❝作为一名R语言重度患者,日常就是Seurat分群、注释、可视化一条龙。直到做细胞通讯CellChat——跑出来的结果要么互作对不太理想,问了chatgpt才知道还有CellPhoneDB这个靠谱神器,定睛一看:Python版?别慌!这篇教程Python只需要复制粘贴,零Python基础也能轻松搞定,看完直接出硬核结果!
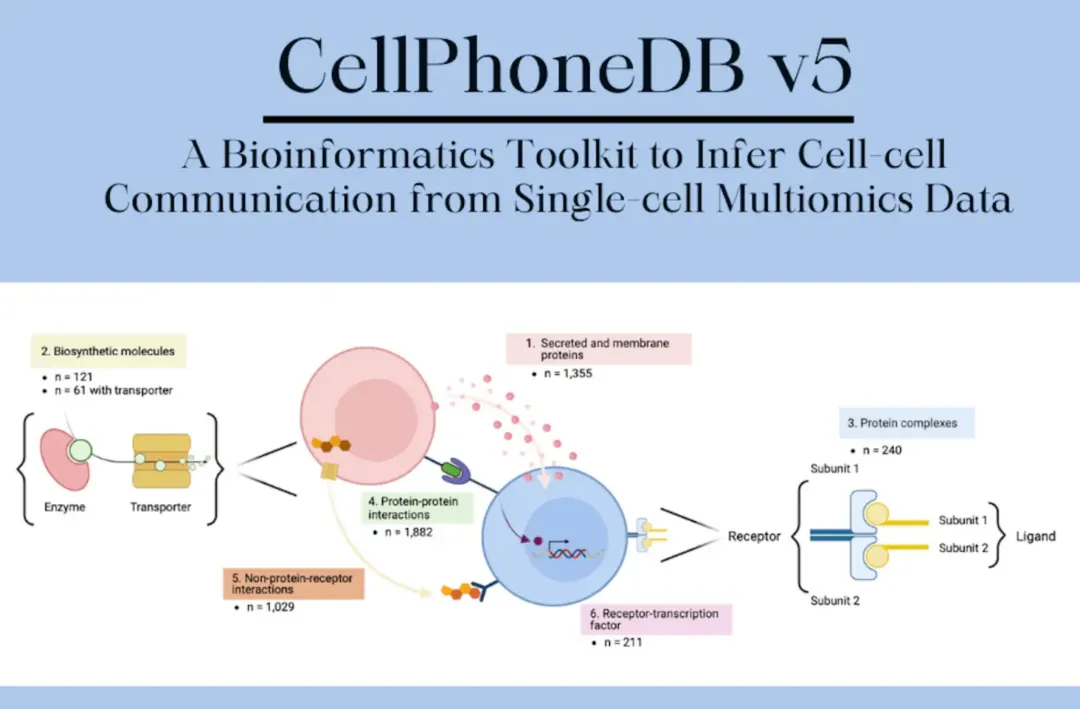
CellPhoneDB是一款基于配体 - 受体互作数据库的细胞通讯分析工具,核心优势是:
1.数据库经过人工校对,包含大量经过实验验证的配体 - 受体对;
2.提供统计检验(置换检验)评估互作的显著性;
3.支持多细胞类型间的通讯网络分析。
github链接:https://github.com/ventolab/CellphoneDB
完整分析流程
R语言(Seurat)预处理数据
CellPhoneDB需要两个核心文件:标准化表达矩阵 + 细胞类型注释文件,我们用Seurat提取并整理格式。
# 加载所需包library(Seurat)library(patchwork)library(tidyverse)library(tibble)# 1. 加载Seurat对象load("images/seob_norm.rdata") # 你的标准化Seurat对象# 2. 筛选目标分组seob_Thrombi <- subset(seob_norm, sample_group == "Tmour") # 合并层(Seurat V5需要)seob_anno <- JoinLayers(seob_Thrombi)# 3. 提取标准化表达矩阵Normalized_counts <- GetAssayData(seob_anno, layer = "data") %>% as.data.frame() %>% tibble::rownames_to_column("Gene") # 第一列命名为Gene# 4. 提取细胞类型注释文件metadata <- seob_anno@meta.data %>% tibble::rownames_to_column("Cell") %>% dplyr::select(Cell, cell_type) # 5. 创建输出目录并保存文件(确保格式为tab分隔、无引号)output_dir <- "./cellphonedb/"if (!dir.exists(output_dir)) { dir.create(output_dir, recursive = TRUE) }# 保存表达矩阵(CellPhoneDB要求第一列为基因名)write.table(Normalized_counts, file.path(output_dir, "Normalized_counts.txt"), row.names = FALSE, sep = "\t", quote = FALSE)# 保存细胞注释文件(CellPhoneDB要求至少两列:Cell、细胞类型)write.table(metadata, file.path(output_dir, "cellphonedb_meta.txt"), row.names = FALSE, sep = "\t", quote = FALSE)
Tips:
- 表达矩阵格式:第一列是
Gene(基因名),其余列是细胞名,值为标准化后的表达量; - 注释文件格式:仅需两列(
Cell=细胞名,cell_type=细胞类型),无多余列,避免CellPhoneDB识别失败; - 若细胞类型列名不是
cell_type,需替换为实际列名(如cluster/celltype)。
下载CellPhoneDB数据库
CellPhoneDB依赖官方配体-受体数据库,需提前下载:
- 下载地址:https://raw.githubusercontent.com/ventolab/cellphonedb-data/master/cellphonedb.zip
- 上传至服务器/本地的指定目录(示例:
/home/cellphonedb/cellphonedb.zip)。
Python运行CellPhoneDB核心分析
可以使用Jupyter
# 导入核心函数from cellphonedb.src.core.methods import cpdb_statistical_analysis_methodimport os# 1. 定义文件路径(替换为你的实际路径)cpdb_file_path = '/home/cellphonedb/cellphonedb.zip'# 数据库文件meta_file_path = '/home/cellphonedb/cellphonedb_meta.txt'# R输出的注释文件counts_file_path = '/home/cellphonedb/Normalized_counts.txt'# R输出的表达矩阵out_path = './cellphonedb_results'# 结果输出目录# 2. 创建输出目录ifnot os.path.exists(out_path): os.makedirs(out_path)# 3. 运行CellPhoneDB统计分析cpdb_results = cpdb_statistical_analysis_method.call( cpdb_file_path = cpdb_file_path, # 必须:数据库zip文件 meta_file_path = meta_file_path, # 必须:细胞注释文件 counts_file_path = counts_file_path, # 必须:标准化表达矩阵 counts_data = 'hgnc_symbol', # 关键:基因名类型 score_interactions = True, # 可选:是否计算互作得分 iterations = 500, # 置换检验迭代次数(500-1000) threshold = 0.1, # 阈值:基因在至少10%的细胞中表达才纳入分析 threads = 12, # 线程数(根据服务器/电脑配置调整) debug_seed = 123, # 随机种子(保证结果可重复) pvalue = 0.05, # 显著性P值阈值 separator = '-', # 结果文件中细胞类型的分隔符 debug = False, # 关闭debug模式(避免生成冗余文件) output_path = out_path # 结果保存路径)
结果文件说明
statistical_analysis_means_*.txt
所有细胞群之间的平均表达交互强度
- 每一行:一个 ligand–receptor pair
- 每一列:一个 cell type A | cell type B 组合
- 数值:ligand 在 A 细胞表达 × receptor 在 B 细胞表达 的平均值
值越大 → 说明这两个细胞之间该配体-受体组合表达越高。
statistical_analysis_pvalues_*.txt
统计显著性
同样结构:
- 数值:permutation test 得到的 p-value
statistical_analysis_significant_means_*.txt
筛选后的显著 interaction
- 只保留 p < threshold (默认0.05) 的 mean
statistical_analysis_deconvoluted_*.txt
分解复合配体/受体
很多 receptor 是 多亚基结构,例如:
IL2 receptor = IL2RA + IL2RB + IL2RG
这个文件会:* 展示 每个 subunit 在每个细胞群的表达
statistical_analysis_deconvoluted_percents_*.txt
表达比例
表示:多少比例的细胞表达这个基因
过滤低表达噪声
statistical_analysis_interaction_scores_*.txt
interaction strength score
CellPhoneDB 计算:
score = ligand expression × receptor expression
通常用于:
值越高 → interaction 越强
最常用的三个文件