Python: Croissant 元数据 – 简化 ML 数据集集成
ML 数据集组织碎片化导致的开发效率瓶颈
机器学习项目大多数时间花在 数据工作 上:寻找、清洗、划分训练/验证/测试集以及分析错误。当前数据集在文件布局、标注格式、元信息描述上缺乏统一规范,致使同一类任务的开发者必须重复编写数据加载、预处理和质量检查代码。数据集搜索引擎只能基于少量通用描述(如 schema.org)定位资源,却无法直接提供 ML‑ready 的切片、标签映射或责任使用约束。结果是研发成本高、工具生态受限,尤其对资源受限的研究团队和初创企业冲击显著。
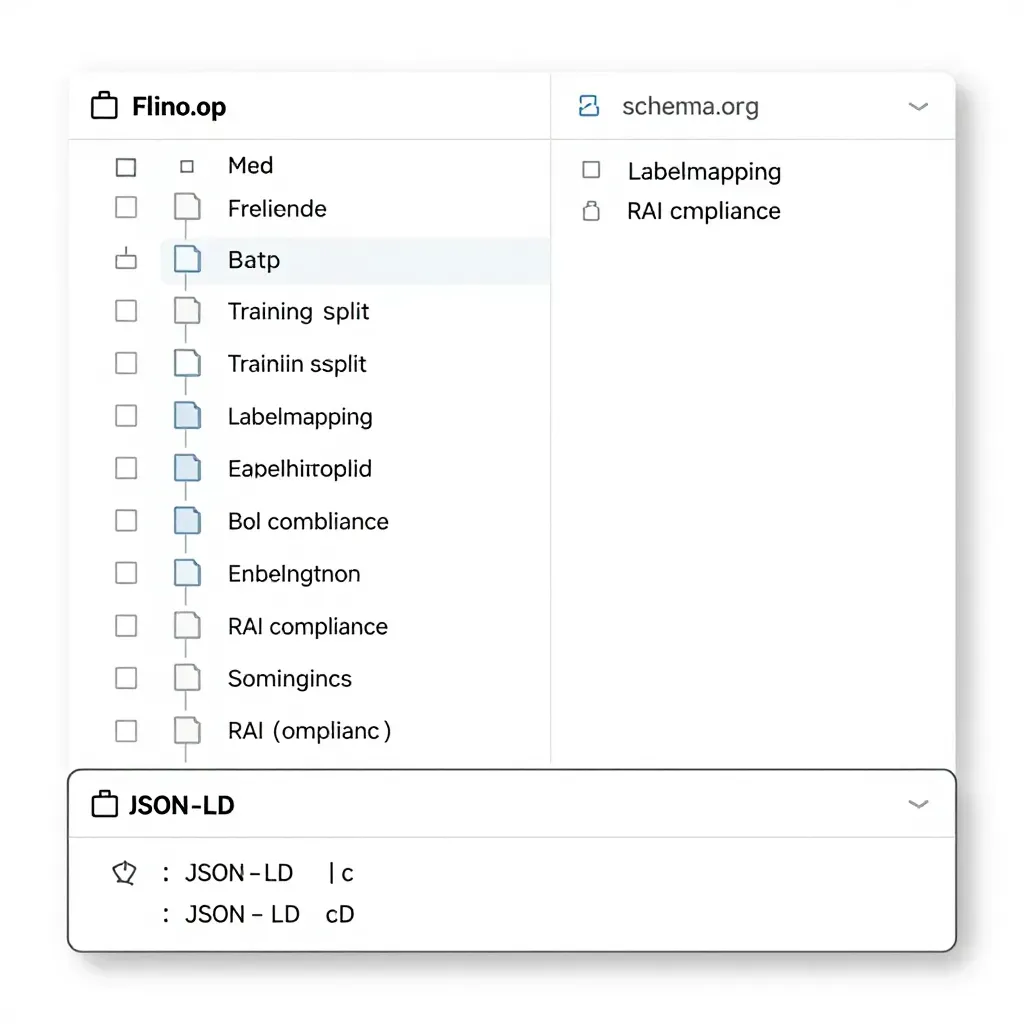
Croissant 元数据层次结构设计
Croissant 在 schema.org 基础上定义了四层扩展:
- ML 相关元信息:标注训练/验证/测试划分、默认特征/标签语义。
- 数据资源描述:列举原始文件 URL、文件格式(JPEG、CSV 等)以及校验信息(MD5、大小)。
- 组织信息:描述目录层级、分片策略(如按类别、时间窗口),便于工具自动构建 DataLoader。
- RAI(Responsible AI)词汇:包含数据生命周期、标注来源、可解释性标签及合规属性。
该结构保持 数据本体不变,仅在旁路提供统一的机器学习语义层。
基于 Python 的 Croissant 库快速入门
Croissant 官方提供 croissant 包,用于 验证、消费、生成 元数据。下面演示如何在 TensorFlow、PyTorch、JAX 三大框架中直接加载 Croissant 数据集。
# python
import croissant as cs
import tensorflow_datasets as tfds
# 1. 读取 Croissant 元数据文件(JSON-LD)
metadata = cs.load("gs://my-bucket/dataset/metadata.jsonld")
# 2. 使用 TFDS 自动生成 tf.data.Dataset
tf_dataset = tfds.load(
name=metadata.name,
data_dir=metadata.data_resources[0].path, # 自动指向资源根目录
split=["train", "validation", "test"],
as_supervised=True,
)
for image, label in tf_dataset["train"].take(1):
print(image.shape, label)
# python
import torch
from croissant import load
from torch.utils.data import DataLoader
meta = load("https://huggingface.co/datasets/xyz/metadata.jsonld")
# Croissant 为每个 split 生成 PyTorch Dataset 子类
train_ds = meta.get_split("train").as_torch_dataset()
loader = DataLoader(train_ds, batch_size=32, shuffle=True)
for batch in loader:
images, targets = batch
break
# python
import jax.numpy as jnp
from croissant import load
meta = load("https://openml.org/dataset/1234/metadata.jsonld")
val_ds = meta.get_split("validation").as_jax_dataset()
for batch in val_ds:
inputs, y = batch
# JAX 训练循环的输入即完成
break
以上示例展示了 Croissant 元数据即插即用 的特性:框架只需读取一次元信息,即可获得完整的数据切分、特征映射和校验路径,省去手工编写 tf.data、torch.utils.data.Dataset 或自定义 JAX 数据管道的繁琐工作。
视觉化编辑与社区生态
Croissant 同时提供 开源可视化编辑器,支持拖拽式创建数据描述。编辑器可实时生成 JSON‑LD,帮助数据作者在 Kaggle、Hugging Face、OpenML 等平台一键发布符合标准的元数据。
标准化元数据的成本与兼容性权衡
采用 Croissant 需要 额外维护元数据文件,对已有数据集的发布流程产生轻微的学习成本。此外,虽然 Croissant 基于 schema.org,仍需各平台实现完整的解析与验证路径,短期内可能出现 兼容性碎片。然而,这些成本被 搜索可发现性、工具自动化、负责任 AI 规范化 带来的长远收益所抵消。
落地建议与核心收益
- 快速上手:使用官方 Python 库或可视化编辑器为现有数据集补充 Croissant 元数据,即可在 TFDS、PyTorch、JAX 中零代码加载。
- 提升价值:在 Kaggle、Hugging Face 等平台发布时勾选 Croissant 支持,可显著提升数据集被检索和复用的概率。
- 负责使用:通过 RAI 扩展为数据集标注合规属性,帮助组织满足监管与公平性审查需求。
采用 Croissant,工程团队可在 数据开发环节削减 30%+ 的重复工作时间,同时为模型训练提供统一、可审计的输入来源。

