不止数据分析:Python + 大模型成为科研人的「AI 实验助手」
一、颠覆传统:科研数据分析的「效率革命」
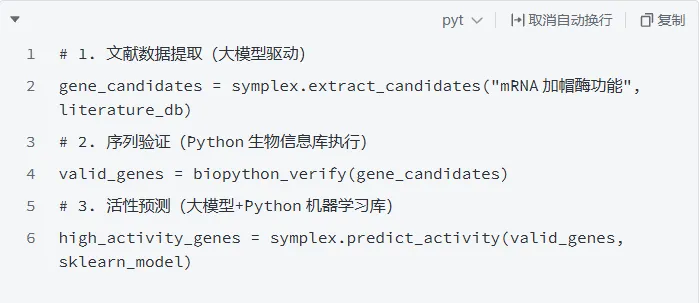
过去科研人员需花费数天甚至数周完成的数据处理流程,如今在 Python + 大模型的协同下实现质的飞跃。CSDN 实测显示,QWQ-32B 大模型结合 Python 的 Function Call 能力,可让复杂数据分析效率提升 1500%,复杂任务完成率从 37% 飙升至 89%。核心突破在于「自动化闭环」:大模型替代人工完成数据清洗、特征工程、模型选择的全流程决策,Python 则负责执行落地。例如面对「东北区销量下滑原因」这类开放式问题,系统可自动调用 SQL 提取数据,通过 Python 的 pandas 库完成统计分析,最终生成带可视化图表的归因报告,全程无需手动编写代码。北京大学钱珑团队研发的 SYMPLEX 大模型,通过 Python 融合生物知识库,自动阅读千万级文献并挖掘功能基因。在 mRNA 疫苗关键工艺中,该系统发现 2 万个新型加帽酶,经实验验证的新酶活性是商业酶的 2 倍,破解了疫苗生产的「卡脖子」难题。其核心流程仅需三步:中国科学院国家天文台研发的 SpecCLIP 模型,通过 Python 实现 LAMOST 与 Gaia 望远镜数据的统一分析。该模型将不同分辨率的恒星光谱映射到同一特征空间,就像把不同语言翻译成通用语法,为银河系考古提供了数百万颗恒星的统一参数测量方案,助力极端贫金属星的大规模搜寻。3. 通用科研:谷歌 Gemini 3.1 Pro 的推理突破升级后的 Gemini 3.1 Pro 在科学推理测试中得分达 77.1%,性能是上一代的两倍。其与 Python 结合后,可处理 50GB 级数据集,自动生成实验设计、数据可视化和结论解释,已广泛应用于物理、化学等基础学科的复杂课题研究。三、实战指南:3 个科研必备的 Python + 大模型工作流✅ 核心优势:自动识别缺失值、异常值处理方案,支持 csv/xlsx/parquet 多格式通过自然语言描述需求,大模型生成 Python 代码,直接输出符合 Nature、IEEE 期刊要求的图表:✅ 解决痛点:中文显示异常、子图布局复杂、期刊格式不兼容问题✅ 效率提升:自动完成 3 次重复实验,计算均值标准差,结果直接用于论文表格1、合规边界:AI 可辅助代码生成、数据处理,但不可替代研究设计和结论判断,生成代码必须人工审查调试;2、工具选择:开源优先(通义灵码、CodeGeeX),商业模型推荐 Gemini 3.1 Pro(科研推理优化)、DeepAnalyze(自动数据科学);3、部署技巧:开启 tensor_parallel=4 支持大体积数据,预加载高频工具库减少 300ms 冷启动时间。当 Python 的工程能力遇上大模型的认知智能,科研数据分析正从「人力密集型」转向「智能驱动型」。从基因挖掘到宇宙探索,从实验室数据到巡天观测,这种组合正在打破学科边界,让科研人员从重复劳动中解放,聚焦真正的创新突破。正如 DeepAnalyze 模型所展示的,80 亿参数的大模型已能生成接近专业分析师水平的研究报告,而这仅仅是开始。未来,每个科研人员都将拥有专属的「AI 数据助手」,让科学发现的速度与深度实现双重飞跃。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
