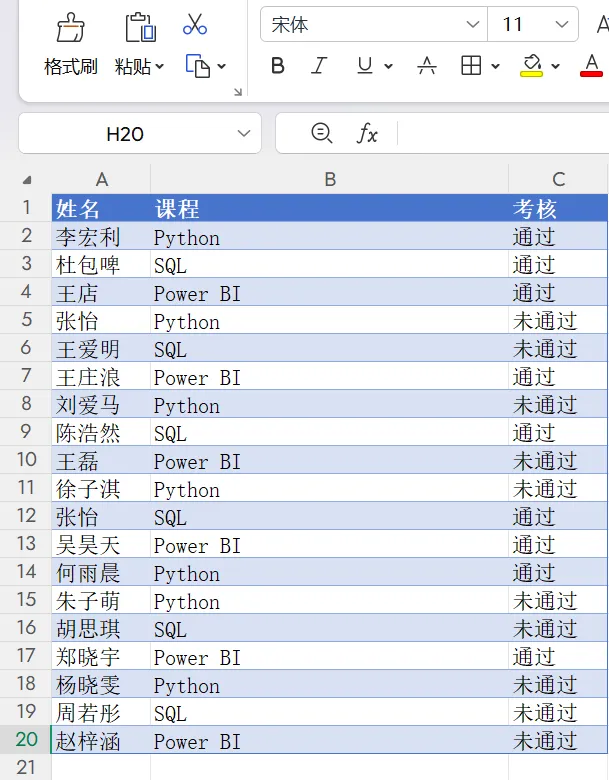
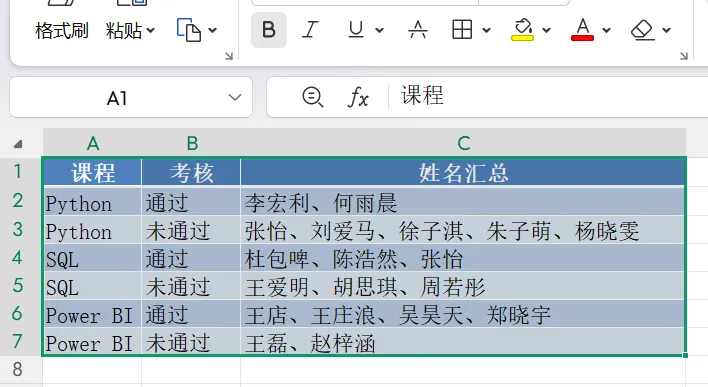
假设你有一份学员考核表 data0215.xlsx,包含“姓名”、“课程”和“考核结果”三列。
你的目标是生成一份汇总表,要求如下:
2. 核心代码实现
直接上干货,下面是使用 Pandas 实现该逻辑的完整代码:
import pandas as pd
# 1. 读取数据
# 文件名为 data0215.xlsx
df = pd.read_excel('data0215.xlsx')
# 2. 按 '课程' 和 '考核' 分组,并对 '姓名' 进行拼接
# 使用 join 函数将相同组合下的姓名连成一个字符串
result = df.groupby(['课程', '考核'])['姓名'].apply(lambda x: '、'.join(x)).reset_index()
# 3. 整理格式:为了匹配你要求的顺序,可以自定义课程排序(可选)
category_order = ['Python', 'SQL', 'Power BI']
result['课程'] = pd.Categorical(result['课程'], categories=category_order, ordered=True)
result = result.sort_values(['课程', '考核'], ascending=[True, False]) # 通过在前,未通过在后
# 4. 重命名列名为“姓名汇总”
result.columns = ['课程', '考核', '姓名汇总']
# 5. 保存结果或打印
print(result)
result.to_excel('汇总结果.xlsx', index=False)
3. 关键技术点深度拆解
A. groupby + apply:汇总的灵魂
这是整段代码的“大招”。
groupby(['课程', '考核']):将数据切分成一个个小块,每一块拥有相同的课程和考核状态。apply(lambda x: '、'.join(x)):这是对每一块数据执行的动作。x 代表这一组里的姓名列,我们利用 Python 字符串的 join 方法将其连成一体。
B. pd.Categorical:掌控排序主动权
默认情况下,Pandas 会按字母顺序排序。但实际工作中,我们往往有自己的业务逻辑(比如:Python > SQL > Power BI)。通过将其转换为 Categorical(分类数据),我们可以赋予这些文本“权重”,从而实现自定义排序。
C. reset_index():从索引变回表格
分组计算后的数据通常会将分组列作为“索引”,这在导出 Excel 时可能导致格式错位。使用 reset_index() 可以让数据重新变回规整的二维表格(DataFrame)。
4. 输出结果
通过 Python,我们成功将繁琐的“复制-粘贴-去重-拼接”过程缩减为了一键运行的代码。这不仅提高了准确率,更让重复性劳动变得可复用。
希望这篇分享能帮你打开 Python 办公自动化的思路!如果你有其他 Excel 处理的难题,欢迎在评论区留言讨论。
🔮 获取和交流
需要源码和源数据的同学,关注+三连,加下面微信!也可以拉你进群交流学习,加群备注:IT小本本学习
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇