凌晨 2 点,数据平台值班手机狂响。你打开电脑,盯着 Airflow 那堆报红的 DAG,3000 行 Python 代码像一团乱麻——某个任务的 xcom_pull 写错了 key,整个数据管道卡住。你花了两小时排查,最后发现是一个缩进错误。
如果我告诉你,有个开源项目,用 50 行 YAML 就能替代这 3000 行 Python,自带可视化拓扑图,还能从 UI 直接改配置并自动同步回 Git——而且它已经服务了 Dior、Oracle、华为、Renault 这些巨头——你会不会考虑让 Airflow "光荣退休"?
 Kestra Banner
Kestra Banner
一、工作流编排的"中年危机"
1.1 数据工程师的"代码屎山"
如果你用过 Apache Airflow,这段对话你一定不陌生:
# 传统 Airflow DAG - 一个真实项目的缩影
with DAG(
dag_id='data_pipeline_v47_final_real_final',
start_date=datetime(2024, 1, 1),
schedule_interval='0 2 * * *',
catchup=False,
max_active_runs=1,
default_args={
'retries': 3,
'retry_delay': timedelta(minutes=5),
'on_failure_callback': send_alert,
'on_retry_callback': log_retry,
'execution_timeout': timedelta(hours=2),
},
tags=['data', 'etl', 'production'],
) as dag:
extract_task = PythonOperator(
task_id='extract_from_mysql',
python_callable=extract_data,
op_kwargs={
'conn_id': 'mysql_prod',
'query': 'SELECT * FROM orders WHERE date = {{ ds }}',
},
provide_context=True,
)
transform_task = PythonOperator(
task_id='transform_with_pandas',
python_callable=transform_data,
op_kwargs={
'data': '{{ ti.xcom_pull(task_ids="extract_from_mysql") }}', # 这行写错就炸
},
)
load_task = PythonOperator(
task_id='load_to_snowflake',
python_callable=load_data,
op_kwargs={
'data': '{{ ti.xcom_pull(task_ids="transform_with_pandas") }}',
},
)
extract_task >> transform_task >> load_task
问题清单:
| |
|---|
| 代码膨胀 | 一个简单的 ETL 管道写了 200 行,复杂项目动辄 3000+ 行 |
| 调试地狱 | Jinja 模板 + Python 混写,报错信息看不懂 |
| UI 是摆设 | |
| 版本锁定 | Airflow 1.x 到 2.x 升级要重写所有 DAG |
| 学习曲线陡 | 新人上手需要 2 周,理解 DAG 依赖、XCom、Hook 概念 |
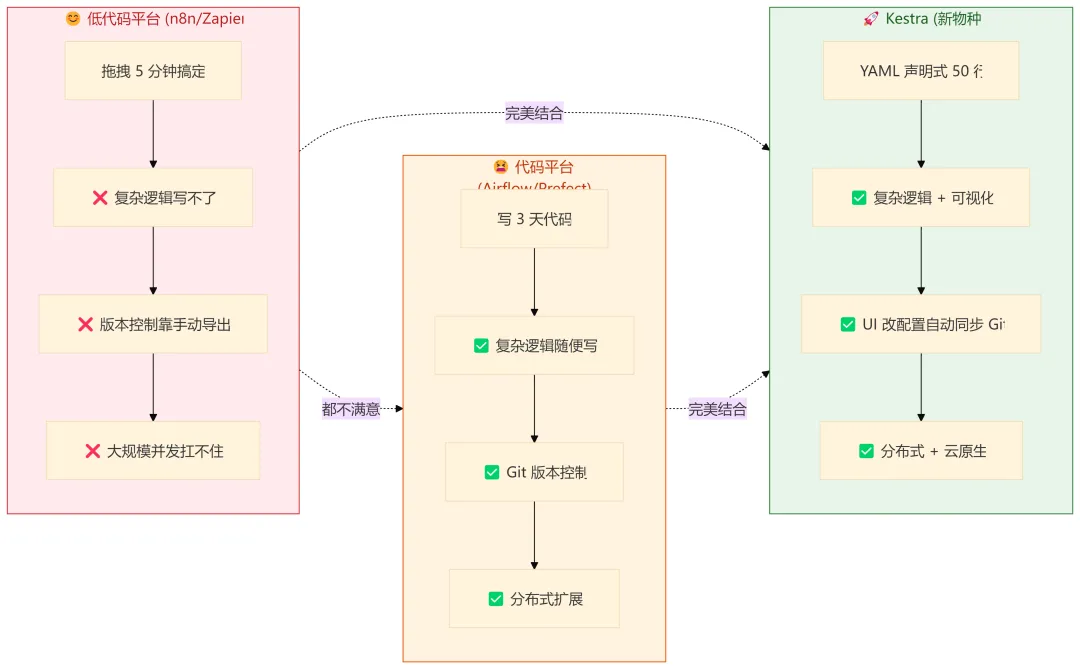
1.2 "那我用 n8n 不就行了?"
n8n、Zapier、Make 这些工具确实简单,但它们有另一个问题:
低代码工具的边界:
- 适合:简单触发 → 简单动作(发个通知、调个 API)
- 不适合:复杂 DAG 依赖、条件分支、错误重试、并发控制、数据管道
代码工具的边界:
有没有一种方案,既能像低代码一样简单,又能像代码平台一样强大?
二、Kestra:当 YAML 遇见分布式调度
2.1 这个项目什么来头?
| |
|---|
| 18,000+ |
| 1,500+ |
| 400+ |
| 1,200+ |
| 250+ |
| Dior、Oracle、华为、Renault、Leroy Merlin... |
| Java 21 + Micronaut + Vue 3 |
| |
Kestra 是一个声明式、事件驱动的工作流编排平台。
一句话定义:
用 YAML 声明你要什么,Kestra 帮你搞定怎么跑——支持定时/事件触发、分布式执行、Git 版本控制、UI 与代码双向同步。
 Kestra Dashboard
Kestra DashboardKestra 的拓扑视图——左边是 YAML 代码,右边是实时 DAG 图,改任意一边都会自动同步
2.2 同样的 ETL,Kestra 只需要 50 行
id: data_pipeline
namespace: production.etl
description: "数据管道 - 从 MySQL 到 Snowflake"
inputs:
- id: date
type: DATE
defaults: "2024-01-01"
variables:
mysql_conn: "mysql://user:pass@prod-db:3306/orders"
tasks:
- id: extract
type: io.kestra.plugin.jdbc.mysql.Query
sql: "SELECT * FROM orders WHERE date = '{{ inputs.date }}'"
url: "{{ vars.mysql_conn }}"
fetchType: STORE
- id: transform
type: io.kestra.plugin.scripts.python.Script
inputFiles:
data.csv: "{{ outputs.extract.uri }}"
script: |
import pandas as pd
df = pd.read_csv('data.csv')
df['total'] = df['price'] * df['quantity']
df.to_csv('result.csv', index=False)
outputFiles:
- result.csv
- id: load
type: io.kestra.plugin.jdbc.snowflake.Load
url: "jdbc:snowflake://account.snowflakecomputing.com"
username: "{{ secret('SNOWFLAKE_USER') }}"
password: "{{ secret('SNOWFLAKE_PASS') }}"
from: "{{ outputs.transform.outputFiles['result.csv'] }}"
table: ORDERS_STAGING
triggers:
- id: daily_schedule
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 2 * * *"
errors:
- id: alert_on_failure
type: io.kestra.plugin.notifications.slack.SlackExecution
url: "{{ secret('SLACK_WEBHOOK') }}"
message: "🚨 ETL 失败: {{ execution.id }}"
对比一下:
| | |
|---|
| | 50 行 YAML |
| | 2 小时 |
| | 可改可看,双向同步 |
| | 清晰的 YAML 验证 |
| | Docker 一行命令 |
三、Kestra 到底解决了什么问题?
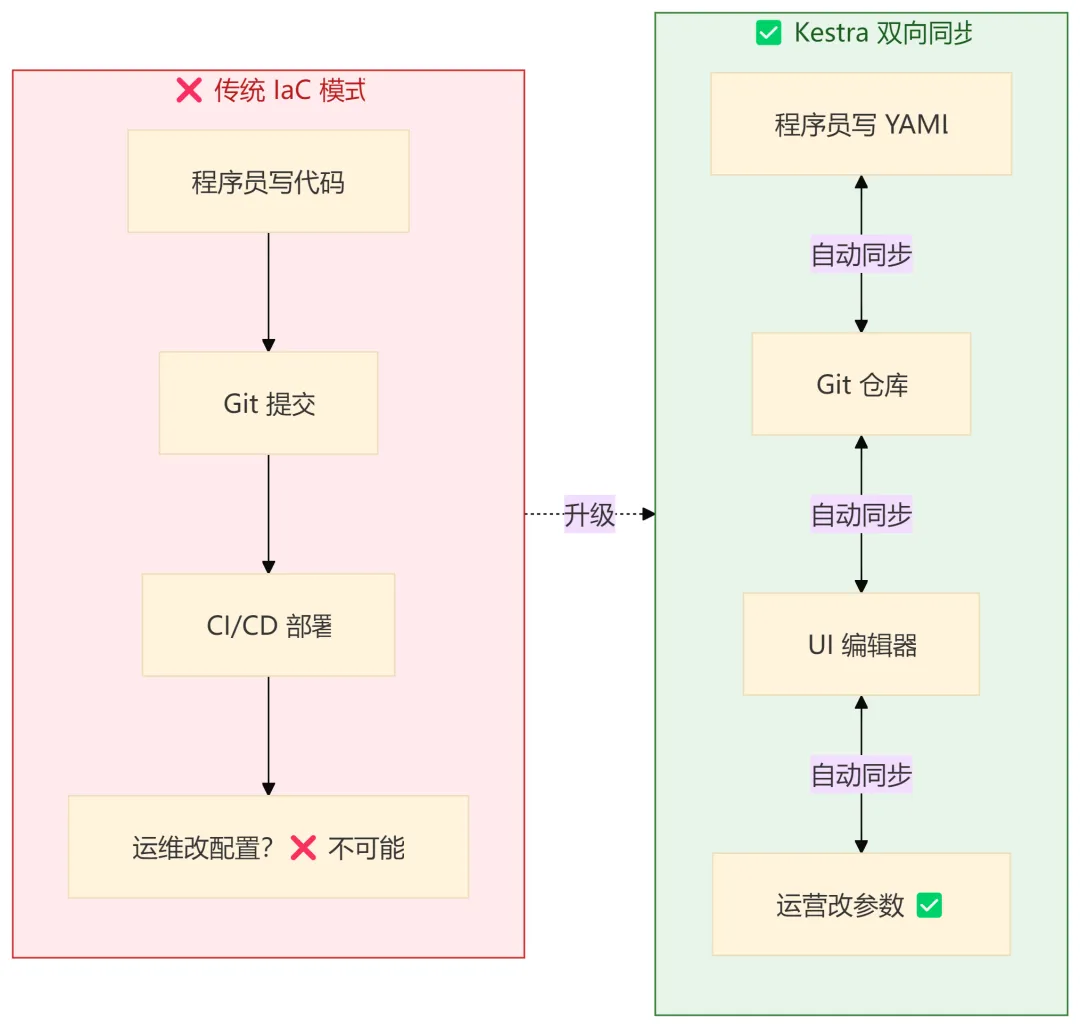
3.1 Everything as Code,但 Code 不是 Everything
传统"Everything as Code"的问题是:只有程序员能改代码。
Kestra 的答案是:Everything as Code + UI is Code
这意味着什么?
- 程序员在 VS Code 写 YAML → 自动同步到 UI
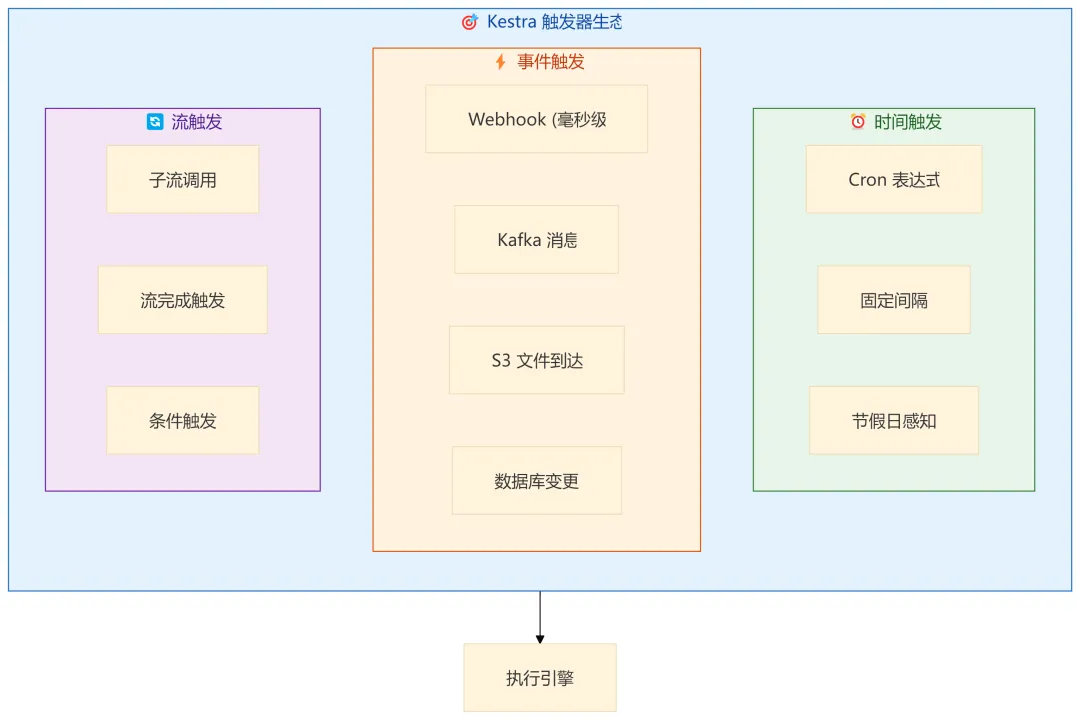
3.2 事件驱动 vs 定时调度
Airflow 是"定时调度优先"的设计,事件触发是后加的。Kestra 从第一天就是事件驱动优先:
一个真实场景:
# 当 S3 收到新文件时,毫秒级触发处理
triggers:
- id: s3_watcher
type: io.kestra.plugin.aws.s3.Trigger
bucket: data-lake
prefix: incoming/
action: MOVE
moveTo: processed/
不需要轮询,不需要 Cron,文件一到就触发——这是真正的事件驱动。
3.3 与 Airflow / Prefect / Temporal 的对比
| | | | Kestra |
|---|
| 语言 | | | | 语言无关 (YAML) |
| UI 能力 | | | | 完整双向 |
| 事件驱动 | | | | 原生 |
| 部署复杂度 | | | | Docker 一行 |
| 学习曲线 | | | | 平 |
| 插件生态 | | | | 1,200+ 内置 |
| 版本控制 | | | | Git + UI 双向 |
| 定价 | | | | 免费自托管 |
四、源码深度拆解:Kestra 的引擎盖下面是什么?
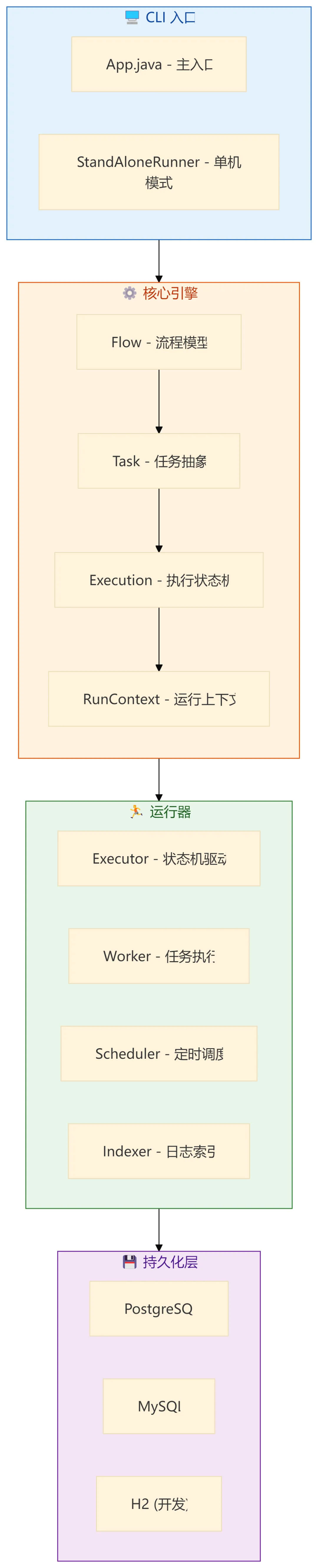
4.1 模块架构全景
Kestra 采用 Gradle 多模块 + Micronaut 微服务框架:
| |
|---|
cli | 命令行入口,支持 standalone / server / worker 模式 |
core | 核心模型:Flow、Task、Execution、Trigger |
jdbc-* | 数据库实现:PostgreSQL / MySQL / H2 |
webserver | |
ui | Vue 3 + Monaco Editor 可视化界面 |
4.2 核心模型:Flow = 有向无环图
在 core/src/main/java/io/kestra/core/models/flows/Flow.java 中,Flow 的核心结构:
@SuperBuilder
@Getter
@FlowValidation
public class Flow extends AbstractFlow implements HasUID {
// 变量定义
Map<String, Object> variables;
// 任务列表(主流程)
@Valid @NotEmpty
List<Task> tasks;
// 错误处理任务
@Valid
List<Task> errors;
// Finally 任务(无论成功失败都执行)
@Valid
List<Task> _finally;
// 触发器
@Valid
List<AbstractTrigger> triggers;
// 输入参数
@Valid
List<PluginDefault> pluginDefaults;
// 输出
@Valid
List<Output> outputs;
// 并发控制
@Valid
Concurrency concurrency;
// 重试策略
@Valid
AbstractRetry retry;
}
关键设计决策:
- Task 是抽象的:可以是普通任务(执行脚本),也可以是 FlowableTask(包含子任务,如 Parallel、EachSequential)
- State 是不可变的:每次状态变更都创建新对象,便于追溯和回滚
- Execution 包含完整上下文:inputs、outputs、labels、variables 全部持久化
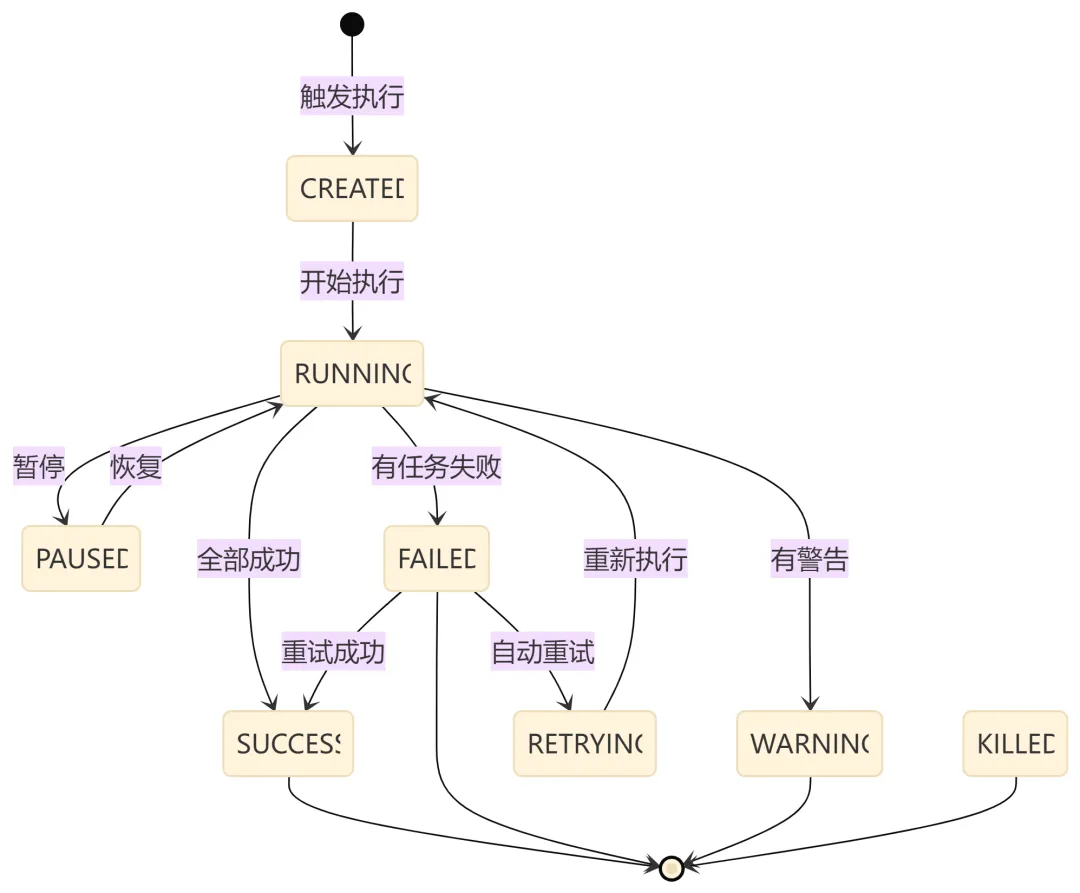
4.3 执行引擎:状态机驱动
Execution 的状态流转是一个经典的状态机:
在 Execution.java 中,状态转换的核心方法:
public Execution withState(State.Type state) {
return new Execution(
this.tenantId,
this.id,
this.namespace,
this.flowId,
this.flowRevision,
this.taskRunList,
this.inputs,
this.outputs,
this.labels,
this.variables,
this.state.withState(state), // 不可变变更
// ... 其他字段
);
}
4.4 RunContext:任务执行的万能上下文
RunContext 是 Kestra 最核心的抽象之一。每个任务执行时都会获得一个 RunContext,它提供:
public abstract class RunContext implements PropertyContext {
// 渲染变量(Pebble 模板)
public abstract String render(String inline);
// 日志记录
public abstract Logger logger();
// 内部存储
public abstract Storage storage();
// KV 存储
public abstract KVStore namespaceKv(String namespace);
// 工作目录
public abstract WorkingDir workingDir();
// 加密解密
public abstract String decrypt(String encrypted);
public abstract String encrypt(String plaintext);
// 流程信息
public abstract FlowInfo flowInfo();
public abstract TaskRunInfo taskRunInfo();
}
这意味着什么? 任何插件只需要拿到 RunContext,就能访问所有运行时能力——日志、存储、变量、密钥——而不用关心底层实现。
4.5 插件系统:1,200+ 开箱即用
Kestra 的插件是真正的"微内核 + 插件"架构。开发一个新插件只需要:
@SuperBuilder
@Getter
public class MyTask extends Task implements RunnableTask<MyTask.Output> {
@PluginProperty
private String myParameter;
@Override
public Output run(RunContext runContext) throws Exception {
// 1. 渲染参数
String rendered = runContext.render(myParameter);
// 2. 执行业务逻辑
String result = doSomething(rendered);
// 3. 返回输出
return Output.builder()
.result(result)
.build();
}
@Getter
@Builder
public static class Output implements io.kestra.core.models.tasks.Output {
private String result;
}
}
插件分类:
| |
|---|
| 数据存储 | PostgreSQL, MySQL, MongoDB, Redis, Elasticsearch |
| 云服务 | AWS S3/EC2/Lambda, GCP, Azure |
| 大数据 | Spark, Flink, dbt, Airbyte |
| 消息队列 | Kafka, RabbitMQ, Redis Pub/Sub |
| 脚本执行 | Python, Shell, Node.js, R, Go |
| 通知 | Slack, Email, Discord, Telegram, 企业微信 |
| AI/ML | OpenAI, Azure OpenAI, Ollama |
五、四大典型企业场景
5.1 数据管道:从 MySQL 到 Snowflake 的完整 ETL
id: daily_etl
namespace: data.etl
tasks:
- id: extract_orders
type: io.kestra.plugin.jdbc.mysql.Query
url: jdbc:mysql://prod-db:3306/ecommerce
sql: |
SELECT * FROM orders
WHERE created_at >= '{{ trigger.date ?? execution.startDate }}'
fetchType: STORE
- id: validate_data
type: io.kestra.plugin.scripts.python.Script
inputFiles:
orders.csv: "{{ outputs.extract_orders.uri }}"
script: |
import pandas as pd
df = pd.read_csv('orders.csv')
assert len(df) > 0, "No orders found!"
assert df['amount'].min() > 0, "Invalid amounts!"
df.to_csv('validated.csv', index=False)
outputFiles:
- validated.csv
- id: load_to_snowflake
type: io.kestra.plugin.jdbc.snowflake.Load
url: jdbc:snowflake://account.snowflakecomputing.com
from: "{{ outputs.validate_data.outputFiles['validated.csv'] }}"
table: ORDERS_STAGING
- id: dbt_transform
type: io.kestra.plugin.dbt.cli.DbtCLI
commands:
- dbt run --select staging
triggers:
- id: daily
type: io.kestra.plugin.core.trigger.Schedule
cron: "0 3 * * *"
5.2 AI Agent:用自然语言处理客户反馈
id: ai_customer_feedback
namespace: ai.agents
tasks:
- id: fetch_feedback
type: io.kestra.plugin.jdbc.postgresql.Query
sql: "SELECT * FROM feedback WHERE processed = false"
fetchType: FETCH
- id: analyze_sentiment
type: io.kestra.plugin.ai.OpenAI
apiKey: "{{ secret('OPENAI_API_KEY') }}"
model: gpt-4
prompt: |
分析以下客户反馈的情感和主题:
{{ outputs.fetch_feedback.rows | toJson }}
返回 JSON 格式:{"sentiment": "positive/negative/neutral", "topic": "..."}
- id: route_feedback
type: io.kestra.plugin.core.flow.Switch
value: "{{ json(outputs.analyze_sentiment.text).sentiment }}"
cases:
negative:
- id: alert_support
type: io.kestra.plugin.notifications.slack.SlackIncomingWebhook
url: "{{ secret('SLACK_WEBHOOK') }}"
payload: |
{"text": "🚨 负面反馈需要处理: {{ outputs.analyze_sentiment.text }}"}
positive:
- id: thank_customer
type: io.kestra.plugin.notifications.email.SendMail
to: "{{ outputs.fetch_feedback.rows[0].email }}"
subject: "感谢您的反馈!"
body: "感谢您的支持..."
5.3 基础设施编排:Terraform + Ansible + K8s
id: infrastructure_provision
namespace: infra.devops
tasks:
- id: terraform_apply
type: io.kestra.plugin.terraform.cli.TerraformCLI
commands:
- terraform init
- terraform apply -auto-approve
outputDirectoryState: OUTPUT_ON_FAILURE
- id: ansible_configure
type: io.kestra.plugin.ansible.cli.AnsibleCLI
commands:
- ansible-playbook -i inventory.ini setup.yml
inputFiles:
inventory.ini: |
[webservers]
{{ outputs.terraform_apply.outputVars.webserver_ip }}
- id: k8s_deploy
type: io.kestra.plugin.kubernetes.kubectl.Kubectl
namespace: default
commands:
- kubectl apply -f deployment.yaml
inputFiles:
deployment.yaml: |
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
...
六、5 分钟跑起来
方式一:Docker 一行命令(推荐)
docker run --pull=always -p 8080:8080 --user=root \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /tmp/kestra-wd:/tmp/kestra-wd \
kestra/kestra:latest server standalone
打开浏览器访问 http://localhost:8080,开始创建你的第一个 Flow!
方式二:Docker Compose(生产推荐)
# docker-compose.yml
services:
postgres:
image: postgres:18
environment:
POSTGRES_DB: kestra
POSTGRES_USER: kestra
POSTGRES_PASSWORD: k3str4
volumes:
- postgres-data:/var/lib/postgresql
kestra:
image: kestra/kestra:latest
command: server standalone
volumes:
- kestra-data:/app/storage
- /var/run/docker.sock:/var/run/docker.sock
environment:
KESTRA_CONFIGURATION: |
datasources:
postgres:
url: jdbc:postgresql://postgres:5432/kestra
username: kestra
password: k3str4
kestra:
repository:
type: postgres
storage:
type: local
local:
base-path: "/app/storage"
queue:
type: postgres
url: http://localhost:8080/
ports:
- "8080:8080"
depends_on:
- postgres
volumes:
postgres-data:
kestra-data:
docker compose up -d
30 秒创建第一个 Flow
id: hello_world
namespace: dev
tasks:
- id: say_hello
type: io.kestra.plugin.core.log.Log
message: "Hello, Kestra! 🚀"
恭喜!你刚刚完成了第一个 Kestra 工作流!
 Kestra 快速开始
Kestra 快速开始
七、Kestra 的核心竞争力
7.1 技术护城河
| |
|---|
| 架构 | Java 21 + Micronaut 微服务,天然支持分布式 |
| 存储 | JDBC 抽象层,PostgreSQL / MySQL / H2 随意切换 |
| 插件 | 1,200+ 官方插件,开发一个新插件只需 50 行代码 |
| UI | Vue 3 + Monaco Editor,真正的双向同步 |
| 调度 | |
7.2 产品护城河
| |
|---|
| 易用性 | |
| 灵活性 | |
| 企业级 | |
| 云原生 | Docker / K8s / AWS / GCP / Azure 全支持 |
| 社区 | |
7.3 与国内场景的适配
八、谁不适合 Kestra?
公平起见,Kestra 不是万能的:
- 纯 Python 团队:如果你们已经深度绑定 Airflow 生态,迁移成本需要评估
- 超简单场景:只是定时发个邮件,用 Cron 就够了
- 实时性要求极高:毫秒级延迟的场景,可能需要专业的流处理引擎(Flink)
- 不想运维:自部署意味着你要管服务器,不想折腾就用 Kestra Cloud
九、结语:工作流编排的"YAML 时刻"
9.1 历史的回响
回顾技术演进:
- 2010 年:Chef / Puppet 用 Ruby 声明基础设施 → Ansible 用 YAML 更简单
- 2015 年:Docker Compose 用 YAML 定义容器编排 → Kubernetes 用 YAML 定义集群
- 2020 年:GitHub Actions 用 YAML 定义 CI/CD → 所有 CI/CD 都支持 YAML
- 2025 年:Kestra 用 YAML 定义工作流编排 → 下一个会是你的项目吗?
9.2 为什么说"YAML 时刻"已经到来?
Kestra 代表的是一种理念:
复杂的事情应该交给引擎,人只需要声明"我要什么"。
就像 SQL 让我们不需要关心数据如何扫描,Docker 让我们不需要关心依赖如何安装,Kestra 让我们不需要关心任务如何调度。
你只需要写 YAML,剩下的交给 Kestra。
十、快速上手
10.1 在线体验(无需安装)
👉 官方 Demo:https://demo.kestra.io
10.2 本地运行
# Docker 一键启动
docker run -p 8080:8080 kestra/kestra:latest server standalone
10.3 资源链接
| |
|---|
| https://github.com/kestra-io/kestra |
| |
| https://kestra.io/plugins |
| https://kestra.io/blueprints |
| |
| |
💡 如果你的团队还在 Airflow 的 3000 行 Python 里挣扎,不妨花 5 分钟跑一个 docker run,体验一下"50 行 YAML 搞定一切"的感觉。
毕竟,人不应该是调度器的奴隶——调度器应该是人的工具。
项目地址:https://github.com/kestra-io/kestra
Star 数:18,000+
许可证:Apache 2.0
关注公众号,每天带你发现一个高质量开源项目。