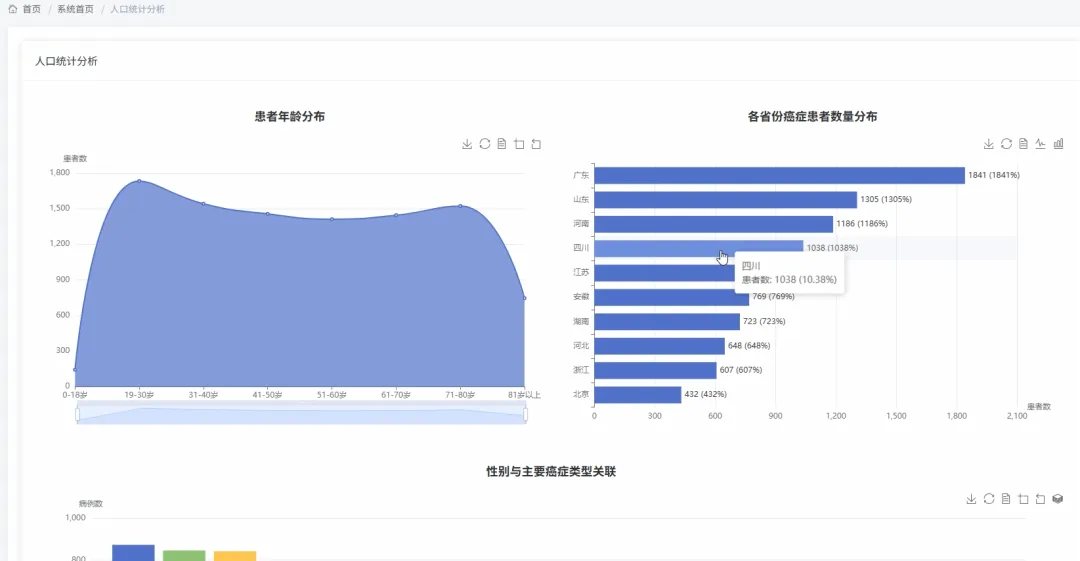
from pyspark.sql import SparkSession, Windowfrom pyspark.sql.functions import col, when, count, sum as _sum, max as _max, row_numberimport pandas as pdspark = SparkSession.builder.appName("CancerDataAnalysis").getOrCreate()def analyze_age_distribution(df): """核心功能1:患者年龄分布分析""" # 定义年龄区间 df_with_age_group = df.withColumn("age_group", when((col("Age") >= 0) & (col("Age") < 20), "0-19岁") .when((col("Age") >= 20) & (col("Age") < 40), "20-39岁") .when((col("Age") >= 40) & (col("Age") < 60), "40-59岁") .otherwise("60岁及以上")) # 按年龄分组统计患者数量 age_distribution_df = df_with_age_group.filter(col("age_group").isNotNull()).groupBy("age_group").agg(count("PatientID").alias("patient_count")) # 按照年龄区间顺序排序 age_distribution_df = age_distribution_df.orderBy(col("age_group")) # 转换为Pandas DataFrame以便返回或进一步处理 result_pdf = age_distribution_df.toPandas() return result_pdfdef analyze_stage_treatment_relation(df): """核心功能2:癌症分期与治疗方式关系分析""" # 筛选出分期和治疗方式不为空的数据 filtered_df = df.filter(col("CancerStage").isNotNull() & col("TreatmentType").isNotNull()) # 按癌症分期和治疗方式分组,统计患者数量 stage_treatment_df = filtered_df.groupBy("CancerStage", "TreatmentType").agg(count("PatientID").alias("patient_count")) # 使用pivot函数将治疗方式转换为列,便于查看矩阵关系 pivoted_df = stage_treatment_df.groupBy("CancerStage").pivot("TreatmentType").sum("patient_count").fillna(0) # 计算每个分期的总患者数,用于后续计算比例 window_spec = Window.partitionBy() pivoted_df = pivoted_df.withColumn("total_patients_per_stage", _sum(*[col(c) for c in pivoted_df.columns if c != "CancerStage"]).over(window_spec)) # 转换为Pandas DataFrame result_pdf = pivoted_df.toPandas() return result_pdfdef analyze_mutation_cancer_correlation(df): """核心功能3:基因突变与癌症特征关联分析""" # 筛选基因突变和肿瘤类型都不为空的数据 filtered_df = df.filter(col("GeneticMutation").isNotNull() & col("TumorType").isNotNull()) # 按基因突变和肿瘤类型分组,统计患者数量 mutation_cancer_df = filtered_df.groupBy("GeneticMutation", "TumorType").agg(count("PatientID").alias("patient_count")) # 使用窗口函数,为每个基因突变分组内的患者数进行排序 window_spec = Window.partitionBy("GeneticMutation").orderBy(col("patient_count").desc()) # 添加排名列,找出每个基因突变类型下最常见的癌症类型 ranked_df = mutation_cancer_df.withColumn("rank", row_number().over(window_spec)) # 筛选出每个基因突变下排名第一的癌症类型 top_cancer_for_mutation_df = ranked_df.filter(col("rank") == 1).drop("rank") # 计算每个基因突变关联的总患者数 total_counts_df = mutation_cancer_df.groupBy("GeneticMutation").agg(_sum("patient_count").alias("total_count")) # 关联总患者数,计算占比 final_df = top_cancer_for_mutation_df.join(total_counts_df, on="GeneticMutation", how="left") \ .withColumn("percentage", (col("patient_count") / col("total_count")) * 100) # 转换为Pandas DataFrame result_pdf = final_df.toPandas() return result_pdf