Python数据分析:可视化帕默群岛企鹅数据项目实战
🐧 数据分析报告:探索企鹅的身高体重与物种、性别、岛屿的关系
大家好!今天我将带大家完成一个经典的数据分析案例——帕默群岛企鹅数据集的可视化分析。我们将使用 Python 的 pandas、matplotlib 和 seaborn 库,从数据清洗到多维度可视化,一步步揭示这些可爱企鹅的秘密。
🎯 分析目标
本次分析的目的是通过对帕默群岛上企鹅样本的相关变量进行可视化,探索种类、性别、所在岛屿等因素与企鹅身体属性(体重、嘴峰长度和深度、鳍长度)之间的关系。
📁 简介
原始数据 Penguins.csv 包含 334 个收集自南极洲帕尔默群岛 3 个岛屿上的企鹅样本,以及以下属性:
species:企鹅的种类(Adelie, Chinstrap, Gentoo)island:企鹅所在岛(Biscoe, Dream, Torgersen)culmen_length_mm:企鹅嘴峰的长度(毫米)culmen_depth_mm:企鹅嘴峰的深度(毫米)flipper_length_mm:企鹅鳍的长度(毫米)
📥 读取数据
首先导入必要的库,并用 pandas.read_csv() 读取数据。
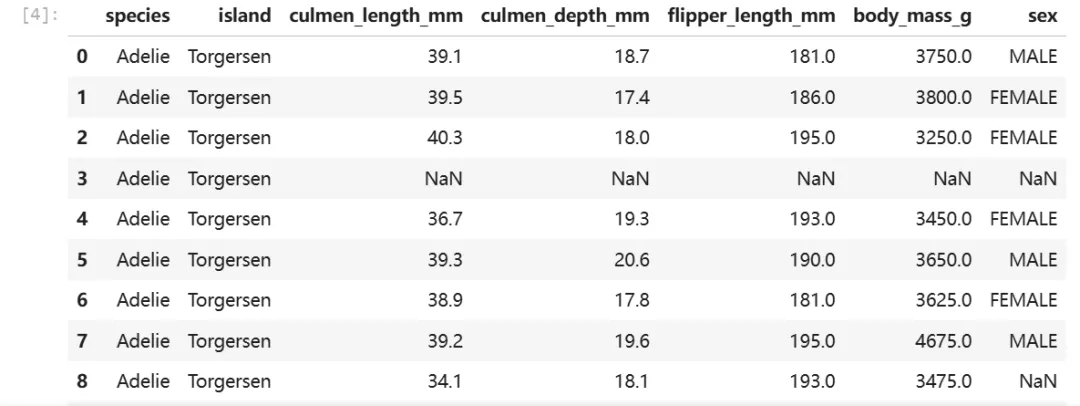
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsoriginal_data = pd.read_csv("Penguins.csv")original_data.head()
输出显示了前 5 行数据,可以看到有缺失值存在(NaN)。
🔍 评估和清理数据
创建一个副本用于数据清洗,保持原始数据不变。
cleaned_data = original_data.copy()
数据整齐度
检查数据结构是否符合“每个变量为一列,每个观察值为一行”的标准。
cleaned_data.head(10)
输出显示数据基本整齐,没有结构性错误。
数据干净度
使用 info() 查看各列的非空计数和数据类型。
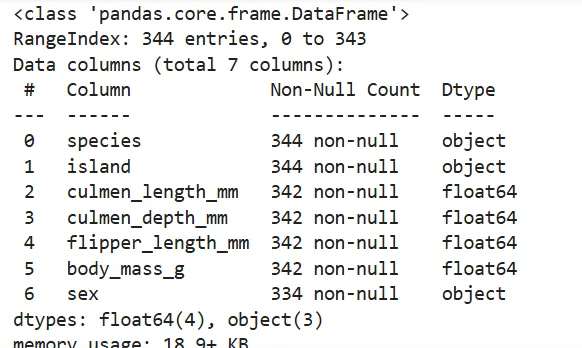
cleaned_data.info()
输出显示:
culmen_length_mm、culmen_depth_mm、flipper_length_mm、body_mass_g 各缺失 2 条。
接着将分类变量转换为 category 类型:
cleaned_data['species'] = cleaned_data['species'].astype("category")cleaned_data['sex'] = cleaned_data['sex'].astype("category")cleaned_data['island'] = cleaned_data['island'].astype("category")cleaned_data.info()
现在类型正确,内存占用也减少了。
🧹 处理缺失数据
我们先查看哪些行有缺失值。
cleaned_data.query("culmen_length_mm.isna()")
cleaned_data.query("culmen_depth_mm.isna()")
cleaned_data.query("flipper_length_mm.isna()")
cleaned_data.query("body_mass_g.isna()")
这几条查询都指向索引 3 和 339 的两行,它们除了种类和岛屿外其他所有字段都为空,无法用于分析,直接删除。
cleaned_data.drop(3, inplace=True)cleaned_data.drop(339, inplace=True)
接着查看缺失性别的行:
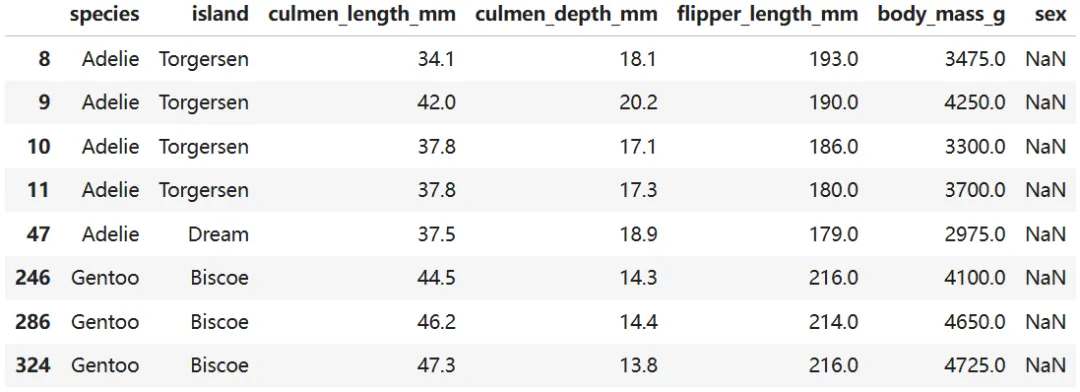
cleaned_data.query("sex.isna()")
有 8 行缺失性别,但其他属性完整,可以保留,因为后续可视化会自动忽略缺失值。
🔁 处理重复数据
根据变量含义,允许重复值存在,因此不进行去重。
✏️ 处理不一致数据
检查分类列中是否有不同值实际指代同一目标的情况。
cleaned_data["species"].value_counts()
speciesAdelie 151Gentoo 123Chinstrap 68
cleaned_data["island"].value_counts()
islandBiscoe 167Dream 124Torgersen 51
cleaned_data["sex"].value_counts()
sexMALE 168FEMALE 165. 1
发现 sex 列中有一个英文句号 .,应替换为 NaN。
cleaned_data['sex'] = cleaned_data['sex'].replace(".", np.nan)cleaned_data["sex"].value_counts()
sexMALE 168FEMALE 165
处理完成。
📊 处理无效或错误数据
使用 describe() 查看数值列的统计信息,检查是否有异常值。
cleaned_data.describe()
所有数值都在合理范围内,没有明显的错误数据。
📈 探索数据
下面开始可视化探索,首先设置图表色盘。
sns.set_palette("pastel")
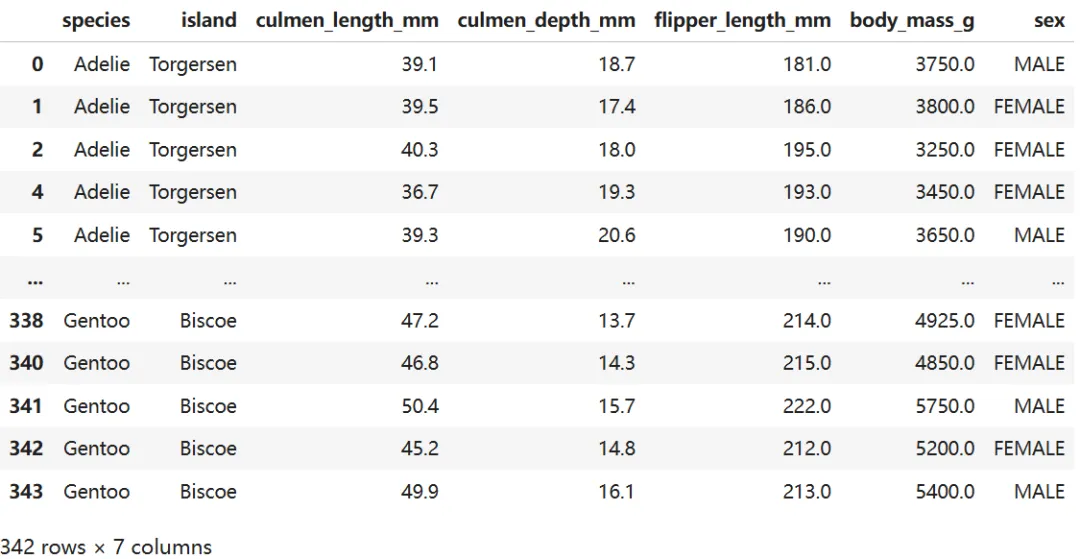
查看清理后的数据概览:
cleaned_data
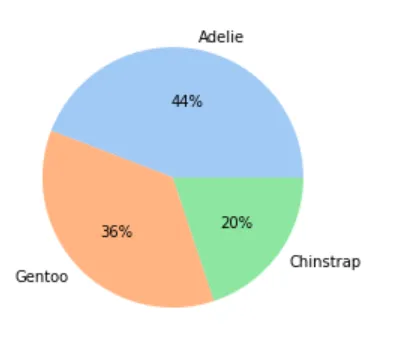
1️⃣ 企鹅种类比例
species_count = cleaned_data["species"].value_counts()plt.pie(species_count, autopct='%.0f%%', labels=species_count.index)plt.show()
从饼图可以看出,样本中 Adelie 种类占比最大(44%),Gentoo 次之(36%),Chinstrap 最小(20%)。
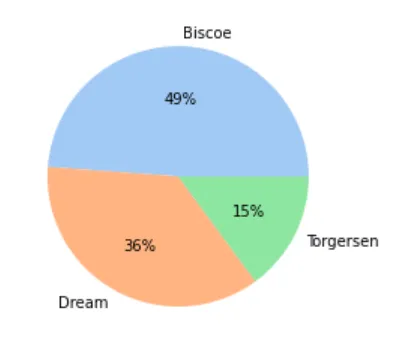
2️⃣ 企鹅所属岛屿比例
island_count = cleaned_data["island"].value_counts()plt.pie(island_count, autopct='%.0f%%', labels=island_count.index)plt.show()
约一半的样本来自 Biscoe 岛,其次是 Dream 岛,Torgersen 岛最少。
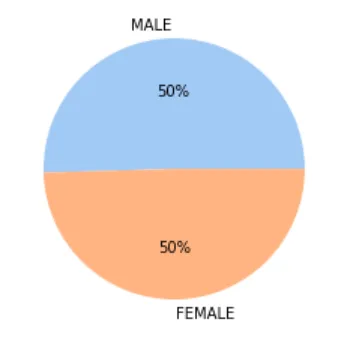
3️⃣ 企鹅性别比例
sex_count = cleaned_data['sex'].value_counts()plt.pie(sex_count, labels=sex_count.index, autopct='%.0f%%')plt.show()
性别比例接近 1:1,符合随机抽样。
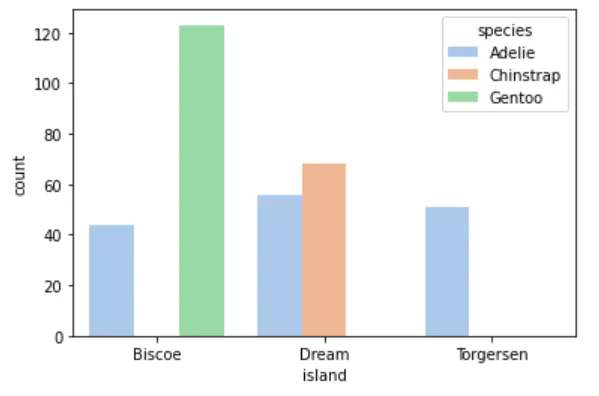
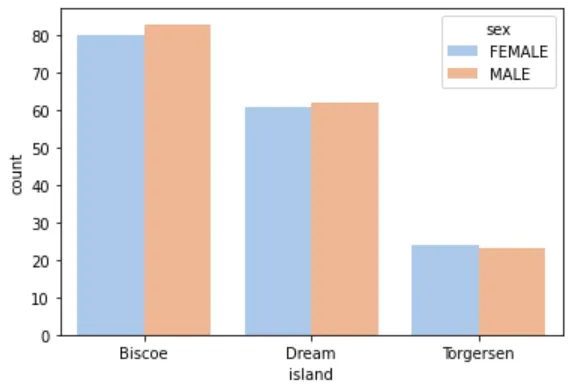
4️⃣ 不同岛上的企鹅种类数量
sns.countplot(cleaned_data, x="island", hue="species")plt.show()
观察可知:
5️⃣ 不同岛屿上的企鹅性别数量
sns.countplot(cleaned_data, x='island', hue='sex')plt.show()
各岛屿上男女比例大致均衡,Dream 岛雄性略多。
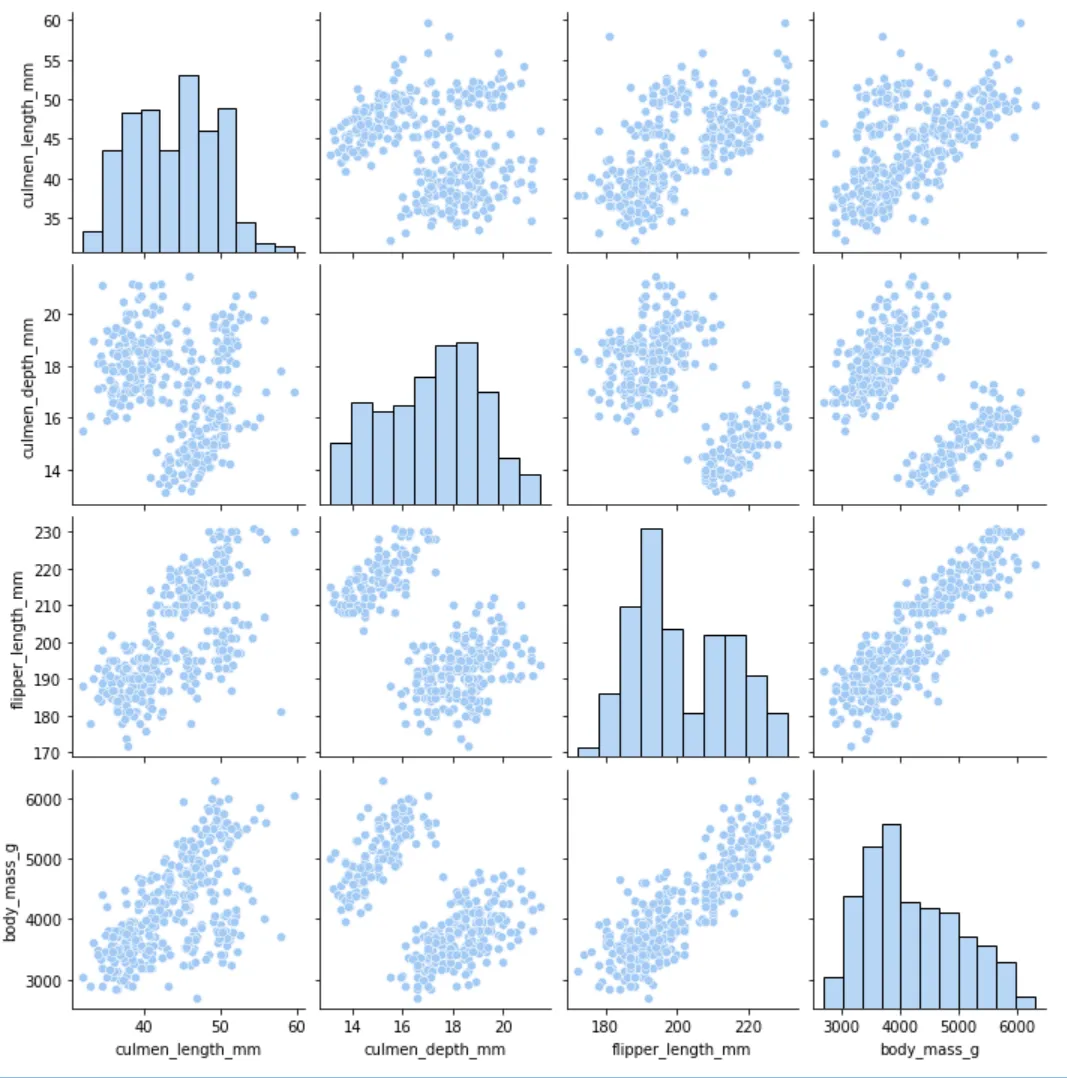
6️⃣ 查看数值之间的相关关系(整体)
sns.pairplot(cleaned_data)plt.show()
从直方图看,各属性分布不是正态的,可能存在多组差异数据;散点图中可以看到明显的集群。
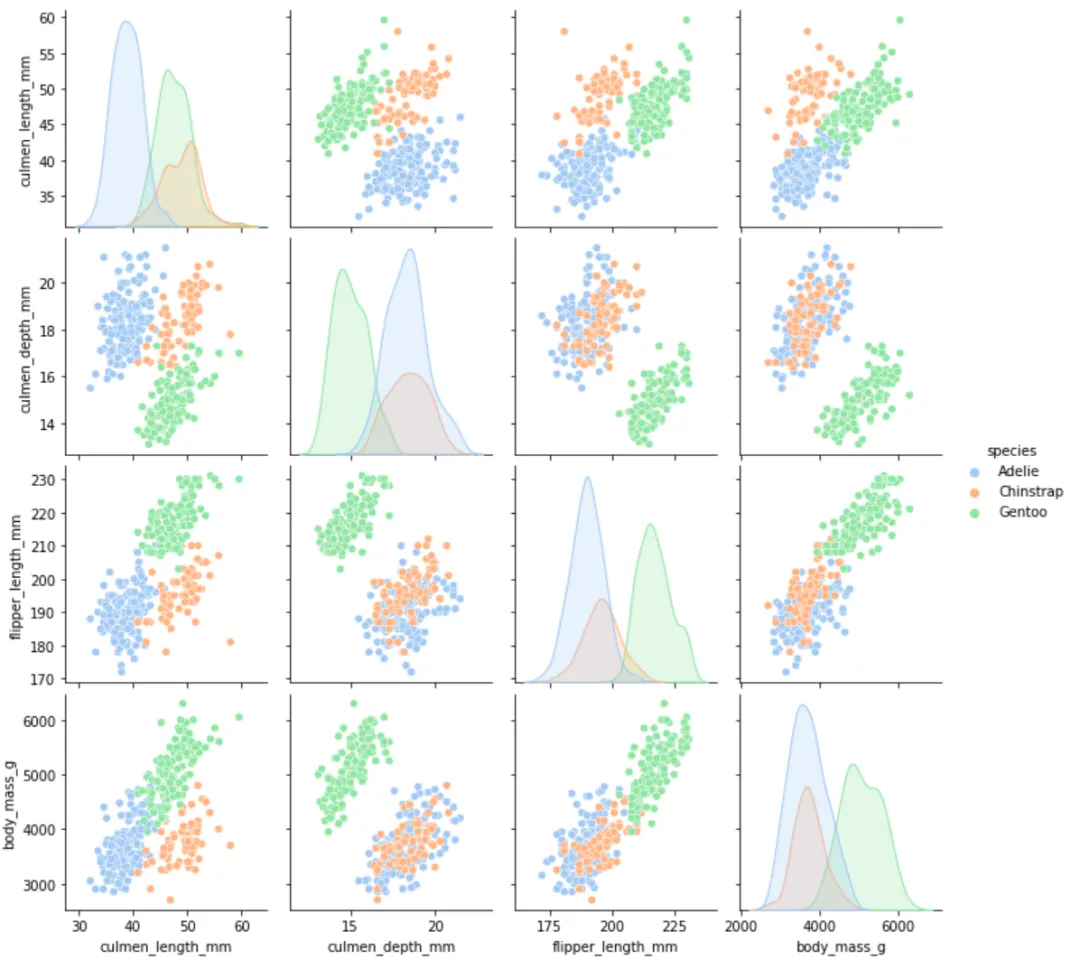
7️⃣ 根据种类查看数值之间的相关关系
sns.pairplot(cleaned_data, hue='species')plt.show()
不同种类的企鹅在散点图上聚集成不同的簇,说明种类与身体属性有强关联。
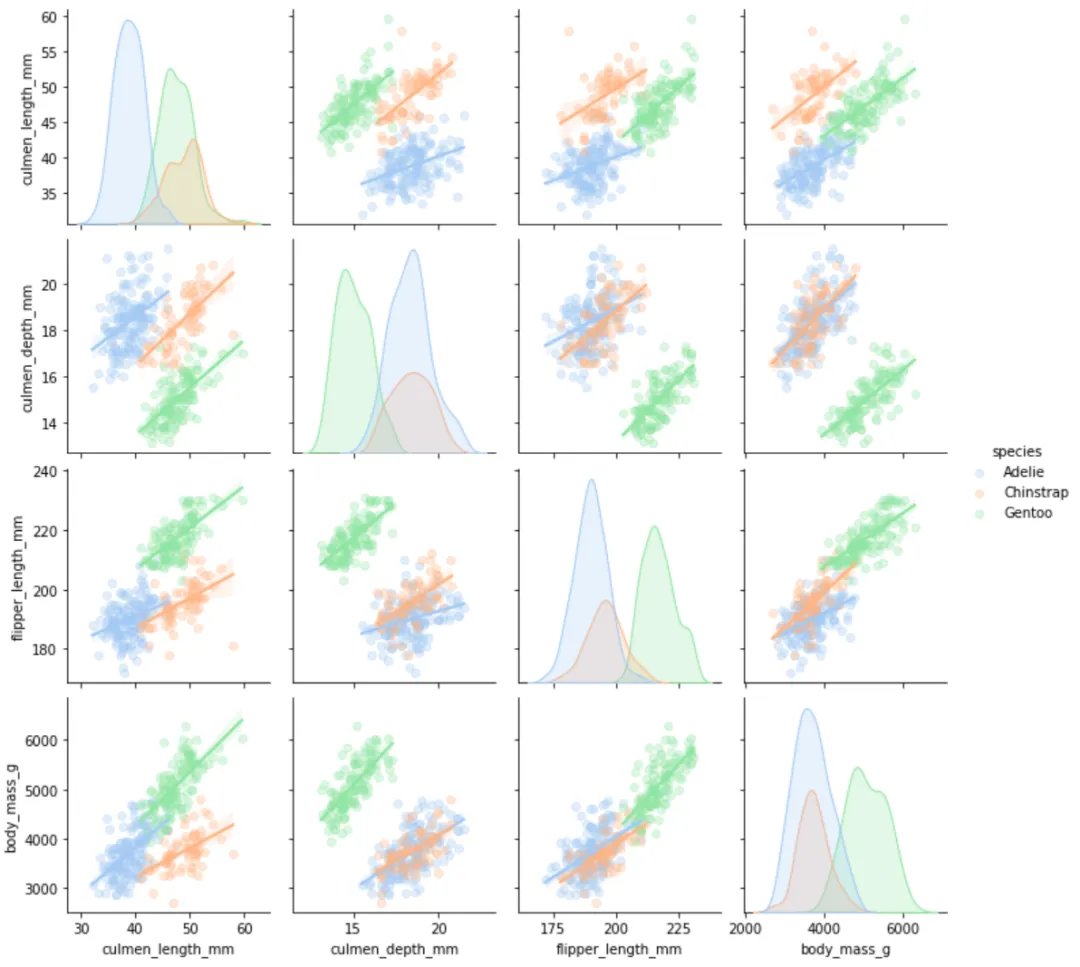
8️⃣ 添加回归线的种类间关系
sns.pairplot(cleaned_data, hue='species', kind='reg', plot_kws={'scatter_kws': {'alpha': 0.3}})plt.show()
同类企鹅的属性之间呈线性正比关系(嘴峰越长 → 嘴峰越深 → 鳍越长 → 体重越重)。
从密度图还可以发现:
- Adelie 嘴峰长度最短,Chinstrap 和 Gentoo 较长;
- Gentoo 嘴峰深度最短,Adelie 和 Chinstrap 较深;
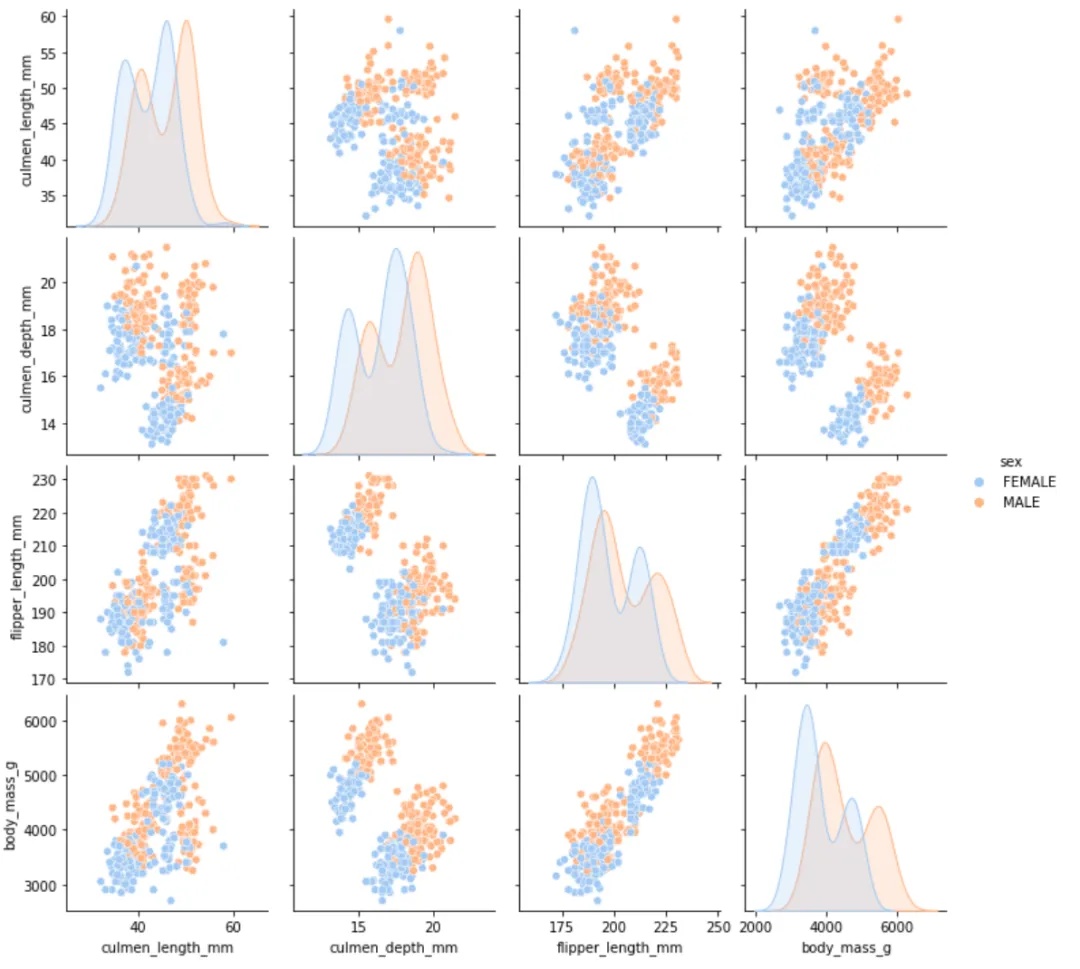
9️⃣ 根据性别查看数值之间的相关关系
sns.pairplot(cleaned_data, hue='sex')plt.show()
雄性企鹅在各项属性数值上普遍大于雌性。
📝 总结
通过本次可视化分析,我们清晰地看到了:
如果你也对数据可视化感兴趣,欢迎关注我的公众号,后续会分享更多数据分析实战案例!
❝💡 完整代码及数据可在公众号后台回复「帕默群岛企鹅数据」获取。