【Python时序预测系列】建立CNN-LSTM-Transformer融合模型实现多变量多步时序预测(案例+源码)
- 2026-07-04 09:42:12
【Python时序预测系列】建立CNN-LSTM-Transformer融合模型实现多变量多步时序预测(案例+源码)写在前面 


热门原创文章推荐阅读点击标题可跳转 写在后面 
免费电子书籍,带你入门人工智能:
这是我的第452篇原创文章。
『数据杂坛』以Python语言为核心,垂直于数据科学领域,专注于(可戳👉)Python程序设计|数据分析|特征工程|机器学习分类|机器学习回归|深度学习分类|深度学习回归|单变量时序预测|多变量时序预测|语音识别|图像识别|自然语音处理|大语言模型|软件设计开发等技术栈交流学习,涵盖数据挖掘、计算机视觉、自然语言处理等应用领域。(文末有惊喜福利)
一、引言
下面通过一个具体的案例,融合CNN + LSTM + Transformer进行多变量输入单变量输出多步时间序列预测,包括模型构建、训练、预测等等。
二、实现过程
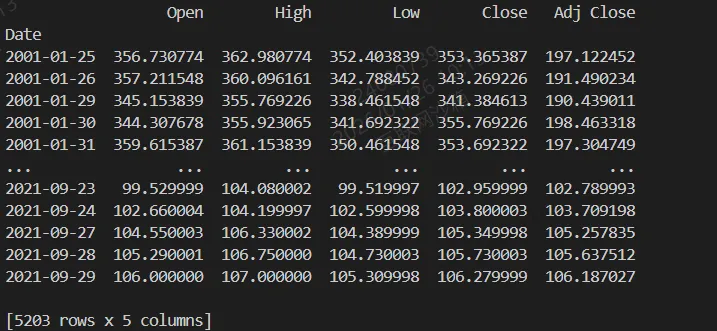
2.1 原始数据集加载
核心代码:
df = pd.read_csv('/workspaces/Data-Miscellany-Forum/src/多变量时序预测系列-股票预测/多输入+单输出+多步/data.csv', parse_dates=["Date"], index_col=[0])df = pd.DataFrame(df)var_num = len(df.columns)print(df)
结果:
2.2 数据集划分
核心代码:
test_split=round(len(df)*0.20)df_for_training=df[:-test_split]df_for_testing=df[-test_split:]
2.3 数据归一化
核心代码:
scaler = MinMaxScaler(feature_range=(0,1))df_for_training_scaled = scaler.fit_transform(df_for_training)df_for_testing_scaled=scaler.transform(df_for_testing)
2.4 构造时序预测数据集
核心代码:
train_dataset = TimeSeriesDataset(df_for_training_scaled, seq_len=seq_len, pred_len=pred_len)test_dataset = TimeSeriesDataset(df_for_testing_scaled, seq_len=seq_len, pred_len=pred_len)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
2.5 建立CNN-LSTM-Transformer模型
核心代码:
class CNN_LSTM_Transformer(nn.Module):def __init__(self, input_dim=5, cnn_channels=16, lstm_hidden=32, transformer_dim=32,transformer_heads=4, transformer_layers=1, pred_len=5):super().__init__()# CNNself.cnn = nn.Conv1d(in_channels=input_dim, out_channels=cnn_channels, kernel_size=3, padding=1)self.cnn_relu = nn.ReLU()# LSTMself.lstm = nn.LSTM(input_size=cnn_channels, hidden_size=lstm_hidden, batch_first=True)# Transformer Encoderencoder_layer = nn.TransformerEncoderLayer(d_model=transformer_dim, nhead=transformer_heads, batch_first=True)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=transformer_layers)# Projection layersself.proj_lstm = nn.Linear(lstm_hidden, transformer_dim)self.pred_len = pred_lenself.fc_out = nn.Linear(transformer_dim, pred_len)def forward(self, x):# x: [batch, seq_len, 1]batch_size, seq_len, _ = x.shape# CNN expects [batch, channels, seq_len]cnn_out = self.cnn_relu(self.cnn(x.transpose(1,2))) # [B, C, T]cnn_out = cnn_out.transpose(1,2) # [B, T, C]# LSTMlstm_out, _ = self.lstm(cnn_out) # [B, T, hidden]lstm_proj = self.proj_lstm(lstm_out) # [B, T, transformer_dim]# Transformertrans_out = self.transformer(lstm_proj) # [B, T, transformer_dim]# 取最后时间步输出预测out = self.fc_out(trans_out[:, -1, :]) # [B, pred_len]return out.unsqueeze(-1) # [B, pred_len, 1]
2.6 模型训练
核心代码:
def train_model(model, dataloader, num_epochs=50, learning_rate=1e-3, device='cpu'):optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)criterion = nn.MSELoss()model.train()loss_history = []for epoch in range(num_epochs):epoch_losses = []for batch_data, batch_targets in dataloader:batch_data = batch_data.to(device)batch_targets = batch_targets.to(device)optimizer.zero_grad()outputs = model(batch_data)loss = criterion(outputs, batch_targets)loss.backward()optimizer.step()epoch_losses.append(loss.item())avg_loss = np.mean(epoch_losses)loss_history.append(avg_loss)if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")return loss_history
结果:
2.7 模型评测
核心代码:
def evaluate_model(model, dataloader, device='cpu'):model.eval()preds = []trues = []with torch.no_grad():for batch_data, batch_targets in dataloader:batch_data = batch_data.to(device)outputs = model(batch_data)preds.append(outputs.cpu().numpy())trues.append(batch_targets.cpu().numpy())# print(preds.shape)# print(trues.shape)preds = np.concatenate(preds, axis=0).squeeze()trues = np.concatenate(trues, axis=0).squeeze()print(preds.shape)print(trues.shape)return preds, trues
2.8 可视化分析
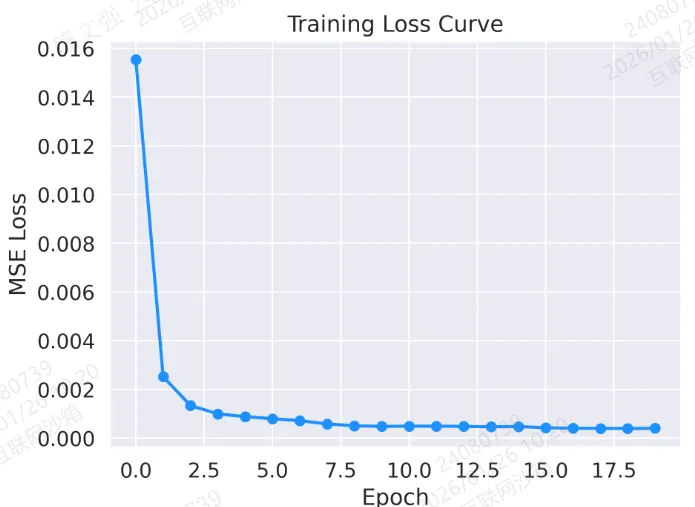
图 1:训练损失曲线
plt.plot(loss_history, marker='o', color='dodgerblue', linestyle='-', linewidth=2)plt.title("Training Loss Curve")plt.xlabel("Epoch")plt.ylabel("MSE Loss")plt.tight_layout()plt.savefig('output_image1.png', dpi=300, format='png')plt.show()
结果:
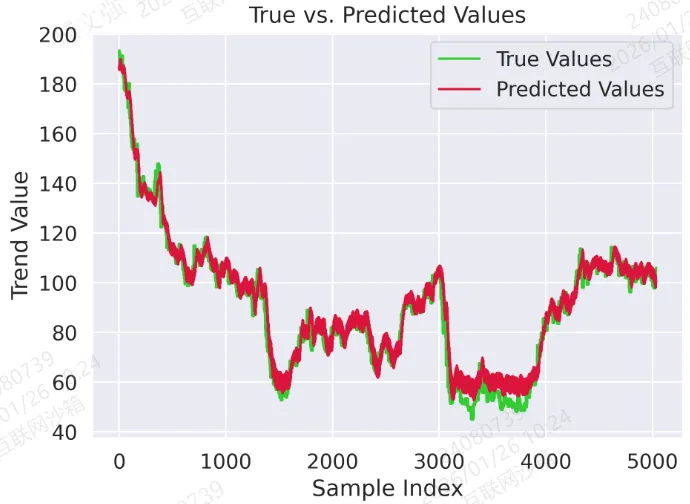
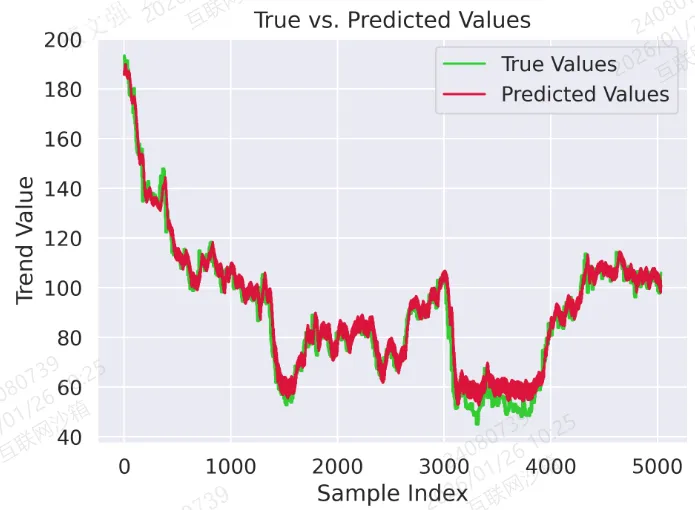
图 2:真实值与预测值对比曲线
plt.plot(trues, label="True Values", color='limegreen')plt.plot(preds, label="Predicted Values", color='crimson')plt.title("True vs. Predicted Values")plt.xlabel("Sample Index")plt.ylabel("Trend Value")plt.legend()plt.tight_layout()plt.savefig('output_image2.png', dpi=300, format='png')plt.show()
结果:
图3:测试集 单样本预测 vs 真值(多步)
idx = idxplt.figure(figsize=(10,6))plt.plot(range(1, pred_len+1), trues[idx], marker='o', linewidth=3, label="True", color=vivid_colors[1])plt.plot(range(1, pred_len+1), preds[idx], marker='s', linewidth=3, label="Pred", color=vivid_colors[0])plt.fill_between(range(1,pred_len+1), preds[idx]-0.05, preds[idx]+0.05, color=vivid_colors[0], alpha=0.15, label="±0.05 band")plt.title("comparison of multi-step predictions on test samples")plt.xlabel("prediction step(horizon)")plt.ylabel("numerical value")plt.legend()plt.tight_layout()plt.savefig('output_image3.png', dpi=300, format='png')plt.show()
结果:
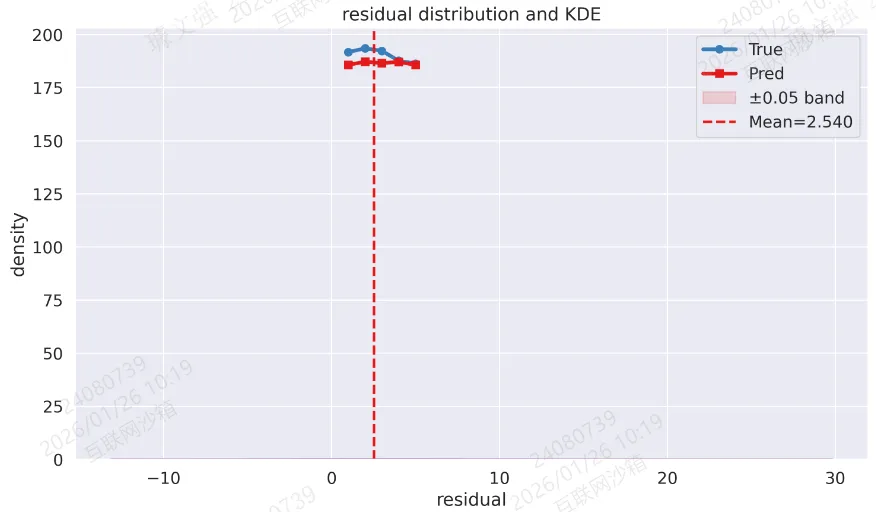
图4:残差分布与 KDE
resid = (preds - trues).reshape(-1)sns.histplot(resid, bins=40, stat="density", color=vivid_colors[3], kde=True, alpha=0.7)plt.axvline(np.mean(resid), color=vivid_colors[0], linestyle='--', linewidth=2, label=f"Mean={np.mean(resid):.3f}")plt.title("residual distribution and KDE")plt.xlabel("residual")plt.ylabel("density")plt.legend()plt.tight_layout()plt.savefig('output_image4.png', dpi=300, format='png')plt.show()
结果:
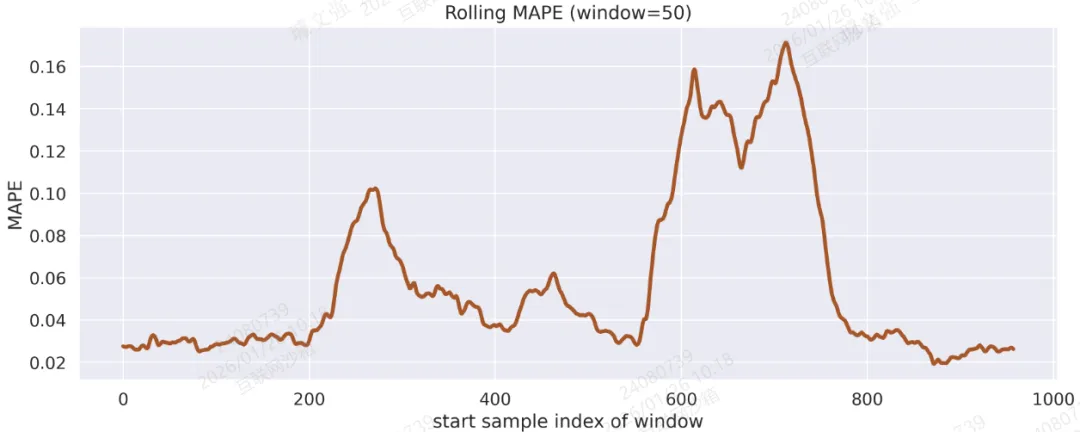
图5:Rolling MAPE(窗口=50 个样本)
win = 50mape_series = np.abs((preds - trues)/(np.abs(trues)+1e-8)).mean(axis=1)rolling = np.array([mape_series[i:i+win].mean() for i in range(0, len(mape_series)-win+1)])plt.figure(figsize=(12,5))plt.plot(rolling, linewidth=3, color=vivid_colors[6])plt.title(f"Rolling MAPE (window={win})")plt.xlabel("start sample index of window")plt.ylabel("MAPE")plt.tight_layout()plt.savefig('output_image5.png', dpi=300, format='png')plt.show()
结果:
2.9 指标计算
核心代码:
def evaluate_metrics(y_true, y_pred):y_true = y_true.reshape(-1)y_pred = y_pred.reshape(-1)eps = 1e-8mse = np.mean((y_true - y_pred)**2)rmse = np.sqrt(mse + eps)mae = np.mean(np.abs(y_true - y_pred))mape = np.mean(np.abs((y_true - y_pred)/(np.abs(y_true)+eps)))smape = np.mean(2*np.abs(y_true - y_pred)/(np.abs(y_true)+np.abs(y_pred)+eps))# R2ss_res = np.sum((y_true - y_pred)**2)ss_tot = np.sum((y_true - np.mean(y_true))**2) + epsr2 = 1 - ss_res/ss_tot# Pearsoncorr = np.corrcoef(y_true, y_pred)[0,1]return dict(MSE=mse, RMSE=rmse, MAE=mae, MAPE=mape, sMAPE=smape, R2=r2, Corr=corr)
结果:
建立CNN与Transformer融合模型实现单变量时序预测(案例+源码)
建立Transformer-LSTM-TCN-XGBoost融合模型多变量时序预测(源码)
利用SHAP进行特征重要性分析-决策树模型为例(案例+源码)
梯度提升集成:LightGBM与XGBoost组合预测油耗(案例+源码)
一文教你建立随机森林-贝叶斯优化模型预测房价(案例+源码)
建立随机森林模型预测心脏疾病(完整实现过程)
建立CNN模型实现猫狗图像分类(案例+源码)
使用LSTM模型进行文本情感分析(案例+源码)
基于Flask将深度学习模型部署到web应用上(完整案例)
新版Dify 开发自定义工具插件在工作流中直接调用(完整步骤)
作者简介:
读研期间发表6篇SCI数据算法相关论文,目前在某研究院从事数据算法相关研究工作,结合自身科研实践经历不定期持续分享关于Python、数据分析、特征工程、机器学习、深度学习、人工智能系列基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
1、关注下方公众号,点击“领资料”即可免费领取电子资料书籍。
2、文章底部点击喜欢作者即可联系作者获取相关数据集和源码。
3、数据算法方向论文指导或就业指导,点击“联系我”添加作者微信直接交流。
4、有商务合作相关意向,点击“联系我”添加作者微信直接交流。

本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。

