最近刷到 MachineLearningMastery 上的一篇文章,讲 Python 内存管理的。我觉得这个话题挺有意思,虽然平时咱们写 Python 代码写得飞起,很少像写 C 语言那样还要手动去 malloc 和 free,但如果你不知道底层发生了什么,遇到性能瓶颈或者内存泄漏的时候,真的会两眼一抹黑。
咱们先聊聊“省心”背后的代价。
很多刚从 C/C++ 转过来的朋友,刚接触 Python 时最大的感慨可能就是:太爽了,变量随便造,根本不用管回收。这确实是 Python 的一大优势,它把内存管理完全自动化了。
但是,这种“自动化”不是魔法,它背后有一套非常复杂的机制在运行。文章里提到了两个核心概念,我觉得非常值得拿出来跟大家唠唠:引用计数(Reference Counting)和垃圾回收(Garbage Collection)。
简单来说,Python 里的一切皆对象。
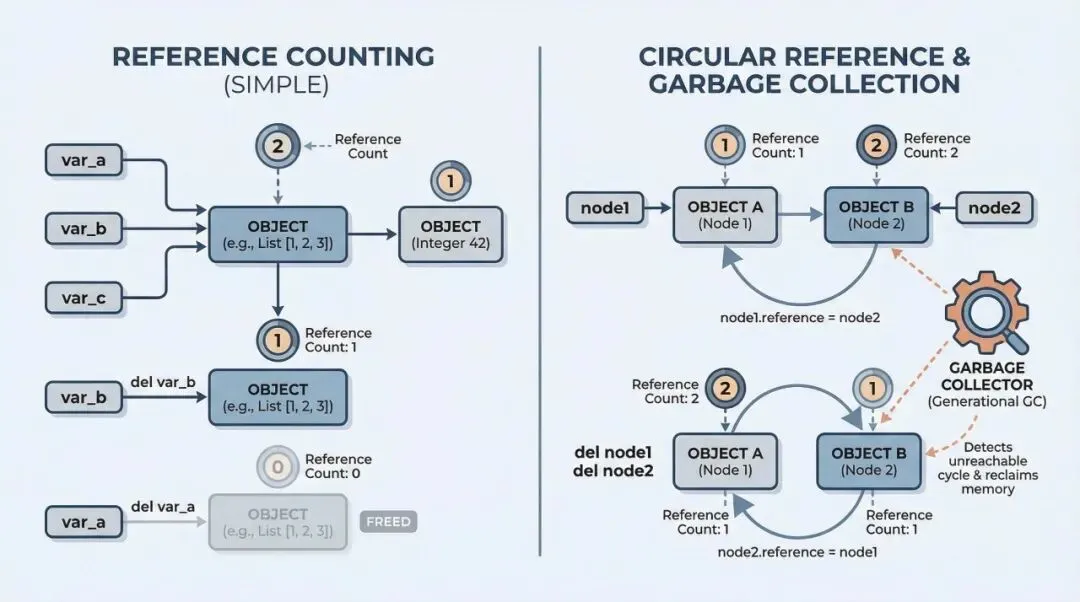
当你创建一个变量,比如 a = 100,Python 其实是在内存里创建了一个整数对象,然后把 a 这个名字贴到了这个对象上。这时候,这个对象的“引用计数”就是 1。
如果我又写了 b = a,那这个对象的引用计数就变成了 2。反过来,如果我把 a 删了或者指向别的东西,计数就减 1。一旦计数变成 0,Python 就会毫不留情地把这块内存回收掉。
但这套机制有个大坑:循环引用。
试想一下,对象 A 引用了 B,对象 B 又引用了 A。就算你在外面把 A 和 B 都删了,它俩在内部还是互相指着对方,引用计数永远不为 0。这时候,光靠引用计数就没辙了,内存直接泄漏。
这时候就轮到 Python 的垃圾回收器(Garbage Collector)出场了。我看文章里把这个机制讲得挺清楚,Python 用的是“分代回收”的策略。它把对象分成三代:
- 第 0 代: 新生的对象。大部分对象都是“朝生暮死”的,所以这一代检查得最勤快。
- 第 1 代: 在第 0 代里幸存下来的老兵。
- 第 2 代: 活得最久的老古董,检查频率最低。
这种设计非常聪明,因为它利用了一个统计学规律:大部分对象很快就会变得没用。所以把精力集中在新生对象上,效率最高。
这给我的一点启示:
虽然咱们平时不用手动管内存,但写代码的时候稍微留个心眼还是很有必要的。比如处理超大数据集的时候,或者写长驻后台的服务时,了解这些机制能帮你避开很多莫名其妙的 OOM(内存溢出)崩溃。
总之,Python 虽然是个“保姆级”语言,但作为一个追求极致的极客,稍微懂点底层的原理,写出来的代码绝对更有“灵性”。
感兴趣的朋友可以去看看原文,里面还有很多关于内存池(Memory Pool)和小整数缓存的细节,挺硬核的。
---
来源:MachineLearningMastery.com
原文链接:https://machinelearningmastery.com/everything-you-need-to-know-about-how-python-manages-memory/ 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
