Hive简介:基于Hadoop的大数据仓库工具
上一节我们详细讲解了Python接入MySQL的全流程实操,解决了结构化数据的持久化与操作问题。本节课,我们将聚焦大数据处理场景——介绍Hive这款主流的数据仓库工具。在海量数据(TB/PB级)处理中,Hive凭借对SQL的完美支持,让非Java/Scala开发者也能轻松实现大数据统计,是大数据生态中不可或缺的核心组件。
温馨提示:本文所有实操均基于Hadoop生态环境,案例延续电商场景的eshop数据库及相关表,建议大家先确保Hadoop集群正常运行、Hive服务启动,动手跟着敲命令、写代码,更易掌握核心逻辑。
一、Hive是什么?核心定位与价值
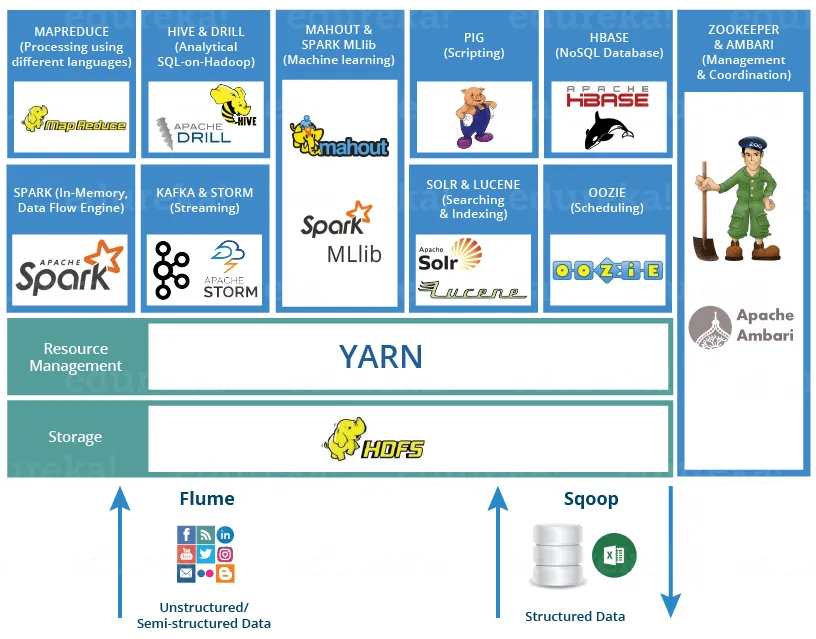
Hive是Facebook开源、目前由Apache软件基金会维护的一款基于Hadoop的数据仓库工具,也是应用最广泛的大数据处理解决方案之一。它的核心价值在于“降低大数据处理门槛”,能将SQL查询转变为MapReduce(Google提出的一个软件架构,用于大规模数据集的并行运算)任务,对SQL提供了完美的支持,能够非常方便的实现大数据统计。
说明:可以通过https://www.edureka.co/blog/hadoop-ecosystem来了解 Hadoop 生态圈,更好地理解Hive在其中的定位。
如果要简单介绍Hive,以下两点是其核心,记牢就能快速掌握Hive的核心逻辑:
- 1. 把HDFS(Hadoop分布式文件系统)中结构化的数据映射成表,无需关注底层文件存储细节,操作方式类似传统数据库;
- 2. 通过把HQL(Hive查询语言,类SQL)进行解析和转换,最终生成一系列基于Hadoop的MapReduce任务或Spark任务,通过执行这些任务完成对数据的处理。也就是说,即便不学习Java、Scala这样的编程语言,一样可以实现对海量数据的处理。
Hive的核心应用场景
Hive主要用于大数据离线批量分析,适合以下场景:
- • 日志分析:处理网站、APP的海量访问日志,统计访问量、用户行为等;
- • 报表生成:定期生成业务报表(如电商交易报表、用户画像报表);
- • 数据仓库建设:对海量结构化、半结构化数据进行清洗、转换、存储,为数据分析提供支撑;
- • 海量数据统计:如用户行为分析、商品销量统计、流量分析等,处理TB/PB级数据效率远超传统数据库。
二、Hive与传统关系型数据库(RDBMS)的核心对比
很多新手会将Hive与MySQL、Oracle等传统关系型数据库混淆,但二者的设计目标、执行方式、数据规模适配差异极大,具体对比如下表所示(清晰区分,避免踩坑):
三、前置准备:Hive使用的5个核心步骤
使用Hive前,需先完成基础环境准备和数据预处理,步骤如下(假设已搭建好大数据平台):
- 1. 搭建如下图所示的大数据平台(核心包含Hadoop、Hive组件,新手可参考Hadoop生态圈文档完成搭建);
- 2. 通过Client节点(跳板机)访问大数据平台,确保能正常连接Hadoop集群和Hive服务;
- 3. 在Hadoop的文件系统(HDFS)中创建数据存储目录,用于存放后续要加载到Hive的数据:
hdfs dfs -mkdir /user/root
- 4. 将本地准备好的数据文件(如用户信息、交易记录)拷贝到Hadoop文件系统的指定目录:
hdfs dfs -put /home/ubuntu/data/* /user/root
- 5. 进入Hive命令行,后续所有建库、建表、查询操作均在此环境中执行:
hive
✅ 小提示:如果进入Hive命令行失败,检查Hive服务是否启动、Hadoop集群是否正常运行,以及环境变量配置是否正确。
四、核心操作:Hive建库建表与数据加载
Hive的使用流程与传统数据库类似(建库→建表→加载数据→查询),但适配大数据场景,支持复合数据类型、分区表等特性,以下是完整实操案例(基于电商场景eshop数据库):
1. 数据库操作(创建、删除、切换)
Hive数据库本质是HDFS中的一个目录,用于隔离不同业务场景的数据,核心命令如下:
-- 1. 创建数据库(eshop:电商场景示例,若不存在则创建)create database eshop;-- 2. 删除数据库(cascade:级联删除,删除数据库的同时删除库中所有表,避免报错)drop database eshop cascade;-- 3. 切换到目标数据库(后续操作均针对该数据库)use eshop;
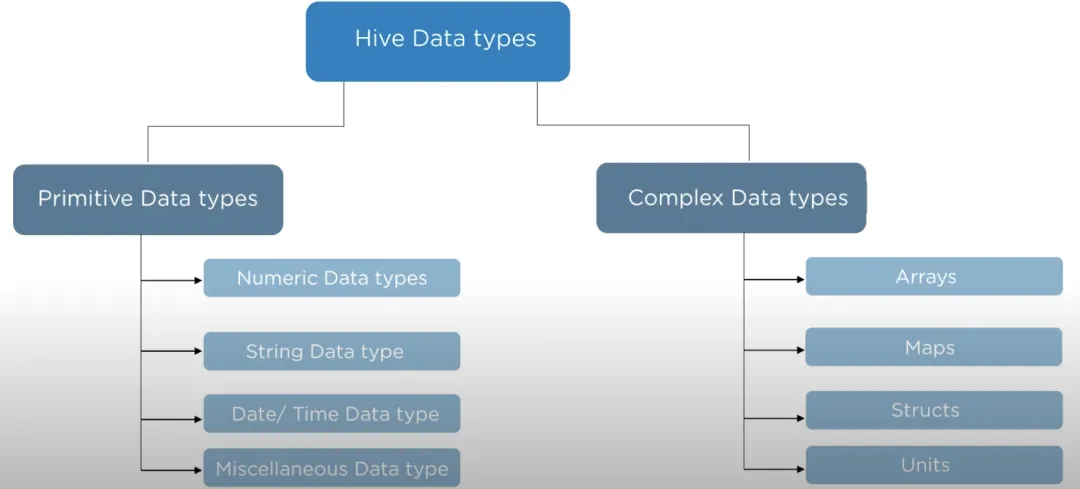
2. Hive数据类型(基础+复合,重点掌握)
Hive支持丰富的数据类型,除了常见的基础类型,还提供适配复杂数据场景的复合类型,无需拆分表字段,适配大数据中多样的数据格式,具体如下:
(1)基本数据类型
| | | |
| | | |
| | | |
| | | 整数(取值范围:-2147483648~2147483647) |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | 日期(格式:yyyy-MM-dd,仅存储日期,不包含时间) |
(2)复合数据类型(大数据场景高频使用)
适合存储嵌套、复杂结构的数据(如用户扩展信息、键值对标签),无需拆分表,提升数据处理效率:
| | |
| | struct<first_name:string, last_name:string>(存储用户姓名,包含名和姓) |
| | map<string,int>(存储用户标签:如{"vip":"1","level":"5"}) |
| | array(存储用户爱好:如["运动","阅读","美食"]) |
3. 创建内部表(基础表类型,新手必学)
内部表(Managed Table):Hive会管理表的数据存储,删除表时会同步删除HDFS中对应的数据源文件,适合临时数据处理、中间结果存储,实操如下:
create table if notexists dim_user_info ( user_id string, -- 用户ID(字符串类型,唯一标识用户) user_name string, -- 用户名 sex string, -- 性别(如male/female) age int, -- 年龄 city string, -- 所在城市 firstactivetime string, -- 首次激活时间(字符串格式,如2018-01-01) level int, -- 用户等级 extra1 string, -- 扩展字段1(存储JSON格式字符串,如用户设备信息) extra2 map<string,string>-- 扩展字段2(map类型,存储键值对,如{"phonebrand":"huawei","vip":"yes"}))row format delimited fields terminated by'\t'-- 字段分隔符:制表符(根据实际数据调整)collection items terminated by','-- 复合类型(array/struct)元素分隔符map keys terminated by':'-- map类型键值对分隔符lines terminated by'\n'-- 行分隔符:换行符stored as textfile; -- 存储格式:文本文件(默认格式,适配大部分场景)
✅ 关键说明:建表时必须指定“分隔符”,否则Hive无法正确解析数据;if not exists表示“若表不存在则创建”,避免重复建表报错。
4. 加载数据到内部表
Hive本身不存储数据,数据实际存储在HDFS中,“加载数据”本质是将HDFS或本地的文件,关联到Hive表中,支持两种加载方式:
-- 方式1:从本地文件加载(local:表示本地路径,加载后本地文件仍存在)load data local inpath '/home/ubuntu/data/user_info/user_info.txt' overwrite intotable dim_user_info;-- 方式2:从HDFS文件加载(无local:表示HDFS路径,加载后HDFS原文件会被移动到表对应的目录)load data inpath '/user/root/user_info.txt' overwrite intotable dim_user_info;
⚠️ 注意:overwrite表示“覆盖表中已有数据”,若想追加数据,去掉overwrite即可(改为into table dim_user_info)。
5. 创建分区表(大数据核心特性,必掌握)
分区表:按指定字段(如日期、地区)分区存储数据,查询时可只扫描目标分区,避免全量扫描,大幅提升查询效率,适合按时间增量更新的数据(如电商交易记录、日志数据):
create table if notexists fact_user_trade ( user_name string, -- 用户名 piece int, -- 购买数量 price double, -- 商品单价 pay_amount double, -- 支付金额 goods_category string, -- 商品品类(如food、clothes) pay_time bigint-- 支付时间戳(后续可转换为日期格式)) partitioned by (dt string) -- 按日期分区(dt格式:yyyy-MM-dd,如2019-03-24)row format delimited fields terminated by'\t'; -- 字段分隔符:制表符
6. 分区数据加载与修复
(1)手动上传分区数据到HDFS
分区表的数据需按“分区目录”存储,手动上传数据到对应目录:
hdfs dfs -put /home/ubuntu/data/user_trade/* /user/hive/warehouse/eshop.db/fact_user_trade
(2)设置动态分区(可选,高效加载多分区数据)
动态分区:加载数据时,自动根据指定字段的值创建分区,无需手动创建分区目录,适合批量加载多日期、多地区的分区数据:
-- 开启动态分区(默认关闭)set hive.exec.dynamic.partition=true;-- 非严格模式(允许所有分区字段动态生成,新手推荐)set hive.exec.dynamic.partition.mode=nonstrict;-- 最大动态分区数(避免过多分区导致性能问题,可根据需求调整)set hive.exec.max.dynamic.partitions=10000;set hive.exec.max.dynamic.partitions.pernode=10000;
(3)修复分区(关键步骤,避免查询不到数据)
手动上传分区数据后,Hive的元数据(记录表结构、分区信息)不会自动更新,需执行修复命令,同步元数据与HDFS中的分区数据:
msck repair table fact_user_trade;
五、Hive查询实操:基础查询+聚合分析(高频场景)
HQL(Hive查询语言)与SQL语法高度兼容,新手可直接复用SQL经验,以下是大数据场景中最常用的查询案例,基于前面创建的dim_user_info(用户表)和fact_user_trade(交易分区表):
1. 基础条件查询(无聚合,简单筛选)
-- 1. 查询北京女用户的姓名,取前10条(限制结果条数,避免返回过多数据)select user_name from dim_user_info where city='beijing'and sex='female' limit 10;-- 2. 查询2019年3月24日购买了food类商品的用户名、购买数量和支付金额(不聚合,返回明细)select user_name, piece, pay_amount from fact_user_trade where dt='2019-03-24'and goods_category='food';-- 3. 统计用户ELLA在2018年的总支付金额和最近、最远两次消费间隔天数selectsum(pay_amount) as total_pay, datediff(max(from_unixtime(pay_time, 'yyyy-MM-dd')), min(from_unixtime(pay_time, 'yyyy-MM-dd'))) as day_interval from fact_user_trade whereyear(dt)='2018'and user_name='ELLA';
2. 聚合查询(group by + having,统计分析)
聚合查询是大数据分析的核心,用于统计汇总数据,group by用于分组,having用于过滤聚合结果(区别于where过滤行数据):
-- 1. 查询2019年1月到4月,每个品类有多少人购买,累计支付金额是多少select goods_category, count(distinct user_name) as total_user, -- 去重统计购买人数(避免同一用户多次购买重复计数)sum(pay_amount) as total_pay -- 累计支付金额from fact_user_trade where dt between'2019-01-01'and'2019-04-30'groupby goods_category;-- 2. 查询2019年4月支付金额超过5万元的用户(筛选聚合后的结果)select user_name, sum(pay_amount) as total_pay from fact_user_trade where dt between'2019-04-01'and'2019-04-30'groupby user_name havingsum(pay_amount) >50000;-- 3. 查询2018年购买的商品品类在两个以上的用户数(子查询+聚合)selectcount(tmp.user_name) as total_user from (select user_name, count(distinct goods_category) as category_count from fact_user_trade whereyear(dt)='2018'groupby user_name havingcount(distinct goods_category) >2-- 筛选购买品类超过2个的用户) tmp; -- 子查询结果作为临时表,统计符合条件的用户数
3. 排序查询(order by,按指定字段排序)
用于对查询结果排序,常与limit配合使用,获取TopN数据:
-- 查询2019年4月支付金额最多的用户前5名(降序排序)select user_name, sum(pay_amount) as total_pay from fact_user_trade where dt between'2019-04-01'and'2019-04-30'groupby user_name orderby total_pay desc-- desc:降序(从大到小),asc:升序(从小到大,默认)limit 5;
六、Hive常用函数(高频实操,提升效率)
Hive提供了大量内置函数,适配大数据处理场景(时间转换、字符串处理、JSON解析等),无需手动编写复杂逻辑,以下是最常用的6个函数,附实操案例:
1. from_unixtime:时间戳转换成日期字符串
用于将bigint类型的时间戳,转换为指定格式的日期字符串,高频用于时间维度分析:
-- 将支付时间戳转换为“年-月-日 时:分:秒”格式select from_unixtime(pay_time, 'yyyy-MM-dd hh:mm:ss') as pay_datetime from fact_user_trade limit 10;
2. unix_timestamp:日期字符串转换成时间戳
与from_unixtime相反,将指定格式的日期字符串,转换为bigint类型的时间戳:
-- 将日期字符串“2019-03-24”转换为时间戳select unix_timestamp('2019-03-24', 'yyyy-MM-dd') as pay_ts from dual; -- dual:Hive虚拟表,用于无表查询(仅测试函数)
3. datediff:计算两个日期的时间差(天数)
语法:datediff(日期1, 日期2),返回“日期1 - 日期2”的天数差,用于计算时间间隔:
-- 计算用户首次激活时间与参照时间(2019-04-01)的间隔天数select user_name, datediff('2019-4-1', to_date(firstactivetime)) as active_interval from dim_user_info limit 10;
4. if/case when:条件判断函数
用于根据条件返回不同的值,适配分类统计场景,case when适合多条件,if适合二值判断:
-- (1)case when:多条件分组,统计不同年龄段的用户数selectcasewhen age <20then'20岁以下'when age <30then'20-30岁'when age <40then'30-40岁'else'40岁以上'endas age_seg,count(distinct user_id) as total_user from dim_user_info groupbycasewhen age <20then'20岁以下'when age <30then'20-30岁'when age<40then'30-40岁'else'40岁以上'end;-- (2)if:二值判断,统计不同性别、不同等级的用户数量select sex, if(level >5, '高等级', '低等级') as level_type, count(distinct user_id) as total_user from dim_user_info groupby sex, if(level >5, '高等级', '低等级');
5. substr:字符串取子串
语法:substr(字符串, 起始位置, 长度),起始位置从1开始,用于截取字符串中的指定内容(如年月、手机号前缀):
-- 截取首次激活时间的“年月”(如2018-01),统计每个月激活的新用户数select substr(firstactivetime, 1, 7) as active_month, count(distinct user_id) as new_user_count from dim_user_info groupby substr(firstactivetime, 1, 7);
6. get_json_object:从JSON字符串中提取指定key的值
用于解析string类型的JSON数据,提取指定key对应的value,高频用于处理扩展字段中的JSON数据:
-- 示例1:从extra1(JSON字符串)中提取手机品牌,统计不同手机品牌的用户数select get_json_object(extra1, '$.phonebrand') as phone_brand, count(distinct user_id) as total_user from dim_user_info groupby get_json_object(extra1, '$.phonebrand');-- 示例2:从map类型字段extra2中提取手机品牌(直接通过key访问,更简洁)select extra2['phonebrand'] as phone_brand, count(distinct user_id) as total_user from dim_user_info groupby extra2['phonebrand'];
✅ 小提示:MySQL中对应的JSON解析函数名叫json_extract,与Hive的get_json_object功能一致,可对比记忆。
七、常见问题与避坑指南(新手必看)
新手操作Hive时,很容易遇到以下问题,提前记牢避坑技巧,避免浪费时间排查:
- 1. 连接Hive失败:检查Hive服务是否启动、Hadoop集群是否正常运行,环境变量(如HIVE_HOME)是否配置正确;
- 2. 分区表查询无结果:手动上传分区数据后,未执行
msck repair table 表名修复元数据,导致Hive无法识别分区; - 3. 数据解析错乱:建表时指定的分隔符(如
fields terminated by '\t')与实际数据的分隔符不一致,需核对数据格式调整; - 4. 动态分区失败:未开启动态分区参数,或分区字段的值格式错误(如日期格式不是
yyyy-MM-dd),需检查参数配置和数据格式; - 5. 查询效率极低:未使用分区字段过滤数据,导致全量扫描HDFS中的海量数据,尽量通过
dt等分区字段缩小查询范围; - 6. 复合类型取值错误:map类型用
[]取值(如extra2['phonebrand']),struct类型用.取值(如user_info.first_name),不要混淆。
八、总结
本节课我们完整讲解了Hive的核心知识点:从Hive的定位、核心特性,到前置环境准备、建库建表、数据加载,再到查询实操与常用函数,覆盖了大数据离线分析的全流程,完全对标上一篇MySQL文档的结构和风格,新手可快速上手。
核心总结:Hive的核心价值是“用SQL处理大数据”,通过将HDFS数据映射为表、将HQL转换为分布式任务,降低了大数据处理的技术门槛,无需掌握Java、Scala,只要会写SQL,就能处理TB/PB级海量数据。它适合离线批量分析场景,是大数据生态中数据仓库建设的核心工具。
后续我们还会讲解Hive的高级特性(如外部表、分桶表、数据倾斜优化),帮大家进一步提升大数据处理效率。建议大家课后结合实际数据集动手实操,熟悉HQL语法与函数使用,真正将知识转化为实战能力~