理解 Linux 命名空间(Namespace):学习从原理到手动构建容器
- 2026-07-03 05:56:34
提到Docker、Podman、Kubernetes这类技术,就绕不开容器这个词。容器凭借轻量、可移植、自包含的执行环境,彻底改变了软件的开发、交付和运行方式。而容器之所以能与宿主机及其他容器隔离开,并非依靠单一的大型软件,而是由一系列内核特性实现的,其中Linux命名空间是最核心的底层支撑。

本文将聚焦于理解命名空间的定义、设计初衷、工作原理,以及如何不借助任何容器运行时直接操作命名空间。同时,你还会学会挂载独立的文件系统、创建隔离的用户环境、添加控制组隔离,以及从零构建一个极简容器。
一、命名空间的发展简史
Linux命名空间诞生于21世纪初,初衷是解决多用户系统中日益增长的资源隔离需求。早在2002年,Linux 2.4.19内核就引入了第一个命名空间——挂载命名空间,实现了为每个进程创建独立的挂载点。这一概念随后不断扩展:2008年推出PID命名空间实现进程隔离,紧接着又诞生了实现网络隔离的网络命名空间和实现进程间通信隔离的IPC命名空间。
2013年Docker的出现成为重要转折点,它利用命名空间技术,在不依赖虚拟机的前提下创建了轻量、可快速部署的容器。Docker将隔离能力(命名空间) 与细粒度资源管理(控制组cgroup) 相结合,让容器技术得到普及,彻底改变了应用开发和部署的模式。
如今,命名空间已成为Kubernetes等技术的核心组件——Kubernetes正是依靠它在生产环境中编排数千个容器。作为Linux原生的资源隔离方案,命名空间轻量、高性能,是现代虚拟化技术的核心驱动力。
二、Linux命名空间的工作原理
熟悉C++或Python编程的开发者对命名空间一定不陌生,它能为变量和对象定义独立的作用域,避免命名冲突。
Linux系统的命名空间借鉴了C++命名空间的核心思想——切换资源作用域。在Unix系统中,大部分资源都是全局管理的:比如进程ID(PID)是由内核全局分配的唯一标识,系统中不会有两个进程拥有相同的PID,设备挂载点的管理方式也是如此。
我们以UTS命名空间(UNIX分时系统命名空间)为例,直观理解命名空间的作用——它的核心功能是隔离主机名和网络信息服务(NIS)域名。
本次实操将使用unshare命令,它的作用是启动一个与父进程解除指定命名空间共享的程序,这里的「解除共享」即表示「为该程序新建并隔离一个独立的命名空间」。
实操:创建独立的UTS命名空间
打开第一个终端,查看当前宿主机的主机名(此时处于宿主机的默认命名空间):
[ddh@lns ~]$ hostname输出示例:

启动一个新的shell进程,并为其创建独立的UTS命名空间( --uts参数指定UTS命名空间,创建多数命名空间需要root权限,因此需配合sudo):
[ddh@lns ~]$ sudo unshare --uts /bin/bash[sudo] password for ddh: [root@lns ddh]# 输出示例:

在这个新的shell中修改主机名,该修改仅对当前UTS命名空间生效:
[root@lns ddh]# hostname isolated-box[root@lns ddh]# exec bash[root@isolated-box ddh]# 输出示例:

执行exec bash的目的是重启shell,让命令行提示符加载新的主机名,此时提示符会显示新主机名isolated-box。
在当前shell中验证主机名修改结果:
[root@isolated-box ddh]# hostnameisolated-box[root@isolated-box ddh]# 打开第二个终端(仍处于宿主机命名空间),再次查看主机名:
[ddh@lns ~]$ hostnamelns输出示例:

输出仍为lns。
结果说明:第一个终端的进程(及其子进程)处于独立的UTS命名空间,主机名为isolated-box;而系统中所有其他进程(包括第二个终端的shell)仍处于宿主机的原始UTS命名空间,主机名保持不变。
不同发行版的权限差异
Ubuntu及其衍生发行版中,无root权限执行unshare会失败——因为系统默认禁用非特权用户命名空间,这会导致内核拒绝向uid_map写入数据,触发经典的Operation not permitted错误。
而RHEL、openSUSE、Arch系列发行版则默认启用非特权用户命名空间,无需额外配置即可直接执行unshare,且能正常访问用户的主目录。若要在Ubuntu中启用该功能,执行以下命令即可,启用后命名空间内的UID 0会正确映射到宿主机的实际用户UID:
sudo sysctl kernel.unprivileged_userns_clone=1查看系统中的命名空间
创建命名空间后,可通过lsns命令全局查看所有可访问的命名空间,或查看指定进程所属的命名空间。
在第二个终端(宿主机命名空间)执行lsns:
输出示例:
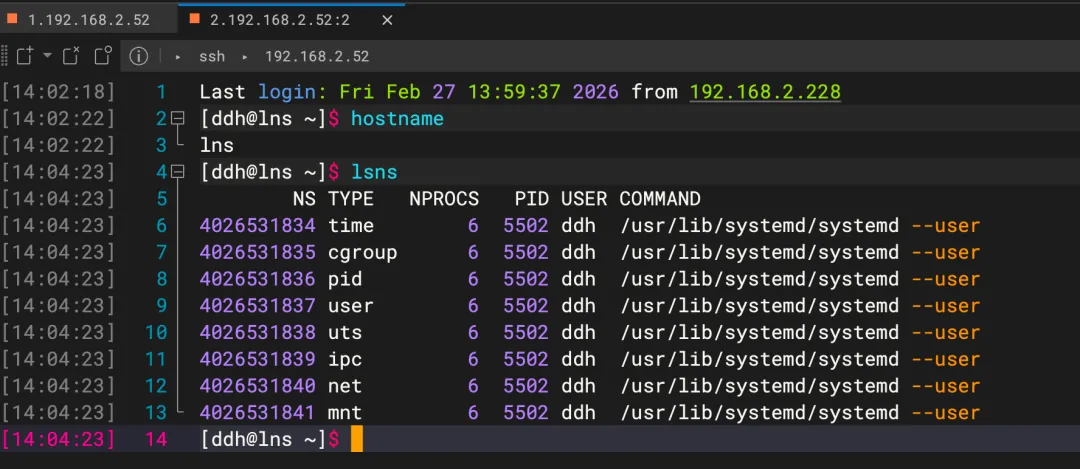
新建命名空间执行lsns:
输出示例:
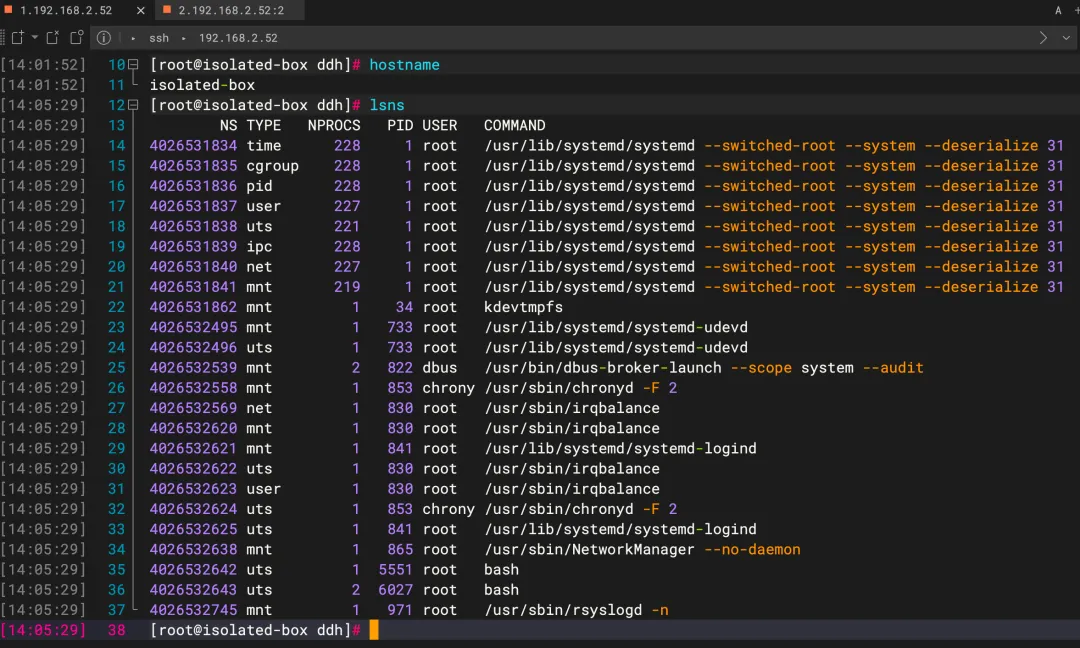
输出中能看到两点关键信息:
原始的 UTS 命名空间(示例中 ID 为 4026531838)被几乎所有进程使用,包括 PID 1 的初始化进程; 新建的 UTS 命名空间(示例中 ID 为 4026532642)仅被一个进程(bash)占用。
命名空间的两个核心特性
理解命名空间的继承性和生命周期,是掌握其工作原理的关键:
继承性:进程通过 fork()创建子进程时,子进程会继承父进程的所有命名空间。这也是为什么上述实操中,新的bash进程会属于新建的UTS命名空间。生命周期:当一个命名空间中的最后一个进程终止或退出时,内核会自动销毁该命名空间。因此,只要在第一个终端执行 exit退出shell,新建的UTS命名空间就会立即消失。lsns输出中的NPROCS列,会显示维持该命名空间存活的进程数。
可被隔离的核心资源
除了UTS命名空间,Linux命名空间还能对以下核心系统资源实现隔离,也是容器技术的核心隔离维度:
挂载(mnt)命名空间 进程ID(pid)命名空间 网络(net)命名空间 进程间通信(IPC)命名空间 用户(user)命名空间
此外,还有一些已提出但尚未实现的命名空间类型:
时间(Time)命名空间 系统日志(syslog)命名空间
三、命名空间的架构类型
操作系统创建和管理命名空间的方式,主要取决于内核中实现的命名空间架构。目前有两种基础架构,所有命名空间均基于其中一种实现:分层架构和非分层架构。
1. 分层架构
分层架构中,不同作用域的资源存在关联关系:新创建的命名空间(子命名空间)资源会与已存在的系统命名空间(父命名空间)关联。尽管命名空间之间相互隔离,但资源可以被映射,因此父命名空间能感知到子命名空间的运行状态。
图示:
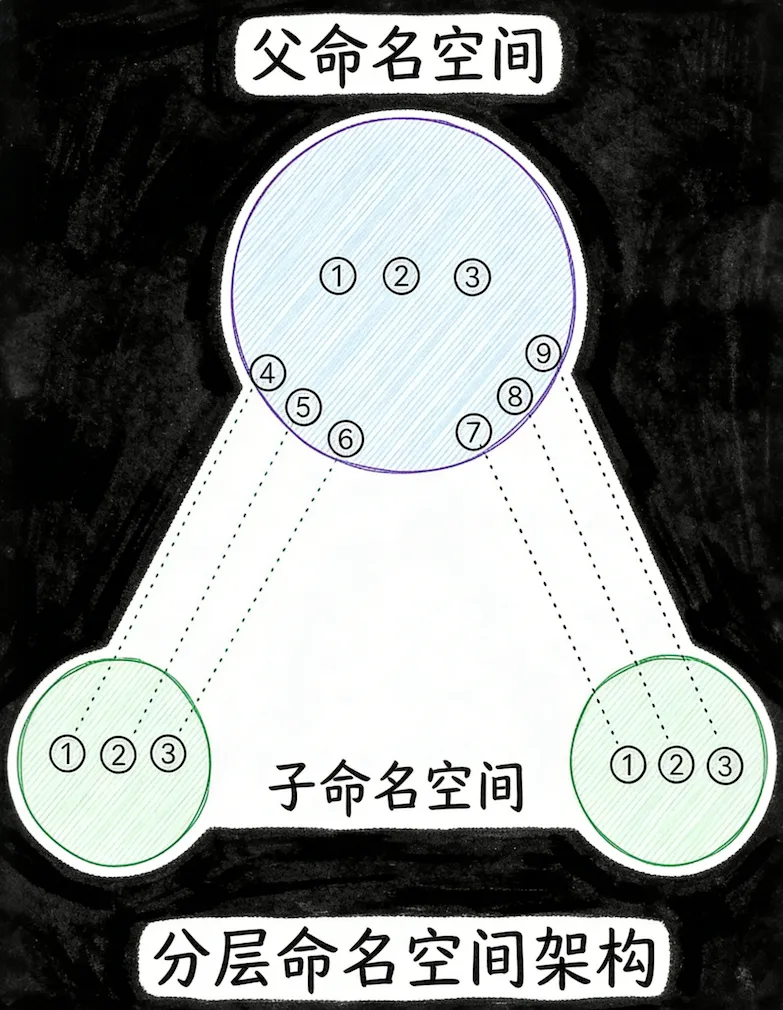
简单来说,子命名空间由父命名空间派生,形成层级关系,子命名空间中的进程会被映射到父命名空间中,但二者的资源标识(如PID)不同。
2. 非分层架构
非分层架构中,不同作用域的资源无任何关联:资源越简单,越可能采用这种架构(比如UTS命名空间)。子命名空间的资源不会映射到创建它的父命名空间(如系统默认命名空间),父命名空间也无法感知子命名空间的资源状态。
架构的实际应用
Linux系统中两种架构均有使用,具体采用哪种取决于被隔离的资源类型,这一点在LXC和Docker容器中体现得尤为明显:
运行在LXC容器中的进程,能在宿主机中被看到(资源已做映射),因此PID命名空间采用分层架构; UTS命名空间则采用非分层架构,容器内的主机名修改不会对宿主机产生任何影响。
命名空间的内核实现:nsproxy结构体
Linux内核中(version:3.10),负责管理命名空间分组的核心数据结构是nsproxy,其定义在include/linux/nsproxy.h头文件中:
structnsproxy {atomic_t count; structuts_namespace *uts_ns;structipc_namespace *ipc_ns;structmnt_namespace *mnt_ns;structpid_namespace *pid_ns;structnet *net_ns;};图示:
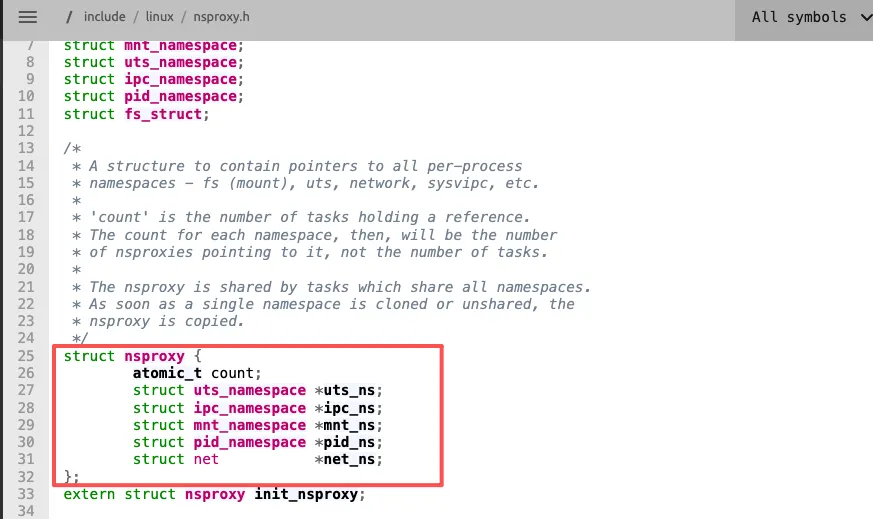
该结构体包含5个命名空间的指针,唯独不包含用户命名空间,这是因为用户命名空间的实现方式特殊:所有其他命名空间的结构体中,都有一个指向用户命名空间的指针user_ns。
将用户命名空间与nsproxy框架分离的核心原因是安全权限的实现差异:
nsproxy框架的操作需要CAP_SYS_ADMIN内核能力(权限等级与sudo相当);用户命名空间属于内核的凭证框架(cred) 组,对应与进程完全不同的安全作用域。
四、七大核心命名空间详解
1. PID命名空间
PID命名空间是对容器化影响最大的命名空间,核心功能是隔离进程ID的编号空间——这意味着不同PID命名空间中的进程,可以拥有相同的PID。
核心问题解决
传统Linux系统中,PID 1是内核启动的第一个进程(init或systemd),负责回收所有孤儿子进程。而容器需要模拟一个独立的Linux系统,也需要自己的PID 1进程,但宿主机的PID 1已被占用。
PID命名空间通过独立的PID编号规则解决该问题:在新的PID命名空间中,第一个被创建的进程会成为该命名空间的PID 1,并承担该命名空间内的「初始化进程」职责——负责回收命名空间内的所有孤儿子进程。
实操:创建独立的PID命名空间
[ddh@lns ~]$ sudo unshare --pid --fork --mount-proc /bin/bash[sudo] password for ddh:[root@lns ddh]#参数解析
--pid:创建新的PID命名空间;--fork:创建PID命名空间的必选参数,让unshare以子进程形式启动指定程序(/bin/bash),该子进程会成为新命名空间的PID 1;--mount-proc:/proc文件系统是ps、top、pstree等命令的底层依赖,会反映当前PID命名空间的进程树。该参数会为新的PID命名空间挂载一个独立的proc文件系统,避免宿主机的所有进程被容器内看到。
验证隔离效果
在新的shell中执行ps aux,只会看到两个进程:bashshell本身(PID 1)和ps命令进程,宿主机上运行的数百个进程完全不可见,实现了进程级的完全隔离。
输出示例:

核心概念:内部PID与外部PID
内部PID:从命名空间内部看到的PID,比如上述实操中 bash的PID为1;外部PID:从宿主机(根PID命名空间)看到的「真实PID」,是内核全局唯一的标识。
在第二个终端(宿主机)中,可通过以下命令查询该进程的真实PID:
[ddh@lns ~]$ ps aux | grep 'unshare.*pid'输出示例:

示例中,宿主机看到的真实PID为20912,而命名空间内看到的PID为1。内核会维护这种PID映射关系,确保kill等命令能跨命名空间正常工作。
2. 网络命名空间
如果说PID命名空间实现了进程隔离,那么网络命名空间就是实现网络隔离的核心,它会为进程提供一个完全独立的网络协议栈,包括:独立的网络接口、IP地址、路由表、套接字列表、连接跟踪表和防火墙规则。
这一特性让每个容器都能拥有自己的lo回环接口、独立的物理/虚拟网卡(如enp0s3)和私有IP地址,与宿主机及其他容器的网络环境完全隔离。
实操:创建独立的网络命名空间
查看宿主机的网络接口(宿主机命名空间):
[ddh@lns ~]$ ip -br link list输出示例:

输出会显示宿主机的所有物理和虚拟网络接口。
创建新的网络命名空间并启动shell:
[ddh@lns ~]$ sudo unshare --net /bin/bash[sudo] password for ddh:[root@lns ddh]# 在新命名空间中查看网络接口:
[root@lns ddh]# ip -br link listlo DOWN 00:00:00:00:00:00 <LOOPBACK>此时宿主机的所有接口(如enp0s3)都会消失,新的网络命名空间默认仅包含一个未启用的 lo 回环接口。
输出示例:

启用回环接口:
[root@lns ddh]# ip link set lo up[root@lns ddh]# ip -br link listlo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>[root@lns ddh]#尝试访问外部网络(如电信DNS):
[root@lns ddh]# ping 61.128.128.68ping: connect: Network is unreachable[root@lns ddh]#会触发Network is unreachable错误,原因是该命名空间无任何路由配置,也无连接外部网络的接口,实现了网络级的完全隔离。
3. 挂载命名空间
挂载命名空间是Linux中最古老、最重要的命名空间之一,核心功能是隔离进程的文件系统视图——容器内看到的/根目录及各路径,与宿主机完全不同,尽管二者最终依赖同一个内核。这种「视觉隔离」让每个容器都拥有自己的文件系统布局,实现自包含。
挂载命名空间会为进程提供私有的挂载点集合:进程只能看到所属命名空间内的挂载点。内核在创建新的挂载命名空间时,会复制当前的挂载表,但后续对挂载表的所有修改(挂载/卸载)仅对当前命名空间生效,除非显式配置了挂载传播。
实操:创建独立的挂载命名空间
查看宿主机的挂载表(宿主机命名空间):
[ddh@lns ~]$ findmnt输出示例:
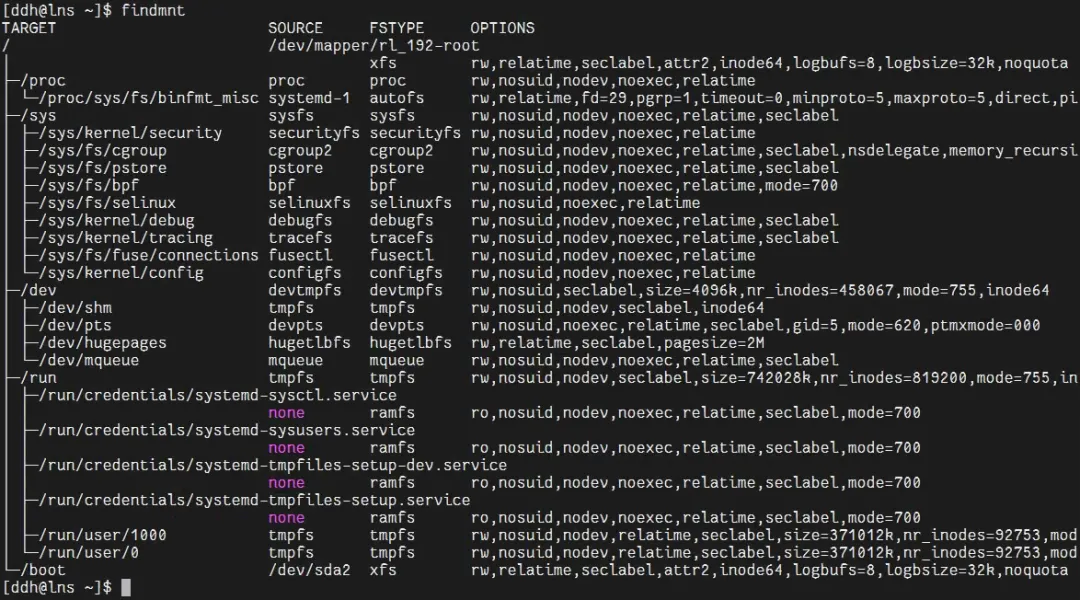
输出会包含根文件系统、启动分区、各类绑定挂载、systemd创建的临时文件系统等,这是当前进程所属命名空间的挂载表。
创建新的挂载命名空间并启动shell:
[ddh@lns ~]$ sudo unshare --mount /bin/bash[sudo] password for ddh:[root@lns ddh]#此时命名空间内的挂载表与宿主机完全一致(创建时复制),但后续的挂载操作不会同步到宿主机。
验证挂载隔离:
① 创建测试挂载点:
[root@lns ddh]# mkdir /mnt/test② 将
/etc目录绑定挂载到测试挂载点:[root@lns ddh]# mount --bind /etc /mnt/test③ 在当前命名空间执行
findmnt,能看到新的绑定挂载;输出示例: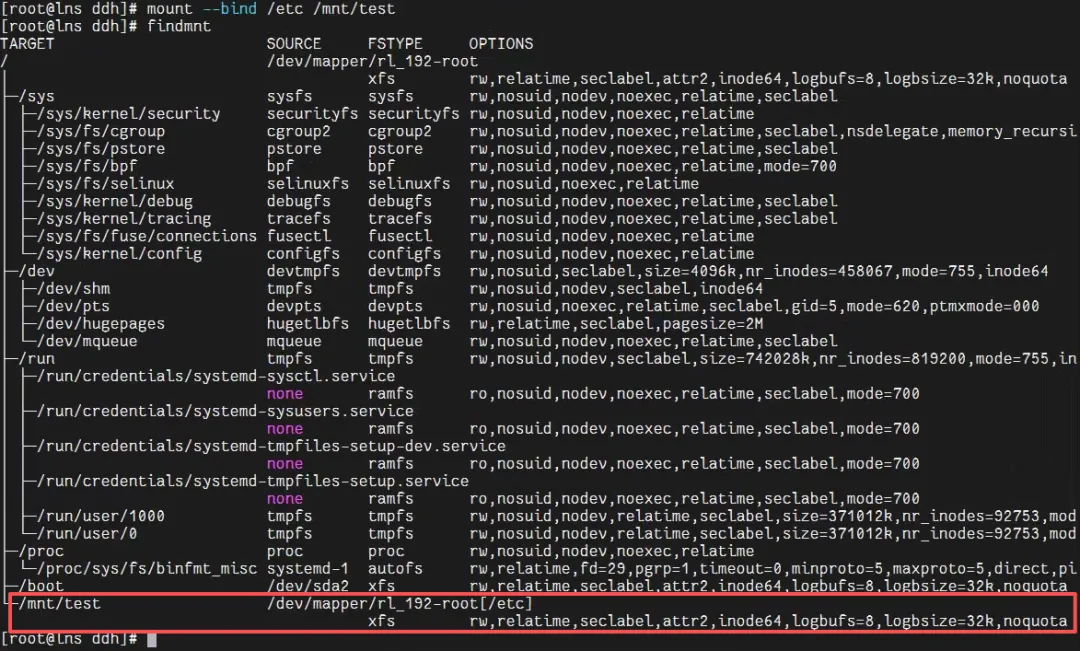
④ 在宿主机终端执行
findmnt,无法看到该挂载点,宿主机对命名空间内的挂载操作完全无感知。输出示例: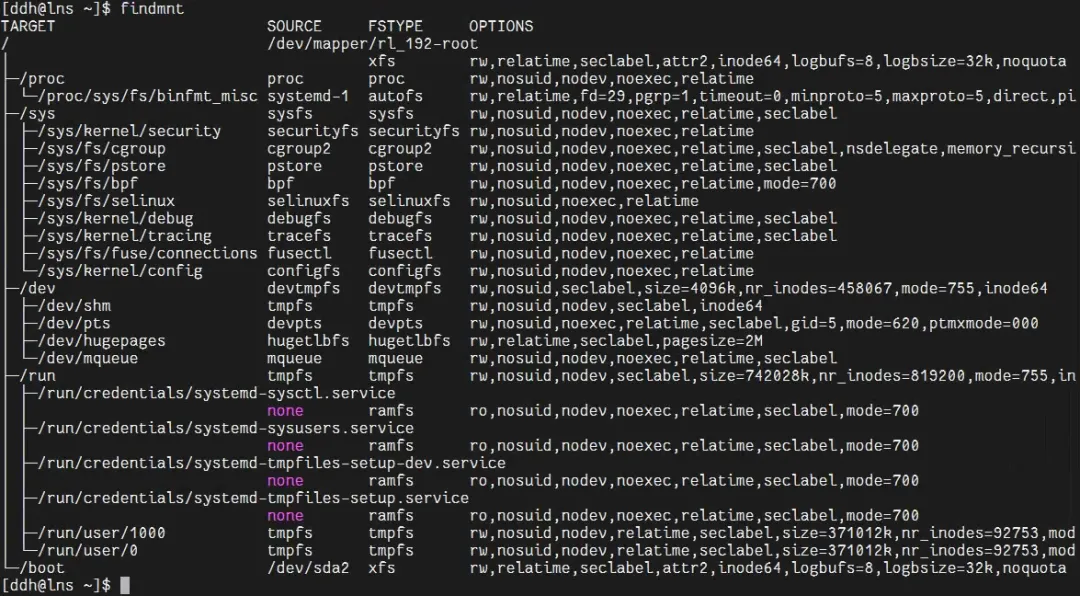
清理测试环境:
[root@lns ddh]# umount /mnt/test[root@lns ddh]# exit退出shell后,命名空间被销毁,该挂载操作也会被内核彻底清除。
关键特性:挂载传播模式
挂载命名空间有一个容易被忽略的重要特性——挂载传播模式,它决定了一个命名空间中的挂载操作是否会传播到其他命名空间。
可通过以下命令查看挂载传播模式:
findmnt -o TARGET,PROPAGATION输出示例:
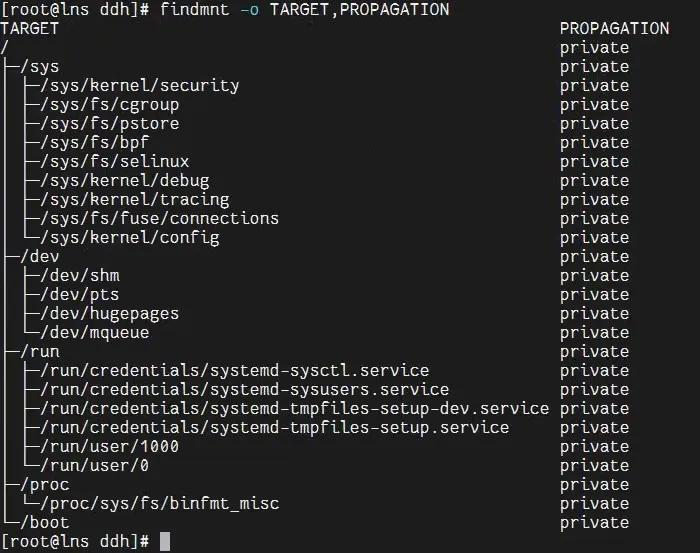
命名空间内的绑定挂载支持三种模式:
私有(private) :挂载操作仅对当前命名空间生效,是容器的最安全选择,避免挂载操作泄漏到父命名空间; 共享(shared) :挂载操作会同步到所有关联的命名空间; 从属(slave) :挂载操作仅能从父命名空间同步到子命名空间,反之则不行。
容器中的应用
Docker、Podman、LXC等容器运行时,均通过挂载命名空间构建容器的自定义文件系统:将实际目录、叠加文件系统(overlayfs)、网络挂载和临时文件系统组合成容器的文件路径,且不会对宿主机的文件系统产生任何影响。例如Docker通过overlayfs将镜像的只读层与容器的可写层结合,若无挂载命名空间,这些叠加层会污染宿主机的文件系统。
4. 用户命名空间
用户命名空间的核心功能是隔离用户和用户组的ID,它允许进程在命名空间内以root身份运行,但在宿主机上无任何root权限。这是Linux安全领域的重要突破,打破了「UID 0一定对应宿主机管理员」的固有认知。
核心机制:UID/GID映射
用户命名空间会建立内部ID与外部ID的映射关系:
内部ID:进程在命名空间内看到的UID/GID,比如命名空间内的UID 0(root); 外部ID:内核在宿主机上为该进程分配的真实UID/GID,通常是宿主机的普通用户ID。
这种映射让进程在命名空间内拥有高权限,而在宿主机上保持低权限,实现权限隔离。
实操:创建独立的用户命名空间
创建用户命名空间最简单的方式是使用-r(或--map-root-user)参数,它会自动配置UID/GID映射,让当前宿主机用户在命名空间内成为root:
[ddh@lns ~]$ unshare -r /bin/bash[root@lns ddh]#此时shell提示符变为root@lns ddh,表示在命名空间内已拥有root权限,但宿主机上该进程的真实所有者仍是普通用户(如UID 1000)。
容器中的应用
几乎所有容器运行时都高度依赖这种ID映射:容器中声明的「以root运行」,均指命名空间内的root身份,宿主机内核仍将其视为普通进程,除非容器以特权模式运行。这一机制大幅降低了容器的安全风险,限制了容器被攻破后对宿主机的破坏范围。
与其他命名空间的协同
用户命名空间能与其他命名空间协同实现更强的隔离效果:比如若一个用户命名空间拥有一个挂载命名空间,那么命名空间内的进程无需宿主机root权限即可执行挂载操作,也能在命名空间内设置内核能力,且不会影响宿主机。这种灵活性让无特权容器(如rootless Podman、rootless Docker)成为可能——普通用户无需root权限即可运行容器。
安全注意事项
用户命名空间曾是Linux内核的安全漏洞高发区:尽管它能限制提权攻击的影响,但如果命名空间的实现本身存在漏洞,仍可能导致宿主机被攻破。因此,一些高安全要求的环境会限制用户命名空间的使用,但对于绝大多数场景,它是让容器安全运行的核心特性,避免了容器对宿主机root权限的依赖。
5. 控制组(cgroup)命名空间
PID命名空间隔离进程、网络命名空间隔离网络,而控制组命名空间的核心功能是隔离控制组的视图——为进程提供私有的控制组层级视图。这一点对容器至关重要,因为容器需要独立管理自身的资源限制,而不干扰宿主机或其他容器的控制组配置。
控制组的基础作用
控制组(cgroups)是Linux的资源限制与计量机制,可对进程的CPU时间、内存分配、I/O带宽等资源进行精细化控制。而控制组命名空间的作用是隐藏宿主机的控制组路径,仅向进程暴露与自身相关的控制组路径。
实操:创建独立的控制组命名空间
查看宿主机的控制组路径(宿主机命名空间):
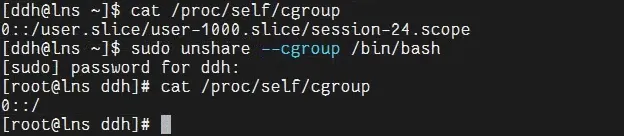
[ddh@lns ~]$ cat /proc/self/cgroup0::/user.slice/user-1000.slice/session-24.scope[ddh@lns ~]$输出会包含每个资源控制器的条目,均指向宿主机控制组层级中的路径。
创建新的控制组命名空间并启动shell:
[ddh@lns ~]$ sudo unshare --cgroup /bin/bash[sudo] password for ddh:在新命名空间中查看控制组路径:
[root@lns ddh]# cat /proc/self/cgroup0::/此时会看到简化后的路径,表示已实现控制组视图的隔离,命名空间内的进程无法查看或修改宿主机的控制组配置。图示:
核心特点
控制组命名空间不会独立创建或销毁控制组,它仅负责控制组视图的隔离。若要为命名空间内的进程设置资源限制,需先在宿主机创建对应的控制组,或在用户命名空间允许的前提下在内部创建。
控制组命名空间与挂载、用户、PID命名空间结合后,为容器提供了完整的资源管理框架,实现了资源隔离与资源限制的双重目标。
6. IPC命名空间
IPC(进程间通信)命名空间的核心功能是隔离System V IPC对象和POSIX消息队列,其中System V IPC对象包括共享内存段、信号量数组和消息队列——这些都是进程间通信的核心机制。
若无IPC隔离,系统中所有进程都能看到并可能干扰其他进程的IPC对象,存在数据泄露和操作冲突的风险。而IPC命名空间确保只有同一命名空间内的进程才能访问彼此的IPC对象。
实操:创建独立的IPC命名空间
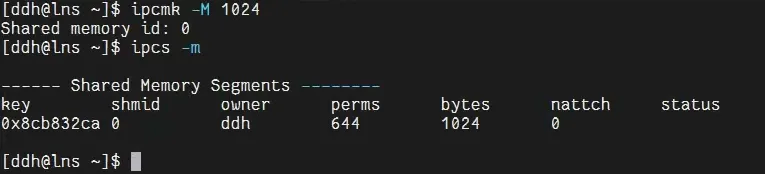
在宿主机创建一个共享内存段(宿主机命名空间):
[ddh@lns ~]$ ipcmk -M 1024Shared memory id: 0[ddh@lns ~]$ ipcs -mipcmk -M 1024表示创建一个1024字节的共享内存段,ipcs -m用于查看所有共享内存段,输出会包含刚创建的共享内存段信息。图示:
创建新的IPC命名空间并启动shell:
[ddh@lns ~]$ sudo unshare --ipc /bin/bash[root@lns ddh]# ipcs -m此时输出为空,宿主机创建的共享内存段在新命名空间中完全不可见,而在命名空间内创建的IPC对象,也仅对内部进程可见。
图示:

7. 时间命名空间
时间命名空间是Linux 5.6内核新增的特性,核心功能是为不同的命名空间设置独立的系统时钟偏移,支持CLOCK_MONOTONIC(单调时钟)和CLOCK_BOOTTIME(启动时钟)的独立配置。
该命名空间的主要应用场景是容器/虚拟机的热迁移,或为一组进程调整系统时间而不影响宿主机的时钟。例如,可将某个容器的时钟回拨24小时,而宿主机和其他容器的时间保持不变。
时间命名空间是一种专用型命名空间,目前尚未在日常的容器操作中广泛使用,但它填补了Linux全局资源隔离的最后一块空白,让所有核心系统资源都能实现隔离。
五、基于Linux命名空间 从零构建极简容器
了解了所有命名空间的核心概念后,我们可以将它们组合起来,不借助任何容器运行时,手动构建一个极简容器。这一过程能让你深入理解容器引擎的底层工作原理——容器引擎本质上就是这些基础操作的自动化封装。
步骤1:创建容器的根文件系统
容器需要拥有自己的独立文件系统,本次实操使用BusyBox(Linux极简工具箱,包含所有基础的Linux命令)构建最小化的根文件系统:
[ddh@lns ~]$ ROOTFS="$HOME/rootfs"[ddh@lns ~]$ mkdir -p "$ROOTFS"/{bin,proc,sys,dev}[ddh@lns ~]$ cp /usr/sbin/busybox "$ROOTFS/bin/"# 如果报错‘No such file or directory’,可能需要安装 busybox[ddh@lns ~]$ for cmd in sh mount umount ls mkdir ps ping hostname; do ln -sf busybox "$ROOTFS/bin/$cmd"done[ddh@lns ~]$命令解析:
定义根文件系统的目录为 ~/rootfs;创建容器文件系统的核心目录: bin(可执行文件)、proc(进程文件系统)、sys(系统文件系统)、dev(设备文件);将BusyBox复制到 bin目录;为常用命令创建软链接,指向BusyBox(BusyBox的所有命令均为自身的软链接)。
实际应用:除了BusyBox,也可使用Debian、Ubuntu、Alpine等发行版的最小化根文件系统,核心要求是包含/bin、/proc、/sys、/dev等核心目录,可选/etc配置目录。
步骤2:创建组合命名空间
组合挂载、PID、UTS、IPC、网络命名空间,创建一个接近真实容器的隔离环境(--fork确保进程在新命名空间中以子进程运行):
[ddh@lns ~]$ sudo ROOTFS="$HOME/rootfs" unshare --mount --pid --uts --ipc --net --fork /bin/bash[sudo] password for ddh:[root@lns ddh]#进入该shell后,你将拥有以下隔离能力:
独立的用户命名空间(root身份); 私有的进程树(PID命名空间); 挂载操作不会影响宿主机(挂载命名空间); 独立的网络、IPC、UTS命名空间。
步骤3:配置挂载命名空间
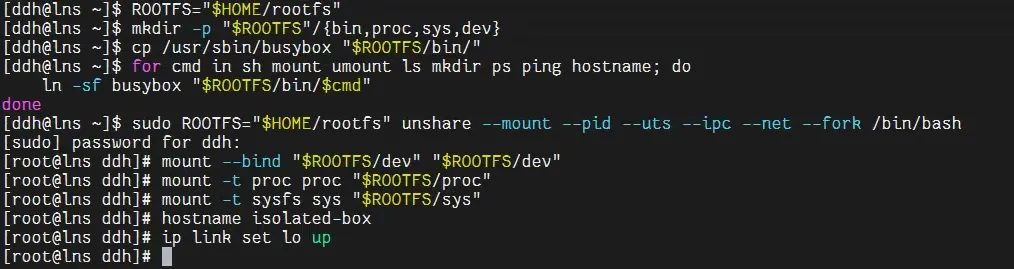
为容器的根文件系统挂载必要的内核文件系统,让容器能正常访问进程、系统和设备信息:
[root@lns ddh]# mount --bind "$ROOTFS/dev" "$ROOTFS/dev"[root@lns ddh]# mount -t proc proc "$ROOTFS/proc"[root@lns ddh]# mount -t sysfs sys "$ROOTFS/sys"同时配置容器的主机名和网络(启用回环接口):
# 配置UTS命名空间的主机名[root@lns ddh]# hostname isolated-box# 启用网络命名空间的回环接口[root@lns ddh]# ip link set lo up图示:
注:若要让容器访问外部网络,需配置虚拟以太网对(veth pair)或macvlan虚拟网卡,这一步在Docker等容器引擎中会自动完成。
步骤4:切换到容器的根文件系统
使用chroot命令,将当前进程的根目录切换到我们创建的~/rootfs,让进程只能看到容器的文件系统:
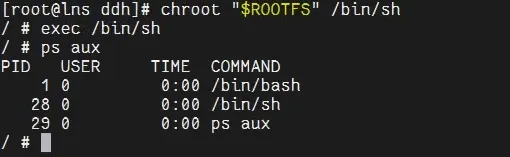
[root@lns ddh]# chroot "$ROOTFS" /bin/sh/ #此时你已进入容器的隔离文件系统,/proc、/sys、/dev均已正确挂载,所有挂载操作仅对容器生效。
步骤5:启动容器的PID 1进程
在容器中启动一个新的shell,作为容器的PID 1进程,承担孤儿进程回收的职责:
exec /bin/sh执行ps aux验证,此时只能看到极少的进程(如PID 1的bash),与真实容器的PID命名空间完全一致。
图示:
最终效果
至此,我们已成功构建一个极简容器,它拥有:
独立的根文件系统; 独立的PID、网络、IPC、UTS、挂载命名空间; 自定义的主机名和回环网络; 与宿主机完全隔离的进程和文件系统视图。
这与Docker等容器引擎创建的容器核心原理一致,区别仅在于容器引擎会将以下操作自动化:
挂载传播模式配置; 网络接口(veth pair)创建与桥接; UID/GID的精细化映射; 镜像分层(overlayfs)的构建; 控制组的资源限制配置; 容器的生命周期管理(启动、停止、重启)。
六、总结
Linux命名空间是构建容器隔离能力的底层隐形框架,它在实现进程、用户、文件系统、网络、资源视图隔离的同时,保持了轻量、高效和灵活的特性。
通过对进程、网络、挂载点等核心系统资源的解耦,命名空间让每个隔离环境都能呈现出「自包含的独立系统」的特征,而所有环境实际上仍共享同一个Linux内核——这也是容器比虚拟机更轻量、更高效的核心原因。
借助unshare、lsns这些简单的命令,我们可以绕开Docker、Kubernetes等上层工具,直接观察和操作命名空间的底层机制。亲手实现这些操作后你会发现,容器的底层原理其实并不复杂,而容器引擎的价值,正是将这些基础操作封装成了易用、可扩展的工具。
理解了命名空间,就理解了容器;理解了容器,就理解了大部分现代云原生基础设施。从Kubernetes到无服务器(Serverless)平台,所有构建在容器之上的技术,其底层核心都是Linux命名空间。
推荐阅读:
👉 1. 数据不丢的底线:Linux运维如何搭建可靠的3-2-1备份体系?
👉 2. 基于 Rocky9 搭建 MySQL8 实践,理解数据库高可用主从架构基础原理
👉 3. Jenkins 安装实践:在 Ubuntu 24.04上搭建 CI/CD 自动化平台
请在微信客户端打开

