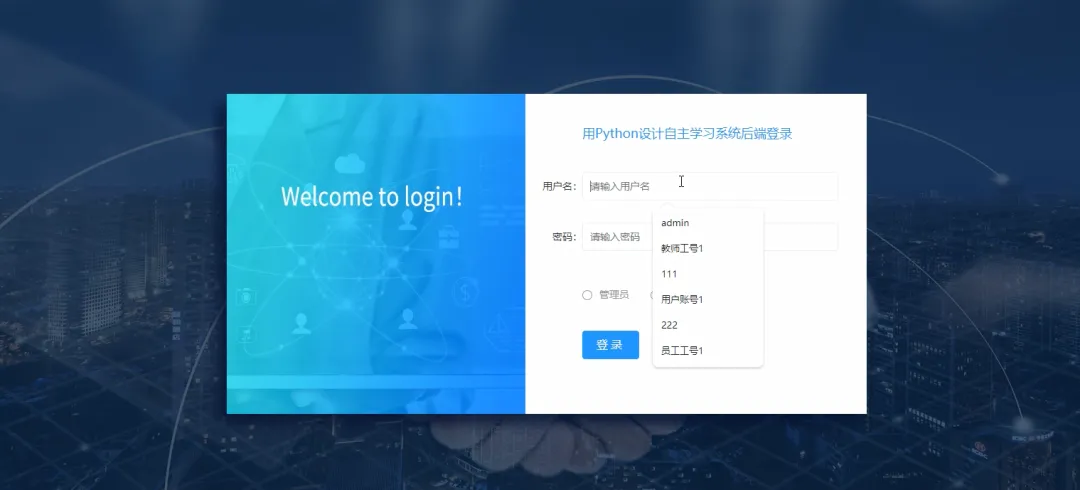
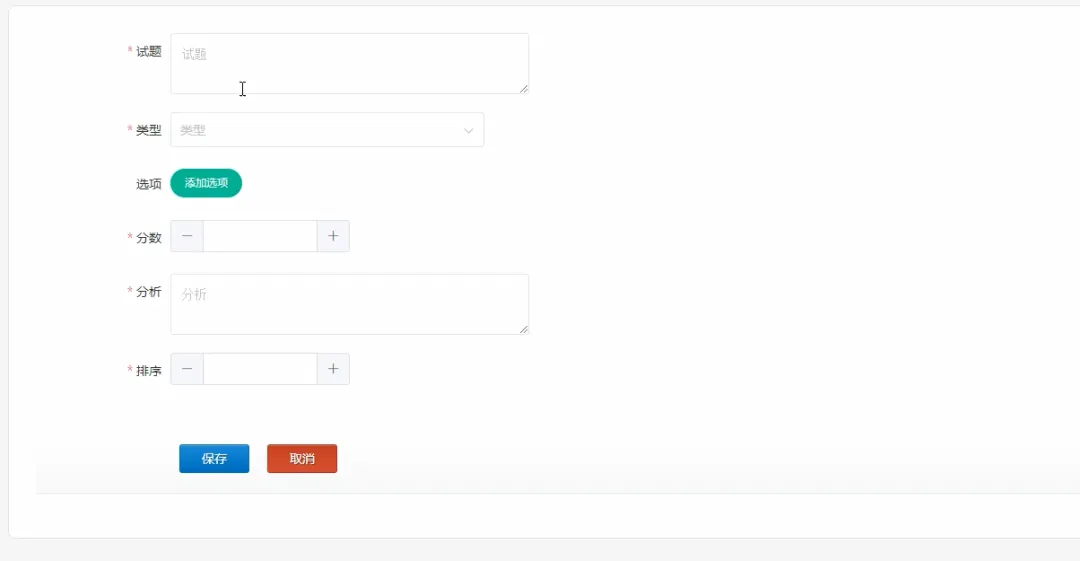
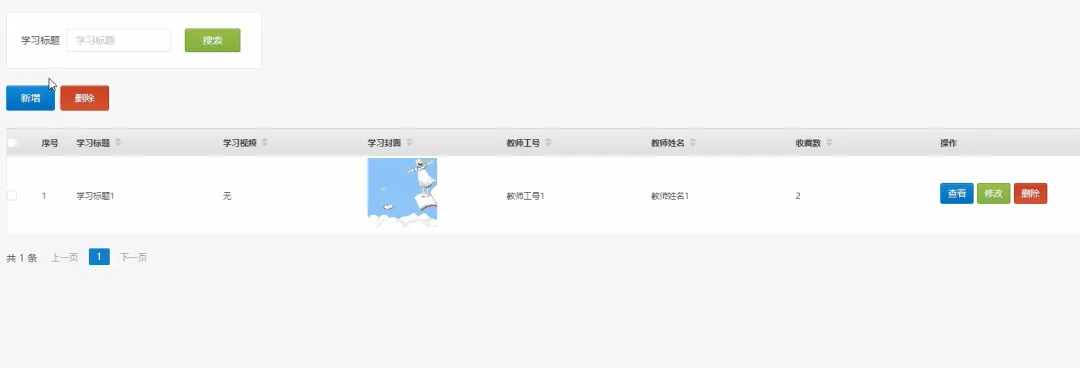
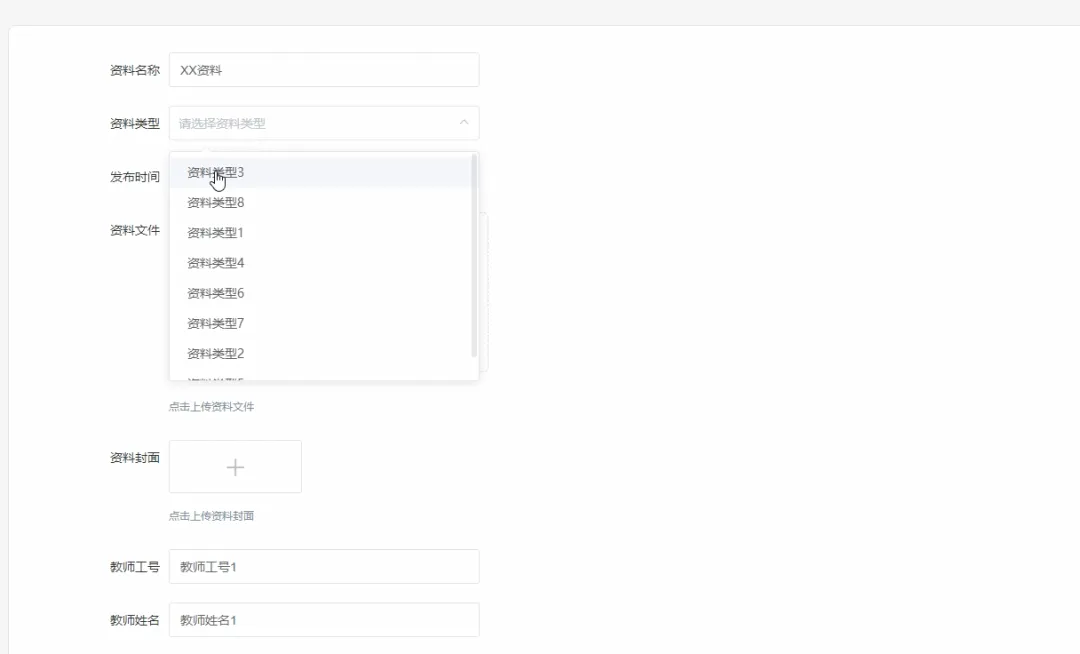
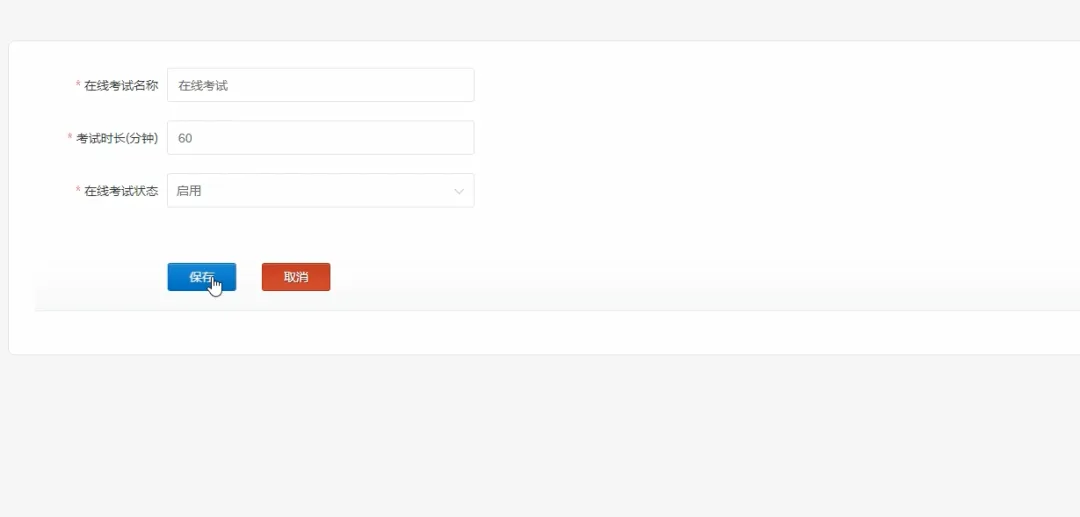
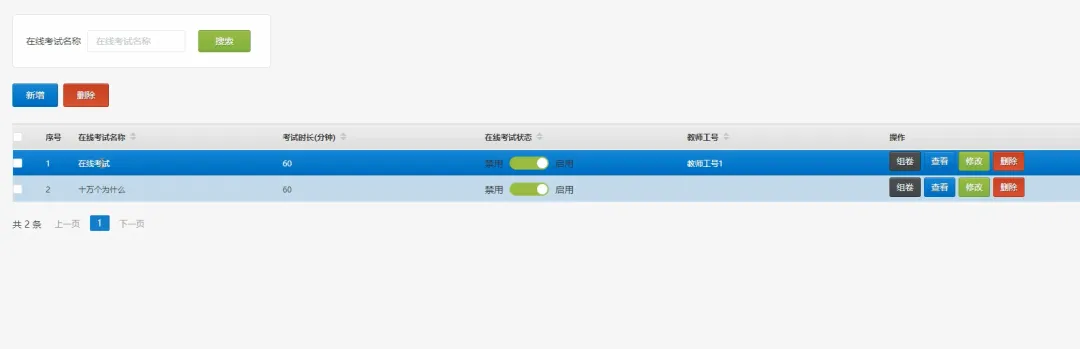
# 假设我们使用Spark进行大规模用户学习行为分析,以生成更精准的推荐spark = SparkSession.builder.appName("DesignLearningSystem").getOrCreate()def generate_learning_path(user_id): # 1. 从MySQL加载用户基本信息和学习历史记录(模拟为DataFrame) user_history_df = spark.read.format("jdbc").options(url="jdbc:mysql://localhost:3306/design_learning", dbtable="user_learning_history", user="root", password="password").load() # 2. 加载所有课程信息(模拟为DataFrame) courses_df = spark.read.format("jdbc").options(url="jdbc:mysql://localhost:3306/design_learning", dbtable="courses", user="root", password="password").load() # 3. 分析目标用户的兴趣标签和已掌握技能 user_profile = user_history_df.filter(user_history_df.user_id == user_id).select("interest_tags", "mastered_skills").first() interest_tags = user_profile.interest_tags.split(',') # 4. 基于协同过滤算法,找到相似用户群体 similar_users = user_history_df.filter(user_history_df.interest_tags.rlike('|'.join(interest_tags))).groupBy("course_id").count().orderBy("count", ascending=False) # 5. 筛选出用户未学过但相似用户高频学习的课程 recommended_courses_df = similar_users.join(courses_df, "course_id").filter(~courses_df.course_id.isin(user_history_df.select("course_id").rdd.flatMap(lambda x: x).collect())) # 6. 选取前5个作为推荐路径,并格式化结果 recommended_path = recommended_courses_df.select("course_id", "course_name", "difficulty").limit(5).collect() # 7. 将推荐结果存入缓存或返回给上层调用 return [{"course_id": row.course_id, "name": row.course_name, "difficulty": row.difficulty} for row in recommended_path]def submit_and_grade_assignment(user_id, assignment_id, file_object): # 1. 获取作业要求信息,例如关键词、文件类型等 assignment = Assignments.objects.get(id=assignment_id) required_keywords = assignment.required_keywords.split(',') # 2. 保存用户上传的文件到指定目录 file_path = f'submissions/user_{user_id}/assignment_{assignment_id}/{file_object.name}' default_storage.save(file_path, file_object) # 3. 初始化分数和反馈 score = 60 # 基础分 feedback = "作业已提交," # 4. 简单的自动评分逻辑:检查文件内容是否包含关键词 if file_path.endswith('.txt') or file_path.endswith('.md'): with default_storage.open(file_path, 'r') as f: content = f.read() found_keywords = [kw for kw in required_keywords if kw in content] score += len(found_keywords) * 10 feedback += f"内容中找到关键词:{', '.join(found_keywords)}。" else: feedback += "非文本文件,暂不支持内容分析。" # 5. 将评分结果和文件路径存入数据库 Submission.objects.update_or_create(user_id=user_id, assignment_id=assignment_id, defaults={'file_path': file_path, 'score': score, 'feedback': feedback, 'status': 'graded'}) # 6. 更新用户总进度 update_user_progress(user_id) # 7. 返回评分结果给前端 return {"status": "success", "score": score, "feedback": feedback}def update_user_progress(user_id): # 1. 获取该用户需要完成的总课程数和作业数 total_courses = Courses.objects.count() total_assignments = Assignments.objects.count() # 2. 查询用户已完成的课程和已提交的作业 completed_courses = UserProgress.objects.filter(user_id=user_id, status='completed').count() submitted_assignments = Submission.objects.filter(user_id=user_id).count() # 3. 计算完成百分比 course_progress = (completed_courses / total_courses) * 100 if total_courses > 0 else 0 assignment_progress = (submitted_assignments / total_assignments) * 100 if total_assignments > 0 else 0 # 4. 计算平均作业得分 avg_score = Submission.objects.filter(user_id=user_id).aggregate(avg_score=Avg('score'))['avg_score'] or 0 # 5. 综合计算总体进度(可自定义权重) overall_progress = (course_progress * 0.4) + (assignment_progress * 0.6) # 6. 将计算出的进度数据更新或存入用户进度表 progress_record, created = UserOverallProgress.objects.get_or_create(user_id=user_id) progress_record.course_progress = course_progress progress_record.assignment_progress = assignment_progress progress_record.overall_progress = overall_progress progress_record.average_score = avg_score progress_record.save() # 7. 可以触发一个信号,通知前端实时更新进度条 return overall_progress