SQL详解之DQL(数据查询语言)
上一节课我们讲解了DML的插入、删除、更新操作,本节课将继续基于「学校选课系统数据库(school)」,详细讲解DQL(Data Query Language,数据查询语言)的使用。DQL的核心作用是从数据库表中获取所需数据,是开发人员、数据分析师最常用的SQL指令,其核心语句为SELECT,搭配不同子句可实现复杂的数据筛选、排序、分组、连接等操作。
温馨提示:执行所有DQL操作前,请先确认已执行「建库建表的DDL语句」和「插入数据的DML语句」,确保表结构和数据完整,再通过以下命令切换到school数据库,避免操作错误。
-- 切换到school数据库(``用于避免关键字冲突,推荐常规使用)USE `school`;
一、DQL基础:简单查询(投影与全量查询)
简单查询主要实现「全量获取数据」或「获取指定字段数据」,核心是SELECT子句(指定查询字段)和FROM子句(指定查询表),是所有复杂查询的基础。
1. 全量查询(查询所有字段、所有记录)
语法:使用「*」表示查询表中所有字段,无需逐一列出,适合快速查看表中所有数据(日常开发不推荐,效率低且易冗余)。
-- 查询所有学生的所有信息(全量查询,* 表示所有字段)SELECT stu_id, stu_name, stu_sex, stu_birth, stu_addr, col_idFROM tb_student;-- 简化写法(不推荐,可读性差,后续修改表结构易出问题)-- SELECT * FROM tb_student;
说明:推荐手动列出所有需要查询的字段,而非使用「*」,既提升查询效率,也能避免获取无用字段,同时增强代码可读性和可维护性。
2. 投影查询(查询指定字段)+ 字段别名
语法:在SELECT后指定需要查询的字段,用「AS」关键字给字段起别名(简化显示,增强可读性),AS可省略。
-- 示例1:查询学生的学号、姓名和籍贯(投影查询),并给字段起中文别名SELECT stu_id AS 学号, stu_name AS 姓名, stu_addr AS 籍贯FROM tb_student;-- 示例2:查询所有课程的名称及学分(投影查询+别名,AS可省略)SELECT cou_name 课程名称, -- 省略AS,直接用空格分隔字段和别名 cou_credit 学分FROM tb_course;
核心注意:字段别名若包含空格、特殊字符(如中文),需用``或''包裹(如 课程 名称),日常推荐用中文别名提升可读性。
二、DQL核心:数据筛选(WHERE子句)
实际场景中,我们很少需要查询全量数据,更多是筛选符合条件的记录,此时需搭配「WHERE子句」指定筛选条件。WHERE子句支持多种运算符,可实现精准筛选、范围筛选、模糊筛选等。
1. 精准筛选(等于、不等于)
使用「=」(等于)、「<>」(不等于)筛选指定条件的记录,常用于按主键、固定值筛选。
-- 示例1:查询所有女学生的姓名和出生日期(stu_sex=0表示女,1表示男)SELECT stu_name, stu_birthFROM tb_studentWHERE stu_sex =0;-- 示例2:查询名字叫“杨过”的学生的姓名和性别(精准匹配姓名)-- 方式1:用CASE流程函数,将性别编码转为中文(推荐,可读性强)SELECT stu_name AS 姓名, CASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别FROM tb_studentWHERE stu_name ='杨过';-- 方式2:用IF流程函数,简化判断(适合简单二元判断)SELECT stu_name AS 姓名, IF(stu_sex, '男', '女') AS 性别 -- stu_sex=1返回男,否则返回女FROM tb_studentWHERE stu_name ='杨过';
2. 多条件筛选(逻辑运算)
使用逻辑运算符「AND」(且)、「OR」(或)、「NOT」(非),组合多个筛选条件,实现更精准的筛选。
-- 示例1:查询籍贯为“四川成都”的女学生的姓名和出生日期(AND 同时满足两个条件)SELECT stu_name, stu_birthFROM tb_studentWHERE stu_sex =0AND stu_addr ='四川成都';-- 示例2:查询籍贯为“四川成都”或者性别是女的学生(OR 满足任一条件)SELECT stu_name, stu_birthFROM tb_studentWHERE stu_sex =0OR stu_addr ='四川成都';-- 示例3:查询不是女学生的姓名(NOT 取反)SELECT stu_nameFROM tb_studentWHERENOT stu_sex =0;
3. 范围筛选(BETWEEN...AND...、>、<、>=、<=)
用于筛选字段值在指定范围内的记录,BETWEEN...AND... 包含边界值,等价于「>= 左边界 AND <= 右边界」。
-- 示例1:查询所有80后学生的姓名、性别和出生日期(日期范围筛选)-- 方式1:用AND组合日期条件SELECT stu_name, stu_sex, stu_birthFROM tb_studentWHERE'1980-1-1'<= stu_birth AND stu_birth <='1989-12-31';-- 方式2:用BETWEEN...AND...(简化写法,推荐)SELECT stu_name, stu_sex, stu_birthFROM tb_studentWHERE stu_birth BETWEEN'1980-1-1'AND'1989-12-31';-- 示例2:查询学分大于2的课程的名称和学分(数值范围筛选)SELECT cou_name, cou_creditFROM tb_courseWHERE cou_credit >2;
4. 特殊筛选(取余、空值处理)
(1)取余筛选(MOD)
使用「MOD(字段, 除数)」获取字段值除以除数的余数,用于筛选奇偶值、特定余数的记录。
-- 查询学分是奇数的课程的名称和学分(MOD(学分,2)<>0 表示余数不为0,即奇数)SELECT cou_name, cou_creditFROM tb_courseWHERE cou_credit MOD 2<>0; -- 等价于 cou_credit % 2 != 0
(2)空值筛选(IS NULL、IS NOT NULL)
SQL中,NULL表示「未录入数据」,不能用「=」「<>」判断,必须用「IS NULL」(是空值)、「IS NOT NULL」(非空值),搭配TRIM()可过滤空字符串。
-- 示例1:查询没有录入籍贯的学生姓名(空值+空字符串)SELECT stu_nameFROM tb_studentWHERETRIM(stu_addr) =''-- 过滤空字符串(如''、' ')OR stu_addr isnull; -- 过滤NULL值(未录入)-- 示例2:查询录入了籍贯的学生姓名(非空值+非空字符串)SELECT stu_nameFROM tb_studentWHERETRIM(stu_addr) <>''AND stu_addr isnot null;
易错提示:切勿写成「stu_addr = null」或「stu_addr <> null」,此类写法不会报错,但永远查询不到结果(NULL与任何值比较都为NULL)。
5. 模糊筛选(LIKE、REGEXP)
用于筛选字段值包含指定字符的记录,适合姓名、地址等模糊匹配场景,常用通配符或正则表达式。
(1)LIKE + 通配符(常用)
支持两个核心通配符:「%」(匹配0个、1个或多个任意字符)、「_」(匹配1个任意字符)。
-- 示例1:查询姓“杨”的学生姓名和性别(% 匹配后面任意字符)SELECT stu_name AS 姓名, CASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别FROM tb_studentWHERE stu_name LIKE'杨%'; -- 杨、杨过、杨不悔都符合-- 示例2:查询姓“杨”名字两个字的学生(_ 匹配1个字符)SELECT stu_name AS 姓名, CASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别FROM tb_studentWHERE stu_name LIKE'杨_'; -- 杨过符合,杨不悔不符合-- 示例3:查询姓“杨”名字三个字的学生(两个_ 匹配2个字符)SELECT stu_name AS 姓名, CASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别FROM tb_studentWHERE stu_name LIKE'杨__'; -- 杨不悔符合,杨过不符合-- 示例4:查询学号最后一位是3的学生的学号和姓名(% 匹配前面任意字符)SELECT stu_id, stu_nameFROM tb_studentWHERE stu_id LIKE'%3'; -- 1033、3923符合-- 示例5:查询名字中有“不”字或“嫣”字的学生(OR 组合模糊条件)SELECT stu_id, stu_nameFROM tb_studentWHERE stu_name LIKE'%不%'OR stu_name LIKE'%嫣%';-- 等价写法:用UNION去重(若有重复记录,UNION会自动去重,UNION ALL不会)SELECT stu_id, stu_nameFROM tb_studentWHERE stu_name LIKE'%不%'UNIONSELECT stu_id, stu_nameFROM tb_studentWHERE stu_name LIKE'%嫣%';
(2)REGEXP + 正则表达式(进阶)
适合复杂的模糊匹配场景(如指定首字符范围、字符长度等),语法更灵活。
-- 查询姓“杨”或姓“林”、名字三个字的学生的学号和姓名SELECT stu_id, stu_nameFROM tb_studentWHERE stu_name REGEXP '[林杨][\\u4e00-\\u9fa5]{2}';-- 解析:[林杨] 表示首字符是林或杨;[\\u4e00-\\u9fa5]{2} 表示后面跟2个中文字符
三、DQL进阶:去重、排序、分页
通过DISTINCT(去重)、ORDER BY(排序)、LIMIT(分页),可对查询结果进行进一步处理,满足实际开发中的展示需求。
1. 去重(DISTINCT)
用于去除查询结果中的重复记录,仅保留唯一记录,需放在SELECT后、字段前。
-- 示例1:查询学生选课的所有日期(去重,避免重复日期)SELECTDISTINCT sel_dateFROM tb_record;-- 示例2:查询学生的籍贯(去重,过滤空值和重复籍贯)SELECTDISTINCT stu_addrFROM tb_studentWHERETRIM(stu_addr) <>''AND stu_addr isnot null;
注意:DISTINCT 作用于所有查询字段,而非单个字段(如SELECT DISTINCT stu_addr, stu_sex 表示“籍贯+性别”组合去重)。
2. 排序(ORDER BY)
用于对查询结果按指定字段排序,核心语法:ORDER BY 字段名 [ASC/DESC],ASC表示升序(默认,可省略),DESC表示降序。
-- 示例1:查询男学生的姓名和生日,按年龄从大到小排列(生日越早,年龄越大)SELECT stu_name, stu_birthFROM tb_studentWHERE stu_sex =1ORDERBY stu_birth ASC; -- ASC升序,stu_birth越小(生日越早),排在前面-- 示例2:补充:将生日换算成年龄,按年龄降序排列(结合日期函数、数值函数)SELECT stu_name AS 姓名,FLOOR(DATEDIFF(CURDATE(), stu_birth) /365) AS 年龄FROM tb_studentWHERE stu_sex =1ORDERBY 年龄 DESC; -- DESC降序,年龄越大,排在前面
说明:可按多个字段排序,用逗号分隔(如 ORDER BY 字段1 ASC, 字段2 DESC),先按字段1排序,字段1相同再按字段2排序。
3. 分页(LIMIT)
用于限制查询结果的条数,适合分页展示数据(如页面显示10条数据),MySQL专属语法,有两种常用写法。
-- 背景:查询学生姓名、课程名称以及成绩(过滤未考核成绩NULL)-- 示例1:取前5条数据(写法1:LIMIT 条数)SELECT stu_name, cou_name, scoreFROM tb_student NATURALJOIN tb_recordNATURALJOIN tb_courseWHERE score isnot nullORDERBY cou_id ASC, score DESC LIMIT 5; -- 仅返回前5条结果-- 示例2:取第6-10条数据(写法2:LIMIT 偏移量, 条数;偏移量从0开始)SELECT stu_name, cou_name, scoreFROM tb_student NATURALJOIN tb_recordNATURALJOIN tb_courseWHERE score isnot nullORDERBY cou_id ASC, score DESC LIMIT 5OFFSET5; -- 偏移量5(跳过前5条),取5条(第6-10条)-- 等价写法(简化,推荐)SELECT stu_name, cou_name, scoreFROM tb_student NATURALJOIN tb_recordNATURALJOIN tb_courseWHERE score isnot nullORDERBY cou_id ASC, score DESC LIMIT 10, 5; -- 第一个数是偏移量,第二个数是条数(与上面效果一致)
易错提示:偏移量 = (页码-1)× 每页条数(如第3页,每页5条,偏移量=10,LIMIT 10,5)。
四、DQL高级:聚合函数与分组查询
聚合函数用于对一组数据进行统计计算(如计数、求和、求平均),常与GROUP BY(分组)搭配使用,实现按指定字段分组统计;搭配HAVING(分组后筛选),可对分组结果进一步筛选。
1. 常用聚合函数
MySQL提供多种聚合函数,核心常用如下(结合示例理解,更易掌握):
-- 示例1:查询年龄最大的学生的出生日期(MIN():求最小值,生日越小,年龄越大)SELECTMIN(stu_birth) AS 年龄最大学生的生日FROM tb_student;-- 示例2:查询年龄最小的学生的出生日期(MAX():求最大值,生日越大,年龄越小)SELECTMAX(stu_birth) AS 年龄最小学生的生日FROM tb_student;-- 示例3:查询编号为1111的课程考试成绩的最高分(MAX():求字段最大值)SELECTMAX(score) AS1111课程最高分FROM tb_recordWHERE cou_id =1111;-- 示例4:查询学号为1001的学生考试成绩的统计信息(多聚合函数组合)SELECTMIN(score) AS 最低分,MAX(score) AS 最高分, ROUND(AVG(score), 1) AS 平均分, -- AVG()求平均,ROUND()保留1位小数 STDDEV(score) AS 标准差, -- STDDEV()求标准差 VARIANCE(score) AS 方差 -- VARIANCE()求方差FROM tb_recordWHERE stu_id =1001;-- 示例5:查询学号为1001的学生考试成绩的平均分(NULL值按0计算)-- 思路:SUM(score)求和,COUNT(*)统计总条数(包含NULL),相除得到平均分SELECT ROUND(SUM(score) /COUNT(*), 1) AS 平均分FROM tb_recordWHERE stu_id =1001;
补充说明:AVG(score) 会自动忽略NULL值,若需将NULL按0计算,需用「SUM(score)/COUNT(*)」替代。
2. 分组查询(GROUP BY)
语法:GROUP BY 分组字段,将查询结果按分组字段的值分组,每组单独使用聚合函数统计,分组字段通常是“类别型”字段(如性别、学院编号)。
-- 示例1:查询男女学生的人数(按stu_sex分组,COUNT(*)统计每组人数)SELECTCASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别,COUNT(*) AS 人数 -- COUNT(*)统计每组的总记录数,包含NULLFROM tb_studentGROUPBY stu_sex; -- 按性别分组(stu_sex=0和stu_sex=1各为一组)-- 示例2:查询每个学院学生人数(按col_id分组,WITH ROLLUP 增加汇总行)SELECT col_id AS 学院编号,COUNT(*) AS 人数FROM tb_studentGROUPBY col_idWITHROLLUP; -- 末尾增加一行,显示所有学院的总人数-- 示例3:查询每个学院男女学生人数(多字段分组:先按学院,再按性别)SELECT col_id AS 学院编号,CASE stu_sex WHEN1THEN'男'ELSE'女'ENDAS 性别,COUNT(*) AS 人数FROM tb_studentGROUPBY col_id, stu_sex; -- 先按col_id分组,每组内再按stu_sex分组-- 示例4:查询每个学生的学号和平均成绩(按stu_id分组,统计每个学生的成绩)SELECT stu_id AS 学号, ROUND(AVG(score), 1) AS 平均分FROM tb_recordGROUPBY stu_id;
3. 分组后筛选(HAVING)
WHERE 用于「分组前筛选记录」,HAVING 用于「分组后筛选分组结果」,HAVING 可使用聚合函数,WHERE 不能。
-- 示例1:查询平均成绩大于等于90分的学生的学号和平均成绩(分组后筛选)SELECT stu_id AS 学号, ROUND(AVG(score), 1) AS 平均分FROM tb_recordGROUPBY stu_idHAVING 平均分 >=90; -- 筛选分组后的结果(平均分>=90),不能用WHERE-- 示例2:查询1111、2222、3333三门课程平均成绩>=90分的学生(分组前后都筛选)SELECT stu_id AS 学号, ROUND(AVG(score), 1) AS 平均分FROM tb_recordWHERE cou_id in (1111, 2222, 3333) -- 分组前:只筛选这三门课程的成绩GROUPBY stu_idHAVING 平均分 >=90-- 分组后:筛选平均分>=90的学生ORDERBY 平均分 ASC;
核心区别:WHERE 筛选的是“原始记录”,HAVING 筛选的是“分组统计结果”;HAVING 可使用聚合函数(如平均分),WHERE 不可。
五、DQL高级:子查询与表连接
实际开发中,单表查询往往无法满足需求,需结合多表数据查询,此时可使用「子查询」(嵌套查询)或「表连接」,两者可实现相同效果,根据场景选择使用。
1. 子查询(嵌套查询)
语法:将一个SELECT查询(子查询)作为另一个SELECT查询的条件或数据源,子查询需用括号包裹,分为“单行子查询”“多行子查询”。
-- 示例1:查询年龄最大的学生的姓名(单行子查询:子查询返回1条结果)SELECT stu_nameFROM tb_studentWHERE stu_birth = (SELECTMIN(stu_birth) -- 子查询:获取年龄最大学生的生日FROM tb_student);-- 示例2:查询选了两门以上课程的学生姓名(多行子查询:子查询返回多条结果)SELECT stu_nameFROM tb_studentWHERE stu_id in (SELECT stu_id -- 子查询:获取选课数>2的学生学号(多条)FROM tb_recordGROUPBY stu_idHAVINGCOUNT(*) >2);-- 易错提示:子查询作为数据源时,必须给子查询起别名(如下示例)-- 查询选课学生的姓名和平均成绩(子查询作为数据源,别名tmp)SELECT stu_name, avg_scoreFROM tb_studentNATURALJOIN (SELECT stu_id, ROUND(AVG(score), 1) AS avg_scoreFROM tb_recordGROUPBY stu_id) as tmp; -- 子查询别名tmp,不可省略-- 错误原因:Every derived table must have its own alias(每个派生表必须有别名)
2. 表连接(多表关联查询)
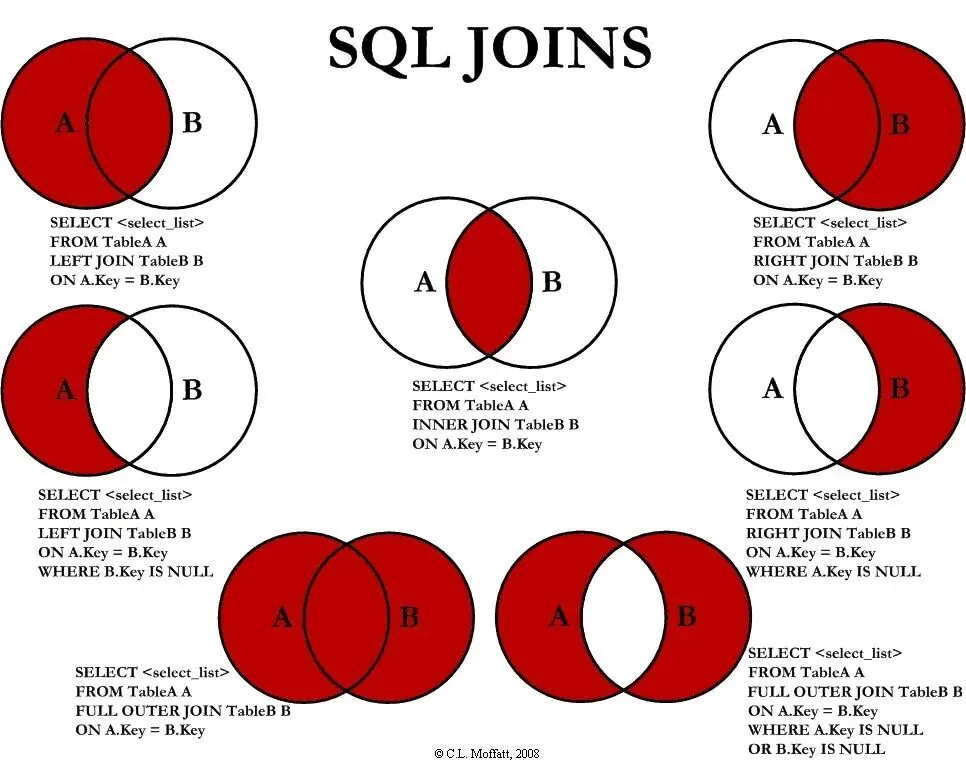
表连接是多表查询的常用方式,核心是通过「关联字段」(如col_id、stu_id、cou_id)将多个表连接起来,获取多表中的关联数据,MySQL支持内连接、左外连接、右外连接,不支持全外连接(可通过UNION模拟)。
(1)内连接(INNER JOIN,默认)
只返回两个表中「关联字段匹配」的记录,不匹配的记录不显示,有三种常用写法。
-- 示例1:查询学生的姓名、生日和所在学院名称(关联tb_student和tb_college)-- 方式1:隐式内连接(逗号分隔表,WHERE指定关联条件,简洁)SELECT stu_name, stu_birth, col_nameFROM tb_student AS t1, tb_college AS t2 -- 表别名t1、t2,简化写法WHERE t1.col_id = t2.col_id; -- 关联条件:学生表和学院表的col_id相等-- 方式2:显式内连接(INNER JOIN,推荐,可读性强)SELECT stu_name, stu_birth, col_nameFROM tb_student INNERJOIN tb_collegeON tb_student.col_id = tb_college.col_id; -- ON指定关联条件-- 方式3:自然内连接(NATURAL JOIN,自动匹配同名字段作为关联条件)SELECT stu_name, stu_birth, col_nameFROM tb_student NATURALJOIN tb_college; -- 自动匹配col_id字段
(2)多表内连接(三个及以上表)
通过多个关联条件,连接三个及以上表,获取多表关联数据。
-- 示例:查询学生姓名、课程名称以及成绩(关联三个表,过滤未考核成绩)-- 方式1:隐式内连接SELECT stu_name, cou_name, scoreFROM tb_student, tb_course, tb_recordWHERE tb_student.stu_id = tb_record.stu_id -- 学生表与选课表关联AND tb_course.cou_id = tb_record.cou_id -- 课程表与选课表关联AND score isnot null; -- 筛选已考核成绩-- 方式2:显式内连接(推荐)SELECT stu_name, cou_name, scoreFROM tb_student INNERJOIN tb_recordON tb_student.stu_id = tb_record.stu_idINNERJOIN tb_courseON tb_course.cou_id = tb_record.cou_idWHERE score isnot null;
(3)左外连接(LEFT JOIN)
返回左表(LEFT JOIN 左边的表)的「所有记录」,右表只返回关联匹配的记录,右表无匹配记录时,显示NULL。
-- 示例:查询每个学生的姓名和选课数量(即使未选课,也显示学生信息,选课数量为0)SELECT stu_name AS 姓名,COALESCE(total, 0) AS 选课数量 -- COALESCE:若total为NULL,返回0FROM tb_student AS t1 -- 左表:学生表(返回所有学生)LEFTJOIN (SELECT stu_id,COUNT(*) AS totalFROM tb_recordGROUPBY stu_id) AS t2 -- 右表:学生选课统计ON t1.stu_id = t2.stu_id; -- 关联条件:学生学号
说明:COALESCE函数用于处理NULL值,避免查询结果中出现NULL(此处将未选课学生的选课数量从NULL改为0,更易读)。
(4)全外连接(MySQL不支持,模拟实现)
MySQL目前不支持全外连接(FULL JOIN),可通过「左外连接 UNION 右外连接」的方式模拟,返回两个表的所有记录,匹配的显示关联数据,不匹配的显示NULL。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
