用 Python 实现语音识别(把语音转文字)和语音合成(把文字转语音)的功能,提供一套简单、易用且不需要复杂配置的完整实现方案。
实现思路
我会使用两个成熟且易用的 Python 库:
- SpeechRecognition:用于语音识别,支持麦克风实时录音识别和音频文件识别,底层对接 Google 语音识别接口(无需翻墙也能基础使用)。
- pyttsx3:用于离线语音合成,无需联网,直接将文字转为语音播放,支持调整语速、音量、音色。
第一步:安装依赖库
首先打开终端/命令行,执行以下命令安装所需库(注意:Windows/macOS/Linux 通用,Linux 需额外安装依赖):
# 安装核心库
pip install SpeechRecognition pyttsx3
# Linux 系统需额外安装(音频驱动依赖)
# sudo apt-get install portaudio19-dev python3-pyaudio
# macOS 系统需额外安装
# brew install portaudio
# pip install pyaudio
# Windows 系统如果安装 pyaudio 失败,可安装预编译包
# pip install pipwin
# pipwin install pyaudio
第二步:完整实现代码
以下代码包含 语音识别(麦克风录音) 和 语音合成(文字转语音) 两个核心功能,可直接复制运行:
import speech_recognition as sr
import pyttsx3
# ---------------------- 初始化语音合成引擎 ----------------------
engine = pyttsx3.init()
# 可选:配置语音合成参数(可根据需求调整)
# 1. 调整语速(范围:0-200,默认200)
engine.setProperty('rate', 150)
# 2. 调整音量(范围:0.0-1.0,默认1.0)
engine.setProperty('volume', 0.8)
# 3. 选择音色(0=男声,1=女声,不同系统可能有差异)
voices = engine.getProperty('voices')
if len(voices) > 1:
engine.setProperty('voice', voices[1].id) # 切换为女声
# ---------------------- 语音合成函数(文字转语音) ----------------------
deftext_to_speech(text):
"""
将文字转为语音并播放
:param text: 要合成的文字内容
"""
ifnot text:
print("错误:合成的文字不能为空!")
return
print(f"正在合成语音:{text}")
engine.say(text)
engine.runAndWait() # 等待语音播放完成
# ---------------------- 语音识别函数(麦克风录音转文字) ----------------------
defspeech_to_text():
"""
通过麦克风录音,将语音转为文字
:return: 识别出的文字(失败返回空字符串)
"""
# 初始化识别器
recognizer = sr.Recognizer()
# 使用系统默认麦克风作为音频源
with sr.Microphone() as source:
print("\n请开始说话(说完后会自动识别)...")
# 调整环境噪音(关键:避免噪音干扰识别)
recognizer.adjust_for_ambient_noise(source, duration=0.5)
# 录制音频
audio = recognizer.listen(source)
try:
print("正在识别语音...")
# 使用 Google 语音识别(中文)
text = recognizer.recognize_google(audio, language='zh-CN')
print(f"识别结果:{text}")
return text
except sr.UnknownValueError:
print("错误:无法识别语音(可能是口音/噪音问题)")
return""
except sr.RequestError as e:
print(f"错误:语音识别服务不可用 → {e}")
return""
# ---------------------- 主函数(测试功能) ----------------------
if __name__ == "__main__":
print("===== Python 语音识别与合成 =====")
# 1. 测试语音识别
recognized_text = speech_to_text()
# 2. 如果识别成功,将结果合成语音播放
if recognized_text:
print("\n--- 开始播放识别结果 ---")
text_to_speech(f"你说的是:{recognized_text}")
# 3. 额外测试:自定义文字合成
print("\n--- 测试自定义文字合成 ---")
text_to_speech("欢迎使用 Python 语音识别与合成功能!")
代码关键部分解释
engine.init():初始化离线语音引擎,无需联网。setProperty():可调整语速、音量、音色,适配不同需求。engine.say() + engine.runAndWait():核心合成逻辑,前者添加要朗读的文字,后者执行播放。
sr.Microphone():调用系统麦克风,作为音频输入源。adjust_for_ambient_noise():校准环境噪音,提升识别准确率。recognize_google():调用 Google 免费语音识别接口,language='zh-CN' 指定中文识别。
运行效果
- 运行代码后,控制台提示“请开始说话”,此时对着麦克风说话(比如“你好”)。
- 程序会将识别结果合成语音播放(比如“你说的是:你好”)。
- 最后播放自定义文字“欢迎使用 Python 语音识别与合成功能!”。
常见问题解决
- Windows 安装 pyaudio 失败:使用
pipwin install pyaudio 安装预编译包。 - 语音识别准确率低:尽量在安静环境下测试,说话清晰,
adjust_for_ambient_noise() 的 duration 可调整为 1 秒。 - 语音合成无声音:检查系统音量,或切换音色(
voices[0] 换 voices[1])。
总结
- 核心库:语音识别用
SpeechRecognition(依赖 Google 接口),语音合成用 pyttsx3(离线),无需复杂配置即可使用。 - 关键优化:语音识别前调用
adjust_for_ambient_noise() 校准噪音,能大幅提升识别准确率。 - 使用场景:该方案适合基础的语音交互场景(如语音助手、简单语音控制),如需更高准确率/定制化,可替换为百度/阿里/讯飞的语音 API(需申请开发者密钥)。
tkinter 把之前的语音识别与合成功能改造成带图形界面的程序,包含开始录音、开始识别、开始合成、文本输入框、预览播放等交互功能,我会为你提供一个完整、美观且易用的 GUI 版本实现。
实现思路
- 基于 tkinter 构建图形界面,划分功能区:录音识别区、文本合成区、状态提示区。
- 保留核心的
SpeechRecognition 和 pyttsx3 功能,将命令行交互改为按钮点击交互。 - 处理 GUI 线程问题:录音识别是耗时操作,需用
threading 避免界面卡死;语音合成需保证播放不阻塞界面。
完整 GUI 代码
import tkinter as tk
from tkinter import ttk, scrolledtext, messagebox
import speech_recognition as sr
import pyttsx3
import threading
# 初始化语音合成引擎(全局)
engine = pyttsx3.init()
# 配置合成参数
engine.setProperty('rate', 150) # 语速
engine.setProperty('volume', 0.8) # 音量
voices = engine.getProperty('voices')
if len(voices) > 1:
engine.setProperty('voice', voices[1].id) # 女声
classVoiceAssistantGUI:
def__init__(self, root):
self.root = root
self.root.title("Python 语音识别与合成助手")
self.root.geometry("600x450") # 窗口大小
self.root.resizable(False, False) # 禁止缩放
# 识别结果存储
self.recognized_text = ""
# 创建界面组件
self.create_widgets()
defcreate_widgets(self):
# ========== 1. 录音识别区域 ==========
frame_recognize = ttk.LabelFrame(self.root, text="语音识别(麦克风)", padding=10)
frame_recognize.pack(fill=tk.X, padx=20, pady=10)
# 开始录音按钮
self.btn_record = ttk.Button(
frame_recognize,
text="开始录音识别",
command=self.start_recognition_thread,
width=20
)
self.btn_record.grid(row=0, column=0, padx=5, pady=5)
# 识别状态标签
self.label_status = ttk.Label(frame_recognize, text="状态:就绪", foreground="black")
self.label_status.grid(row=0, column=1, padx=5, pady=5)
# 识别结果文本框
ttk.Label(frame_recognize, text="识别结果:").grid(row=1, column=0, sticky=tk.W, padx=5, pady=5)
self.text_recognized = scrolledtext.ScrolledText(
frame_recognize,
width=70,
height=5,
wrap=tk.WORD
)
self.text_recognized.grid(row=2, column=0, columnspan=2, padx=5, pady=5)
# ========== 2. 文本合成区域 ==========
frame_synthesize = ttk.LabelFrame(self.root, text="语音合成(文字转语音)", padding=10)
frame_synthesize.pack(fill=tk.X, padx=20, pady=10)
# 合成文本输入框
ttk.Label(frame_synthesize, text="输入合成文本:").grid(row=0, column=0, sticky=tk.W, padx=5, pady=5)
self.text_synthesize = scrolledtext.ScrolledText(
frame_synthesize,
width=70,
height=5,
wrap=tk.WORD
)
self.text_synthesize.grid(row=1, column=0, columnspan=3, padx=5, pady=5)
# 按钮组:预览播放、合成、清空
self.btn_play = ttk.Button(
frame_synthesize,
text="预览播放",
command=self.play_synthesized_voice,
width=15
)
self.btn_play.grid(row=2, column=0, padx=5, pady=5)
self.btn_synthesize = ttk.Button(
frame_synthesize,
text="使用识别结果合成",
command=self.use_recognized_text,
width=15
)
self.btn_synthesize.grid(row=2, column=1, padx=5, pady=5)
self.btn_clear = ttk.Button(
frame_synthesize,
text="清空文本",
command=self.clear_text,
width=15
)
self.btn_clear.grid(row=2, column=2, padx=5, pady=5)
defstart_recognition_thread(self):
"""启动录音识别线程(避免界面卡死)"""
# 禁用按钮,防止重复点击
self.btn_record.config(state=tk.DISABLED)
self.label_status.config(text="状态:正在录音,请说话...", foreground="blue")
# 启动线程执行识别
thread = threading.Thread(target=self.speech_to_text)
thread.daemon = True# 守护线程,关闭窗口时自动退出
thread.start()
defspeech_to_text(self):
"""语音识别核心逻辑(线程内执行)"""
recognizer = sr.Recognizer()
try:
with sr.Microphone() as source:
recognizer.adjust_for_ambient_noise(source, duration=0.5)
audio = recognizer.listen(source)
# 识别语音
self.label_status.config(text="状态:正在识别...", foreground="orange")
self.recognized_text = recognizer.recognize_google(audio, language='zh-CN')
# 更新界面(识别成功)
self.root.after(0, self.update_recognized_text)
self.label_status.config(text="状态:识别完成", foreground="green")
except sr.UnknownValueError:
self.root.after(0, lambda: messagebox.showwarning("警告", "无法识别语音(请确保环境安静、发音清晰)"))
self.label_status.config(text="状态:识别失败(语音无法识别)", foreground="red")
except sr.RequestError as e:
self.root.after(0, lambda: messagebox.showerror("错误", f"识别服务不可用:{e}"))
self.label_status.config(text="状态:识别失败(服务异常)", foreground="red")
finally:
# 恢复按钮可用
self.root.after(0, lambda: self.btn_record.config(state=tk.NORMAL))
defupdate_recognized_text(self):
"""更新识别结果到文本框"""
self.text_recognized.delete(1.0, tk.END) # 清空原有内容
self.text_recognized.insert(tk.END, self.recognized_text)
defplay_synthesized_voice(self):
"""预览播放输入框中的文本"""
text = self.text_synthesize.get(1.0, tk.END).strip()
ifnot text:
messagebox.showwarning("警告", "请先输入要合成的文本!")
return
# 启动线程播放,避免界面卡死
thread = threading.Thread(target=self.text_to_speech, args=(text,))
thread.daemon = True
thread.start()
defuse_recognized_text(self):
"""将识别结果填入合成文本框"""
ifnot self.recognized_text:
messagebox.showwarning("警告", "暂无识别结果,请先完成语音识别!")
return
self.text_synthesize.delete(1.0, tk.END)
self.text_synthesize.insert(tk.END, self.recognized_text)
defclear_text(self):
"""清空所有文本框"""
self.text_recognized.delete(1.0, tk.END)
self.text_synthesize.delete(1.0, tk.END)
self.recognized_text = ""
self.label_status.config(text="状态:就绪", foreground="black")
deftext_to_speech(self, text):
"""语音合成核心逻辑"""
engine.say(text)
engine.runAndWait()
if __name__ == "__main__":
root = tk.Tk()
app = VoiceAssistantGUI(root)
root.mainloop()
代码关键部分解释
- 分为「语音识别区」和「语音合成区」两个标签框架(
LabelFrame),结构清晰。 - 使用
ScrolledText 作为文本输入/输出框,支持滚动,适配长文本。 - 按钮功能分工明确:开始录音识别、预览播放、使用识别结果合成、清空文本。
- 录音识别和语音播放都是耗时操作,通过
threading.Thread 开启子线程执行,避免 GUI 主线程卡死。 - 用
root.after(0, 函数) 确保界面更新操作在主线程执行(tkinter 不允许子线程直接修改界面)。
- 状态标签实时显示当前状态(就绪/录音中/识别中/完成/失败),并通过颜色区分。
- 空文本校验:合成前检查输入框是否为空,避免无效操作。
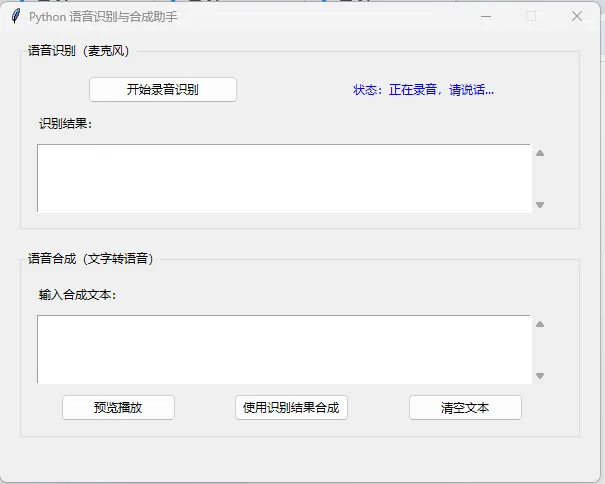
运行效果
- 启动程序后,弹出 600x450 的窗口,分为两个功能区。
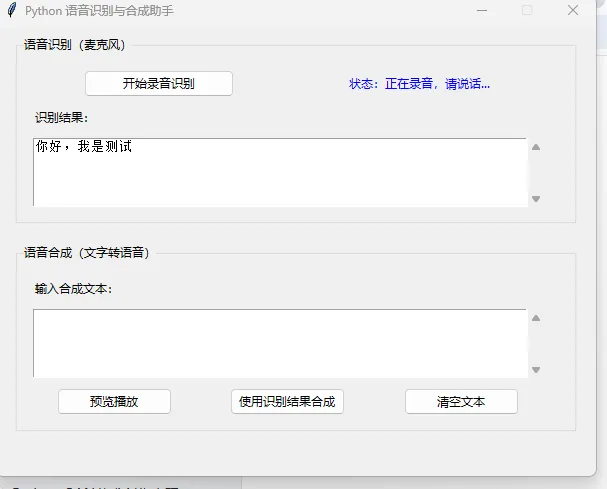
- 点击「开始录音识别」,状态变为“正在录音,请说话”,对着麦克风说话。
- 说完后自动停止录音,状态变为“正在识别”,识别完成后结果显示在「识别结果」文本框。
- 可直接在「输入合成文本」框输入文字,点击「预览播放」即可听到合成语音。
- 点击「使用识别结果合成」,会将识别结果自动填入合成文本框,方便快速复用。
- 点击「清空文本」可清空所有输入/输出内容,恢复初始状态。
依赖说明
运行前需确保已安装以下库(和之前一致):
pip install SpeechRecognition pyttsx3
# Windows 若 pyaudio 安装失败,执行:
# pip install pipwin && pipwin install pyaudio
总结
- 核心改进:用 tkinter 封装了语音识别/合成功能,实现可视化交互,关键耗时操作通过线程避免界面卡死。
- 交互亮点:状态提示、按钮禁用/启用、空值校验、识别结果一键复用,提升用户体验。
- 扩展方向:可添加语速/音量调节滑块、保存合成语音为音频文件、更换识别/合成引擎(如百度AI)等功能。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
