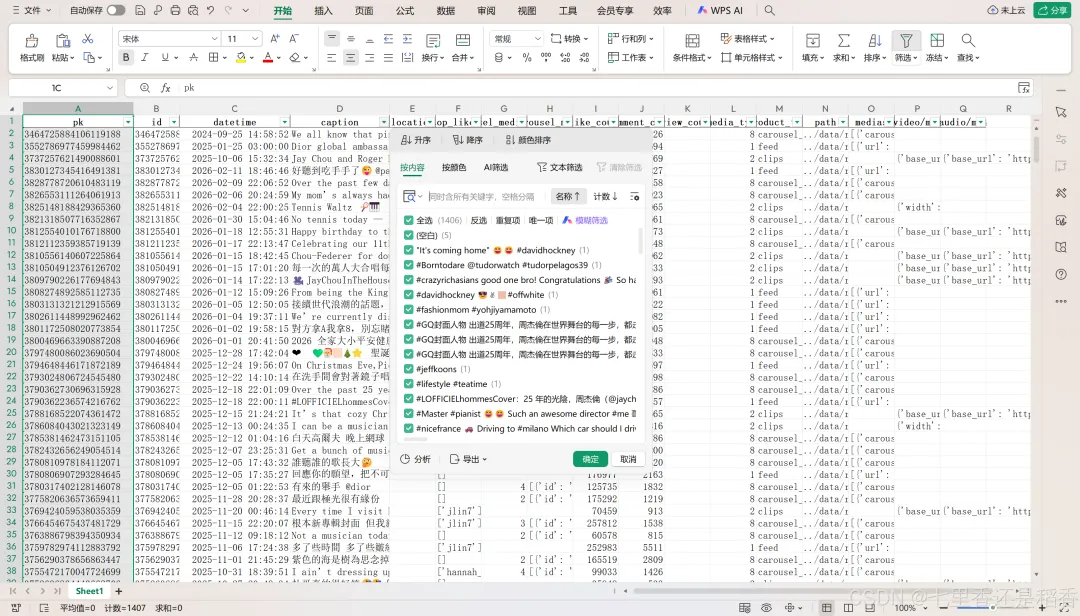
从HAR文件中提取的全部帖子的关键信息:
下载完后,杰伦所有帖子的相关图片和视频文件数据:
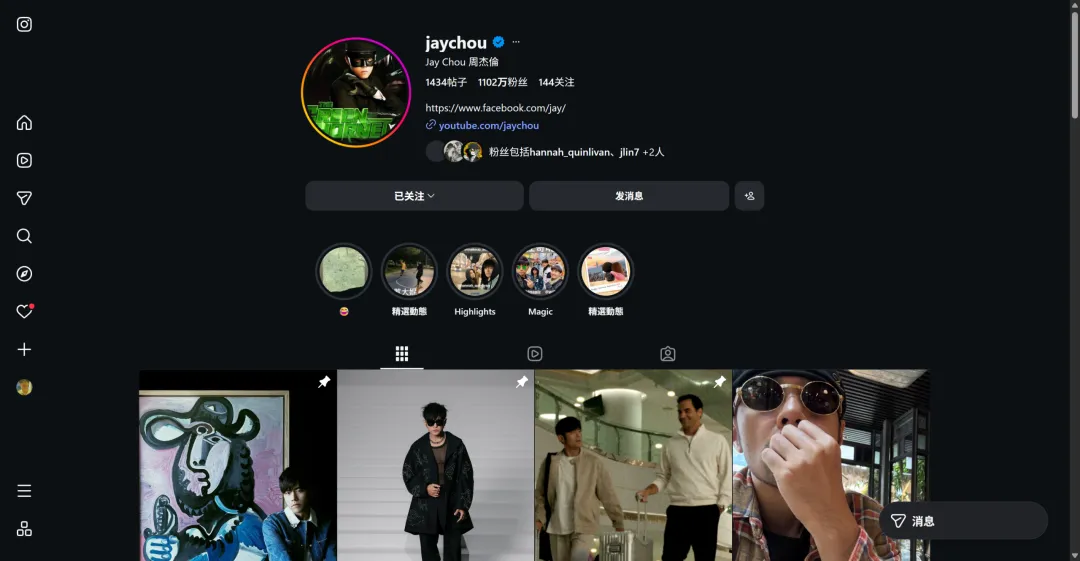
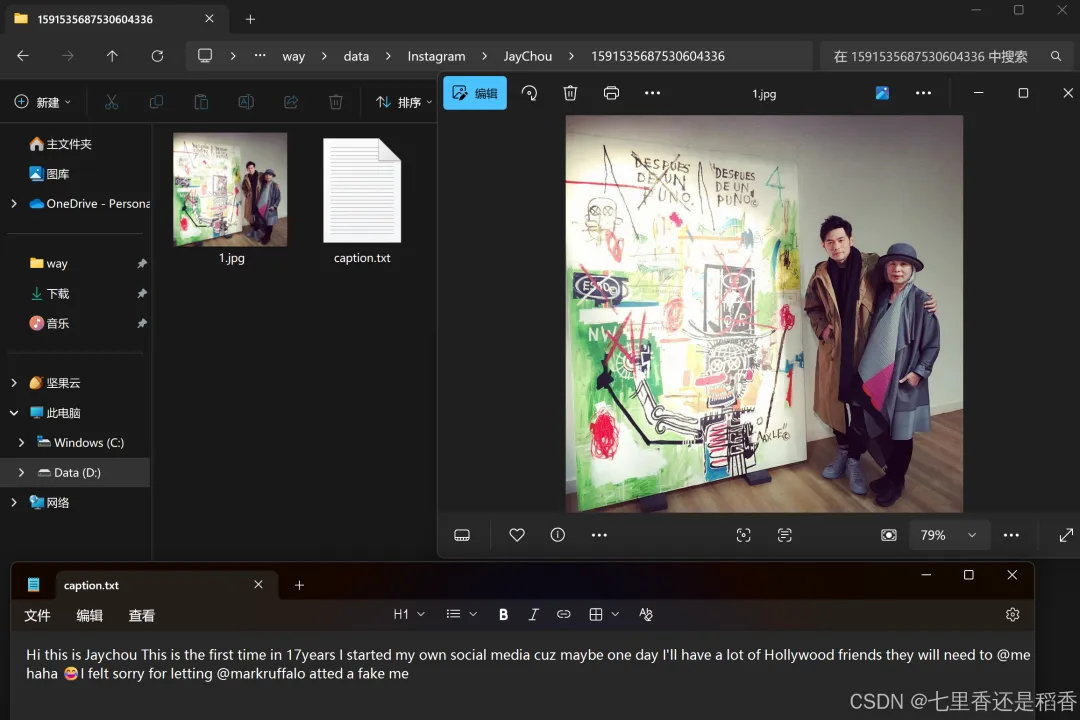
2017年8月29日,杰伦在Instagram上发布的第一条帖子内容:
以上即为本文的全部内容,若需要全部源代码的,请关注公众号《Python王者之路》,回复关键词:20260214,即可获取。
写在最后
虽然没有像第一篇文章一样,直接模拟接口请求来爬取数据,但是这种将抓包数据直接保存下来,不用分析接口的调用逻辑,也不失为一种完美(曲线救国)的方案了~
如果你有更好的方案,也欢迎一起交流哦~
当然,如果你是杰迷,也欢迎一起交流哦~
最后,祝大家新春快乐,马年行大运!!