AI科研时代!【Python不用学】能看懂即可,4万字总结(建议收藏)
- 2026-06-28 20:52:55
AI时代,编程不必再深入学习了,但并非完全不学!
比如:问 AI 怎么写「论文代码」
情况 1:完全没知识储备
你只会说:
“帮我写个代码。”
AI 只能懵:
写什么代码?Python 还是 MATLAB?用来干嘛?算数据还是画图?
最后给你的东西,大概率完全用不上。
情况 2:有一点点基础知识
你会说:
“帮我写一段 Python 代码,用最小二乘法拟合一组实验数据,输出图像。”
AI 马上就能写出能用的代码。
情况 3:有扎实专业知识
你会这样问:
“帮我写一段基于 Python 的最小二乘拟合代码,要求对含噪声数据做鲁棒拟合,排除异常值,用 sklearn 实现,并且把残差图一起画出来。”
AI 直接给你高质量、可直接放进论文里的成品代码。
能“看懂代码”,掌握项目流程,并用专业语言指挥ai进行编程即可击败95%的研究生!
所以本文针对”非计算机专业生,完全不懂编程,但科研中还必须用到编程的伙伴”,一文掌握代码所有门路,并使用ai进行辅助编程,并能通过更专业prompt指挥ai进行代码debug和优化!
如果你有python基础请直接跳转到最后一章“AI辅助编程”提问模板和避坑指南!我一个用了很长时间ai进行科研的都觉得有用!

python语法查询:https://www.runoob.com/python/python-dictionary.html
警告:全文4万字,建议收藏!!
一、PEP8代码规范和风格
1、全局变量使用英文大写,单词之间使用下划线_
SCHOOL_NANE="BUCT"全局变量一般只在模块内有效,实现方法:使用_ALL_机制或添加一个前置下划线2、私有变量使用英文小写和一个前导下划线_student_name3、内置变量使用英文小写,两个前导下划线和两个后置下划线__maker__4、一般变量使用英文小写,单词之间使用下划线class_name
注:变量第一个不能使用数字,不能使用python关键字或保留字符pyrthon关键字
>>> keyword.kwlist['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']>>> keyword.iskeyword('pass')True5、函数名是英文小写,单词之间加下划线,提高可读写;不要使用·关键字、缩写等。实例方法的第一个参数总是使用self类方法的第一个参数总是使用cls
6、属性和类类的命名遵循首字母大写规则类的属性(方法和变量)命名使用全部小写,可用下划线
7、模块和包模块命名使用简短的小写英文的方式,可用下划线包的命名也用简短的小写英文,但不推荐使用下划线
8、规定下列运算符前后都需使用一个空格:
= + - < > == >= <= andornot下列运算符前后不使用空格:
* / **二、变量和数据
python是面向对象(object)的编程语言,在python中一切皆为对象。对象是某类型具体实例中的某一个,每个对象都有身份、类型和值。
>>身份:身份(Identity)与对象是唯一对应关系,每一个对象的身份产生后就独一无二,无法改变。对象的ID是对象在内存中获取的一段地址的标识。>>类型:类型(Type)是决定对象以那种数据类型进行存储的。>>值:值(Value)存储对象的数据,某些情况下可以修改值,某些对象声明值过后就不可修改。1、变量
变量:指向对象的值的名称,一种标识符,对内存中存储位置的命名。python中变量可不声明直接赋值使用,由于python使用动态类型(Dynamic Type),变量可根据赋值类型决定变量的数据类型。
数据类型:可自由改变变量数据类型的动态类型&变量事先说明的静态类型,动态类型更灵活。
①Numbers(数字类型):int、float、complex不可改变的数据类型,如果改变就会分配一个新的对象。整型、浮点型、复数②Strings(字符串类型):str序列类型③Lists(列表类型):list序列类型④Tuples(元组类型):tuple序列类型⑤Dictionaries(字典类型):dict映射类型⑥Sets(集合类型):set集合类型下面先简单介绍下整型、浮点型、复数、布尔类型、字符串类型:
(1)整型:int,包括正整数和负整数,python中为长整型,范围无限(只要内存足够大)。除了十进制,二进制0b、八进制0o、十六进制0x也使用整型,之间的进制可以转换:
>>> a=15 >>> print(bin(a)) 0b1111>>> print(oct(a)) 0o17>>> print(hex(a)) 0xf>>> s='010011101' >>> print(int(s,2)) 157注:int(s,base)表示将字符串s按照base参数提供的进制转为十进制。内置函数input()输入时是字符串,需使用int()函数转换为整型。
(2)浮点类型:float,含有小数的数值,表示实数,由正负号、数字和小数点组成fromhex(s):十六进制浮点数转换为十进制数hex():以字符串形式返回十六进制的浮点数is_integer():判断是否为小数,小数非0返回False,为0返回True
(3)复数类型:complex由实数和虚数组成,虚数部分加上j或J(其他语言一般没有)
(4)布尔类型:bool是整型的一个子类,用数值1和0表示常量的True和False。在Python中,False可以是数值为0、对象为None、序列中的空字符串、空列表、空元组等。
(5)字符串类型:str,使用一对单引号、双引号和三对单引号或双引号的字符就是字符串,如‘hello’、“hello”等,显然这里把字符串当作了对象的值,但严格地说字符串表示一种对象的类型。
拓:调用type(变量名)函数可查看变量的类型;调用help(函数名)函数可查看函数用途
2、运算符
算数运算符和逻辑运算符等,这里暂且省略,使用到可自行查看。
三、三种程序结构
顺序结构、分支结构、循环结构
1、分支结构
①单向条件
if 表达式: 语句块
②双向条件
if 表达式1: 语句块1
else 表达式2: 语句块2
③多向条件
if 表达式1: 语句块1
elif 表达式2: 语句块2...
else 表达式n: 语句块n
条件嵌套(一定要控制好缩进),可表达更复杂的逻辑
2、循环结构
①for循环
for 变量 in 序列/迭代对象:
循环体(语句块1)
else: 语句块2
注:else只有在循环结束时才会执行,如果用break跳出就不会执行else部分,根据需要可省略else。range(起始数,终点数+1,步长)可用于生成一段数字序列,不指定起始默认从0开始,默认步长为1。
例1:1~100求和
sum = 0for s in range(1, 101): sum = sum + sprint(sum)例2:删除1~10之间的所有偶数
x = list(range(11))for i in x: x.remove(i)else: print("奇数")print(x)②for循环嵌套
例1:打印乘法表
for i in range(1,10): for j in range(1,i+1): print(str(j)+'x'+str(i)+'='+str(j*i),end=' ') #转换为字符类型才能进行语句拼接,end使不换行 print('') #换行 1x1=11x2=2 2x2=41x3=3 2x3=6 3x3=91x4=4 2x4=8 3x4=12 4x4=161x5=5 2x5=10 3x5=15 4x5=20 5x5=251x6=6 2x6=12 3x6=18 4x6=24 5x6=30 6x6=361x7=7 2x7=14 3x7=21 4x7=28 5x7=35 6x7=42 7x7=491x8=8 2x8=16 3x8=24 4x8=32 5x8=40 6x8=48 7x8=56 8x8=641x9=9 2x9=18 3x9=27 4x9=36 5x9=45 6x9=54 7x9=63 8x9=72 9x9=81 ③while循环不知道循环次数,但知道循环条件时使用(注意python中没有do while)
while 循环条件:
循环体(语句块1)
else: 语句块2
注:break跳出所在层级循环,执行循环后的语句;continue表示结束本次循环,进行下一次循环
四、组合数据类型
列表、元组、字典、集合
1、列表(list)
序列类型,是任意对象的有序集合,通过”位置“或者”索引“访问其中元素,具有可变对象、可变长度、异构、任意嵌套的特点。(索引从0开始)
①创建列表
sample_list1 = [0,1,2,3,4]sample_list2 = ["A","B","C","D","D"]列表中允许有不同的数据类型元素:
sample_list3 = [0,"a",3,'python']列表可嵌套使用:
sample_list4 = [sample_list1,sample_list2,sample_list3]②使用列表
sample_list1 = [0,1,2,3,4]print(sample_list1[1]) #1print(sample_list1[-2]) #从列表右侧倒数第2个元素:3del sample_list1[2] #以索引方式删除元素sample_list1.remove('2') #直接以值的方式删除元素del sample_list1 #删除整个列表sample_list1=[] #清空列表③列表中的内置函数&其他方法
print(len(sample_list1))print(max(sample_list1))print(min(sample_list1))a = (0,1,2,3,4)print(list(a)) #将元组转换为列表sample_list1.append(5) #末尾添加print(sample_list1)b = [6,7,8,9]sample_list1.extend(b) #扩展(序列合并)print(sample_list1)sample_list1.insert(0,3) #在特定索引位置插入元素print(sample_list1)sample_list1.reverse() #翻转元素顺序print(sample_list1)print(sample_list1.count(3)) #计数元素出现次数print(sample_list1.index(8)) #获取元素所在索引(位置)# 其他还有pop、remove、sort、copy、clear等2、元组(tuple)
与列表一样属于序列类型,也是任意对象的有序集合,也通过索引(位置)访问其中元素,也具有可变长度、异构和任意嵌套的特点。与列表不同的是,元组中的元素是不可修改的。①创建元组
sample_tuple1 = (0,1,2,3,4)sample_tuple2 = ("p",'python',1989)元素可以使各种可迭代的类型,也可以是空:
sample_tuple3 = ()若只有一个元素,为避免歧义在元素后加逗号,否则括号会被当作运算符:
sample_tuple4 = (123,)元组也可嵌套使用:
sample_tuple5 = (sample_tuple1,sample_tuple2)②使用元组也是利用索引访问(也是中括号[]):
tuple = (1,2,3,4,5,6)print(tuple[2])print(tuple[-3])支持切片操作:
print(tuple[:]) #全部元素print(tuple[2:4]) #索引为2和3的元素,不包括索引为4的print(tuple[2:])print(tuple[0:5:2])删除元组:
deltuple③元组的内置函数
len、max、min、tuple等,与列表相似,tuple(listname)把列表转换为元组
3、字典(dict)
字典属于映射类型,通过键实现元素的存取,具有无序、可变长度、异构、嵌套、可变类型容器等特点。①创建字典
dict1 = {'Name':'Xiaohuang','City':'Beijing','School':'BUCT'}dict2 = {12:34,56:78,45:67}dict3 = {'Name':'Xiaohuang',12:34,'School':'BUCT'}若一个键被两次赋值,则第一个值无效:
dict4 = {'Name':'Xiaohuang','City':'Beijing','School':'BUCT','City':'Henan'}也支持嵌套:
dict5 = {'student':{'stu1':'Xiaoming','stu2':'Xiaohong','stu3':'Xiaogang'},'school':{'sch1':'Tsinghua','sch2':'Penking','sch3':'BUCT'}}②使用字典利用键访问,也配合中括号[]:
print(dict1['City'])Beijingprint(dict2[56])78print(dict5['student']){'stu1': 'Xiaoming', 'stu2': 'Xiaohong', 'stu3': 'Xiaogang'}print(dict5['student']['stu2']) #嵌套访问Xiaohong修改已有值:
dict1['City'] = 'Henan'print(dict1['City'])Henan在字典中添加新的键值元素:
dict1['Age'] = 21print(dict1){'Name': 'Xiaohuang', 'City': 'Henan', 'School': 'BUCT', 'Age': 21}删除某个元素和整个字典:
del dict1['School']print(dict1)del dict1print(dict1)③字典内置函数和方法len、str输出字典、type:
len(dict2)3str(dict2)'{12: 34, 56: 78, 45: 67}'type(dict2)<class'dict'>**其他内置方法:**①dictname.fromkeys(序列,value)
seq1 = ('Name','City','School')seq2 = ['Name','City','School']dict1 = {}dict1 = dict1.fromkeys(seq1)print(dict1)dict2 = {}dict2 = dict2.fromkeys(seq2,10)print(dict2)②key in dictname,在的话返回True否则False
'Name'in dict2True③dictname.get(key)
dict2 = {'Name': 10, 'City': 10, 'School': 10}print(dict2.get('Name'))print(dict2.get('Age'))dict5 = {'student':{'stu1':'Xiaoming','stu2':'Xiaohong','stu3':'Xiaogang'},'school':{'sch1':'Tsinghua','sch2':'Penking','sch3':'BUCT'}}print(dict5.get('student').get('stu1')) #嵌套使用对比:dictname.get(key) 方法在 key(键)不在字典中时,可以返回默认值 None 或者设置的默认值。dictname[key] 在 key(键)不在字典中时,会触发 KeyError 异常。
④dictname.keys()、dictname.values()、dictname.items()
dict1 = {'Name': 'Xiaohuang', 'City': 'Henan', 'School': 'BUCT', 'Age': 21}print(dict1.keys())print(dict1.values())print(dict1.items()) #返回可遍历的元组数组for key,value in dict1.items(): print(key,':',value)④dictname.update(dictname1)
dict1 = {'Name': 'Xiaohuang', 'City': 'Henan', 'School': 'BUCT', 'Age': 21}dict2 = {}dict2.update(dict1)print(dict2)⑤dictname.pop(key),删除对应键值,返回值为key对应的value
dict1 = {'Name': 'Xiaohuang', 'City': 'Henan', 'School': 'BUCT', 'Age': 21}x = dict1.pop('Name')print(x)print(dict1)⑥dictname.popitem()弹出最后一组键值(返回值),并删除
x = dict1.popitem()print(x)print(dict1)5、集合(set)
集合是一种集合类型(无序、不可重复),表示任意元素的集合,索引可通过另一个任意键值的集合进行,可无序排列和哈希。可变集合set:创建后可通过各种方法被改变,如add()、update()等不可变集合frozenset:可哈希(一个对象在其生命周期内,其哈希值不会变化,并可与其他对象做比较),也可作为一个元素被其他集合使用,或者作为字典的键。
①创建集合可使用{}创建,或set()、frozenset()创建。为了防止与字典歧义,创建空集合时必须使用:empty = set()不能用empty = {}
set1 = {1,2,3,4,5,6}set2 = {'a','b','c','d','e'}set3 = set([10,20,30,40,50])set4 = frozenset(['huang','zhang','zhao'])②使用集合字典可自行去除重复的元素:
set5 = {1,2,3,4,5,6,1,2,3}print(set5){1, 2, 3, 4, 5, 6}print(len(set5))集合是无序的,没有”索引“或”键“来指定调用某个元素,但可用循环输出:
for x in set5: print(x,end=' ')123456
增加元素,update不允许整型只允许序列:
set5.add(7)print(set5)set5.update('huang')print(set5)set5.update('89')print(set5)set5.update(1234) #不允许int成员测试:
'h'in set5True1notin set5False集合运算:
set1 = {1,2,3,4,5}set2 = {3,4,5,6,7}set1 - set2 #差集set1 | set2 #并集set1 & set2 #交集set1 ^ set2 #对称差集删除元素:
set1.remove(3)print(set1){1, 2, 4, 5}③集合的方法很多。。。省略,详细可见python语言知识点查阅: https://www.runoob.com/python/python-dictionary.html
五、字符串与正则表达式
字符串用于表示文本类型的数据,也是有序的字符数组集合,序列不可更改,索引也是从0开始。正则表达式是操作字符串的特殊字符串,通过正则表达式可验证相应的字符串是否符合对应的规则。
1、字符串基础
字符串的字符可以是ASCII字符、或其他各种符号,伴随单引号、双引号、三引号出现。一些特殊字符叫做转义字符,用于不能直接输入的情况:
\\(反斜线)、\'(单引号)、\"(双引号)、\a(响铃符)、\b(退格)、\f(换页)、\n(换行)、\r(回车)、\t(水平制表符)、\v(垂直制表符)、\0(Null空字符串)、\000(以八进制表示的ASCII码对应符)、\xhh(以十六进制表示的ASCII码对应符)①字符串基本操作求字符串长度:
str1 = 'I love python'print(len(str1))13
字符串的连接:
str2 = 'I','love','python'print(str2,type(str2))str3 = 'I''love''python'print(str3,type(str3))str4 = 'I'+'love'+'python'print(str4,type(str4))str5 = 'love'*5print(str5)字符串的遍历:
str6 = 'Python'for s in str6: print(s)包含判断:
print('P'in str6)print('y'notin str6)可索引获取但不可修改:
print('P'in str6)print('y'notin str6)print(str6[2])print(str6[:3])print(str6[3:])str6[0] = 'p' #报错不可修改②字符串格式化用format()方法:
print(' I am {0},and I am from {1}'.format('Liming','China'))用格式化符号:%s、%r、%c、%b、%o、%d、%i、%f等(详细自找)
%可理解为占位符,后面就是实际要跟的参数,实际参数的本质就是元组
print(' I am %s,and I am from %s'%('Liming','China'))print('花了%.2f元'%(19.56789))2、字符串方法进阶
①strip删除首尾字符,未指定字符默认删除首尾空格或换行符
str1 = ' Hello world*##'print(str1.strip()) # 去除首尾空白字符print(str1.strip('#')) # 去除首尾的 # 字符print(str1.strip('*##')) # 去除首尾的 * 和 # 字符②count统计指定范围内某个字符出现的次数
str2 = '101010101010'print(str2.count('1',2,10)) #不包括索引为10的末尾4③capitalize将字符串首字母大写
str3 = 'xiaohuang'print(str3.capitalize())Xiaohuang
④replace替换字符,不指定第3个参数替换次数默认全部替换
str2 = '101010101010'print(str2.replace('10','89'))#输出:898989898989print(str2.replace('10','89',2))#输出:898910101010⑤find在指定范围内查找字符并返回索引号(未找到返回-1,多次出现返回第一次出现的索引号)
str4 = '01234507'print(str4.find('2')) # 查找 '2' 在字符串中的首次出现位置print(str4.find('2',3,8)) # 在索引 3 到 8(不包含8)范围内查找 '2'print(str4.find('0')) # 查找 '0' 在字符串中的首次出现位置⑥index与find一样但是未找到会直接报错
str4 = '01234507'print(str4.index('8'))Traceback (most recent call last):
File "<pyshell#16>", line 1, in
print(str4.index('8'))
ValueError: substring not found
⑦isalnum判断字符串是否全由字母或数字组成
str5 = 'aaaa1111'str6 = 'asdfgg'str7 = 'ash17%%#'print(str5.isalnum(),str6.isalnum(),str7.isalnum())True True False
类似的函数还有:
isalpha判断是否全部由字母组成isdigital判断是否全部由数字组成isspace判断是否全部由空格组成islower判断是否全是小写isupper判断是否全是大写istitle判断首字母是否是大写
⑧lower、upper全部换为小写或大写
str8 = 'aBcDeF'print(str8.lower())print(str8.upper())abcdef
ABCDEF
⑨split(sep,maxsplit)按照指定sep字符进行分割(不指定sep默认分割空格),maxsplit为分割次数(不指定默认全部分割)
str9 = 'uhaduadhaxbu'print(str9.split('a'))print(str9.split('a',2))str10 = 'I love python'print(str10.split())['uh', 'du', 'dh', 'xbu']
['uh', 'du', 'dhaxbu']
['I', 'love', 'python']
⑩startswith判断(在指定范围内)是否以指定字符开头;endswith判断(在指定范围内)是否以指定字符结尾
str11 = '13hhhh'print(str11.startswith('13'))print(str11.startswith('13',2,5))print(str11.endswith('hh',2,6))True
False
True
⑩partition(sep),以sep第一次出现位置分成三部分,返回一个三元元组,若没有sep则返回空格;repartition(sep),以sep最后一次 出现位置分成三部分
str12 = '1234561234'print(str12.partition('34'))print(str12.partition('78'))print(str12.rpartition('12'))('12', '34', '561234')
('1234561234', '', '')
('123456', '12', '34')
3、正则表达式
正则表达式,即描述某种规则的表达式,代码简写regex、regexp或RE。它使用某些单个字符串来描述或匹配某个句法规则的字符串,在很多文本编辑器中,RE被用来检索或替换那些符合某个模式的文本:表格——P84?????????????没懂干啥哩???
①re模块re模块提供了正则表达式操作所需的方法
import reresult = re.match('huang','huang666') #匹配print(result.group()) #group用于只返回匹配结果print(result)#match与search的区别,search就算不是从开头对应也能匹配到result1 = re.match('huang','xiaohuang') #匹配不到huangprint(result1.group())result2 = re.search('huang','xiaohuang') #匹配到huangprint(result2.group())huang
<_sre.SRE_Match object; span=(0, 5), match='huang'>
Traceback (most recent call last):
File "<pyshell#xx>", line 1, in
print(result1.group())
AttributeError: 'NoneType' object has no attribute 'group'
huang
为了使程序实现的代码更加简单。需要把程序分成越来越小的组成部分,3种方式——函数、对象、模块。
六、函数
1、函数概述
C语言大括号{}里是函数体,python种缩进块里是函数体(配合def和冒号:)函数外面定义的变量是全局变量(大写配合下划线)函数内部定义的局部变量(小写配合下划线),只在内部有效
def foodprice(per_price, number): sum_price = per_price * number return sum_pricePER_PRICE = float(input('请输入单价:'))NUMBER = float(input('请输入数量:'))SUM_PRICE = foodprice(PER_PRICE, NUMBER)print('一共', SUM_PRICE, '元')请输入单价:15
请输入数量:4
一共 60.0 元
若想在函数内部修改全局变量,并使之在整个程序生效用关键字global:
def foodprice(per_price, number): global PER_PRICE PER_PRICE = 10 sum_price = per_price * number return sum_price# 补充完整可运行的代码(结合之前的上下文)PER_PRICE = float(input('请输入单价:'))NUMBER = float(input('请输入数量:'))SUM_PRICE = foodprice(PER_PRICE, NUMBER)print('函数内修改后的PER_PRICE:', PER_PRICE)print('一共', SUM_PRICE, '元')请输入单价:15
请输入数量:4
函数内修改后的 PER_PRICE: 10
一共 60.0 元
2、参数和返回值
在python种,函数参数分为3种:位置参数、可变参数、关键字参数。参数的类型不同,参数的传递方式也不同。
①位置参数位置参数:传入参数值按照位置顺序依次赋给参数。传递方式:直接传入参数即可,如果有多个参数,位置先后顺序不可改变。若交换顺序,函数结果则不同
def sub(x, y): return x - yprint(sub(10, 5))print(sub(5, 10))5
-5
②关键字参数关键字参数:通过参数名指定需要赋值的参数,可忽略参数顺序传递方式:2种,一是直接传入参数,二是先将参数封装成字典,再在封装后的字典前添加两个星号**传入
def sub(x, y): return x - yprint(sub(y=5, x=10))print(sub(**{'y':5, 'x':10}))5
5
③默认值参数当函数调用忘记给某个参数值时,会使用默认值代替(以防报错)
def sub(x=100, y=50): return x - yprint(sub())print(sub(51))print(sub(10, 5))50
1
5
④可变参数可变参数:在定义函数参数时,我们不知道到底需要几个参数,只要在参数前面加上星号*即可。
def var(*param): print('可变参数param中第3个参数是:', param[2]) print('可变参数param的长度是:', len(param))var('BUCT', 1958, 'Liming', 100, 'A')可变参数 param 中第 3 个参数是: Liming
可变参数 param 的长度是: 5
除了可变参数,后也可有普通参数(普参需要用关键字参数传值):
def var(*param, str1): print('可变参数param中第3个参数是:', param[2]) print('可变参数param的长度是:', len(param)) print('我是普通参数:', str1)var('BUCT', 1958, 'Liming', 100, 'A', str1 = '普参')可变参数 param 中第 3 个参数是: Liming
可变参数 param 的长度是: 5
我是普通参数:普参
⑤函数的返回值若没有用return指定返回值,则返回一个空None
result = var('BUCT',1958,'Liming',100,'A',str1 = '普参')print(result)None若将函数改为:
def var(*param, str1): print('可变参数param中第3个参数是:', param[2]) print('可变参数param的长度是:', len(param)) print('我是普通参数:', str1) return paramresult = var('BUCT', 1958, 'Liming', 100, 'A', str1 = '普参')print(result)可变参数 param 中第 3 个参数是: Liming
可变参数 param 的长度是: 5
我是普通参数:普参
('BUCT', 1958, 'Liming', 100, 'A')
3、函数的调用
自定义函数:先定义再调用内置函数:直接调用,有的在特定模块里,需要先import相应模块
①嵌套调用内嵌函数/内部函数:在函数内部再定义一个函数,作用域只在其相邻外层函数缩进块内部。
②使用闭包闭包:函数式编程的一个重要的语法结构,在一个内部函数里对外部作用域(不是全局作用域)的变量进行引用。此时这个内部函数叫做闭包函数,如下sub2(b)就是引用了a,为闭包函数:
def sub(a): def sub2(b): result = a - b return result return sub2print(sub(10)(5))5
注:闭包本质还是内嵌函数,不能再全局域访问,外部函数sub的局部变量对于闭包来说是全局变量,可以访问但是不能修改。
③递归调用递归:严格说其属于算法范畴,不属于语法范围。函数调用自身的行为叫做递归。两个条件:调用函数自身、设置了正确的返回条件。如计算正整数N的阶乘:
常规迭代算法:
def factorial(n): result = n for i in range(1, n): result *= i return resultprint(factorial(10))3628800
迭代算法:
def factorial(n): if n == 1: return 1 else: return n * factorial(n-1)print(factorial(10))3628800
注:python默认递归深度为100层(限制),也可用sys.setrecursionlimit(x)指定递归深度。递归有危险(消耗时间和空间),因为它是基于弹栈和出栈操作;递归忘记返回时/未设置正确返回条件时,会使程序崩溃,消耗掉所有内存。
七、模块/库
1、模块概述
模块实际上是一种更为高级的封装。前面容器(元组,列表)是对数据的封装,函数是对语句的封装,类是方法和属性的封装,模块就是对程序的封装。——就是我们保存的实现特定功能的.py文件
命名空间:一个包含了一个或多个变量名称和它们各自对应的对象值的字典,python可调用局部命名空间和全局命名空间中的变量。如果一个局部变量与全局变量重名,则再函数内部调用局部变量时,会屏蔽全局变量。如果要修改函数内全局变量的值,需要借助global
①模块导入方法方法一:
import modulenameimport modulename1,modulename2使用函数时modulename.functionname()即可
方法二:
from modulename import functionname1,functionname2方法三:
import modulename as newname相当于给模块起了个新名字,便于记忆也方便调用
②自定义模块和包
自定义模块:编写的mine.py文件放在与调用程序同一目录下,在其他文件中使用时就可import mine使用。
自定义包:在大型项目开发中,为了避免模块名重复,python引入了按目录来组织模块的方法,称为包(package)。包是一个分层级的文件目录结构,定义了有模块、子包、子包下的子包等组成的命名空间。只要顶层报名不与其他人重名,内部的所有模块都不会冲突。——P114
③安装第三方包pip install xxxx
2、模块应用实例
①日期和时间相关:datatime模块导入:
from datetime import datetime#不能import datetime,可以import datetime.datetime(因为datetime模块里还有一个datetime类)获取当前日期时间:
>>> now = datetime.now()>>> print(now)2023-10-05 17:28:24.303285获取指定日期时间:
>>> dt = datetime(2020,12,12,11,30,45)>>> print(dt)2020-12-1211:30:45datetime与timestamp互相转换:把1970-1-1 00:00:00 UTC+00:00的时间作为epoch time,记为0,当前时间就是相对于epoch time的秒数,称为timestamp。计算机中存储的当前时间是以timestamp表示的,与时区无关,全球各地计算机在任意时刻的timestamp是相同的。
>>> dt = dt.timestamp()>>> print(dt)1607743845.0#再转换回去:>>> dt = datetime.fromtimestamp(dt)>>> print(dt)2020-12-1211:30:45str转换为datetime:用户输入的日期和时间类型是字符串,要处理日期和时间,必须把str转换为datetime
>>> test = datetime.strptime('2023-10-05 17:49:00','%Y-%m-%d %H:%M:%S') #特殊字符规定了格式>>> print(test)2023-10-05 17:49:00datetime转换为str:若已有datetime对象,要把它格式化为字符才能显示给用户
>>> now = datetime.now()>>> print(now.strftime('%a,%b %d %H:%M'))Thu,Oct 05 17:28、datetime加减计算:(再导入timedelta类)
>>> from datetime import datetime,timedelta>>> now = datetime.now()>>> nowdatetime.datetime(2023, 10, 5, 17, 58, 9, 377124)>>> now + timedelta(hours = 2)datetime.datetime(2023, 10, 5, 19, 58, 9, 377124)>>> now - timedelta(days = 3)datetime.datetime(2023, 10, 2, 17, 58, 9, 377124)本地时间转换为UTC时间:(再导入timedelta、timezone类)本地时间为系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。datetime里面有时区属性tzinfo。
>>> from datetime import datetime,timedelta,timezone>>> new_utc = timezone(timedelta(hours = 8)) #创建新时区UTC+8:00>>> new_utc1 = timezone(timedelta(hours = 7)) #创建新时区UTC+7:00>>> now = datetime.now()>>> nowdatetime.datetime(2023, 10, 5, 18, 9, 17, 667655)>>> test = now.replace(tzinfo = new_utc) #为当前时间强制设置新的时区>>> testdatetime.datetime(2023, 10, 5, 18, 9, 17, 667655, tzinfo=datetime.timezone(datetime.timedelta(0, 28800)))>>> test1 = now.replace(tzinfo = new_utc1) #为当前时间强制设置新的时区UTC+7:00>>> test1datetime.datetime(2023, 10, 5, 18, 9, 17, 667655, tzinfo=datetime.timezone(datetime.timedelta(0, 25200)))时区转换:先用datetime类提供的utcnow()方法获取当前UTC时间,再用astimezone()方法转换为任意时区的时间
②读写JSON数据:json模块JSON是一种轻量级的数据交换格式,等同于python里面的字典格式,里面可以包含方括号括起来的数组(列表)。json模块专门解决json格式的数据,提供4种方法:dumps()、dump()、loads()、load()dumps()、dump()实现序列化功能:
dumps()实现将数据序列化为字符串str,而使用dump()时必须传文件描述符,将序列化的字符串str保存到文件中。
>>> import json>>> json.dumps('huang')'"huang"'>>> json.dumps(13.14)'13.14'>>> dict1 = {'name':'huang','school':'buct'}>>> json.dumps(dict1)'{"name": "huang", "school": "buct"}'>>> withopen("D:\\json_test.json","w",encoding = 'utf-8')as file_test: json.dump(dict1,file_test,indent = 4)运行结果:dump()方法将字典数据dict_test保存到D盘文件夹下的json_test.json文件中,里面的内容如下{ "name": "huang", "school": "buct"}
loads()、load()是反序列化方法:
loads()只完成了反序列化,load()只接收文件描述符,完成了读取文件和反序列化。
import json# 先定义字典并序列化/反序列化(对应第一行代码)dict1 = {'name': 'huang', 'school': 'buct'}print(json.loads(json.dumps(dict1)))# 读取JSON文件并分别用loads/load反序列化with open("D:\\json_test.json","r",encoding = 'utf-8') as file_test: test_loads = json.loads(file_test.read()) # 先读取文件字符串再反序列化 file_test.seek(0) # 重置文件指针到开头 test_load = json.load(file_test) # 直接从文件对象反序列化print(test_loads)print(test_load){'name': 'huang', 'school': 'buct'}
{'name': 'huang', 'school': 'buct'}
{'name': 'huang', 'school': 'buct'}
③系统相关:sys模块sys是python自带模块,包含了与系统相关的信息。可通过help(sys)或dir(sys)查看sys模块的可用方法(很多),下面列举几种。sys.path包含输入模块的目录名列表:
import sysprint(sys.path)结果:['', 'D:\python3.6.6\Lib\idlelib', 'D:\python3.6.6\python36.zip', 'D:\python3.6.6\DLLs', 'D:\python3.6.6\lib', 'D:\python3.6.6', 'D:\python3.6.6\lib\site-packages']
该命令获取了指定模块搜索路径的字符串集合。将写好的模块放在上面得到的某个路径下,就可以在使用import导入时正确找到,也可以用sys.path.append(自定义路径)添加模块路径。——“自定义模块乱放程序是找不到的!”sys.argv在外部向程序内部传递参数:????sys.argv变量是一个包含了命令行参数的字符串列表,利用命令行向程序传递参数。其中脚本的名称是sys.argv列表的第一个参数。
④数学:math模块math模块也是python自带模块,包含了和数学运算公式相关的信息——P125
⑤随机数:random模块列举常用模块:生成随机整数(需指定上下限,且下限小于上限):randint
import random>>> random.randint(10,2390) #生成指定范围内的随机整数2375生成随机浮点数:random
>>> random.random()0.9935870033845187>>> random.uniform(10,100)27.07308173076904>>> random.uniform(100,10)18.198994262912336随机字符:choice
>>> random.choice('98%$333#@')'3'洗牌:shuffle
>>> test = ['a','B',1,2,5,'%']>>> random.shuffle(test)>>> print(test)[5, 1, 2, 'a', 'B', '%']八、类与对象
1、面向对象概述
面向对象编程(Object Oriented Programming,OOP),是一种程序设计思想,是以建立模型体现出来的抽象思维过程和面向对象的方法。模型是用来反映现实世界中的事物特征的,是对事物特征和变化规律的抽象化,是更普遍、更集中、更深刻地描述客体的特征。OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
术语简介:
# 1. 类(Class):定义对象的模板,包含属性(特征)和方法(功能)class Person: # 这是一个类,描述"人"这个对象的特征和行为 # 2. 属性(Attribute):静态特征(如姓名、年龄) species = "人类" # 类属性(所有实例共享) # 14. 构造函数(__init__):创建对象时自动调用的特殊方法,初始化属性 def __init__(self, name, age): self.name = name # 实例属性(每个实例独有) self.age = age # 3. 方法(Method):动态动作(如说话、跑) def speak(self, words): print(f"{self.name}说:{words}") def run(self): print(f"{self.name}正在跑步") # 15. 析构函数(__del__):释放对象时调用(Python中一般不用手动写,解释器自动回收) def __del__(self): print(f"{self.name}的对象被释放了")# 6. 实例化(Instantiation):创建类的实例的过程# 4. 对象(Object) + 5. 实例(Instance):类的具体实体(对象=实例)person1 = Person("小黄", 20) # person1是Person类的一个实例/对象person2 = Person("小李", 25) # person2是另一个实例/对象# 7. 封装(Encapsulation):把属性和方法集中在类里,屏蔽细节(比如外部不用关心speak怎么实现,只需要调用)person1.speak("你好!") # 外部只需要调用方法,不用管方法内部怎么打印的# 封装也可以通过私有属性/方法(加__)屏蔽细节,比如:class Student(Person): def __init__(self, name, age, score): super().__init__(name, age) self.__score = score # 私有属性,外部不能直接访问,实现封装 def get_score(self): # 提供接口访问私有属性 return self.__scorestu1 = Student("小张", 18, 90)# print(stu1.__score) # 直接访问会报错,体现封装的屏蔽性print(stu1.get_score()) # 通过接口访问,输出90# 8. 继承(Inheritance):子类继承父类的属性和方法,还能拓展# Person是父类/基类/超类,Student是子类/派生类class Student(Person): # 13. 重写(Override):子类重新定义父类的方法,实现不同功能 def speak(self, words): # 重写父类的speak方法 print(f"学生{self.name}大声说:{words}") # 功能和父类不同 # 12. 事件(Event):简化理解:外部行为触发方法(比如调用study就是"学习事件") def study(self, course): print(f"{self.name}正在学习{course}") # 外部调用该方法=触发"学习事件"stu1 = Student("小张", 18)stu1.speak("我要好好学习") # 调用重写后的方法,输出"学生小张大声说:我要好好学习"stu1.study("Python") # 触发"学习事件",输出"小张正在学习Python"# 9. 多态(Polymorphism):同一个方法,不同对象有不同实现def let_speak(obj): # 统一的函数,接收不同对象 obj.speak("多态示例")let_speak(person1) # 输出"小黄说:多态示例"(父类方法)let_speak(stu1) # 输出"学生小张大声说:多态示例"(子类重写后的方法)# 11. 重载(Overload):Python没有原生方法重载(同名方法传不同参数),但可以通过默认参数模拟class Calculator: def add(self, a, b=0, c=0): # 模拟重载:一个add方法,支持2个或3个参数相加 return a + b + ccalc = Calculator()print(calc.add(1, 2)) # 传2个参数,输出3print(calc.add(1, 2, 3)) # 传3个参数,输出6# 10. 接口(Interface):Python没有专门的interface关键字,一般用抽象类模拟# 接口只定义方法结构(不实现),子类必须实现这些方法from abc import ABC, abstractmethodclass AnimalInterface(ABC): # 抽象类(接口) @abstractmethod # 抽象方法(只定义,不实现) def eat(self): pass # 无实现 @abstractmethod def sleep(self): passclass Dog(AnimalInterface): # 必须实现接口的所有方法 def eat(self): print("狗吃骨头") def sleep(self): print("狗睡觉")# 不能直接创建接口的对象:AnimalInterface() 会报错dog = Dog() # 先创建实现接口的类,再创建对象dog.eat() # 输出"狗吃骨头"2、类
①类的定义类就是对象的属性和方法的拼接,静态的特征称为属性,动态的动作称为方法。
class Person: #规定类名以大写字母开头 #属性 skincolor = "yellow" high = 185 weight = 75 #方法 def goroad(self): print("人走路动作的测试...") def sleep(self): print("睡觉,晚安!")皮肤颜色: yellow 身高: 185 体重: 75 人走路动作的测试... 睡觉,晚安! p2的皮肤颜色: yellow
②类的使用(类实例化为对象)
p = Person() #将类实例化为对象,注意后面要加括号()③类的构造方法及专有方法类的构造方法:int(self)。只要实例化一个对象,此方法就会在对象被创建时自动调用——实例化对象时是可以传入参数的,这些参数会自动传入__int__(self,param1,param2...)方法中,可以通过重写这个方法来自定义对象的初始化操作。
class Bear: def __init__(self, name): self.name = name def kill(self): print("%s是保护动物不可猎杀"%self.name)a = Bear("狗熊")a.kill()解释:与Person()相比,这里重写了__init__()方法,不然默认为__init__(self)。在Bear()中给了一个参数name,成了__init__(self,name),第一个参数self是默认的,所以调用时把“狗熊”传给了name。也可以给name默认参数,这样即使忘记传入参数,程序也不会报错:
class Bear: def __init__(self, name = "狗熊"): self.name = name def kill(self): print("%s是保护动物不可猎杀"%self.name)b = Bear()b.kill()c = Bear("丹顶鹤")c.kill()④类的访问权限在C++和JAVA中是通过关键字public、private来表明访问权限是共有的还是私有的。在python中,默认情况下对象的属性和方法是公开的、公有的,通过点(.)操作符来访问。如上面的kill()函数(方法)的访问,也可以访问变量:
class Test: name = "大连橡塑"a = Test()print(a.name)若变量前面加上双下划线(__)就表示声明为私有变量就不可访问:
class Test: __name = "君欣旅店"a = Test()# 尝试直接访问私有属性会报错print(a.__name)可利用函数方法访问私有变量:
class Test: __name = "君欣旅店" def getname(self): return self.__namea = Test()print(a.getname())也可通过"_类名__变量名"格式访问私有变量:
a._Test__name'君欣旅店'(由此可见python的私有机制是伪私有,python的类是没有权限控制的,变量可以被外界调用)
⑤获取对象信息类实例化对象后(如a = Test()),对象就可以调用类的属性和方法:即a.getname()、a.name、a.kill()这些
3、类的特点
①封装形式上看,对象封装了属性就是变量,而方法和函数是独立性很强的模块,封装就是一种信息掩蔽技术,使数据更加安全!如列表实质上是python的一个序列对象,sort()就是其中一个方法/函数:
list1 = ['E','C','B','A','D']list1.sort()print(list1)②多态不同对象对同一方法响应不同的行动就是多态(内部方法/函数名相同,但是不同类里面定义的功能不同):
class Test1: def func(self): print("这是响应1...")class Test2: def func(self): print("这是响应2...")x = Test1()y = Test2()x.func()y.func()注意:self相当于C++的this指针。由同一个类可以生成无数个对象,这些对象都源于同一个类的属性和方法,当一个对象的方法被调用时,对象会将自身作为第一个参数传给self参数,接收self参数时,python就知道是哪个对象在调用方法了。
③继承继承是子类自动共享父类数据和方法的机制。语法格式如下:
# 定义父类(基类)class Animal: # 父类名首字母大写,符合规范 def __init__(self, name): self.name = name def eat(self): print(f"{self.name}正在进食...")# 定义子类(派生类),继承父类Animalclass Dog(Animal): # ClassName=Dog,BaseClassName=Animal # 子类可以拓展父类的方法 def bark(self): print(f"{self.name}汪汪叫...")# 实例化子类dog = Dog("旺财")# 调用父类的方法dog.eat()# 调用子类自己的方法dog.bark()子类可继承父类的任何属性和方法,如下定义类Test_list继承列表list的属性和方法(append和sort):
class Test_list(list): passlist1 = Test_list()list1.append('B')print(list1)list1.append('UCT')print(list1)list1.sort()print(list1)使用类继承机制时的注意事项:a、若子类中定义与父类同名的方法或属性,自动覆盖父类里对应的属性或方法。b、子类重写父类中同名的属性或方法,若被重写的子类同名的方法里面没有引入父类同名的方法,实例化对象调用父类的同名方法就会出错:
import randomclass Dog: def __init__(self): self.x = random.randint(1,100) #两个缩进 self.y = random.randint(1,100) def run_Dog(self): self.x += 1 print("狗狗的位置是:",self.x,self.y)class Dog1(Dog): passclass Dog2(Dog): def __init__(self): self.hungry = True def eat(self): if self.hungry: print("狗想吃东西了!") self.hungry = False else: print("狗吃饱了!")分析:子类Dog2重写了父类(基类)Dog的构造函数__init__(self),则父类构造函数里的方法被覆盖。要解决此问题,就要在子类里面重写父类同名方法时,先引入父类的同名方法,两种技术:a、调用未绑定的父类方法;b、使用super函数
a、调用未绑定的父类方法——语法格式:paraname.func(self)。父类名.方法名.(self)对上面示例代码的Dog2类更改:
# 仅规整指定代码段的缩进(完整上下文)class Dog2(Dog): def __init__(self): Dog.__init__(self) # 加了这一行 self.hungry = True# 调用代码dog2 = Dog2()dog2.run_Dog() # 输出:狗狗的位置是: 85 16b、使用super函数,该函数可以自动找到父类方法和传入的self参数,语法格式:super().func([parameter])。parameter为可选参数,若是self可省略。对上面示例代码的Dog2类更改:
class Dog2(Dog): def __init__(self): super().__init__() # 加了这一行 self.hungry = True# 调用代码dog2 = Dog2()dog2.run_Dog() # 输出:狗狗的位置是: 96 82使用super函数的方便之处在于不用写任何关于基类(父类)的名称,直接写重写的方法即可,会自动去父类去寻找,尤其在多重继承中,或者子类有多个祖先类时,能自动跳过多种层级去寻找。如果以后要更改父类,直接修改括号()里面的父类名称即可,不用再修改重写的同名方法里的内容。
④多重继承一个子类同时继承多个父类的属性和方法:
classClassname(Base1,Base2,Base3): ...虽然多重继承的机制可以使子类继承多个属性和方法,但是容易导致代码混乱,引起不可预见的Bug,一般尽量避免使用。
九、异常
某些代码错误不是致命的,不会导致程序崩溃,如逻辑错误、用户输入不合法等。这些可通过python提供的异常机制,在错误出现时,以程序内部的方式消化解决。
1、检测异常try语句
任何出现在try语句范围内的异常都可以被检测到,4种模式:try-except语句、try-except-finally语句、try-except-else语句、try(with)-except语句。①try-except语句语法格式(语句块为检测范围,except后跟异常名字,as reason输出异常的具体内容):
# 规整缩进后的异常处理模板try: # 可能触发异常的语句块 [语句块]except Exception as reason: # 出现异常后的处理代码 print(f"发生异常:{reason}")示例1:
try: f = open('test.txt') print(f.read()) f.close()except OSError as reason: print("文件出现错误的原因是:" + str(reason))注:一个try还可以与多个except搭配,对我们感兴趣的异常进行检测处理:OSError、TypeError
try: # 可能触发多种异常的语句块 f = open('test.txt') print(f.read() + 123) # 模拟两种异常:文件不存在(OSError)、字符串+数字(TypeError) f.close()except OSError as reason: print("文件出现错误的原因是:" + str(reason))except TypeError as reason: print("数据类型错误的原因是:" + str(reason))若对多个异常统一进行处理,可写为:
except (OSError,TypeErro):②try-finally语句语法格式:
# 规整缩进后的 try-except-finally 完整模板try: # 可能触发异常的语句块 [语句块]except Exception as reason: # 出现异常后的处理代码 print(f"发生异常:{reason}")finally: # 无论是否发生异常,都会执行的代码 print("这段代码一定会执行")示例:如在示例1后加入
finally: f.close()③try-except-else语句语法格式:
try: [语句块]except Exception[as reason]: 出现异常(exception)后的处理代码else: 没有异常时被执行的代码④try(with)-except语句语法格式:
try: with <语句> as name: [语句块]except OSError as reason: 出现异常(exception)后的处理代码在语法中可以看出,with语句出现在try语句块中,一般情况下不需要再写finally语句块了。使用with语句最大的好处是减少代码量,例如当我们对文件操作时忘记了关闭文件操作,则with语句会自动执行关闭文件操作。示例代码如下:
try: with open('D:\\data.txt', "w") as f: f.write("测试with语句功能!写入这句话") for each_line in f: print(each_line)except OSError as reason: print("文件出现错误的原因是:" + str(reason))2、抛出异常
主动抛出异常,使用关键字raise,语法格式:
raise Exception(defineexceptname)其中Exception为异常名称如OSError、TypeError、ZeroDivisionError等。defineexceptname为自定义的异常描述。
# 规整缩进并补充完整可运行代码# 主动抛出 ZeroDivisionError 异常raise ZeroDivisionError('不能除以0')3、异常处理流程
此处略,可根据需要自行学习!!
十、文件操作
大多数程序遵循输入、处理、输出的模型,但我们不满足input、print,再进阶就涉及到对文件的处理!
1、打开文件
打开文件使用内置函数open(),创建file对象,只有存在file对象后用户才能对文件进行相应操作。语法格式:
# 仅规整 open() 函数参数定义的代码格式file_object = open(file_name, access_mode, buffering)以默认只读方式打开一个文件(只读模式时,文件路径必须完整):
f = open("D:\data.txt")①文件模式acess_mode
# 文件打开模式整理(仅规整格式,无额外代码)"""r :只读方式打开文件,默认模式。rb :只读方式、二进制格式打开文件。r+ :打开一个文件,用于读写(可理解为rw)。w :打开一个文件,用于写入。 - 文件存在:删除内部信息,从头编辑; - 文件不存在:创建新文件,从头写入。wb :以二进制打开一个文件,用于写入。一般用于非文本文件。w+ :打开一个文件,用于读写(可理解为wr)。wb+ :以二进制打开一个文件,用于读写。一般用于非文本文件。a :打开一个文件,用于追加。 - 文件存在:接着内部信息写入; - 文件不存在:创建新文件,从头写入。ab :以二进制打开一个文件,用于追加。a+ :打开一个文件,用于读写。ab+ :以二进制打开一个文件,用于读写。(a类比w,区别在于a写时不会删除原信息,而是跟着原信息追加)"""②文件缓冲区
python文件缓冲区,一般分为3种模式:全缓冲、行缓冲、无缓冲。全缓冲:默认模式,空间大小为4096字节。前4069个字节信息会写在缓冲区,当第4097个字节写入时,系统会把先前的4096个字节通过系统调用写入文件。可以指定参数Buffering = n自定义缓冲区大小。行缓冲:Buffering = 1,系统每遇到一个换行符('\n')时才进行系统调用,将缓冲区的信息写入文件。无缓冲:Buffering = 0,将系统产生的信息实时写入文件。
2、基本的文件方法
①读和写、关闭文件
读:str = fileobject.read(size)其中size是指定读取的字节数,若没指定默认读取全部信息,返回值为从文件中读到的字符串。
>>> f = open('D:\\data.txt','r')>>> str_test = f.read()>>> print(str_test)测试with语句功能!写入这句话>>> f.close()
写:fileobject.write(string)
>>> f = open('D:\\data.txt','w')>>> f.write("这是一个写测试!\n")9 #返回值是写入字符串的个数(\n也算)>>> f.close()②读取行
str = fileobject.readline(size):
读取整行,包括\n字符,size也是可选参数fileobject.readline():
读取所有行,直到结束符EOF,并返回列表(包括所有行信息),常结合for ...in...结构处理。
③文件重命名
语法格式:
import osos.rename(current_filename,new_filename)示例:
>>> import os>>> os.rename('D:\\data.txt','D:\\newdata.txt')④删除文件(系统中已存在的文件)
语法格式:
import osos.remove(filename)3、基本的目录方法
①创建与删除目录(文件夹)
os.mkdir('newdir')os.rmdir('dirname')示例:
>>> import os>>> os.mkdir('D:\\testdir')>>> os.rmdir('D:\\testdir')②显示当前工作目录
os.getcwd()示例:
>>> os.getcwd()'D:\\python3.6.6'③改变当前工作目录
os.chdir('newdir')十一、爬虫
爬虫又称网络机器人,可以代替人工从互联网中采集、整理数据。常见的网络爬虫主要有百度公司的Baiduspider、360公司的360Spider、搜狗公司的Sogouspider、微软的Bingbot等。
1、准备工作
爬取一个站点之前,需要大致了解站点规模和结构。站点自身的robots.txt和sitemap文件都能为我们提供帮助。
①robots文件:一般大部分站点会自定义自己的robots文件,以便引导爬虫按照自己的意图爬取相关数据。robots文件能使我们了解该站点的限制条件,提升爬取成功率;也可了解到站点结构,使我们有针对性地设计程序。
②sitemap文件:呈现了整个站点的组成结构,可根据需求定位需要的内容;但是该文件可能存在更新不及时或不完整的情况。
③估算站点规模:目标站点的大小会影响爬取的效率,通常可通过百度搜索引擎百度搜索引擎site关键字过滤域名结果,获取相关统计信息(如在www.baidu.com搜索框输入“site:目标站点域名”)
2、爬虫类型
按照实现的技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。实际的网络爬虫系统是由它们组成的。
①通用网络爬虫:又称全网爬虫,主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块构成。其获取的目标资源在整个互联网中,目标数据量庞大,爬行范围广泛,对性能的要求较高,主要用在大型搜索引擎(如百度搜索),应用价值较高。
②聚焦网络爬虫:又称主题网络爬虫,主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块构成。按照预先设定的主题在一定范围内爬取,对于网络的带宽资源及服务器资源要求较低,主要用于特定信息的获取。
③增量式网络爬虫:主要由本地页面URL集合、待爬行URL集合、本地页面集、爬行模块、排序模块、更新模块构成。对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫。与周期性爬行和刷新页面的爬虫相比,增量式网路爬虫只会在需要的时候爬取新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,减少时间和空间上的浪费,但增加了算法难度。
④深层网络爬虫:主要由URL列表、LVS列表、爬行控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器构成,其中LVS是指标签/数据集合,用来表示填充表单的数据源。用于爬取互联网深层页面的爬虫程序,与通用爬虫相比,深层页面的爬取需要想办法自动填充对应的表单,因而,深层网络爬虫的核心在于表单的填写。
3、爬虫原理
不同爬虫程序的原理不尽相同,但是都有“共性”,下面用一个通用爬虫网络的结构来说明爬虫的基本工作流程。
①按照预定主题,选取一部分精心挑选的种子URL②将种子URL放入待抓取的URL队列中③从待抓取URL队列中依次读取种子URL,解析其对应的DNS,并得到对应的主机IP,将URL对应的网页下载下来,并存入已下载网页数据库中,随后将已访问的种子URL出队,放入已抓取URL队列中。④分析已抓取队列中的URL,从已下载网页数据中分析出其他的URL,并和已抓取的URL进行重复性比较。最后,将去重过的URL放入待抓取的URL队列中,重复③④操作,直到待抓取URL队列为空。Python爬虫有三个比较实用的库:Requests、BeautifulSoup和Lxml,为我们编写爬虫程序提供很大支持。
4、Requests库
安装:
pip install requestsRequests库主要有7种主要方法:**①requests.get(‘域名’)**方法主要用于获取HTML网页,相当于HTTP的GET。返回对象response的常用属性如下:
r.status_code:HTTP请求的返回状态,200表示链接成功,404表示失败。r.text:HTTP响应内容的字符串形式,即url对应的页面内容。r.encoding:从HTTP header中猜测的响应内容编码方式。r.apparent_encoding:从内容中分析出的响应内容的编码方式。r.content:HTTP响应内容的二进制形式。**②requests.head(‘域名’)**方法主要用于获取HTML网页头部信息,相当于HTTP的HEAD。返回对象也是response
**③requests.post(‘域名’,data=xxx)**方法主要用于向HTTP网页提交POST请求,相当于HTTP的POST,xxx可以使字典名或字符串。返回对象也是response
**④requests.put(‘域名’,data=xxx)**方法主要用于向HTTP网页提交put请求,相当于HTTP的PUT,xxx可以使字典名或字符串。**⑤requests.patch(‘域名’,data=xxx)**方法主要用于向HTTP网页提交局部修改请求,相当于HTTP的PATCH。
**⑥requests.delete('域名')**方法主要用于向HTTP页面提交删除请求,相当于HTTP的DELETE。**⑦requests.requests(method,url,**kwargs)**方法主要用来构造一个请求,支撑①~⑥各个基础方法。其中method是指请求方式,对应get()、put()等方法,例如’GET‘、’PUT‘;url为目标页面的url链接地址;**kwargs代表控制访问参数,共13个。
爬取定向网页的通用代码框架下面的示例有利于使大家按照统一的编程风格编写程序,提高通用代码的可读性:
import requestsdef getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() # 如果状态码不是200,引发HTTPError异常 r.encoding = r.apparent_encoding return r.text except: return "产生异常"if __name__ == "__main__": # 限定getHTMLText()只在所定义的文件中执行 url = "https://www.baidu.com/" print(getHTMLText(url))5、BeautifulSoup库
BeautifulSoup是一个用Python编写的HTML/XML的解释器,可处理不规范标记并生成剖析树,并提供导航、搜索、修改剖析树的操作。下面主要介绍如何使用该库处理不规范标记,按照指定格式输出对应文档。
安装:
pip install beautifulsoup4基本操作:
①创建BeautifulSoup对象
通过soup对象格式化函数prettify可格式化输出soup对象中的内容,该函数是分析HTML文档的第一步。
②BeautifulSoup库的对象
BeautifulSoup库用于将一个复杂HTML文档转化为一个复杂的树形结构,每个节点都是一个Python对象,据功能该库的对象分为4类:Tag对象:得到标签内容NavigableString对象:获取标签内部的文字用.stringBeautifulSoup对象:可当作特殊的Tag对象,表示一个文档全部内容Comment对象:可当作特殊的NavigableString对象,输出实际内容仍不包括注释符号
③遍历文档搜索文档树的find_all()方法:
fand_all(name,attrs,recursive,text,**kwargs)
6、Lxml库
Lxml库是另一种高效的网页解析库,速度比BeautifulSoup快。
安装:
pip install lxmlPython中数据可视化有多种实现方式,下面以实战项目需求为导向介绍几种比较流行的数据可视化模块:Pyplot模块、Seaborn模块、Artist模块、Pandas模块。(个人经常用到pyplot和seaborn)
十二、绘图
1、Matplotlib模块(常用)
Matplotlib提供了一整套和Matlab类似的命令API,适合交互式制图。可方便地作为绘图控件,嵌入GUI应用程序。文档完备https://matplotlib.org/3.1.1/gallery/index.html各种图打开都有源程序。
①绘图流程&常用图
①分别导入Matplotlib.pyplot和numpy②定义横轴标度并以横轴标度为自变量,定义纵轴功能函数③figure()函数指定图像长宽比④plot()函数绘制功能函数⑤plt的属性函数设置图像属性⑥show()函数显示图像格式:
plt.plot(x,y,其他参数)其他参数label、color、linewidth、b--(同时指定颜色和线型,点(.)实线(-)虚点线(-.)点线(:)虚线(--)无线条(‘"‘))
常用图类型:
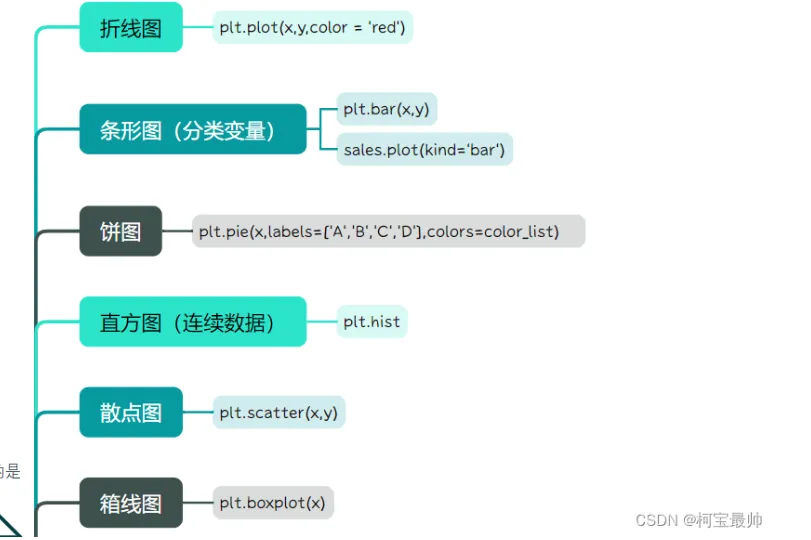
折线图plt.plot演示:
import matplotlib.pyplot as pltimport numpy as npx = np.linspace(0, 10, 1000)y = np.sin(x)z = np.cos(x**2)plt.figure(figsize=(8, 4))plt.plot(x, y, label="$sin(x)$", color="red", linewidth=2) # 绘图并指定了线的标签,颜色,粗细plt.plot(x, z, label="$cos(x^2)$", color="blue", linewidth=1)plt.xlabel("Times")plt.ylabel("Volt")plt.title("PyplotTest")plt.ylim(-1.2, 1.2) # y轴显示范围plt.legend() # 显示图中左下角的提示信息,即提示标签(哪个线是哪个函数)plt.show() # 补充显示图像的关键语句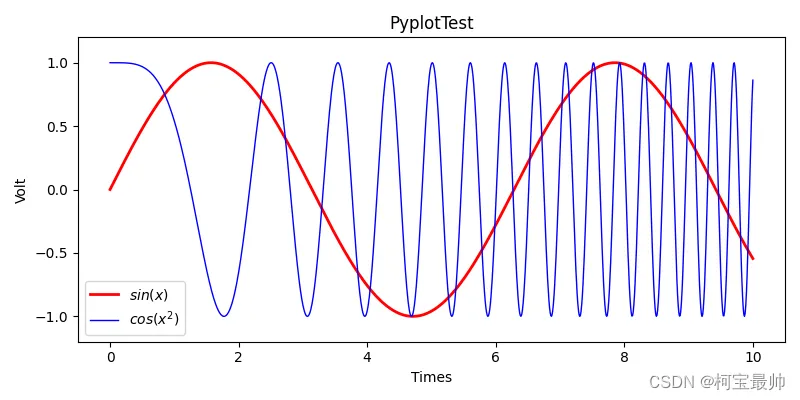
②绘制子图&添加标注
Matplotlib中用轴表示一个绘图区域,一个绘图对象(figure)可包含多个轴(axis),可理解为子图。可用subplot函数快速绘制有多个轴的图表(子图):
subplot(numRows,numCols,plotNum)将绘图区域分为numRows x numCols个子区域,从左到右从上到下依次编号,从编号1开始。三个参数都小于10时可省略之间逗号
标注即为图的注释:
①text()函数可将文本放置在轴域的任意位置,用来标注绘图的某些特征
②annotate()方法提供辅助函数进行定位,使标注变得准确方便文本位置及标注点位置均由元组(x,y)描述,参数x,y表示标注点位置,参数xytext表示文本位置
③...
# 子图绘制演示(接着上面示例的构建的函数)fig = plt.figure(figsize=(8, 4))ax = fig.add_subplot(211) # 创建Axes对象plt.subplot(2, 1, 1) # 两行一列个子区域,编号1位置plt.plot(x, y, label="$sin(x)$", color="red", linewidth=2)plt.ylabel("y-Volt")plt.legend()plt.subplot(2, 1, 2) # 两行一列个子区域,编号2位置plt.plot(x, z, label="$cos(x^2)$", color="blue", linewidth=1)plt.ylabel("z-Volt")plt.xlabel("Times")ax.annotate("sin(x)", xy=(2,1), xytext=(3,1.5), arrowprops=dict(facecolor='black', shrink=0.05)) # 添加文字和黑色箭头ax.set_ylim(-2, 2)plt.show()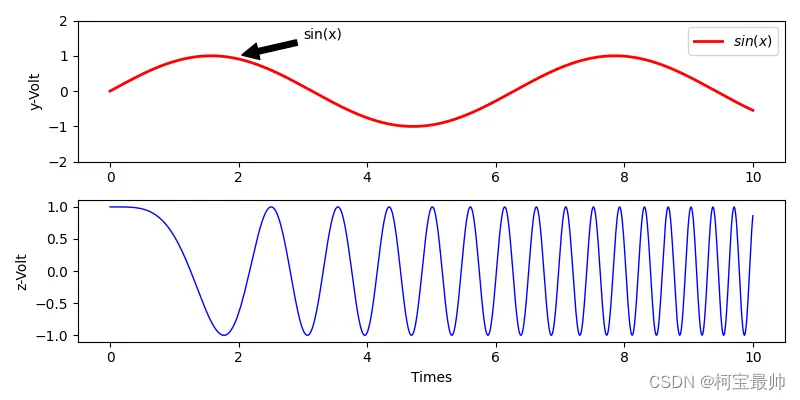
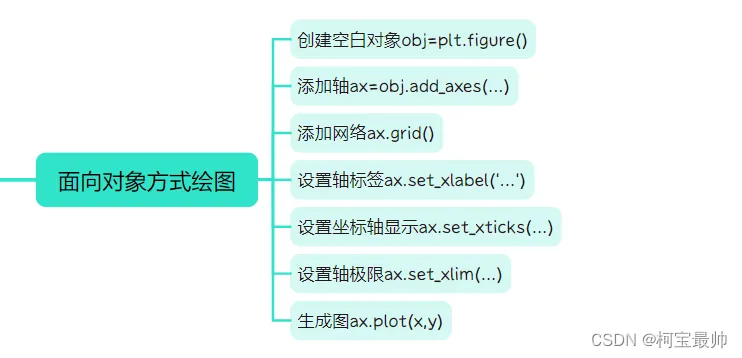
③面向对象画图
④Pylab模块应用
也是matplotlib里面的一个模块,提供可绘制二维、三维数据的工具模块,包含numpy和pyplot模块中的常见函数,方便快速计算和绘图。
2、Seaborn模块(常用)
它基于matplotlib,但提供了更高级的统计图形方法!
①常用图

②代码示例
下面选取逻辑回归算法(一种分类算法,titannic数据集)中特征工程(数据预处理)中的一段代码演示:
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seabornimport sklearnfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn import preprocessing# 读取泰坦尼克号数据集(幸存/遇难者信息)titanic_data = pd.read_csv("titanic_data.csv")# 选取需要分析的8列特征titanic_data = titanic_data[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Embarked', 'Fare']]# 1. 特征工程# Age有177个空值,用平均值填充titanic_data['Age'].fillna((titanic_data['Age'].mean()), inplace=True)# Embarked只有2个空值,直接删除含空值的行titanic_data.dropna(inplace=True)# 分离自变量X(特征)和因变量Y(是否存活:1/0)titanic_data_X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Embarked', 'Fare']]titanic_data_Y = titanic_data[['Survived']]# 将数据按8:2比例划分为训练集和测试集X_train, X_test, Y_train, Y_test = train_test_split( titanic_data_X, titanic_data_Y, test_size=0.20)seaborn.countplot(x='Pclass', data = X_train) #检查Pclass(舱位等级)柱状图plt.show()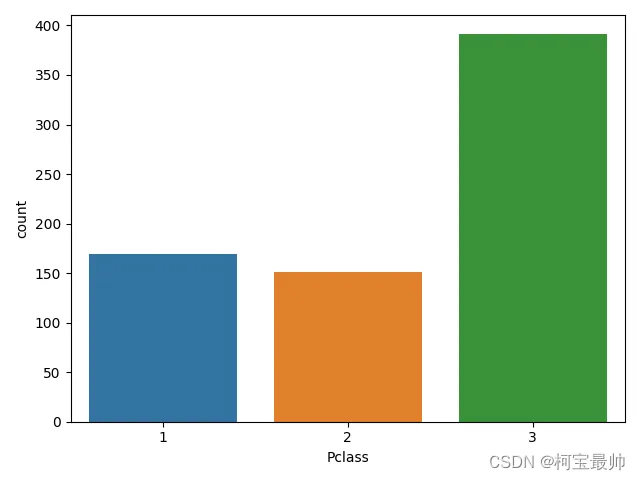
seaborn.displot(X_train['Age']) #检查Age分布图(柱状图+核密度估计)plt.show()seaborn.displot(X_train['Fare']) #检查Fare(票价)分布图(柱状图+核密度估计)plt.show()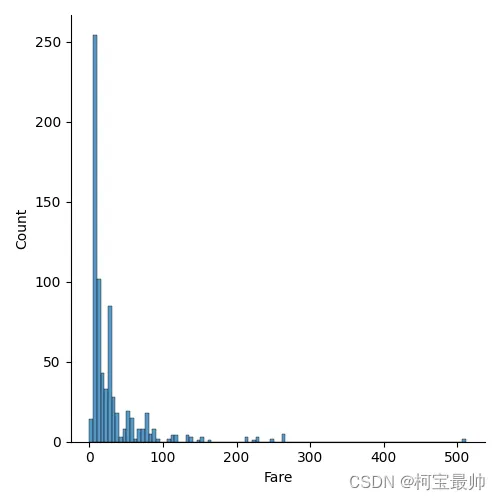
# 对Age进行Z-Score标准化age_scaler = StandardScaler()age_scaler.fit(pd.DataFrame(X_train['Age']))X_train.loc[:, 'Age'] = age_scaler.transform(X_train[['Age']]) # 双[]保持DataFrame格式# 对Fare(票价)进行Z-Score标准化fare_scaler = StandardScaler()fare_scaler.fit(pd.DataFrame(X_train['Fare']))X_train.loc[:, 'Fare'] = fare_scaler.transform(X_train[['Fare']]) # 双[]保持DataFrame格式# 将Sex类别特征映射为数值(female=0,male=1)X_train.loc[:, 'Sex'] = X_train['Sex'].map({'female': 0, 'male': 1})# 对Embarked(登船口)类别特征进行标签编码embarked_encoder = preprocessing.LabelEncoder()embarked_encoder.fit(pd.DataFrame(X_train['Embarked']))X_train.loc[:, 'Embarked'] = embarked_encoder.transform(X_train[['Embarked']])# 绘制热力图,检查特征之间的关联性seaborn.heatmap(X_train.corr())plt.show()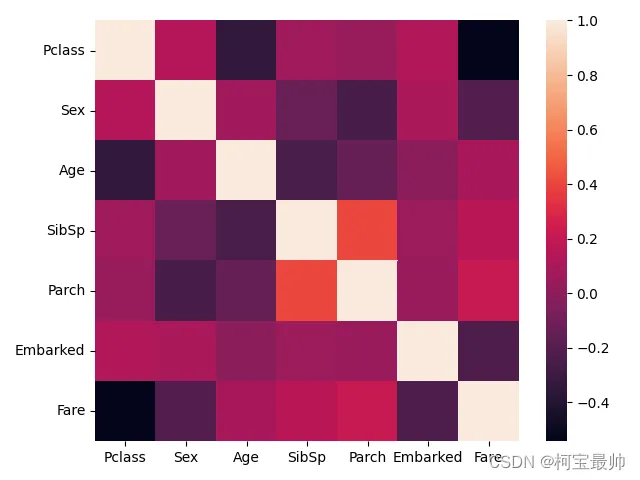
3、Artist模块
Matplotlib绘图库的API包含3个图层——画板、渲染、artist.Artist(如何渲染)。相比Pyplot和Pylab两个API,Artist用于处理所有的高级结构,如处理图表、文字、曲线等的绘制和布局,不需要关注底层的绘制细节。
Artist分简单类型、容器类型两种。
简单类型的Artist为标准的绘图元件,如Line2D、Rectangle、Text、AxesTmage等;容器类型可以包含许多简单类型的Artist组成一个整体,如Axis、Axes、Figure等。
步骤:
①创建Figure对象②用Figure对象创建一个或多个Axes或者Subplot对象③调用Axes等对象的方法创建各种简单类型的ArtistMatplotlib所绘制的图表中的每一个元素都由Artist控制,而每一个Artist对象包含很多属性来控制显示效果,常见属性:
alpha透明值,0完全透明,1完全不透明animate布尔值,绘制动画效果是使用axes此Artist对象所在的Axes对象,可能为Nonefigure此Artist对象所在的Figure对象,可能为Nonelabel文本标签picker控制Artist对象选取zorder控制绘图顺序所有属性都可通过相应的**get_*和set_***函数读写,如将alpha设置为当前值的一半:
fig.set_alpha(0.5*fig.get_alpha())若一句代码设置多个属性:
fig.set(alpha = 0.5,zorder = 2,label = '$sin(x)$')4、Pandas绘图
pandas是python最强大的数据分析和探索工具,包含高级的数据结构和精巧的工具。
它构建在numpy之上,使得以numpy为中心的应用更便捷;支持类似于SQL的数据操作,具有丰富的数据处理函数;它的作图依赖于matplotlib,通常两者一起使用。
①数据框(dataframe)&系列(series)
pandas带两个重要数据结构:数据框(dataframe)、系列(series)
数据框:
二维表,行列都有索引,面向行列的操作对称。
创建数据框的方法很多,常用包含相等长度列表的字典或Numpy数组来创建数据库,行索引默认由0开始,列索引用户自定义(也可自定义行索引,列索引要与字典对应不然数据为空)
import pandas as pddata = { 'name': ['小明', '小红', '小刚', '小强', '大壮'], 'age': [15, 16, 14, 18, 20], 'score': [88, 99, 65, 95, 67]}dataframe1 = pd.DataFrame(data)dataframe2 = pd.DataFrame( data, columns=['name', 'age', 'score'], index=['one', 'two', 'three', 'four', 'five'])print(dataframe1)print(dataframe2)系列:
对具有同一属性的值的统称,可理解为一维数组(退化了的数据框)
print(dataframe2['name'])运行结果:one 小明two 小红three 小刚four 小强five 大壮Name: name, dtype: object②pandas常用绘图函数
plot():绘制线性二维图(matplotlib/pandas库都有)pie():绘制饼形图(matplotlib/pandas、库都有)hist():绘制二维条形直方图(matplotlib/pandas库都有)boxplot():绘制样本数据箱体图(pandas库)plot(logy = True):绘制y轴的对数图(pandas库)plot(yerr = error):绘制误差条形图(pandas库)十三、机器学习和AI库:科研人必知
不用深入理解算法原理,只需知道“什么场景用什么库、怎么让AI帮你用”,聚焦科研中最常用的机器学习/AI功能,而非复杂理论。
1. 科研中你真的需要哪些AI库?(拒绝盲目学)
• 核心原则:只学“能直接落地到论文”的库,以下是高频刚需库清单(附场景): 库名称 核心用途 科研场景举例 scikit-learn 经典机器学习(拟合/分类/回归) 实验数据拟合、样本分类 NumPy/Pandas 数据预处理(清洗/计算/格式转换) 处理CSV/Excel实验数据、去异常值 Matplotlib/Seaborn 可视化(画图/出图) 拟合曲线、残差图、对比柱状图 TensorFlow/PyTorch(轻量化) 简单深度学习(可选) 图像类实验、复杂时序数据预测 statsmodels 统计分析(显著性检验/回归诊断) 实验结果的统计验证、P值计算
2. 如何“用基础知识点”指挥AI调用这些库?
• 新手避坑:不用背API、不用记参数,只需掌握“向AI描述需求的关键词”:✅ 正确描述:“帮我用sklearn的RANSACRegressor(鲁棒拟合)处理含噪声的实验数据,剔除3σ异常值,用Pandas读取CSV文件”❌ 错误描述:“帮我用AI拟合数据” • 实操示例:给AI的“指令模板”(可直接复制): “我需要用Python处理论文中的实验数据:1. 用Pandas读取‘实验数据.csv’(第一列时间、第二列吸光度);2. 用sklearn的最小二乘法做线性拟合,排除异常值;3. 输出拟合参数、R²值,用Matplotlib画出拟合曲线(要求高清、白底、宋体);4. 代码加详细注释,兼容中文路径。”
3. AI写的库代码容易出什么问题?
• 常见问题1:库版本不兼容(比如sklearn版本过高/过低)→ 让AI在代码开头加“版本适配说明”; • 常见问题2:数据格式报错(比如空值、字符串混数字)→ 让AI加“数据清洗前置步骤”; • 常见问题3:出图模糊(不符合论文要求)→ 明确要求AI设置“dpi=300、figsize=(8,6)”。
十四、AI辅助:“会问”到“即用论文级代码”
这是全文的“最终落地章”,教你从“只会说帮我写代码”升级为“精准指挥AI产出高质量代码”,附可直接套用的prompt模板和实操案例。
1. “三层提问法”(对应你的知识储备)
结合你前文提到的“知识储备分层”,我们升级提问逻辑,新增深度学习场景,无论你是基础薄弱,还是能熟练描述需求,都能对应找到合适的提问方式,避免“AI听不懂、输出用不了”的尴尬。
核心原则:知识储备越多,提问越具体,AI输出质量越高,哪怕你只掌握了前文1-12章的基础,也能跳过“无基础”阶段,直接进入“有基础”提问。
关键提醒:非计算机专业科研人,无需追求“专业级”提问,能达到“有基础”级提问,就已经能解决90%的科研代码需求;深度学习代码无需自己修改模型结构,让AI帮你选择“轻量化模型”,避免电脑跑不动、训练耗时久的问题。
2. 科研代码的“AI提问万能模板”
不用自己组织语言,直接替换模板中的「括号内容」,就能向AI下达精准指令,无论你是写常规数据处理代码,还是深度学习代码,都能套用,彻底解决“不知道怎么问”的问题。模板核心逻辑:场景→工具→数据→需求→输出要求→约束,和AI的“理解逻辑”完全匹配,避免歧义。
模板1:常规科研代码(拟合、数据处理、可视化,适配sklearn/NumPy等库)
【场景】:论文《XXX》中XX章节的XX实验数据处理(如“论文《某材料的吸光度实验研究》中3.2章节的吸光度数据拟合”)【工具】:Python 3.9,使用XX库(如sklearn/Pandas/Matplotlib/statsmodels)【数据】:数据文件为XX格式(CSV/Excel),文件路径为XX(如“D:\实验数据\吸光度数据.csv”),数据列说明:XX列是自变量(如时间),XX列是因变量(如吸光度),数据存在XX问题(如异常值/空值/噪声,无则写“无特殊问题”)【需求】:1. 数据预处理(如剔除3σ异常值、跳过空值、归一化,无则写“无需预处理”);2. 核心计算(如最小二乘拟合/线性回归/显著性检验,明确具体方法);3. 可视化(如拟合曲线/残差图/柱状图,明确图表类型)【输出要求】:1. 代码加详细注释(每一步说明用途,方便论文附录使用);2. 输出核心结果(如拟合参数/R²值/P值,保留4位小数);3. 图片保存为XX格式(PNG/PDF,优先PDF矢量图,符合论文要求),要求高清(dpi=300)、白底、宋体字体,坐标轴标签清晰;4. 兼容中文路径,避免中文报错【其他约束】:如Python版本要求、库版本要求(如“sklearn版本0.24.2”)、结果保存路径(如“保存到D:\实验数据\结果\”)模板2:深度学习科研代码(图像/时序数据,适配TensorFlow/PyTorch库)
【场景】:论文《XXX》中XX章节的XX深度学习实验(如“论文《基于深度学习的细胞图像分类研究》中4.1章节的细胞图像分类实验”)【工具】:Python 3.9,使用XX深度学习库(TensorFlow/PyTorch,二选一,推荐轻量化使用),搭配Matplotlib/Pandas辅助【数据】:数据类型为XX(图像/时序数据),数据路径为XX(如“D:\实验数据\细胞图像\”),数据说明:图像尺寸XX*XX(如224*224),分为XX类(如正常细胞/异常细胞,共2类),标签文件为XX格式(CSV/XML,无则写“无单独标签文件,按文件夹分类”)【需求】:1. 数据预处理(如图像尺寸调整、灰度化/归一化、数据增强(可选,如随机裁剪)、划分训练集和测试集(比例7:3));2. 模型选择(要求轻量化,如“TensorFlow的MobileNetV2”“PyTorch的ResNet18,冻结部分层数”);3. 模型训练(要求加入早停(EarlyStopping)防止过拟合,训练轮次XX轮(如50轮),批次大小XX(如32));4. 结果评估(输出测试准确率、混淆矩阵、训练曲线(损失/准确率))【输出要求】:1. 代码加详细注释(模型结构、训练步骤、结果输出部分重点注释,方便论文说明);2. 输出训练日志、测试准确率、混淆矩阵;3. 训练曲线、混淆矩阵保存为高清图片(dpi=300,PDF格式,贴合论文排版);4. 模型保存为XX格式(如.h5/.pth),可后续调用;5. 兼容中文路径,代码可直接复制运行,无需额外配置复杂环境【其他约束】:如Python版本要求、库版本要求(如“TensorFlow 2.10.0”“PyTorch 1.12.0”)、电脑配置适配(如“无需GPU,CPU可运行”)、结果保存路径示例演示(直接复制给AI就能用):
深度学习示例:
【场景】:论文《基于PyTorch的植物叶片病害识别》中3.3章节的病害识别实验;
【工具】:Python 3.9,使用PyTorch库,搭配Matplotlib、Pandas;
【数据】:数据类型为图像,路径为“D:\叶片数据\”,图像尺寸224224,分为3类(健康叶片、病害1、病害2),按文件夹分类(每个文件夹对应一类);
【需求】:1. 数据预处理:调整图像尺寸为224*224,灰度化,划分训练集和测试集(7:3),加入随机翻转的数据增强;2. 模型选择:用ResNet18,冻结前5层,轻量化训练;3. 模型训练:加入早停,训练50轮,批次大小32;4. 结果评估:输出测试准确率、混淆矩阵、训练曲线;
【输出要求】:1. 代码加详细注释;2. 输出训练日志、测试准确率;3. 训练曲线、混淆矩阵保存为PDF格式(dpi=300);4. 保存模型为.pth格式,兼容中文路径;【其他约束】:无需GPU,CPU可运行,结果保存到“D:\叶片数据\结果\”。”
3. 让AI帮你“debug+优化代码”
科研中,哪怕AI写出的代码,也可能出现报错(如数据格式错误、库版本不兼容)、运行缓慢、结果不达标等问题,不用自己查资料解决,让AI帮你“兜底”,省时又高效,这也是“指挥AI”的核心能力之一。
①场景1:代码报错(最常见,常规+深度学习都适用)
提问公式:报错信息+代码片段+你的数据情况+需求
示例1(常规代码报错):
“我用你写的Python拟合代码运行时,出现报错:‘FileNotFoundError: [Errno 2] No such file or directory: '实验数据.csv'’,代码片段如下(粘贴AI写的代码),我的数据文件是CSV格式,放在D盘根目录,文件名叫“实验数据1.csv”,帮我定位报错原因,修改代码,确保能正常运行,同时保留原来的拟合需求。”
示例2(深度学习代码报错):
“我用你写的PyTorch图像分类代码运行时,出现报错:‘RuntimeError: Expected input batch_size (32) to match target batch_size (1)’,代码片段如下(粘贴AI写的模型训练部分代码),我的图像是224*224灰度图,分为2类,帮我找到报错原因,修改代码,说明报错逻辑(方便我论文中规避),确保能正常训练。”
②场景2:优化代码(提升效率、贴合论文要求)
提问公式:代码片段+优化需求(明确、具体)
示例1(常规代码优化):
“帮我优化这段Python拟合代码(粘贴代码),优化要求:1. 提升运行速度(我的数据量较大,约1000组);2. 增加残差分析的输出(如残差均值、标准差);3. 调整图表格式,让坐标轴标签字号12,标题字号14,图例在右上角,线条宽度2px,保存为PDF矢量图;4. 代码更简洁,注释更规范,贴合论文附录要求。”
示例2(深度学习代码优化):
“帮我优化这段PyTorch深度学习代码(粘贴代码),优化要求:1. 提升训练速度(我的实验电脑没有GPU,CPU运行),可简化模型结构、调整批次大小;2. 加入学习率衰减,防止过拟合;3. 优化训练曲线,同时输出训练损失、测试损失、训练准确率、测试准确率,图表颜色搭配简洁(贴合论文排版,避免花哨);4. 增加代码容错性(如跳过损坏的图像文件);5. 保留详细注释,适配论文说明。”
③场景3:代码适配论文(核心需求,重中之重)
提问公式:代码片段+论文格式要求
示例:“帮我调整这段代码(粘贴常规/深度学习代码),适配论文要求:1. 代码注释规范,每一步操作说明用途(如“读取数据:用Pandas读取CSV文件,跳过空值,确保数据完整性”),方便论文附录引用;2. 输出结果保留4位小数,图表为白底、宋体,dpi=300,PDF格式,可直接插入论文;3. 深度学习代码需补充模型结构说明(如“使用ResNet18轻量化模型,冻结前5层,减少训练量,适配CPU运行,避免过拟合”),常规代码需补充方法说明(如“使用鲁棒最小二乘拟合,剔除3σ异常值,提升拟合精度”);4. 代码末尾加入运行说明(如“运行环境:Python 3.9,sklearn 0.24.2,无需额外配置”)。”
4、深度学习专属:新手避坑指南(非计算机专业必看)
很多科研人提到深度学习就害怕,觉得“复杂、难操作”,其实只要找对方法,让AI帮你规避难点,就能轻松上手,重点记住以下4个避坑点,避免走弯路:
• 避坑1:不追求“复杂模型”,优先选择“轻量化模型”—— 科研中,深度学习代码的核心是“能用、能出结果、能放进论文”,无需搭建复杂模型(如ResNet50、Transformer),让AI选择MobileNetV2、ResNet18等轻量化模型,冻结部分层数,既能减少训练时间,又能适配普通科研电脑(无需GPU)。 • 避坑2:不自己写模型结构,让AI帮你搭建、注释—— 无需记住CNN、RNN的模型结构,直接在提问中要求AI“搭建轻量化模型,补充模型结构注释”,AI会帮你完成模型定义、层设置,你只需关注“输入输出”即可。 • 避坑3:数据预处理不复杂,简化步骤—— 深度学习的核心痛点是“数据预处理”,无需做复杂的增强操作,让AI帮你完成“尺寸调整、归一化、划分数据集”即可,复杂的数据增强(如旋转、裁剪)可根据需求选择,无需强制添加。 • 避坑4:不纠结“训练参数”,让AI给出默认值+说明—— 无需记住“学习率、批次大小、训练轮次”的最优值,让AI在代码中设置合理的默认值(如学习率0.001、批次大小32、训练轮次50),并说明“可根据数据量调整”,后续根据运行结果,让AI帮你优化参数即可。
5、最终避坑清单
无论你是写常规代码,还是深度学习代码,记住这5点,能让你少走90%的弯路,确保AI输出的代码“能用、达标、贴合论文”:
1. 永远向AI说明“你的数据情况”—— 包括数据格式、路径、列说明(常规代码)、图像尺寸、类别数(深度学习代码),否则代码大概率出现“文件找不到、数据不匹配”的报错,这是新手最常犯的错误。 2. 提问时“明确工具和版本”—— 比如“Python 3.9”“TensorFlow 2.10.0”,避免AI输出的代码与你的运行环境不兼容,减少报错概率。 3. 必须要求AI“代码加详细注释”—— 一方面方便你看懂代码、修改代码,另一方面方便论文附录引用,注释越详细,论文的严谨性越高。 4. 先用“小样本数据”测试代码—— 无论是常规代码,还是深度学习代码,先用少量数据(如10组常规数据、20张图像)测试,确认代码能正常运行、输出结果符合预期,再用全量实验数据,避免浪费时间。 5. 关键结果“手动验算/验证”—— AI偶尔会出现逻辑错误(如拟合参数计算错误、深度学习模型标签对应错误),核心结果(如拟合参数、测试准确率)一定要手动验算或验证一遍,确保结果正确,避免影响论文质量
AI辅助编程的核心,从来不是“让AI替你完成所有事”,而是“你用自己的科研专业知识+前文掌握的Python基础、AI库知识,精准指挥AI,帮你高效完成代码编写、debug、优化”。
对于非计算机专业的科研人来说,你不需要精通编程,不需要吃透深度学习算法,只要能“清晰描述自己的实验需求”,套用本章的提问模板,就能让AI产出论文级代码。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 什么芯片组?服役 30 年才被 Linux 正式弃用
- 轻量化Xubuntu Linux安装体验
- 7python之会话列表及聊天时更新会话名
- 【解读】 Python 语言在数据分析领域的作用趋势:高校课程设置变化为例
- 为了忘却的纪念——2022 Linux 内核十大技术革新功能 | 年终盘点
- 熠熠生辉 | 2023 年 Linux 内核十大技术革新功能
- 2024年Linux内核十大技术革新盘点|年终盘点
- Linux 运维神器 lsof!搞定端口占用 / 磁盘不释放等问题
- 在Linux上开发ESP32C3时由于ModemManager导致的异常排除笔记
- 一图总结python最常用的工具库!
