Linux正则表达式
#正则表达式介绍 正则表达式(Regular Expression,缩写为 regex 或 regexp)是一种强大的文本模式匹配工具,在 Linux 系统中被广泛应用于各种命令行工具(如 grep、sed、awk 等),用于搜索、替换和提取文本。 正则表达式是由普通字符(如字母、数字)和特殊字符(元字符)组成的字符串模式,用于描述一组字符串的特征。通过使用正则表达式,可以高效地匹配、查找和处理符合特定模式的文本。 #基础正则表达式(BRE)和扩展正则表达式(ERE) 1.基础正则表达式(BRE) 在一些简单的文本处理场景中,基础正则表达式通常就足够了。例如,在使用 grep 命令进行简单的文本搜索时,默认使用基础正则表达式。 (1)字符匹配 点号(.):匹配任意单个字符。例如,a.c 可以匹配 abc、aac、adc 等。 方括号([]):用于指定字符集合。例如,[abc] 表示匹配 a、b 或 c 中的任意一个字符;[0-9] 表示匹配任意数字。 (2)重复匹配 星号(*):表示前面的字符或字符集合可以重复 0 次或多次。例如,a* 可以匹配空字符串、a、aa、aaa 等;[0-9]* 表示匹配任意长度的数字字符串。 花括号({}):用于指定重复次数。例如,a{3} 表示匹配连续的 3 个 a;a{2,4} 表示匹配 2 到 4 个连续的 a。 (3)定位符 脱字符(^):表示匹配行首。例如,^a 表示匹配以 a 开头的行。 美元符号($):表示匹配行尾。例如,a$ 表示匹配以 a 结尾的行。 2.扩展正则表达式(ERE) 当需要更复杂的匹配模式和更灵活的操作时,扩展正则表达式更为适用。例如,在使用 egrep 命令(等同于 grep -E)或一些高级的文本处理工具(如 sed、awk)中,可以使用扩展正则表达式来实现更强大的文本处理功能。 (1)字符匹配:与基础正则表达式类似,但在使用字符集合时,扩展正则表达式支持一些额外的语法,如[:digit:] 表示数字字符集合,等同于 [0-9];[:alpha:] 表示字母字符集合等。 (2)重复匹配 加号(+):表示前面的字符或字符集合至少出现 1 次。例如,a+ 可以匹配 a、aa、aaa 等,但不匹配空字符串。 问号(?):表示前面的字符或字符集合可以出现 0 次或 1 次。例如,a? 可以匹配空字符串或 a。 花括号({}):在扩展正则表达式中,花括号的使用更加灵活。例如,a{3,} 表示匹配至少 3 个连续的 a;a{,3} 表示匹配最多 3 个连续的 a。 (3)分组和引用 圆括号(()):用于分组,可以将多个字符或表达式组合在一起,作为一个整体进行操作。例如,(ab)+ 表示匹配一个或多个连续的 ab 字符串。 管道符(|):用于表示或关系。例如,a|b 表示匹配 a 或 b;(ab|cd)表示匹配 ab 或 cd。
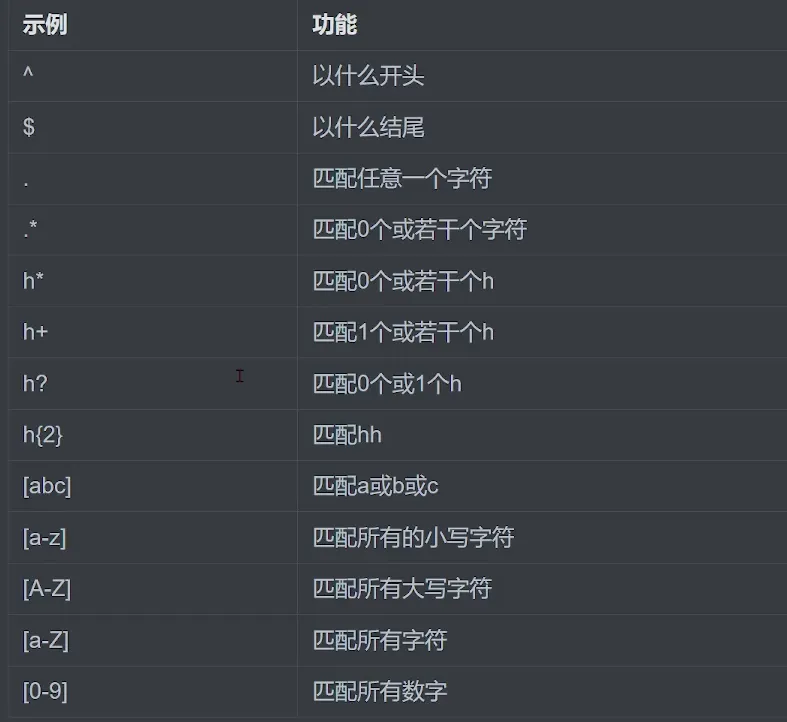
#任何命令只要支持正则表示的参数就可以在命令操作后面加上正则表达式去匹配(reguler expression) regexp 练习:test.txt文件,文本内容如下 cat>> test.txt << END cat caaat catdog cat2dog catanddog dogcat ccat catdogcccc c123t c45678t Cat cAt catdogDogCAT #this is a cat ;this is a dog END grep"cat" test.txt grep-i"cat" test.txt 忽略大小写 grep ^cat test.txt grep dog$ test.txt grep ^catdog$ test.txt grep ^cat.*dog$ test.txt grep ^cat.dog$ test.txt grep ^cat...dog$ test.txt grep-E ^cat.{3}dog$ test.txt 中间3个任意字符 grep ^c[0-9]*t$ test.txt [0-9]* 匹配0个或若干个数字 grep-E ^"[#;]" test.txt grep-e ^"#"-e ^";" test.txt 作用同上,-e 可以同时指定多个表达式
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
