Python遥感实战:基于多个自变量的岭回归分析
- 2026-07-02 01:06:07
Python遥感实战:基于多个自变量的岭回归分析
1.岭回归基本原理 在遥感地学领域中,地表参数往往受到多个因子的共同影响。这些环境因子之间通常存在高度的线性相关性(即多重共线性),导致传统的普通最小二乘法(OLS)在求解回归系数时变得极其不稳定,甚至出现物理意义解释不通的情况。 岭回归通过引入一个扰动项 λI(也称为岭参数或正则化参数)来改良回归估计。其数学表达形式为: 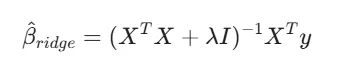
针对岭回归在像元尺度的计算流程如下: 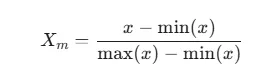
2.数据集要求 对于多变量岭回归,我们必须确定我们的一个因变量和多个自变量,现在我们有 所有变量 Vars 文件夹: 
其中,上面的文件夹包括因变量(ALT,GPP_T等)和 自变量 SOT,其中每个文件夹下面包括以变量名+年份的多张TIF影像,每张影像的维度和空间参考信息一致,例如下面SOT文件夹: 
3.岭回归代码 下面是核心代码(后附实战演示): 下面是代码实战演示: 3.1 导入库 3.2 确定变量文件夹 要求每个文件夹都是以对应自变量命名: 
3.3 建立模型 3.4 岭回归结果-回归模型参数 Mean_Coef (平均回归系数);Mean_SE (平均标准误差);Mean_P_Value (平均 P 值);Mean_Rel_Contrib (平均相对贡献率);Mean_Abs_Contrib (平均绝对贡献量) 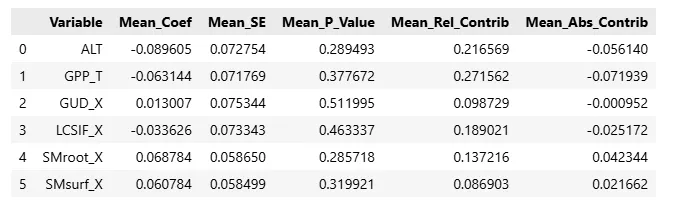
3.4 岭回归结果-可视化 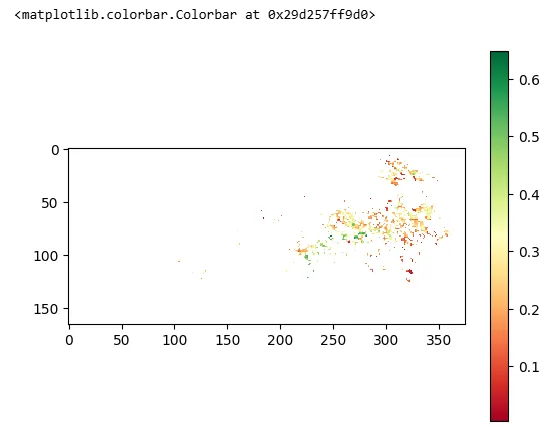
由于该代码要求只对所有年份像元都有有效值的区域进行回归,因此会有大部分像元是无效值 3.5 岭回归结果输出 所有结果都被保存在一个文件夹中: 
注:上述代码已经全部打包,后期会将集成公众号更多数据分析代码和可视化代码进行整理并进一步更新打包!
📒 点赞👍 关注 ❤️ 不迷路哦~
🌍 在遥感地学分析的实际应用中,探究环境因子对生态系统指标(如蒸散发、植被指数等)的贡献量时,往往面临多因子共线性干扰、像元尺度计算量大以及物理意义难以定量表达等挑战。
✅ 本文介绍一套基于 Python 的完整岭回归(Ridge Regression)地学分析工作流:首先对多源遥感变量(如降水、气温、植被指数等)进行像元尺度的归一化处理,消除量级差异;接着利用岭回归系数结合时间序列趋势分析,定量分解各因子的相对贡献率与绝对贡献量;最后实现结果的批量空间可视化输出。
👇 该方法实现了从数据预处理、模型参数寻优到贡献量制图的全流程自动化,代码结构清晰,能够为解释区域环境变化驱动机制提供科学支撑。
完整可复制代码Ridge_Regression_Code.zip
点击关注上方“翔的学术日记”,选择加"星标"置顶重磅干货,第一时间送达
1. 数据归一化 (Normalization):由于不同因子的单位不同(如降水的 mm 和气温的 °C),在回归前必须进行像元尺度的归一化处理:
2. 趋势计算 (Trend Calculation): 代码中利用一元线性回归分别计算归一化后的自变量趋势 X_s_trend 和因变量趋势 Y_n_trend,以及原始因变量的实际趋势 Y_trend
3. 贡献量量化 (Contribution Analysis):
贡献分量 (n_c):计算为回归系数 a 与因子归一化趋势 X_s_trend 的乘积。它代表了单个因子对因变量变化倾向的拉动力度。
相对贡献 (n_rc):反映该因子在所有影响因子中的贡献占比。
绝对贡献 (n_ac):将归一化空间中的贡献还原回具有物理单位的实际趋势中
# -*- coding: utf-8 -*-# Packagesimport osimport reimport numpy as npimport rasterioimport pandas as pdfrom scipy import statsclass RidgeTrend(object):"""Ridge Regression for Remote Sensing with Absolute and Relative Contribution analysis.This class performs pixel-wise regression and exports results to GeoTIFF format."""def __init__(self, data_dir, nodata=-99999):"""Initialize the RidgeTrend tool.:param data_dir: Directory containing subfolders for each variable.:param nodata: Value used for masking and output NoData."""self.data_dir = data_dirself.nodata = nodataself.profile = Nonedef _load_var_stack(self, var_path, pattern=r'\d{4}'):"""Internal helper to load temporal TIF stacks into a 3D numpy array (T, H, W)."""files = sorted([f for f in os.listdir(var_path) if f.endswith(".tif")],key=lambda x: int(re.findall(r"\d+", re.search(pattern, x).group())[0]))stack = []for f in files:with rasterio.open(os.path.join(var_path, f)) as src:arr = src.read(1).astype(float)if src.nodata is not None:arr[arr == src.nodata] = np.nanstack.append(arr)if self.profile is None:# Save profile from the first file to use for output GeoTIFFsself.profile = src.profile.copy()return np.stack(stack)def _calculate_trend(self, data_1d):"""Calculates the linear slope (trend) of a 1D time series."""y = data_1d.flatten()x = np.arange(len(y))mask = ~np.isnan(y)if np.sum(mask) < 2: return 0slope, _, _, _, _ = stats.linregress(x[mask], y[mask])return slopedef _normalize(self, data_1d):"""Min-Max Normalization: Xm = (x - min) / (max - min)."""d_min, d_max = np.nanmin(data_1d), np.nanmax(data_1d)if d_max == d_min: return np.zeros_like(data_1d)return (data_1d - d_min) / (d_max - d_min)def RR(self, y_var_name, pattern=r'\d{4}', k_best=2):"""Main Ridge Regression function.:param y_var_name: Folder name of the dependent variable (e.g., 'ET').:param k_best: Regularization parameter (Lambda).:return: Dictionary containing 'summary' (DataFrame) and 'maps' (2D Arrays)."""......def save_results_to_tif(self, results, output_dir):"""Exports all result maps to GeoTIFF and summary to CSV."""if not os.path.exists(output_dir):os.makedirs(output_dir)# Update metadata profile for outputout_profile = self.profile.copy()out_profile.update({"driver": "GTiff","dtype": 'float32',"count": 1,"nodata": self.nodata})# Save each mapfor name, data in results['maps'].items():out_path = os.path.join(output_dir, f"{name}.tif")out_data = data.astype(np.float32)out_data[np.isnan(out_data)] = self.nodatawith rasterio.open(out_path, "w", **out_profile) as dst:dst.write(out_data, 1)# Save summary tableresults['summary'].to_csv(os.path.join(output_dir, "summary.csv"), index=False)print(f"Results successfully saved to {output_dir}")
import numpy as npimport matplotlib.pyplot as pltimport geosis.rdr as rdr
data_dir = r'E:\公众号\岭回归\data\vars'# 创建数据集:data_dir 是所有变量文件夹的上一级文件夹inst = rdr.RidgeTrend(data_dir)# y_var_name 指的是因变脸名称,pattern 指的是每个变量中# 变量名称和时间名称的关系(例如‘\d{4}’代表变量名+年份# k_best 是岭回归正则化参数(需通过交叉验证等方法确定最优值)RidgeRe = inst.RR(y_var_name = 'SOT', pattern=r'\d{4}', k_best=2)
RidgeRe.get('summary')maps = RidgeRe.get('maps')# 可视化im = plt.imshow(maps['r2'], cmap='RdYlGn')plt.colorbar(im)
inst.save_results_to_tif(RidgeRe, output_dir=r'E:\公众号\岭回归\Result')请在微信客户端打开
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 黄仁勋炸场发言:干嘛还学 Python?未来最牛的编程语言,竟是她!
- Python脚本自动分析INCA的MF4和DAT文件-汽车标定-诊断监控功能鲁棒性分析
- Python_变量
- 我是真的发现,学好Python不难!
- 学C++信奥和学Python人工智能,到底能不能“无缝切换”?抓住“可迁移能力”这颗定心丸!
- 假期太闲搭建了一个python自动化办公学习库,开工直接惊呆了同事
- 入门了Python,却卡在进阶的瓶颈?这个13k star的免费开源项目值得你一刷
- 别死记!Python 函数这样分类超清晰
- Python数据分析可视化:一眼看穿数据分布的“箱线图”全指南(附可运行代码)
- 学生作品(五):基于Python和Streamlit的英语听力精听系统
