Python,工业应用的编程语言
- 2026-07-04 13:58:03
Python,工业应用的编程语言
Python[1] 是一门优雅而健壮的编程语言,它继承了传统编译语言的强大性和通用性,同时也借鉴了脚本语言和解释语言的易用性。
核心理念包括:
• 优美胜于丑陋(Beautiful is better than ugly) • 明了胜于晦涩(Explicit is better than implicit) • 简洁胜于复杂(Simple is better than complex) • 可读性很重要(Readability counts)
Python是由创始人贵铎·范·罗萨姆(Guido van Rossum)在阿姆斯特丹于1989年圣诞节期间,为了打发圣诞节的无趣,开发的一个新的解释型脚本语言。
Python(大蟒蛇)[2] 作为该编程语言的名字,是因为他是BBC当时正在热播的喜剧连续剧“Monty Python”的爱好者。
第一部分:Python 编程语言详尽介绍
1. 历史背景
Python 由荷兰程序员 Guido van Rossum 于 1989 年圣诞节期间在荷兰国家数学与计算机科学研究所(CWI)开始设计。Guido 当时参与了 ABC 语言项目,ABC 虽然语法优美、易教易学,但扩展性差、难以与系统交互。Guido 希望创造一门兼具可读性和系统编程能力的语言。
• 首个公开版本:1991 年 2 月在 alt.sources 发布 Python 0.9.0。 • 命名由来:源自 Guido 喜爱的英国喜剧团体“Monty Python's Flying Circus”(蒙提·派森的飞行马戏团),而非蟒蛇。 • 设计哲学:体现在《The Zen of Python》(PEP 20)中,核心是“简单优于复杂”“可读性至关重要”“应该只有一种显而易见的方式去做一件事”。
2. 重要版本更新
| 破坏性升级 | |||
现状:Python 2 于 2020 年 1 月 1 日正式停止维护,工业界已全面转向 Python 3.x。
3. 语言核心特点(带经典实例)
• 解释型 + 动态强类型:无需编译,变量无需声明类型,但类型检查严格。 • 强制缩进:代码块由缩进决定,强制可读性。 • 多范式:支持面向对象、函数式、命令式。 • “电池内含”:标准库极其丰富。 • 胶水语言:极易与 C/C++ 集成。
经典实例演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 1. 列表推导式 + 条件过滤(Pythonic 风格)even_squares = [x**2 for x in range(20) if x % 2 == 0]print(even_squares) # [0, 4, 16, 36, 64, 100, 144, 196, 256, 324]# 2. 面向对象 + 装饰器def timer(func): import time def wrapper(*args, **kwargs): start = time.perf_counter() result = func(*args, **kwargs) print(f"{func.__name__} 耗时: {time.perf_counter() - start:.4f}s") return result return wrapper@timerdef fibonacci(n): a, b = 0, 1 for _ in range(n): yield a a, b = b, a + blist(fibonacci(20)) # 快速生成前20个斐波那契数,并打印执行时间
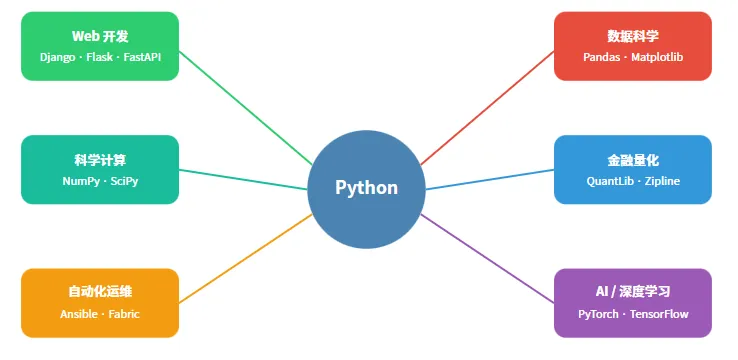
4. 典型应用场景(基于真实案例)
• Web 开发:Django(Instagram 早期)、FastAPI(高性能 API)。 • 自动化与运维:Ansible、Fabric。 • 数据分析:金融、电商、科研的数据清洗与可视化。 • 科学计算:NASA、LIGO 引力波项目。 • 人工智能:当前事实上的标准语言(后文详述)。
第二部分:机器学习与深度学习领域的工业级核心库
Python 在 AI 领域的统治地位源于其生态:底层高性能计算用 C/C++/CUDA 实现,上层接口用 Python 封装,兼顾开发效率与执行速度。
1. NumPy —— 数值计算基石
几乎所有 AI 库的底层依赖,底层由 C 语言编写,支持向量化运算(Vectorization),规避了 Python 循环的低效
核心特性:
• 发布:2006 年 • N 维数组对象(ndarray) • 向量化运算,性能远超纯 Python • 线性代数、傅里叶变换、随机数生成
1 2 3 4 5 6 7 import numpy as npA = np.random.randn(1000, 1000)B = np.random.randn(1000, 1000)%time C = np.dot(A, B) # 底层调用 BLAS,毫秒级完成# 对比纯 Python 列表循环:慢数百倍
2. Pandas —— 结构化数据处理标准
发布:2008 年(Wes McKinney),数据处理和数据分析的关键工具包
| Matplotlib | ||
| Seaborn | ||
| Plotly | ||
| Bokeh | ||
| Altair | ||
| PyEcharts |
核心特性:
• DataFrame 和 Series 数据结构 • 数据清洗、转换、分组、聚合 • 时间序列分析 • 数据读写(CSV、Excel、SQL、JSON 等)
1 2 3 4 5 6 7 8 9 10 import pandas as pddf = pd.DataFrame({ "city": ["北京", "上海", "广州", "深圳"], "temp": [30, 32, 35, 33], "sales": [1000, 1500, 800, 1200]})print(df.groupby("city")["sales"].mean())print(df[df["temp"] > 32]) # 筛选高温城市
3. Scikit-learn —— 经典机器学习
• 发布:2007 年 • 地位:传统 ML 算法的工业标准
核心特性:
• 分类、回归、聚类算法 • 模型选择与评估 • 特征工程 • 管道(Pipeline)机制
1 2 3 4 5 6 7 8 9 10 from sklearn.ensemble import RandomForestClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitiris = load_iris()X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)model = RandomForestClassifier(n_estimators=100)model.fit(X_train, y_train)print(f"准确率: {model.score(X_test, y_test):.3f}")
4. PyTorch —— 当前深度学习主流
深度学习的首选框架,是企业级别的软件包.
• 发布:2016 年(Meta) • 优势:动态计算图、调试友好 • 实际采用:OpenAI GPT 系列、Tesla 自动驾驶、Stable Diffusion
PyTorch 特性:
• Facebook(Meta)开发,动态计算图 • Pythonic 设计,易于调试 • 学术界广泛使用 • TorchScript 用于生产部署
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import torchimport torch.nn as nnclass Net(nn.Module): def __init__(self): super().__init__() self.fc = nn.Sequential( nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10) ) def forward(self, x): return self.fc(x.view(x.size(0), -1))model = Net()x = torch.randn(32, 1, 28, 28) # Batch of 32 MNIST imagesoutput = model(x)print(output.shape) # torch.Size([32, 10])
5. TensorFlow / Keras —— 工业部署标杆
• 发布:TensorFlow 2015(Google),Keras 2015 • 优势:成熟的部署生态(TFLite、TF Serving)
TensorFlow 特性:
• Google 开发的端到端深度学习平台 • 支持分布式训练、移动端部署(TensorFlow Lite) • TensorBoard 可视化 • Keras 高层 API
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tffrom tensorflow import kerasmodel = keras.Sequential([ keras.layers.Dense(64, activation='relu', input_shape=(784,)), keras.layers.Dense(10, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# model.fit(...) # 训练代码省略model.summary()
6、 JAX —— Google 的高性能数值计算库
简介:JAX 是 Google 开发的高性能数值计算库,可以看作是"可微分的 NumPy + XLA 编译器"。它提供了自动微分(grad)、即时编译(jit)、自动向量化(vmap)和并行化(pmap)等功能。
• 开发者:Google Research • GitHub Stars:31k+ • 特点:函数式编程风格、可组合的变换、XLA 编译加速
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import jaximport jax.numpy as jnpfrom jax import grad, jit, vmapfrom jax import random# ==================== 基础操作(NumPy 兼容 API) ====================key = random.PRNGKey(42)x = random.normal(key, (3, 4))print(f"JAX 数组:\n{x}")print(f"设备: {x.devices()}")# ==================== 自动微分 ====================def loss_fn(w, x, y): """简单的线性回归损失函数""" predictions = jnp.dot(x, w) return jnp.mean((predictions - y) ** 2)# 自动计算梯度grad_fn = grad(loss_fn)# 模拟数据key1, key2 = random.split(key)w = random.normal(key1, (4,))X = random.normal(key2, (100, 4))y = jnp.dot(X, jnp.array([1.0, 2.0, 3.0, 4.0])) + 0.1 * random.normal(key, (100,))gradients = grad_fn(w, X, y)print(f"\n梯度: {gradients}")# 高阶导数hessian_fn = jax.hessian(loss_fn)
第三部分:Python vs Julia —— 基于事实的客观对比
| 性能 (速度) | 原生极快 | ||
| 生态成熟度 | 王者地位 | ||
| 二分解问题 | 不存在 | ||
| 编译延迟 | 有(TTFP 问题) | ||
| 多重派发 | 核心特性 |
Julia(2012 年发布,MIT)旨在解决“双语言问题”:原型用易用语言,生产用高性能语言重写。
| 原生性能 | |||
| 调用库性能 | |||
| AI/深度学习生态 | 绝对统治 | ||
| 科学计算特定领域 | 更强 | ||
| 包生态规模 | |||
| 启动/编译延迟 | |||
| 并行能力 | |||
| 工业采用度 | |||
| 学习曲线 |
以上是软件本身的各自优势,还有附加的生态系统,是否有大量的软件包供使用,也是程序员的一个选择主要依据.
| 深度学习 | ||
| 传统 ML | ||
| 数据处理 | ||
| 科学计算 | ||
| 可视化 | ||
| 统计 |
Python 更适合的场景:
1. Web 开发:Django、Flask、FastAPI 生态成熟 2. 数据科学全流程:从数据采集到部署的完整工具链 3. 深度学习生产环境:TensorFlow/PyTorch 生态强大,部署工具丰富 4. 自动化脚本:丰富的标准库和第三方工具 5. 快速原型开发:开发速度快,调试方便 6. 教学与入门:语法简洁,学习曲线平缓 7. 跨平台应用:移动端、嵌入式部署(TensorFlow Lite)
| 设计目标 | ||
| 首次发布 | ||
| 类型系统 | ||
| 执行方式 | ||
| 核心范式 | ||
| 数组索引 | ||
| 包管理 | ||
| 并行模型 | ||
| REPL | ? 帮助、; shell 模式) |
Julia 更适合的场景:
1. 高性能科学计算:接近 C/Fortran 速度,无需重写底层代码 2. 数值优化:JuMP.jl 是最先进的优化建模语言之一 3. 微分方程求解:DifferentialEquations.jl 功能最全面 4. 量化金融:高频交易、风险建模(性能关键) 5. 物理模拟:气候模拟、分子动力学 6. 并行计算密集型:无 GIL 限制,原生多线程 7. 研究型项目:需要高性能同时保持代码可读性
| 执行性能 | ||
| 开发效率 | ||
| 生态成熟度 | ||
| 学习难度 | ||
| 社区规模 | ||
| 科学计算 | ||
| 深度学习 | ||
| Web 开发 | ||
| 并行计算 | ||
| 部署便利性 |
Python 以成熟生态和易用性占据主导地位,Julia 以性能和现代设计在科学计算领域崭露头角。理想策略是掌握两者,根据具体场景选择最合适的工具。

Python 仍将在未来 5-10 年保持数据科学和 AI 领域的主导地位,而 Julia 将在高性能科学计算和数值优化领域持续增长。

公众号《博優旮旯-BOYOGALA》[3],致力于让大家更专业、更完整和更系统地获取与了解数学(运筹与优化、数值分析)等相关数学知识分享!
🎯公众号ID:boyogala,🌐网址: www.boyogala.us.kg[4],💬微信: boyougala,📧邮箱: boyogala@qq.com[5].
说明文档:公众号《博優旮旯-boyogala》的使用指南,以下罗列代表作可供查阅.
优化求解器 — 代表作:优化求解器类型总结线性二次和非线性求解器,Ipopt开源免费的非线性求解器,HiGHS开源免费整数线性求解器,SCIP开源免费的优化求解器,Gurobi商业收费全局优化求解器,CPLEX商业收费整数优化求解器,MOSEK商业收费的优化求解器,BARON商业收费的全局优化求解器,LindoAPI商业收费的全局优化求解器,COPT国产自研的优化求解器
三大数学软件 — 代表作:MATLAB工程师的科学计算软件,MATHEMATICA物理的计算软件,MAPLE数学家的数学软件
嵌入式、无人机和机器人 — 代表作:OSQP二次规划求解器
线性方程组的求解软件 — 代表作:PARDISO并行直接求解器,MUMPS高性能并行求解器,SuitSparse稀疏矩阵软件包,SuperLU非对称直接法求解器
基于MATLAB的优化建模工具 — 代表作:CVX免费凸优化建模工具,Yalmip免费的优化建模工具,CasADi开源最优化控制工具
基于Python的优化建模工具 — 代表作:CasADi非线性优化和最优控制,Gekko数值优化和动态系统建模,Pyomo面向对象代数建模语言
科学计算软件 — 代表作:oneAPI统一的异构编程模型,CUDA人工智能时代的基石,OpenFOAM开源的CFD软件,COMSOL业界多物理场仿真软件
全球优化建模平台 — 代表作:AMPL数学规划建模语言,AIMMS快速优化建模工具,GAMS通用代数建模系统,JuMP数学优化建模语言(学习中…)
人类在思考 — 代表作:公众号排版数学公式的经验,200篇论文🆚1个优化求解器,盗版Windows系统🆚破解版LINGO18
数学是第三世界 — 代表作:数学研究需要师徒传承吗?函数梯度的可视化
引用链接
[1] Python: https://www.python.org/[2] Python(大蟒蛇): https://zhuanlan.zhihu.com/p/35446551[3] 《博優旮旯-BOYOGALA》: https://www.cardopt.cn/api/images/1_1763724698_ce344a.png[4] www.boyogala.us.kg: http://www.boyogala.us.kg[5] boyogala@qq.com: mailto:boyogala@qq.com

